课程作业
1.
请自己编写的一个简单C语言例子(至少包括3个C文件、至少一个头文件;含有初始化全局变量、未初始化全局变量、函数内静态变量与局部变量、函数调用、if语句、while语句等),尽量不要包含第三方的头文件,按照预处理->编译->汇编->链接的操作过程,截图分析做成文档,分析源程序与可执行程序Section的对应关系,特别是数据与指令,通过分析阐述编译器的功能。着重分析LLVM的IR与源语句的对应关系。
环境
1 | Ubuntu 20.04.3 gcc 9.3.0 |
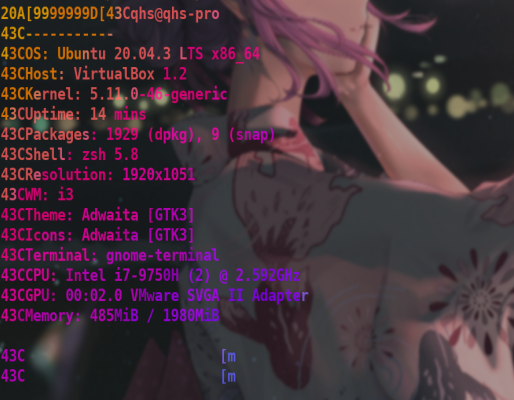
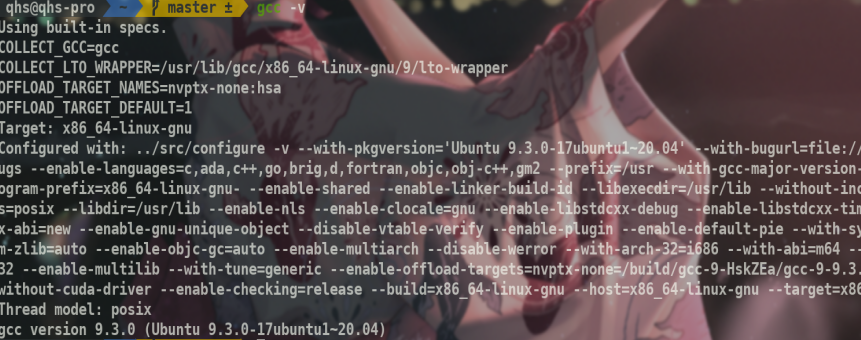
使用GCC
gcc具体使用参考教程.这里大概写一下1
2
3
4gcc -E #预处理
gcc -S #进行编译
gcc -c#进行汇编,获得目标文件
gcc -o # -o本是指定输入文件名,不加参数直接进行链接
注意,-Wall选项可以输出尽可能多的提示信息,建议每次都加上
源文件
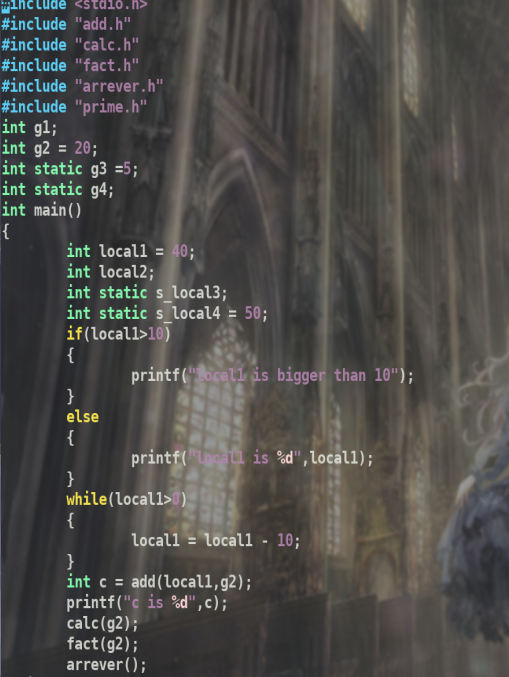
可以看到变量类型涉及到 全局变量,全局静态变量,局部变量和局部静态变量.
同时由引入的函数头文件,while和if结构. 先进行单个文件由.c->.i->.S->.o->可执行文件的过程.从中分析每个过程的变化以及一些信息.
预处理
1 | gcc -E -o main.i main.c -Wall |
可以看到main.c引入了一些头文件,主要是stdio.h,我们可以查看.i文件大小

可以看到由原本467B变为17KB,可见文件中引入了许多信息,都是由宏处理的.
所谓预处理操作,主要是处理那些源文件和头文件中以 # 开头的命令(比如 #include、#define、#ifdef 等),并删除程序中所有的注释 // 和 / … /
这一步没有太多要说的
编译
1 | gcc -S -o main.S main.i -Wall |
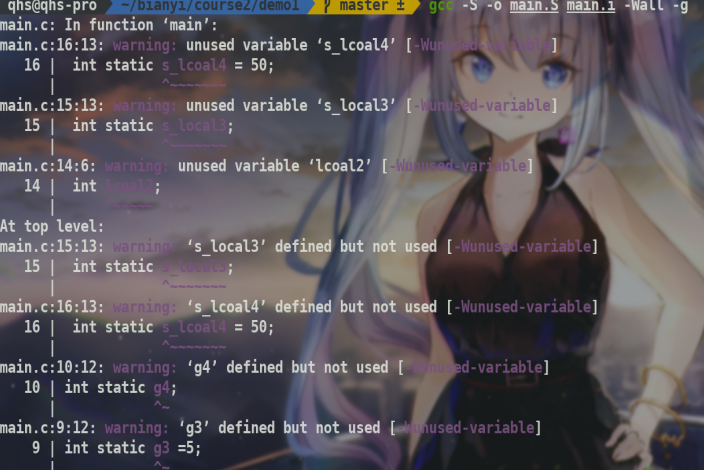
可以看到报了几个warning,这是因为局部变量如果没有初始化,它们是不会在.bss段的,而是在栈中1,代码段中(局部变量是函数的变量,而函数在代码段中2),也就是程序运行过程随着调用函数开栈,随着栈帧的创建而创建,随着函数结束生命周期也就结束了.(在当前gcc版本下),同时如果定义了但没有使用也会报warning.如果加了-O优化这种代码很可能被优化处理.
值得注意的是,代码段中也会存储一些const值.
C语言中定义的字符串常量
const型常量:C语言中const关键字用来定义常量
我们可以根据编译得到的汇编代码更加详细地查看.
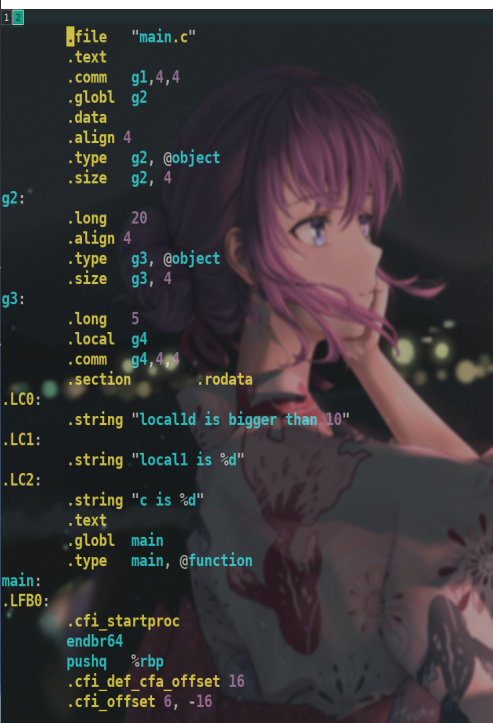
由于main.c文件写得有点复杂,这里挑重点说一下.
.file标识文件名 .text就是一个熟悉的重要的section,就是代码段.存着函数以及一些常量(比如c语言的字符串和const常量)
我发现这里有些符号没遇到过,网上搜索一番3,而且貌似全局未初始化变量并没有直接放在.bss段的.
.comm表示的就是未初始化的全局变量.
