NLP即自然语言处理,入门学习一下.
从自然语言的角度出发,基本可以划分为两个部分:自然语言的理解和自然语言的生成
但总的来说,自然语言理解又可以分为三个方面:
- 词义分析
- 句法分析
- 语义分析
自然语言的生成则是从结构化的数据(可以通俗理解为自然语言理解分析后的数据)以读取的方式自动生成文本。主要有三个阶段:
- 文本规划:完成结构化数据中的基础内容规划。
- 语句规划:从结构化数据中组合语句来表达信息流。
- 实现:产生语法通顺的语句来表达文本。
概念
NLP 的一些基础专业术语。
- 分词:词是 NLP 中能够独立活动的有意义的语言成分。即使某个中文单字也有活动的意义,但其实这些单字也是词,属于单字成词。
- 词性标注:给每个词语的词性进行标注,比如 :跑/动词、美丽的/形容词等等。
- 命名实体识别:从文本中识别出具有特定类别的实体。像是识别文本中的日期,地名等等。
- 词义消歧:多义词判断最合理的词义。
- 句法分析:解析句子中各个成分的依赖关系。
- 指代消解:消除和解释代词「这个,他,你」等的指代问题。
同时还要学习一些字符串的一些常见操作.正则表达式这些肯定是要比较熟练的.
demo.py1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126# 统计字串的出现次数
# .count() 方法返回特定的子串在字符串中出现的次数
import re
def count_example():
str = "jalfjsalf;"
n = str.count('a')
print(n)
# 可以看到python在处理这些操作时是十分简便的
# 去除字符串
# .strip()方法可以去除字符串首尾的指定符号。
# 无指定时,默认去除空格符 ' ' 和换行符 '\n'
def strip_example():
str = "asdfhjkasjkfas"
print(str.strip('as'))
# 只想要去除字符串开头的某个字符串,但是字符串的末尾有一个同样的字符串并不需要去掉。
# 这时候可以使用 .lstrip() 方法
# 同理去掉末尾使用 .rstrip()
def concate_example():
seq1 = "你"
seq2 = "好"
seq = seq1 + seq2
print(seq)
# 需要将字符串用特定的符号拼接起来的字符的时候,可以用.join()
# 方法来进行拼接
print(','.join(["你好", "再见"]))
# 字符串比较
# 当想要比较两个字符串的大小时,这里需要加载 operator 工具,
# 它是 Python 的标准库。不需要额外下载,
# 直接通过 import 调用即可。
# operator 从左到右第一个字符开始,根据设定的规则比较,返回布尔值( True,False )
import operator
def compare_example():
seq1 = "字符串1号"
seq2 = "字符串2号"
print(operator.lt(seq1, seq2))
print(operator.le(seq1, seq2))
print(operator.eq(seq1, seq2))
print(operator.ne(seq1, seq2))
# 另外可以直接使用> <比较字符串字典序
print(seq1 < seq2)
def ulcase():
str = "LkfLkas"
print(str.upper())
print(str.lower())
# 字符串查找 find与index 如果没有找到 index会报错 find返回-1
def find_str():
str = "这是一段字符串"
seq = "一段"
n = str.find(seq)
print(n)
# 切分字符串
# 有两种常用的方法。第一种是直用序列截取的方法。
# 这种方法十分的简单,就是根据顺序来截取序列上你想要的某些片段。
def spit_str():
str = "你好,很好"
print(str[0])
# split() 函数可以完成这个操作, 函数返回一个由切分好的字符串组成的列表。
print(str.split(','))
# 需要翻转字符串的时候,那么我们直接用序列操作,
# 直接以上面截取序列的方法,但是按照逆向的来截取实现翻转
print(str[::-1])
