机器学习有必要好好学会numpy,pandas和matplotlib
开始
1 | pip install pandas |
安装.
Pandas 一个强大的分析结构化数据的工具集,基础是 Numpy(提供高性能的矩阵运算)。
Pandas 可以从各种文件格式比如 CSV、JSON、SQL、Microsoft Excel 导入数据。
Pandas 可以对各种数据进行运算操作,比如归并、再成形、选择,还有数据清洗和数据加工特征
数据结构
Series,DataFrame
前者是一列,类似一维数组,后者是表格。1
2
3
4
5
6
7
8
9
10
11
12pandas.Series( data, index, dtype, name, copy)
参数说明:
data:一组数据(ndarray 类型)。
index:数据索引标签,如果不指定,默认从 0 开始。
dtype:数据类型,默认会自己判断。
name:设置名称。
copy:拷贝数据,默认为 False。1
2
3
4
5
6
7import pandas as pd
a = [1, 2, 3]
myvar = pd.Series(a)
print(myvar)
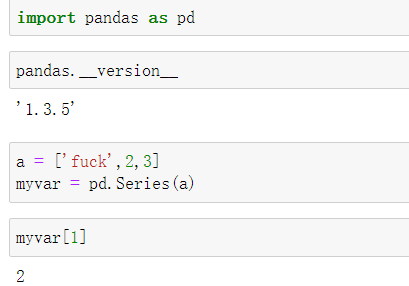
索引默认从0开始,可以修改索引名字.1
2
3
4
5
6
7import pandas as pd
a = ["Google", "Runoob", "Wiki"]
myvar = pd.Series(a, index = ["x", "y", "z"])
print(myvar)
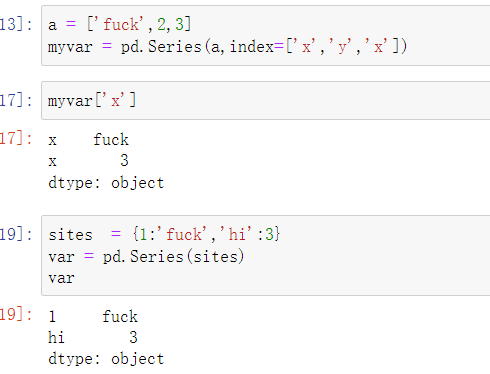
也可以使用字典创建对象,
DataFrame 构造方法如下:1
pandas.DataFrame( data, index, columns, dtype, copy)
参数说明:
- data:一组数据(ndarray、series, map, lists, dict 等类型)。
- index:索引值,或者可以称为行标签。
- columns:列标签,默认为 RangeIndex (0, 1, 2, …, n) 。
- dtype:数据类型。
- copy:拷贝数据,默认为 False。
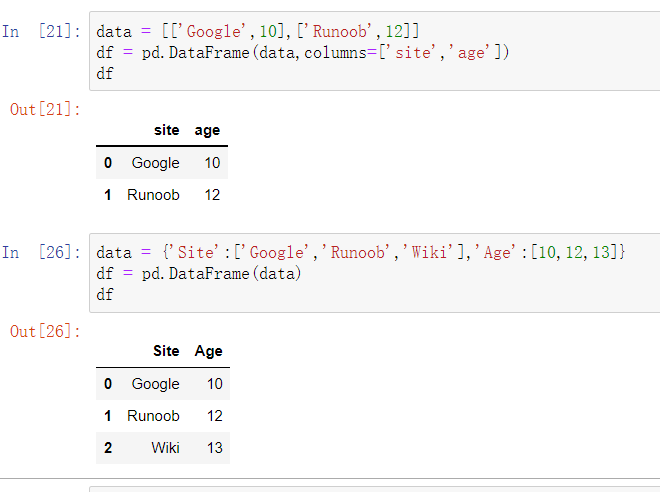
使用二维数组创建1
2
3
4
5
6
7import pandas as pd
data = [['Google',10],['Runoob',12],['Wiki',13]]
df = pd.DataFrame(data,columns=['Site','Age'],dtype=float)
print(df)
使用numpy类型创建
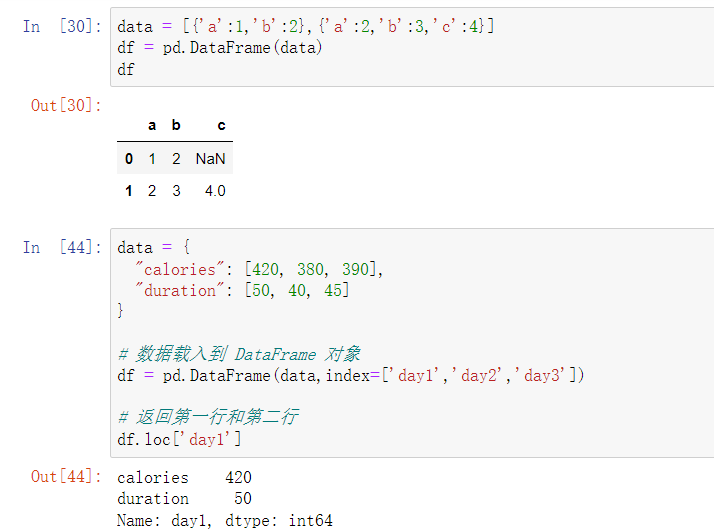
loc属性返回指定行或列
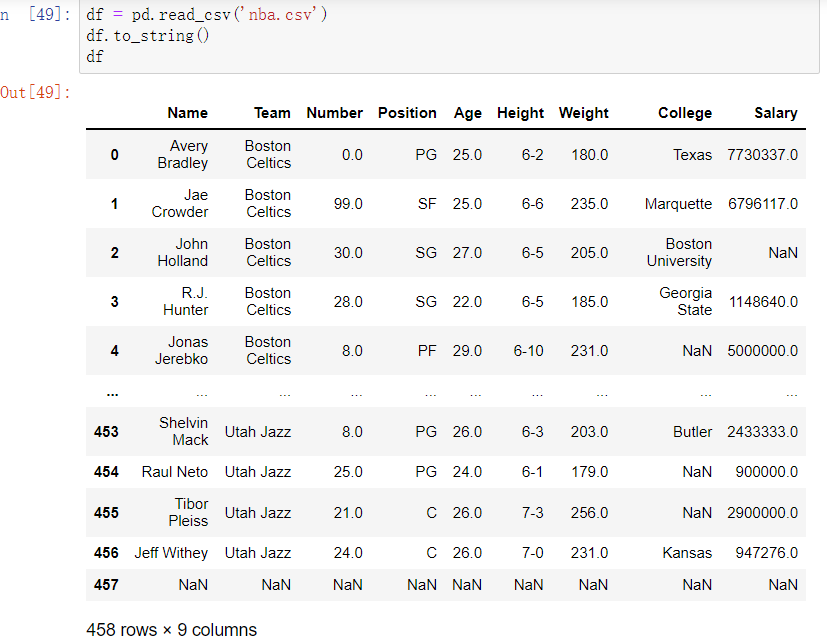
读取csv文件
1 | df = pd.read_csv() |
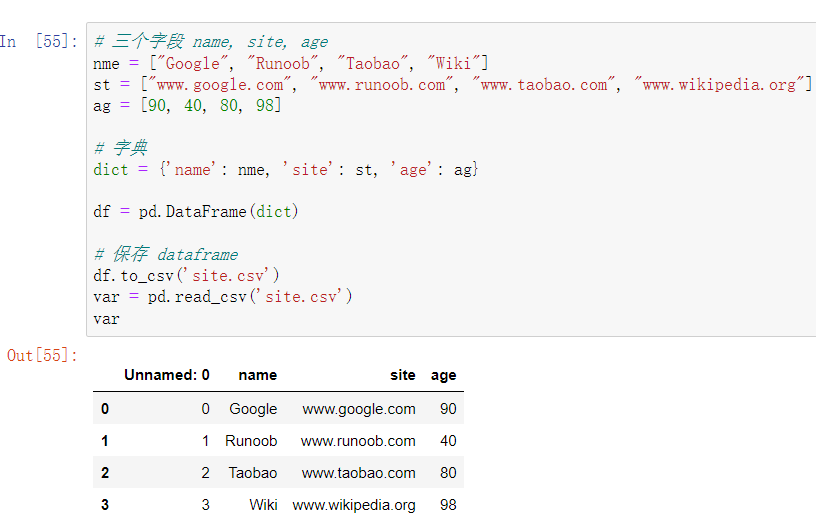
存为csv文件
to_csv()将DataFrame数据存为csv
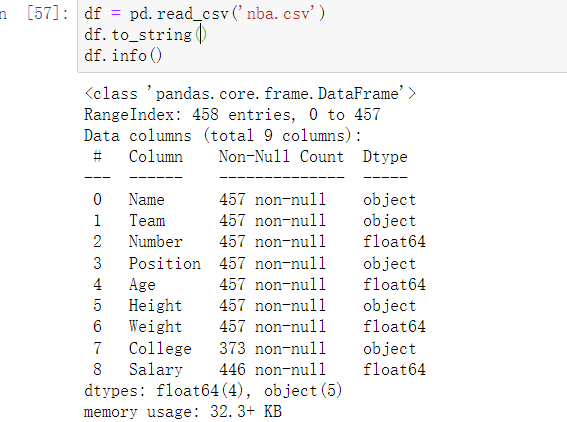
数据处理