可以得知g1是全局变量,因为是.comm(这与.lcomm都在链接后分配在.bss),
g2为20为全局变量(.global),.long 20.g3值为5,但可以看出其没有了.global,推测这是因为加了static导致,同时因为其进行了初始化,所以不会加在.bss段,即这里不会在.comm。
(.comm是未初始化全局变量,.lcomm是静态全局变量)可以这么简单理解
可以看出g4就是全局静态变量(.local)且未进行初始化.
总结一下
g2和g3变量在*.S文件中差别是g2有 .global g2表示全局(全文件的作用域) g3没有.
表示全局变量加上static导致的作用域减小.即g2可以在其他文件中使用extern使用.
g2和g3都有type @object,都分配在.data段.表示经过了初始化,如果加了static作用域受限,没有.global.
g1和g4差别是g1是.comm,g4是.local .comm即.lcomm表示g1是未初始化的全局变量,链接后在.bss段,而g4是静态的未初始化全局变量,同理其作用域也是所在的文件,编译后也分配在.bss段.
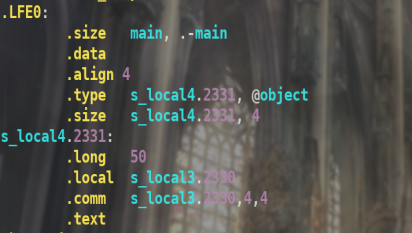
而main函数中的变量,比如local1和local2是在栈中,在汇编代码中没有相关符号.
而两个静态局部变量 s_local3应该分配在.bss段,s_local4分配在.data段,因为其初始化过了.
全局未初始化变量没有被放到任何段,而是作为未定义的COMMON符号。这个和不同语言、编译器实现有关,有的编译器放到.bss 段,有的仅仅是预留一个COMMON符号,在链接的时候再在.bss段分配预留空间。编译单元内部可见的静态变量,比如在上述中加上static的 static int global_static_var则确实被放到了.bss,是因为这个仅仅是编译单元内部可见
对于全局变量来说,如果初始化了不为0的值,那么该全局变量则被保存在data段,如果初始化的值为0,那么将其保存在bss段,如果没有初始化,则将其保存在common段,等到链接时再将其放入到BSS段。关于第三点不同编译器行为会不同,有的编译器会把没有初始化的全局变量直接放到BSS段
.LC0等这些存储着字符串,这是固定值.还有一些汇编符号4.值得注意的是,尽管这个汇编代码中没有.bss,但是.data中包含了.bss,.comm或.lcomm表示这个变量分配在.bss段
从这个汇编代码得到的信息不太够.

可以看到这里有movl $40 -8(%rbp)这其实就是int local1=40表示局部变量初始化.在这之前有1
2
3pushq %rbp
movq %rsp %rbp
subq $16 %rbp
这其实就是栈帧的开始,表明局部变量(不是静态)分配在栈中(.data),而静态变量在编译时就有了.
汇编
1 | gcc -c -o main.o main.c -Wall -g |
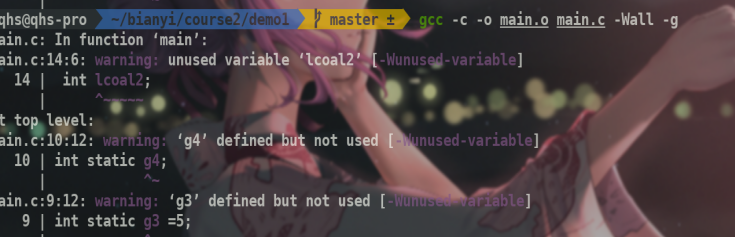
得到目标文件
注意格式relocatable,表示没有进行重定位.直接运行是有问题的,需要进行链接.
objdump
使用objdump对于目标文件以及可执行文件进行反编译8.1
objdump -f #file headers
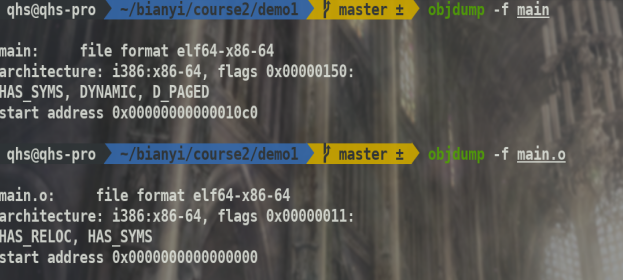
可以知道main.o目标文件是需要重定位且开始地址还未定.
main可执行文件程序开始地址已经定了.1
objdump -x #查看所有的头信息(文件头,section头,程序头(*.o文件没有程序头),符号表,重定位信息)
对于main.o文件
section头
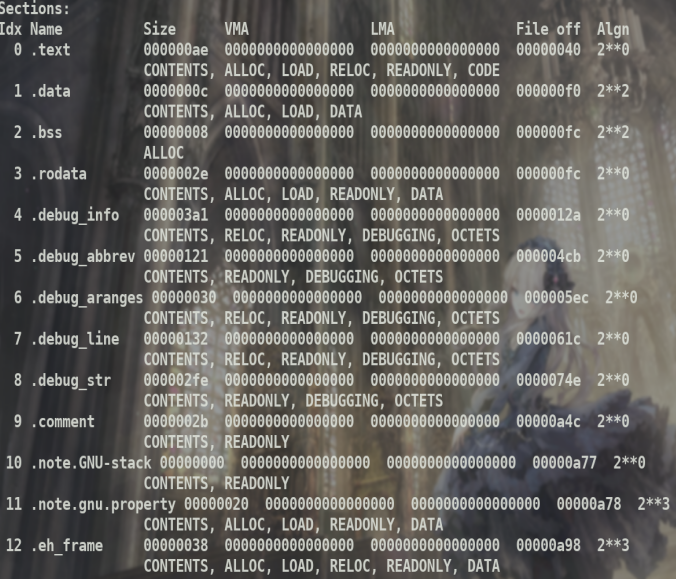
重点关注.text .data .bss .rodata.由于没有重定位,逻辑地址都是0
.text代码段,只读 .data数据段初始化全局变量(不管是否是static,如果加了static,则作用域减小). .bss未初始化段,包含未初始化的全局变量或者静态变量.
符号表

通过符号表可以更方便地查看某个量分配在哪个section.
由于这是main.o文件,没有进行链接,可以观察到后面几个函数都是und(undefined).
g3在.data段,g4在.bss段.s_local4在.data段,s_local3在.bss段
后面还有重定位记录,但是由于是main.o这些地址不是最终地址.1
2
3objdump -s #查看所有内容 二进制
objdump -d #反汇编 .text
objdump -D #反汇编所有
查看 .data段
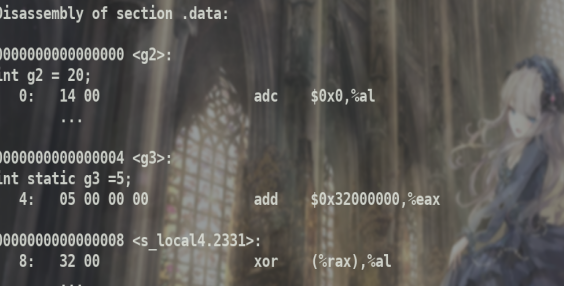
可以看见.data都是初始化了的静态变量或全局变量.
局部变量加了static初始化后分配在.data
查看.bss
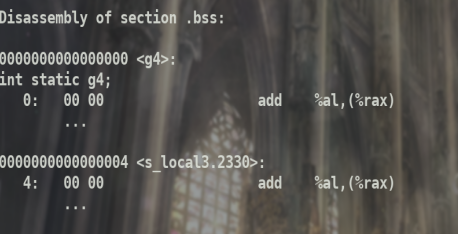
.text段内容是main函数中的内容,局部变量在这.