# 判断字符串中是否存在某个字符
# in 关键字可以用在任何容器对象上,判断一个子对象是否存在于容器当中,并不局限于判断字符串是否存在某子串,
# 还可以用在其他容器对象例如 list [],tuple (),set {} 等类型
def in_example():
str = "232434"
if '2' in str:
print('exists')
# 有时需要把字符串中的某段字符串用另一段字符串代替
def replace_str():
seq = "l;fjasfkfkla"
print(seq.replace("l","a"))
# 当遇到需要判断字符串是否以某段字符开头的时候。比如想要判断 ‘abcdefg’ 是否以 'a' 开头。
# 可以用 .startswish() 方法
def startswith():
seq = "afljsaakl"
print(seq.startswith('akl'))
print(seq.endswith('akl'))
def isDigit():
# 当想要检查字符串的构成,像是检查字符串是否由纯数字构成。
seq = "hjkhfahkjas"
print(seq.isdigit())
# seq.isalnum()
# seq.isalpha()
# seq.isdecimal()
def regresson():
pattern = re.compile(r'[0-9]{4}')
# 正则规则
match = pattern.search("432432532564") #search查找
# print(match) #对象 <re.Match object; span=(0, 4), match='4324'>
print(match.group(0)) #group中有匹配结果
# 这个方法是将正则表达式与字符串进行匹配,如果找到第一个符合正则表达式的结果,就会返回,
# 然后匹配结果存入group()中供后续操作。
result = pattern.findall("423425334")
print(result) #.findall():
# 这个方法可以找到符合正则表达式的所有匹配结果
# .match() 方法与 .search() 方法类似,只匹配一次,并且只从字符串的开头开始匹配
if __name__ == '__main__':
# count_example()
# strip_example()
# concate_example()
# compare_example()
# find_str()
# spit_str()
# replace_str()
# startswith()
regresson()
正则表达式的应用场景十分广泛:在去除网页类文本语料库中 html 符号,去除一些聊天的表情符号像是 Orz ,T_T 等等有着十分重要的应用。因此学会使用正则表达式,将会对自然语言处理实现有着不小的帮助.
中英文分词方法
分词作为自然语言处理实际运用当中当中最基本的任务,对文本预处理来说十分的重要
在语言理解中,词是最小的能够独立活动的有意义的粒度。由词到句,由句成文。因此,将词确定下来是理解自然语言处理的第一步,只有跨越了这一步,才能进行后续任务
我的理解就是把词分开.
英文分词
对于英文来说,空格或是一些标点符号就足以.
英文文本词与词之间有空格或者标点符号,如果想要对这种普通的英文文本进行分词的话是不需要什么算法支撑,只需暴力拆分即可,即直接通过空格或者标点来将文本进行分开就可以完成英文分词。
假设对于一句英文,利用空格,逗号,句号,问号和感叹号来分割1
2
3
4
5
6
7
8
9
10
11
12
13def tokenize_Entext(text):
tokenize_text = []
for data in text:
tokenize_data = []
for s in data.split('.'):
for s1 in s.split('?'):
for s2 in s1.split("!"):
for s3 in s2.split(","):
tokenize_data.extend(
s4 for s4 in s3.split()
)
tokenize_text.append(tokenize_data)
return tokenize_text
对于中文分词就难得多了.
中文分词
我们想要通过计算机将句子转化成词的表示,自动识别句子中的词,在词与词之间加入边界分隔符,分割出各个词汇。这个切词过程就叫做中文分词.
中文分词存在歧义与分词界限等问题.