1 | head() #前面几行 |
读取json文件
存储和交换文本信息的语法,类似 XML
JSON 比 XML 更小、更快,更易解析
主要是内嵌的json.1
2read_json() #读取json文件
json_normalize() #将内嵌的数据完整解析1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26{
"school_name": "ABC primary school",
"class": "Year 1",
"students": [
{
"id": "A001",
"name": "Tom",
"math": 60,
"physics": 66,
"chemistry": 61
},
{
"id": "A002",
"name": "James",
"math": 89,
"physics": 76,
"chemistry": 51
},
{
"id": "A003",
"name": "Jenny",
"math": 79,
"physics": 90,
"chemistry": 78
}]
}
读取students并包括了school_name,class1
2
3
4
5
6
7
8
9
10
11
12
13
14import pandas as pd
import json
# 使用 Python JSON 模块载入数据
with open('nested_list.json','r') as f:
data = json.loads(f.read())
# 展平数据
df_nested_list = pd.json_normalize(
data,
record_path =['students'],
meta=['school_name', 'class']
)
print(df_nested_list)
使用glom模块处理数据嵌套1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34{
"school_name": "local primary school",
"class": "Year 1",
"students": [
{
"id": "A001",
"name": "Tom",
"grade": {
"math": 60,
"physics": 66,
"chemistry": 61
}
},
{
"id": "A002",
"name": "James",
"grade": {
"math": 89,
"physics": 76,
"chemistry": 51
}
},
{
"id": "A003",
"name": "Jenny",
"grade": {
"math": 79,
"physics": 90,
"chemistry": 78
}
}]
}
只读取math字段1
2
3
4
5
6
7import pandas as pd
from glom import glom
df = pd.read_json('nested_deep.json')
data = df['students'].apply(lambda row: glom(row, 'grade.math'))
print(data)
说实话,包括numpy这些东西找官网找api就行了.现在只需要大概过一遍.