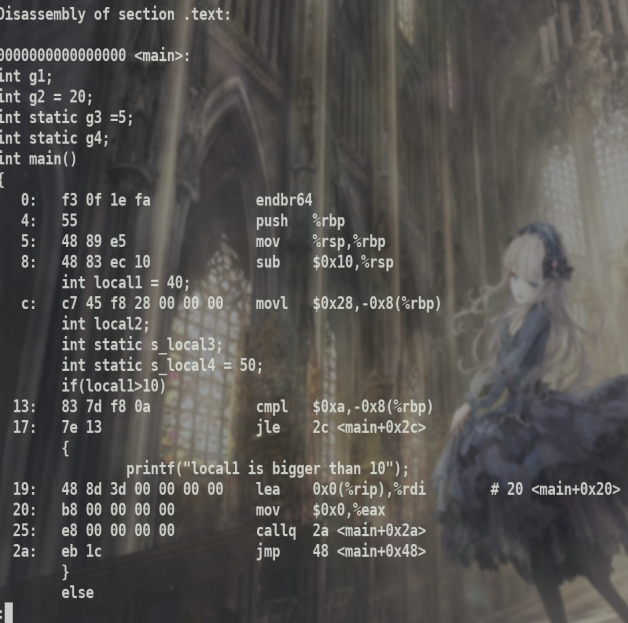
将main.o反汇编后与main.S比较,可以看出main.S中值表示是十进制的,而反汇编后是16进制.
call指令跳转,在*.S中,直接指定跳转函数名,反汇编是指令相对地址
同时,如果使用.bss或.data的内容,会使用%RIP(指令地址)+偏移获得值.
在*.S文件中同样的使用符号表示偏移,即相对地址.
具体可以看这个例子
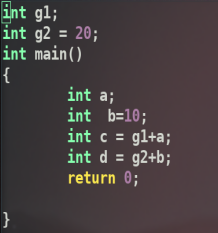
可以看到,当把g1,g2全局变量(分配在.data或.bss段)进行运算时,利用%rip作为基址,变量名为偏移.同时可以看出 -4(%rbp)是d,-8(%rpb)是c,-12(%rbp)是a,-16(%rbp)是b.
gcc -c得到目标文件再反汇编可以看到
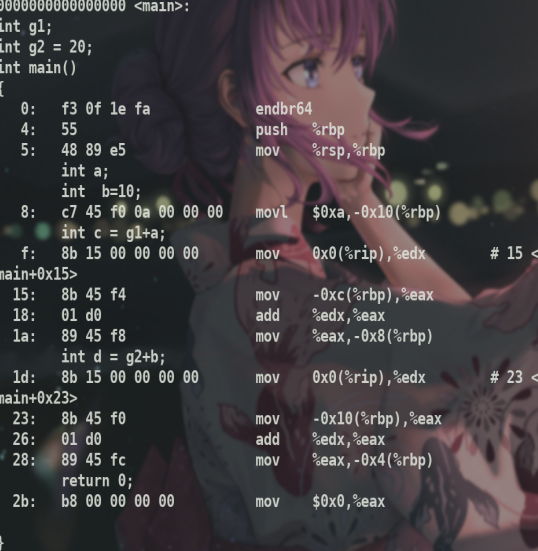
可以看到这里地址是0x0(%rip),为什么是这样呢?推测这是因为目标文件没有进行重定位,所以这里的地址都是0,需要链接后才是真正的地址.
同时发现符号表中g1并没有在.bss段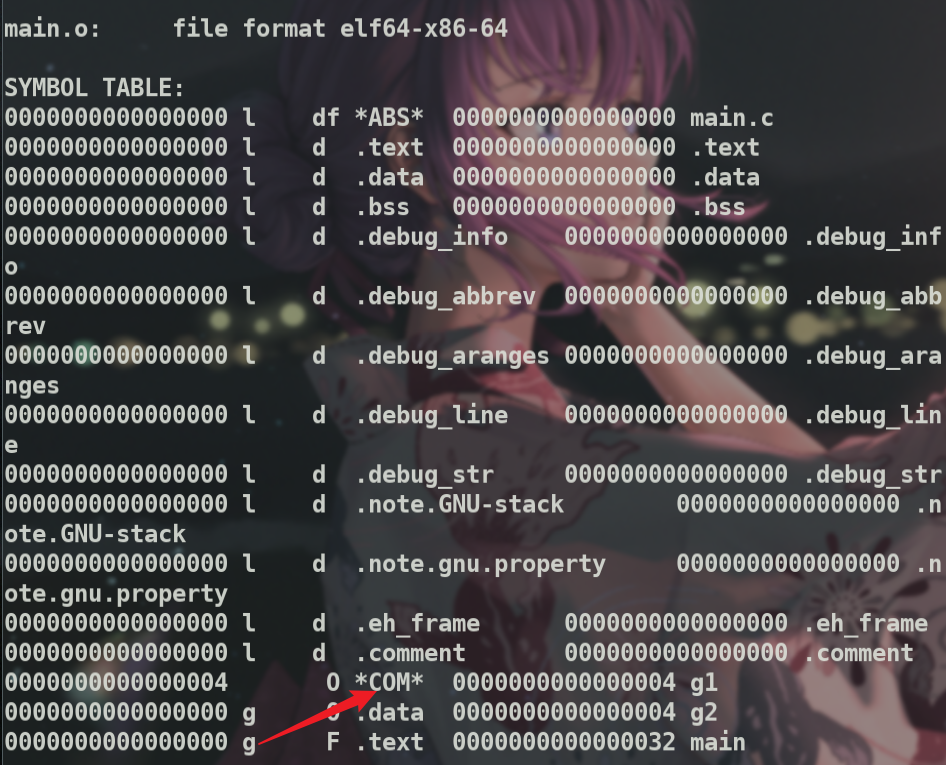
同时.bss段的大小也是0
但是g1作为未初始化的全局变量,分配在.bss段,按理说.bss段大小不应该为0.这表明需要在链接后才能查看bss段大小(若有不对之处还望指出).
接下来分析这个程序的可执行文件的反汇编结果.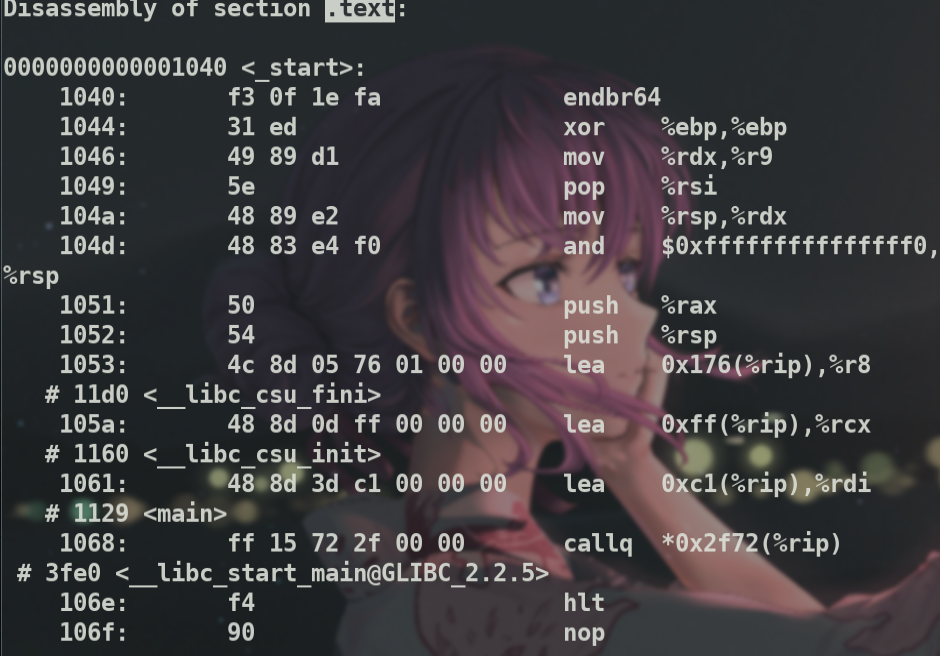
值得注意的是,链接后得到的文件.text段内容增加了一些动态库的信息.重定位文件*.o.text段开头简简单单的就是一个main函数.现在开头有一些初始化函数.