中文分词这个概念自提出以来,经过多年的发展,主要可以分为三个方法:
- 机械分词方法;
- 统计分词方法;
- 两种结合起来的分词方法
机械分词方法又叫做基于规则的分词方法:这种分词方法按照一定的规则将待处理的字符串与一个词表词典中的词进行逐一匹配,若在词典中找到某个字符串,则切分,否则不切分。机械分词方法按照匹配规则的方式,又可以分为:正向最大匹配法,逆向最大匹配法和双向匹配法三种。
机械分词方法
正向最大匹配
正向最大匹配法(Maximum Match Method,MM 法)是指从左向右按最大原则与词典里面的词进行匹配。假设词典中最长词是 𝑚m 个字,那么从待切分文本的最左边取 𝑚m 个字符与词典进行匹配,如果匹配成功,则分词。如果匹配不成功,那么取 𝑚−1m−1 个字符与词典匹配,一直取直到成功匹配为止。
逆向最大匹配
逆向最大匹配法( Reverse Maximum Match Method, RMM 法)的原理与正向法基本相同,唯一不同的就是切分的方向与 MM 法相反。逆向法从文本末端开始匹配,每次用末端的最长词长度个字符进行匹配
双向最大匹配
双向最大匹配法(Bi-direction Matching Method ,BMM)则是将正向匹配法得到的分词结果与逆向匹配法得到的分词结果进行比较,然后按照最大匹配原则,选取次数切分最少的作为结果
一般步骤(正向匹配)
算法步骤:
导入分词词典
dic,待分词文本text,创建空集words。遍历分词词典,找到最长词的长度,
max_len_word。将待分词文本从左向右取
max_len=max_len_word个字符作为待匹配字符串word。将
word与词典dic匹配若匹配失败,则
max_len = max_len - 1,然后重复 3 - 4 步骤
匹配成功,将
word添加进words当中。去掉待分词文本前
max_len个字符重置
max_len值为max_len_word重复 3 - 8 步骤
返回列表
words
1 | # 初始最长词长度为 0 |
max_len_word0是词典中词的最大长度1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32sent = text
words = [] # 建立一个空数组来存放分词结果:
max_len_word = max_len_word0
# 判断 text 的长度是否大于 0,如果大于 0 则进行下面的循环
while len(sent) > 0:
# 初始化想要取的字符串长度
# 按照最长词长度初始化
word_len = max_len_word
# 对每个字符串可能会有(max_len_word)次循环
for i in range(0, max_len_word):
# 令 word 等于 text 的前 word_len 个字符
word = sent[0:word_len]
# 为了便于观察过程,我们打印一下当前分割结果
print('用 【', word, '】 进行匹配')
# 判断 word 是否在词典 dic 当中
# 如果不在词典当中
if word not in dic:
# 则以 word_len - 1
word_len -= 1
# 清空 word
word = []
# 如果 word 在词典当中
else:
# 更新 text 串起始位置
sent = sent[word_len:]
# 为了方便观察过程,我们打印一下当前结果
print('【{}】 匹配成功,添加进 words 当中'.format(word))
print('-'*50)
# 把匹配成功的word添加进上面创建好的words当中
words.append(word)
# 清空word
word = []
这种分词的方法缺陷主要在词库.
统计分词方法
目前基于统计的分词方法大体可以分两种方法:
- 语料统计方法
- 序列标注方法
语料统计方法
语料就是我们的自备的文本库
对于语料统计方法可以这样理解:我们已经有一个由很多个文本组成的的语料库
D,假设现在对一个句子【我有一个苹果】进行分词。其中两个相连的字 【苹】【果】在不同的文本中连续出现的次数越多,就说明这两个相连字很可能构成一个词【苹果】。与此同时 【个】【苹】 这两个相连的词在别的文本中连续出现的次数很少,就说明这两个相连的字不太可能构成一个词【个苹】。所以,我们就可以利用这个统计规则来反应字与字成词的可信度。当字连续组合的概率高过一个临界值时,就认为该组合构成了一个词语
序列标注方法
序列标注方法则将中文分词看做是一个序列标注问题。首先,规定每个字在一个词语当中有着 4 个不同的位置,词首 B,词中 M,词尾 E,单字成词 S。我们通过给一句话中的每个字标记上述的属性,最后通过标注来确定分词结果。
在训练时,输入中文句子和对应的标注序列,训练完成得到一个模型。在测试时,输入中文句子,通过模型运算得到一个标注序列。然后通过标注序列来进行切分句子。
在统计学习方法中,可以用于序列标注任务的方法有很多。例如,隐马尔可夫模型,条件随机场等.
