主要涉及到一个查询参数的逆向.疫情填报打卡,之前用selenium写过,不过比较笨重.
现在直接使用requests.
爬虫的精髓应该是js逆向,反爬技术.
使用python的简单之处就是利用方法简单的库,cookie自动保存,留给我们的就是去逆向,多线程处理等等.
开始
首先进入官网
打开检查,一般流程是发送一个GET请求,有了cookie.如果你发现响应没有set-cookie,而请求直接就有了cookie,这一般是浏览器缓存了,可以清除一下cookie.
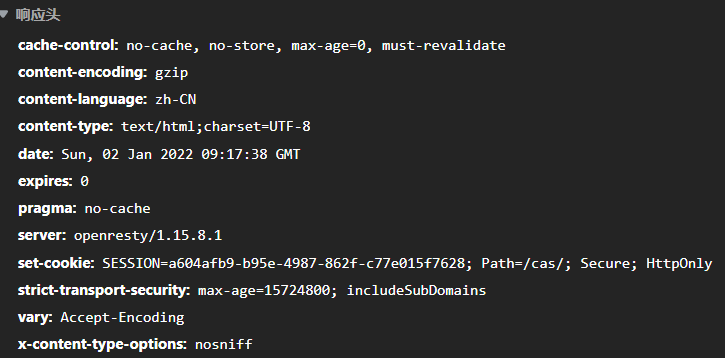
这就是响应,可以看到有了set-cookie,这很重要,直接提交表单的话没有cookie,很可能失败(要说为什么不是一定,这与你调的第三方包有关).
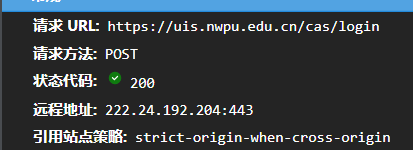
然后输入账号密码,查看又发了什么请求,通常会发一个POST.
打开筛选器 method:POST查看
当看到POST请求时有必要查看PAYLOAD,也就是携带的数据.
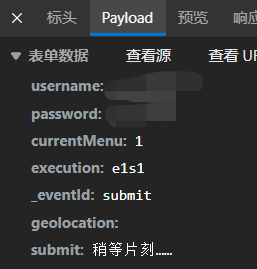
构造请求时直接把这个表单发过去就行了.
再看看响应头又有set-cookie说明这个很有用,因为给了你cookie.
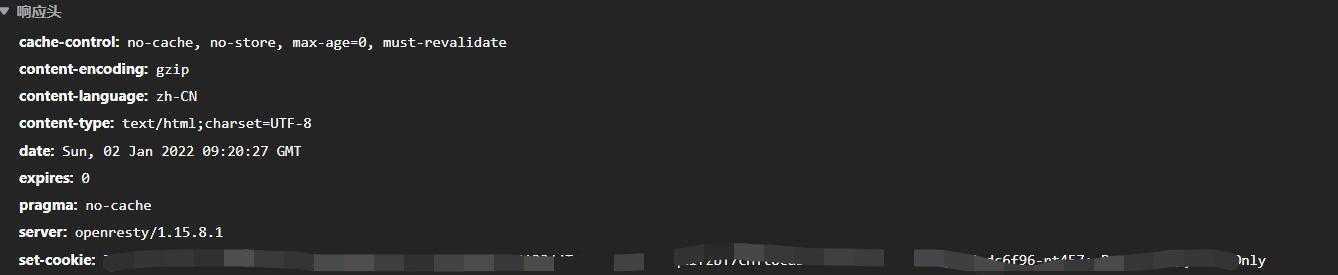
这样登录之后就有了基本的cookie
进入疫情填报
然后进入疫情填报界面疫情每日填报
正常一波操作:打开审查,刷新,查看重要的请求(一般是jsp或者js啥的)
看到了熟悉的set-cookie
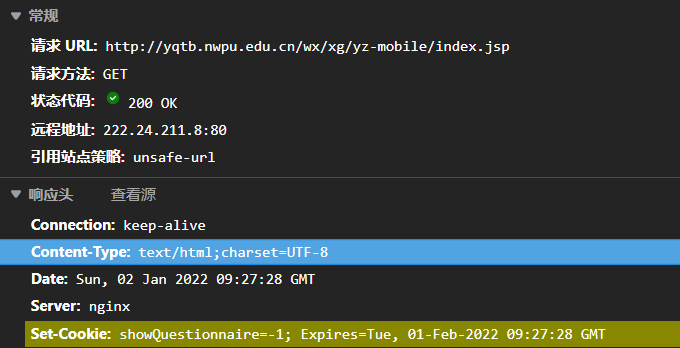
说明这个url是需要get的,同时查看响应发现有很多个人信息,包括姓名.
注意一下:因为我们登陆时只输入了学号和密码,如果后面需要姓名,可以通过这种方法获取响应提取出姓名.
这里就可以利用正则提取出姓名.1
2name_info = s.get(get_name_url, headers=headers).text
name = re.search(r'姓名:(.*)<', name_info).group(1)
同时我们又可以发现还有POST请求
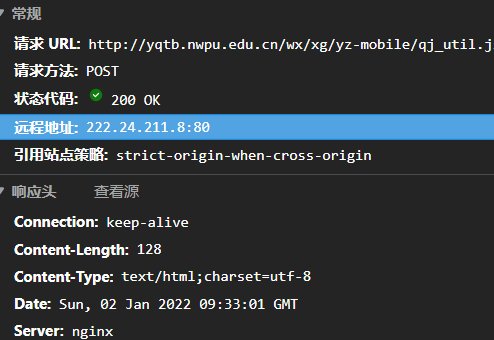
查看payload,有一个1
actionType: getRoles
看不出有什么特别的作用,可以不用post.