找到main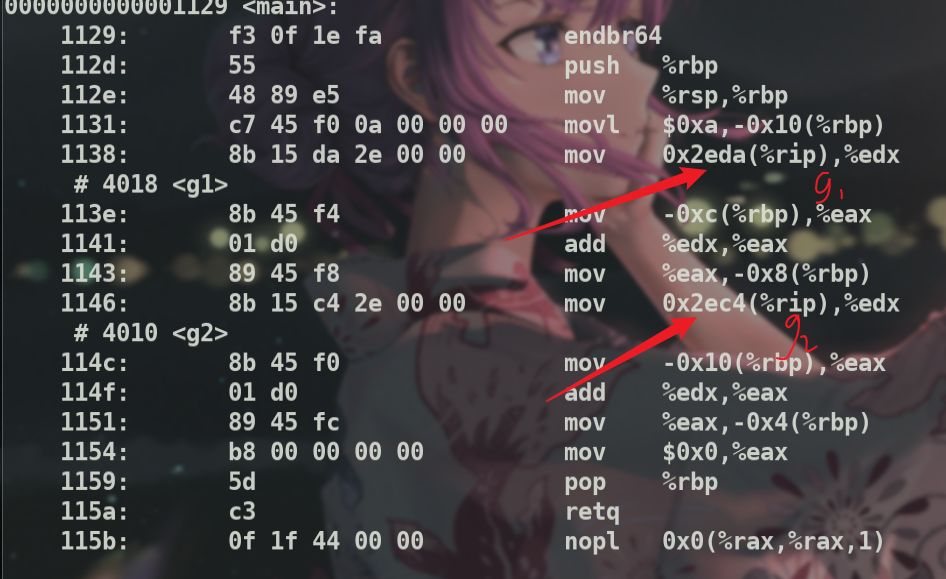
可以明显看出g1,g2这种分配在.data或是.bss段的值由%rip作为基址(需要注意的是当我们执行一条指令时%rip的值已经是下一条指令的地址了)取引用.
0x113e+0x2eda = 0x4018
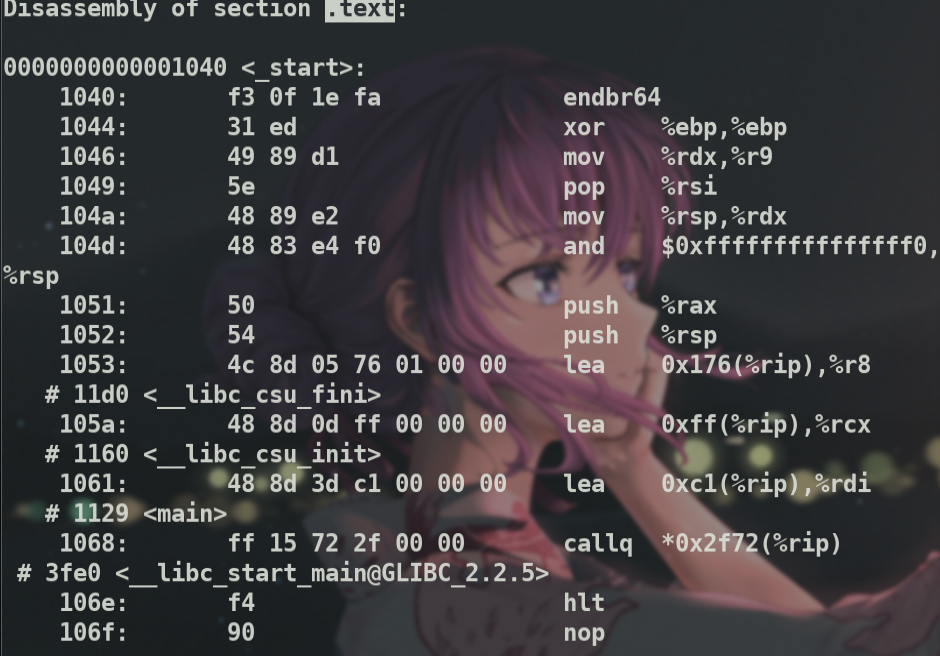
根据得到的地址找到g1,发现这个地址下啥都没有,表明.bss段只记录地址.而值在每次运行时由os清零5.
114c+2ec4 = 4010
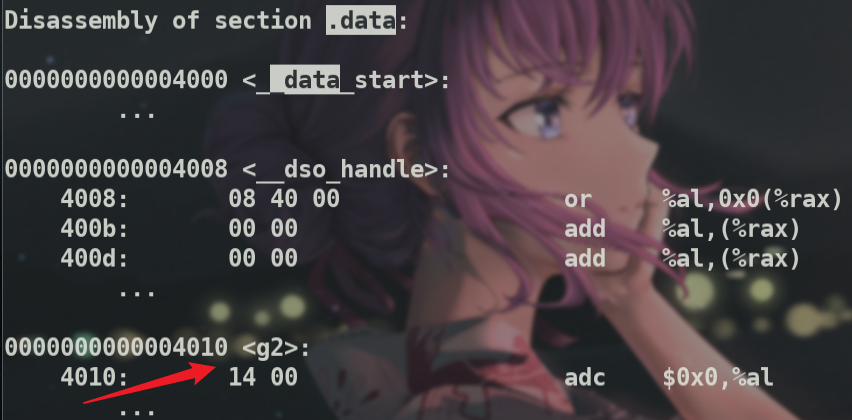
可以在.data段下看到这个地址即对应的值 g2值为0x14.比较有意思的是,因为g2是4个字节.
所以表示为1400,然后因为是小段存放,所以低字节上的14先放,所以成了14 00,objdump就将这个14 00编码成了汇编代码,但是后面的adc $0x0,%al并不是正确要表达的意思.
call调用函数类似,在汇编代码中,call的调用是按照函数名称的,不是按照地址的.
在目标文件中(可重定位文件),call的相对地址是%RIP的值,即下一条指令的地址,显然这是有问题的.不符合实际情况.
在执行文件中偏移地址+%RIP,下一条指令地址加上偏移,这里不细说了.可以在.data中
注意在可重定位文件中,由于没有链接,用的函数是UND,且未初始化的全局变量是COM.
查看调用函数时跳转地址.