Jieba
第三方库 jieba帮助我们解决训练模型得到标注序列的问题.jieba 工具用的是隐马尔可夫模型与字典相结合的方法,比直接单独使用隐马尔可夫模型来分词效率高很多,准确率也高很多.
- 基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图 (DAG)
- 采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合
- 对于未登录词,采用了基于汉字成词能力的 HMM 模型,使用了 Viterbi 算法
分词
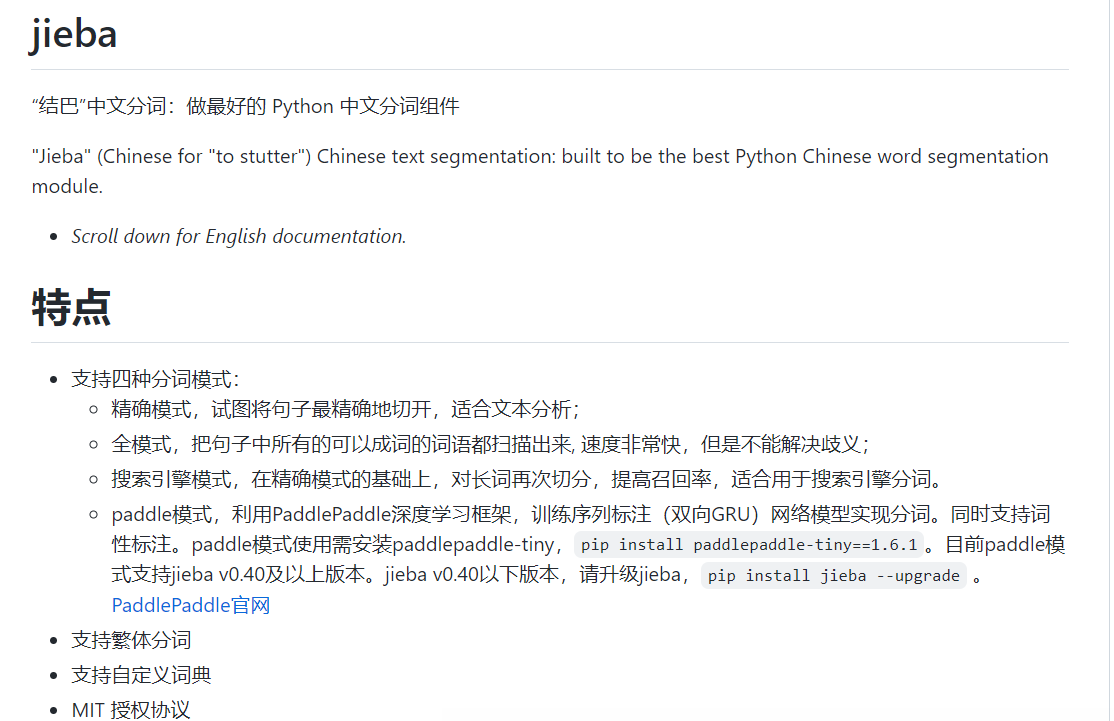
在使用 jieba 进行分词时,有三种模式可选:
- 全模式 将句中可以成词的词语都扫描出来
- 精确模式 将句子精确分开
- 搜索引擎模式 再精确模式下,对长词再次切分

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23import jieba
str = "你好,我是张三.你是谁"
def all():
seg_list = jieba.cut(str,cut_all=True)
# print(seg_list)
print("|".join(seg_list))
# seg_list 无法直接显示,若想要显示,可以下面这样。
# 用 ‘|’ 把生成器中的词串起来显示。
# 这个方法在下面提到的精确模式和搜索引擎模式中同样适用
def pre():
seg_list = jieba.cut(str,cut_all=False)
print("|".join(seg_list))
def search():
seg_list = jieba.cut_for_search(str)
print("|".join(seg_list))
if __name__ == '__main__':
# all()
# pre()
search()
全模式和搜索引擎模式,jieba 会把全部可能组成的词都打印出来。在一般的任务当中,我们使用默认的精确模式就行了,在模糊匹配时,则需要用到全模式或者搜索引擎模式