最后
然后点击每日填报,又进入新的页面,查看有没有什么请求
筛选jsp,我们到这里就可以知道这个网站的架构了,利用jsp(不过这是常见的方法)
可以发现一个请求jrsb.jsp,貌似没什么特别作用.
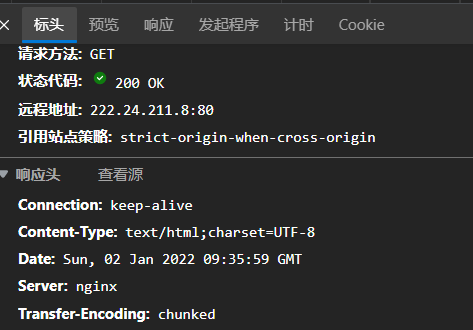
不过可以看看响应的预览,后面可能会用于提取一些数据啥的.
勾选已检测,提交表单.
可以查看新的请求
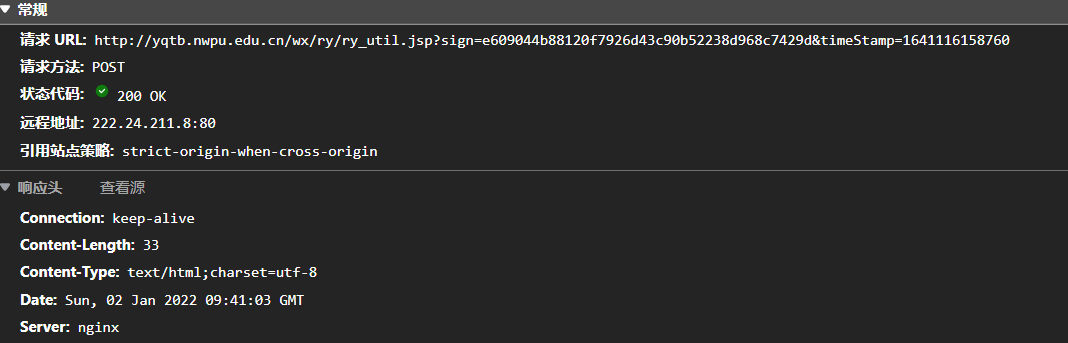
这就是提交表单的POST.
查看Payload,重点是sign和timeStamp.表单数据正常贴过去就行.
主要是sign和timeStamp数据如何获取.
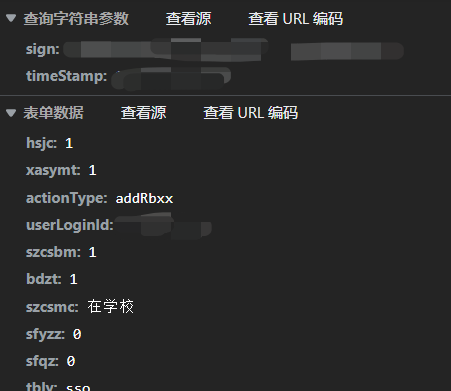
接下来说说这个重点
重点
直接全局搜索sign或者其他关键词,这里的要点是不能把之前的清空了,也就是查询字符串参数与之前的响应有关.
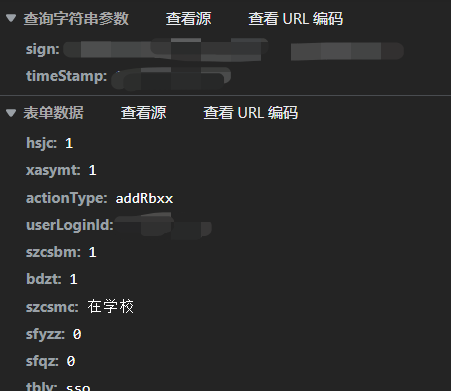
结果惊奇的发现这个字段在jrsb.jsp的响应里,url就是这个字段,推测是后台java生成后发过来的.

提取出来就行了.1
2query_info = s.get(get_query_url, headers=headers).text
info = re.search(r'sign=(.*?)&timeStamp=(\d*)', query_info)
后面post需要params的参数,也就是post需要data表单数据,也需要params的字符串查询参数.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27post_url = 'http://yqtb.nwpu.edu.cn/wx/ry/ry_util.jsp?' + info.group()
params = {
'sign': sign,
'timeStamp': timestamp
}
data = {
'hsjc': '1',
'xasymt': '1',
'actionType': 'addRbxx',
'userLoginId': sno,
'szcsbm': '1',
'bdzt': '1',
'szcsmc': '在学校',
'sfyzz': '0',
'sfqz': '0',
'tbly': 'sso',
'qtqksm': '',
'ycqksm': '',
'userType': '2',
'userName': name,
}
# 这里要加一下请求源 必要
headers.update({
'Referer': 'http://yqtb.nwpu.edu.cn/wx/ry/jrsb.jsp',
'Origin': 'http://yqtb.nwpu.edu.cn',
})
r = s.post(post_url, headers=headers, data=data, params=params)
最后要加一下请求的referer
Referer 请求头包含了当前请求页面的来源页面的地址,即表示当前页面是通过此来源页面里的链接进入的
如果不加测试发现过不了,应该是服务器有检测.
这样整个代码基本就完成了.
源代码
1 | import json |
学习资料
这是偶然看到的,感觉挺不错,无聊时可以看看