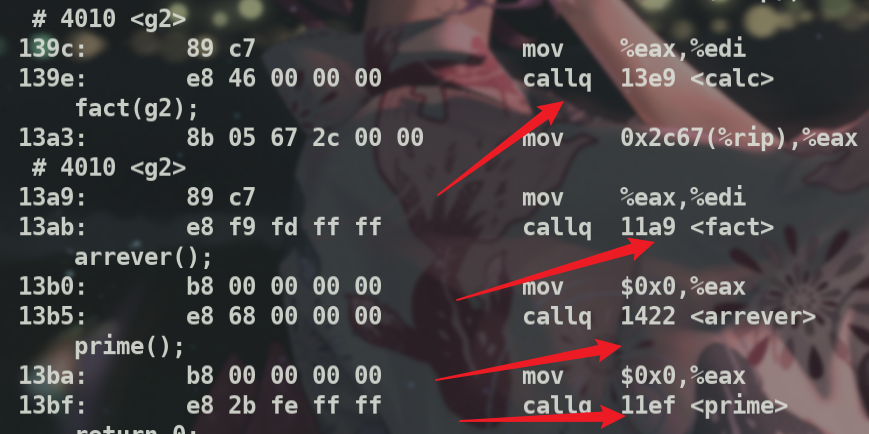
在符号表中查找,

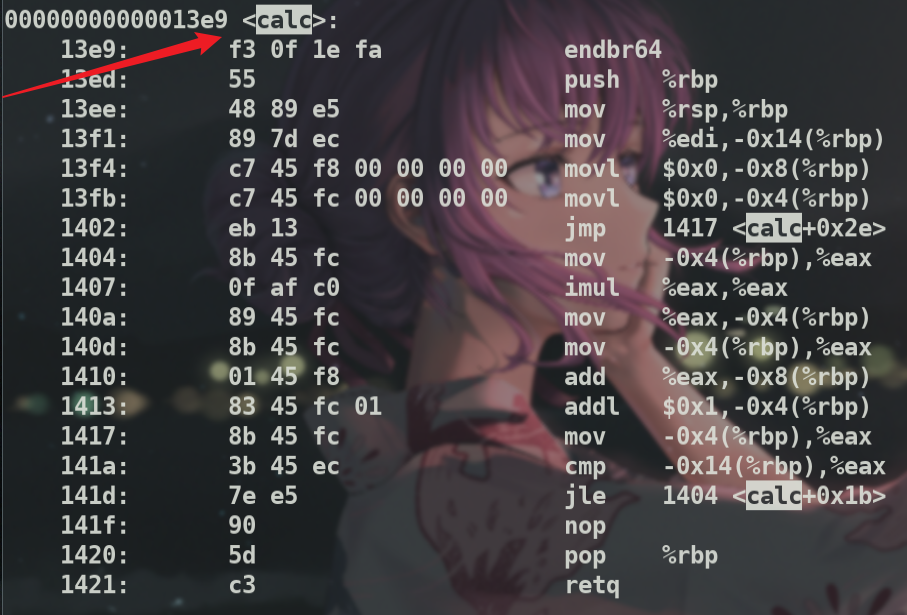
可以看到函数地址 0x13e9
也可以进行反编译,查看这个函数符号的代码.
到这里基本的变量和符号(section和函数符号)就分析完了.
下面分析一下if和while得到的汇编代码.
if代码
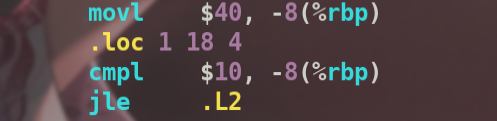
可以看到40与10比较,
cmpl指令将两个操作数相减,但计算结果并不保存,只是根据计算结果改变eflags寄存器中的标志位。如果两个操作数相等,则计算结果为0,eflags中的ZF位置1.
通过标志跳转.L2,再次体现了汇编代码通过符号跳转这个概念.
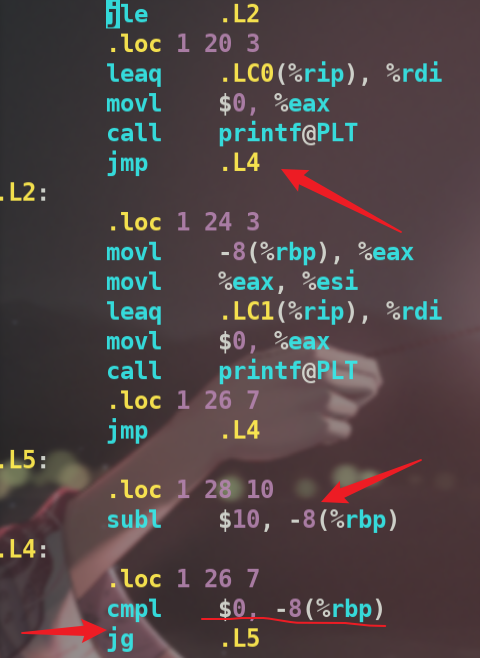
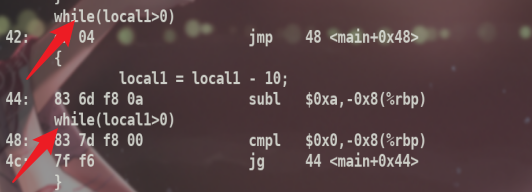
可以看到进入.L4后,与0比较,如果大于就跳转到.L5,.L5就是while中的语句,值减去10,再进入.L4进行判断.
分析重定位文件.
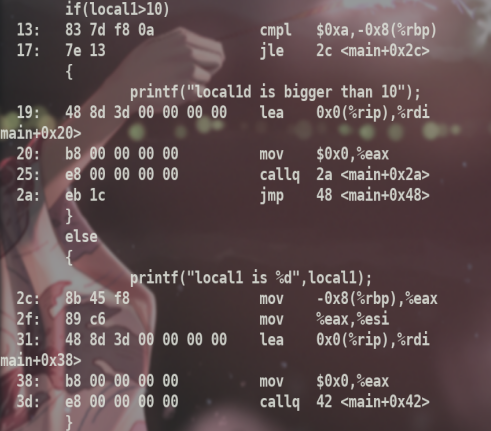
汇编代码中通过jle .L2符号跳转,而重定位文件中,通过函数内偏移,0x2c是跳转的对应的地址,因为是main.o目的文件,没有经过链接,没有重定位,所以地址都是相对的.链接后地址会变化.
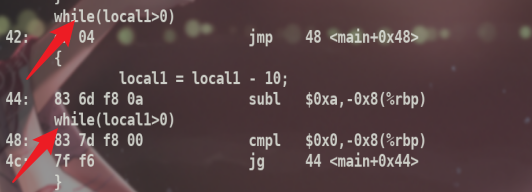
可以看到在while语句中,结束时会再次判断,根据结果再选择跳转.跳转地址是main内相对地址
对于可执行程序,反汇编得到.text段.
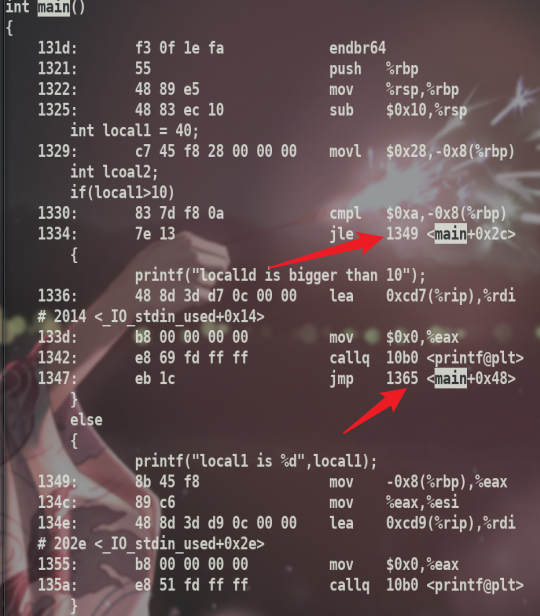
可以看到相对地址是没有变的,这表明在一个函数内的if,while等跳转遵循相对跳转,且相对地址没有变化,基址是函数地址.
如果是调用函数或者使用全局变量就是利用%RIP作为基址,在.data,.bss,.text段中找到数据.
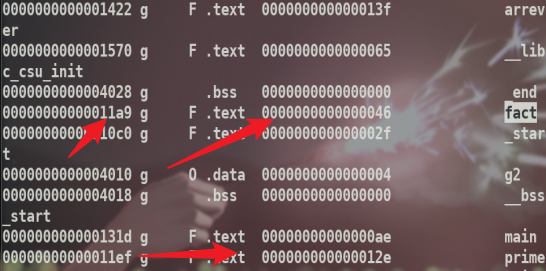
可以看见这些函数在.text段,可以得到它们的地址和大小.
分析ELF文件既可以用objdump也可以用readelf,不过这两个命令有一些差别.