载入字典
为了解决未分词问题(即词库中没有需要的分词) jieba 允许用户自己添加该领域的自定义词典,我们可以提前把这些词加进自定义词典当中,来增加分词的效果。调用的方法是:jieba.load_userdic()
自定义词典的格式要求每一行一个词,有三个部分,词语,词频(词语出现的频率),词性(名词,动词……)。其中,词频和词性可省略。用户自定义词典可以直接用记事本创立即可,但是需要以 utf-8 编码模式保存。
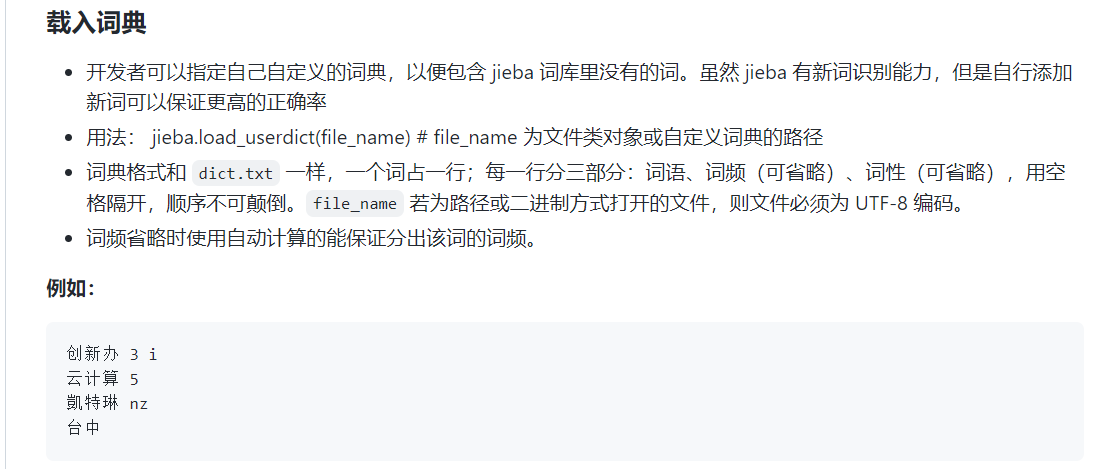
创建txt文件 每一行格式 词语 词频 词性
| 标签 | 含义 | 标签 | 含义 | 标签 | 含义 | 标签 | 含义 |
|---|---|---|---|---|---|---|---|
| n | 普通名词 | f | 方位名词 | s | 处所名词 | t | 时间 |
| nr | 人名 | ns | 地名 | nt | 机构名 | nw | 作品名 |
| nz | 其他专名 | v | 普通动词 | vd | 动副词 | vn | 名动词 |
| a | 形容词 | ad | 副形词 | an | 名形词 | d | 副词 |
| m | 数量词 | q | 量词 | r | 代词 | p | 介词 |
| c | 连词 | u | 助词 | xc | 其他虚词 | w | 标点符号 |
| PER | 人名 | LOC | 地名 | ORG | 机构名 | TIME | 时间 |
除了使用 jieba.load_userdic() 函数在分词开始前加载自定义词典之外,还有两种方法在可以在程序中动态修改词典。
- 使用
add_word(word, freq=None, tag=None)和del_word(word)可在程序中动态修改词典。 - 使用
suggest_freq(segment, tune=True)可调节单个词语的词频,使其能(或不能)被分出来
1 | # suggest_freq |