使用1
2man readelf
man objdump
可以详细查看两者的命令参数.1
readelf -S #也可以查看section header
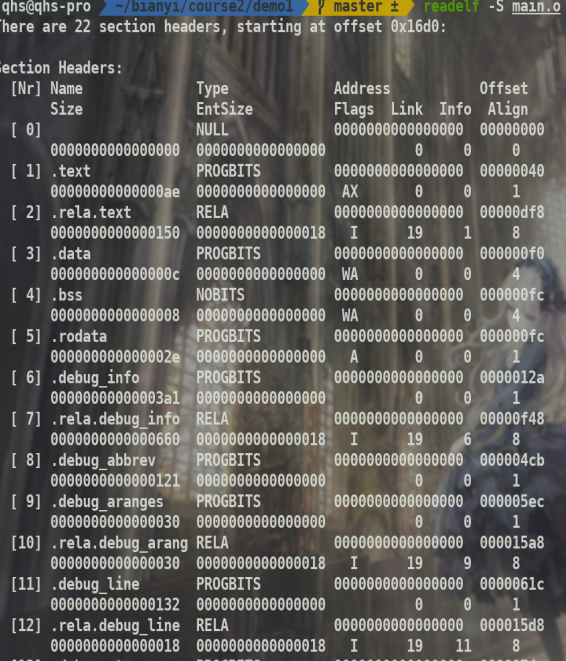
同时readelf -h可以查看文件头,从中可以知道section header和program header.
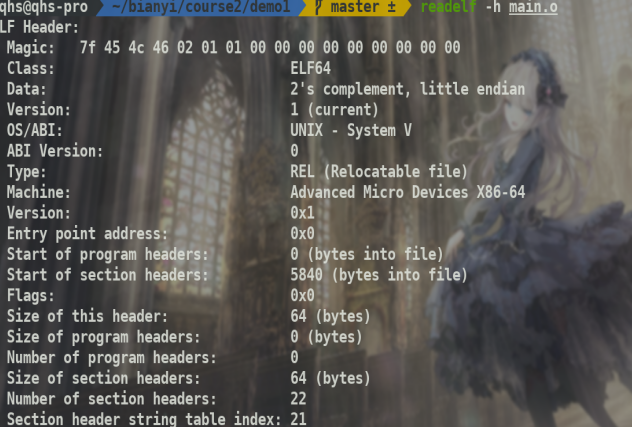
可以看出main.o是没有程序头的.

上图是ELF文件视图
下面对可执行文件main分析
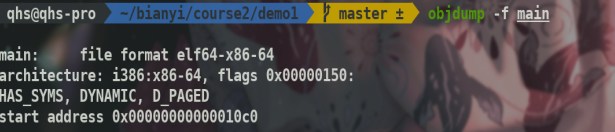
可以看到有起始地址,而且是dynamic链接.
由于文件链接了很多其他文件,内容较多.1
objdump -x main #查看所有头信息
可以看到多个了program header

其中有段的地址.
此外由于链接了一些动态库,出现了dynamic section,不过这相对来说不重要.
关注Sections
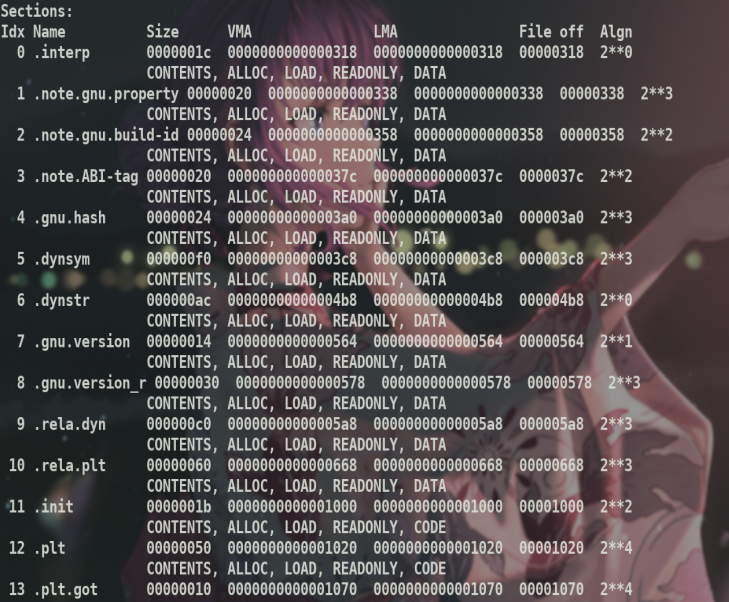
可以看到已经有了地址和大小
另外也有符号表的信息

注意到重定位信息已被删去9
函数的调用和返回
这方面的内容我在做cmu的炸弹实验已经了解过了(自我认为).可以查看网站上的之前文章.
现在在windows上直接使用MinGW.
源文件很简单
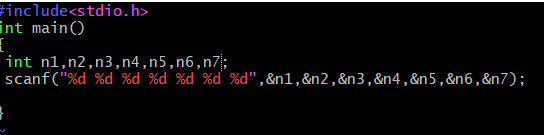
scanf函数调用了八个参数,一个字符串以及7个数.
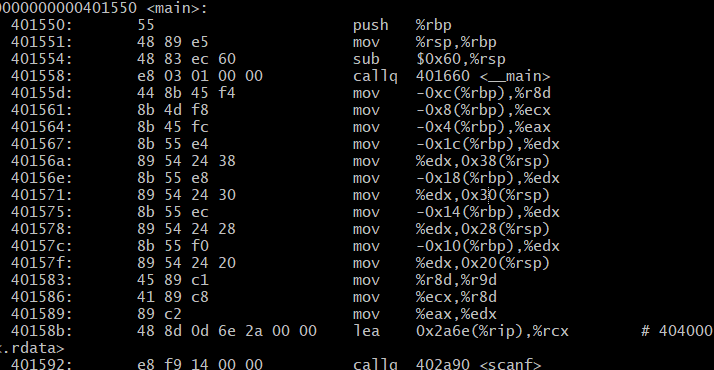
在.rodata中的就是字符串,利用%rcx传参,n1在%eax上.
有意思的是在Linux的gcc上并不是这样
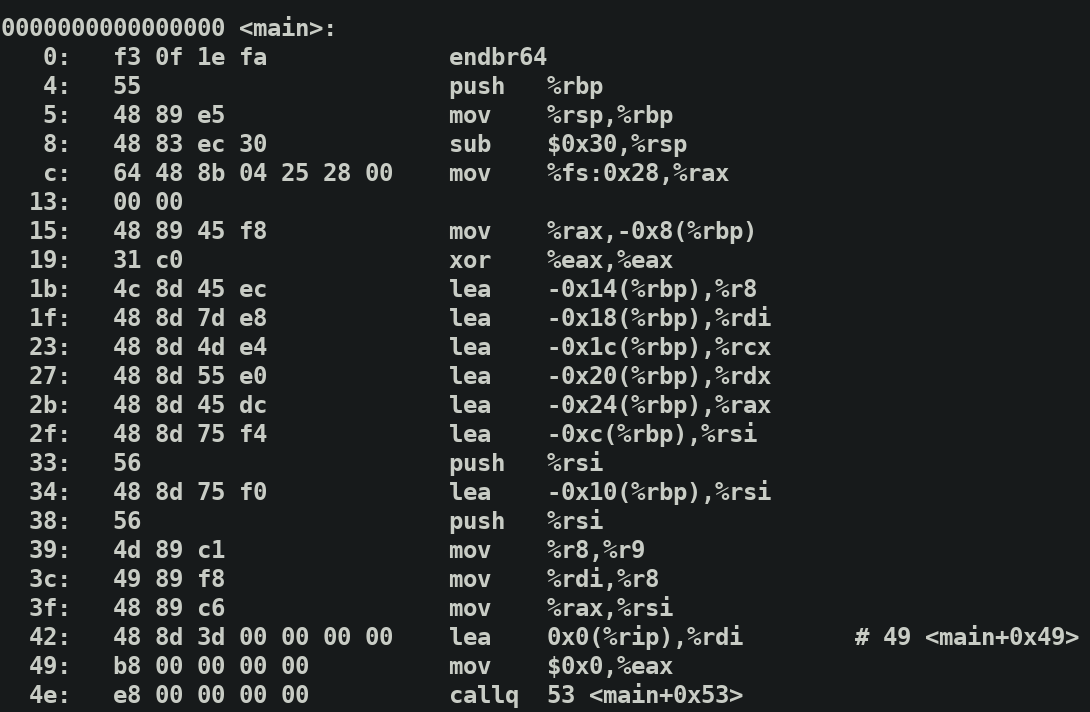
鉴于这并不直观,看一下另一个源文件。
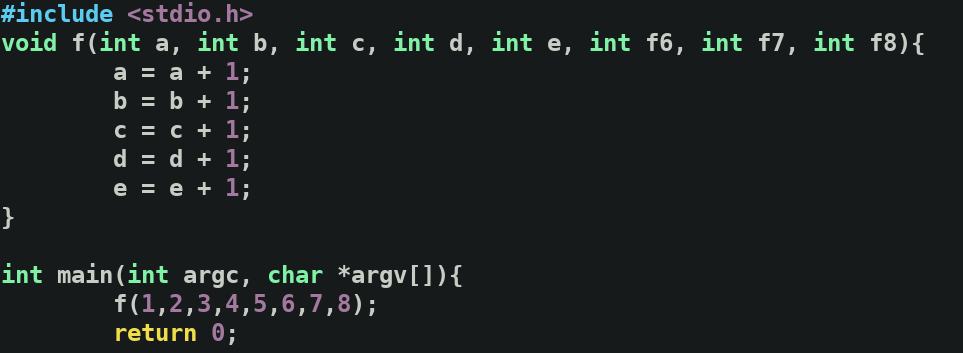
反编译得到结果
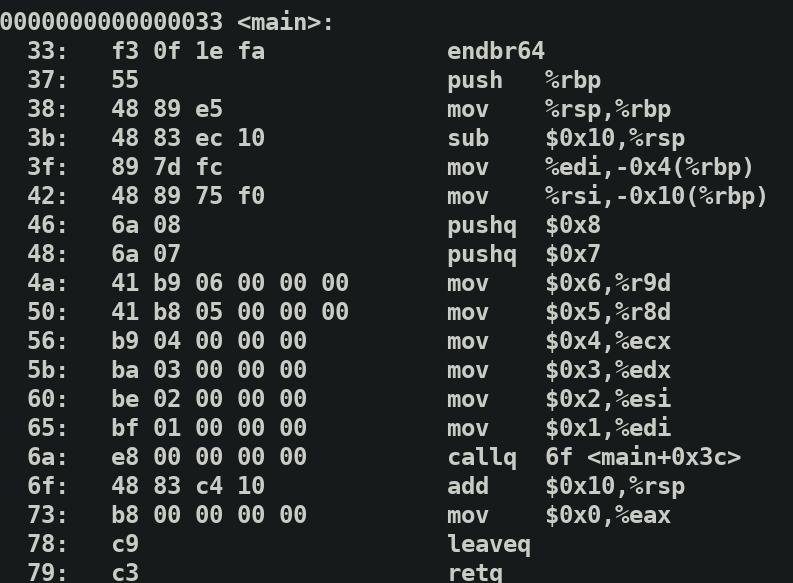
我们传参是1,2..8. 其首先从最后一个参数开始,有六个寄存器用于传参(64位下),多余的传入栈中.
在这里push两个值,剩余的六个值用寄存器传参.即以$rdi,%rsi,%rdx,%rcx寄存器的顺序
在这里,值6直接传到%r9d,注意%r9d就是低32位的%r9.
同理,其余值也依次传到寄存器中.
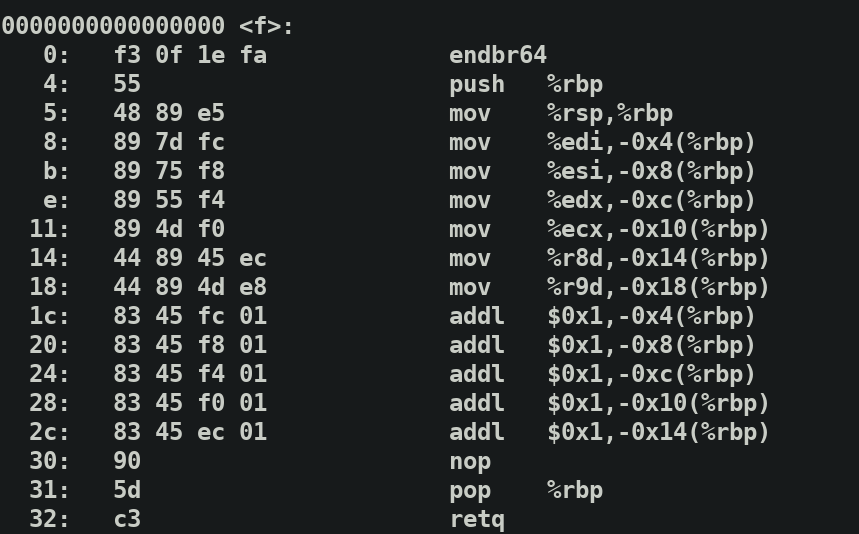
可以看到函数中先开栈,然后依次将1,2..的值从寄存器中使用.
寄存器这个网站简洁分析了各个寄存器.
结论:当参数个数小于等于6个时,使用寄存器rdi,rsi,rdx,rcx,r8,r9,从第7个参数开始通过栈传递,顺序为从右往左入栈。
LLVM
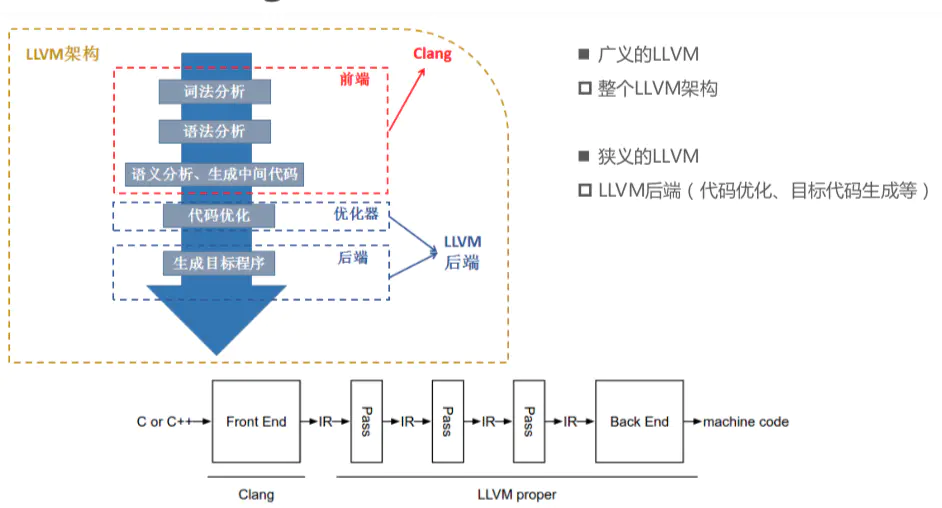
传统的编译器是前端,优化(可选),后端.在某些书中也称为analysis和synthetic.

LLVM本身并不是一个编译器,它是一种架构.
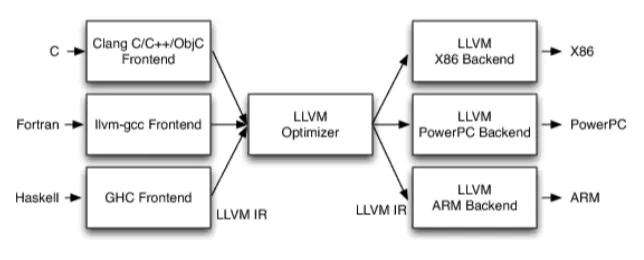
编译器根据前端生成的AST(抽象语法树)得到一种中间语言,对IR进行优化后由后端生成对应的机器代码.
IR可以说是集中体现了这款编译器的特征—-他的算法,优化方式,汇编流程等等,想要完全掌握某种编译器的工作和运行原理,分析和学习这款编译器的中间语言无疑是重要手段,另外,由于中间语言相当于一款编译器前端和后端的“桥梁”
对于现代编译器来说,编译器前端和后端分别指分析输入源语言和生成目标平台汇编代码的两编译阶段,大部分现代编译器在前端和后端之间会有个中间表示层。有了一个设计良好的中间表示,有m种前端编程语言(C\C++、Fortran、Ada、Java等)和n种后端平台(x86、MIPS、Sparc、ARM等)的编译器设计,这样就减少了为了设计m中语言和n个平台从而设计m*n个编译器设计
同时LLVM可以提供优化算法,在优化时可以将其提供的算法链接进来.
GCC的中间语言RTL形式.
gimple和RTL是gcc用来表示指令的两种形式。因此每个基本块都包含有两组指令序列,一组是gimple指令,一组是RTL指令。每个函数将首先被gimple化,此时基本块里只包含gimple指令,之后由gimple生成RT
中间表示RTL:RTL叫做“寄存器转移语言”(Register Transfer Language),它是以一种虚拟寄存器(pseudo register)的方式来叙述计算机行为的语言。RTL 是一种接近机器指令的语言,既有指令序列组成的内部形式,又有机器描述和调试信息组成的文本形式。
对于GCC
gcc的设计并不是教科书般的,它的前端和后端也并没有那么明确.
使用命令1
gcc -S fdump-tree-all main.c
得到一大堆文件.
这些都是中间文件,我们看看cfg和ssa.
我的源文件1
2
3
4
5
6
7
8
9
10
11
12//main.c
int g1 = 10;
int g2;
int main()
{
int a = 10;
int c;
c = add(a,g1);
c = ADD(c,g2);
return c;
}
CFG文件
cfg是控制流图.
每个函数翻译为GENERIC的语法树之后,会进行gimplification,在这一过程中函数的语法树被翻译为了控制流图的形式。每个函数对应一个控制流图
可以看到有很多cfg中间文件,应该是经过了多次处理.
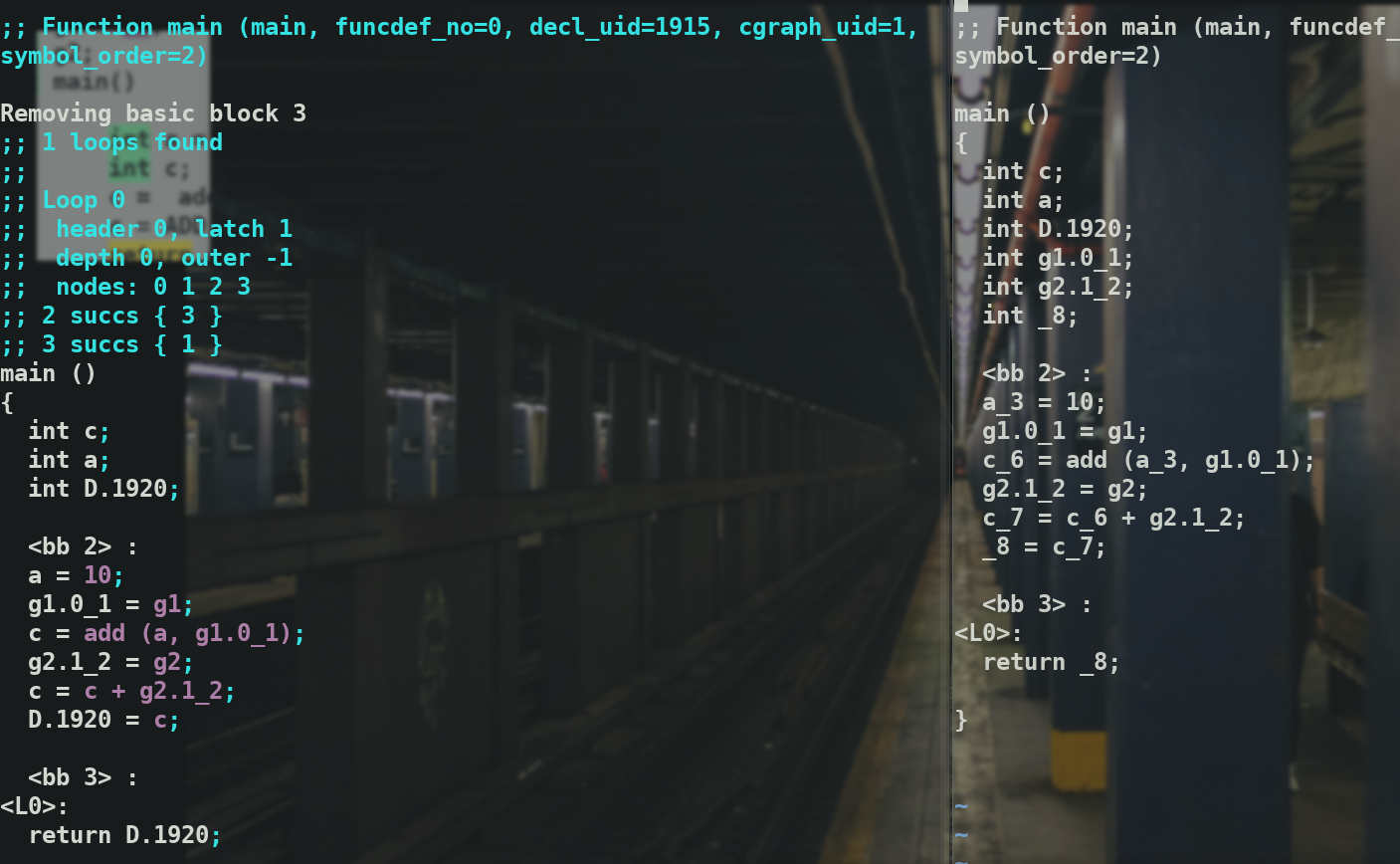
SSA文件
SSA 形式的 IR 主要特征是每个变量只赋值一次。相比而言,非 SSA 形式的 IR 里一个变量可以赋值多次。为了得到 SSA 形式的 IR,起初的 IR 中的变量会被分割成不同的版本(version),每个定义(definition:静态分析术语,可以理解为赋值)对应着一个版本.
把程序转换为 SSA 形式,最简单的方法就是将每个被赋值的变量用一个新的变量(版本)来取代,同时将每次使用的变量替换为这个变量到达该程序点的“”版本”
可以看到有两个ssa中间文件

值得一提的是前面这个ssa文件与最新的cfg文件是相同的.而这个release版的ssa文件只增加了一些东西

这表明ssa过程并没有改变什么(当然只是针对我这个源文件而言)
对于gcc的中间语言就不做分析了.
对于clang
以LLVM为后端的是苹果的clang编译器,其作为前端10.
clang优点
编译速度快:在某些平台上,Clang的编译速度显著的快过GCC(Debug模式下编译OC速度比GGC快3倍)
占用内存小:Clang生成的AST所占用的内存是GCC的五分之一左右
模块化设计:Clang采用基于库的模块化设计,易于 IDE 集成及其他用途的重用
诊断信息可读性强:在编译过程中,Clang 创建并保留了大量详细的元数据 (metadata),有利于调试和错误报告
设计清晰简单,容易理解,易于扩展增强
在Linux或者其他平台上需要自己安装.苹果上应该是自带的.
LLVM 工具链下载 · GitBook (buaa-se-compiling.github.io)1
2sudo apt-get install llvm
sudo apt-get install clang
Ubuntu 20.04.
继续用刚才的源程序分析.1
clang -emit-llvm -S -o main.ll main.c

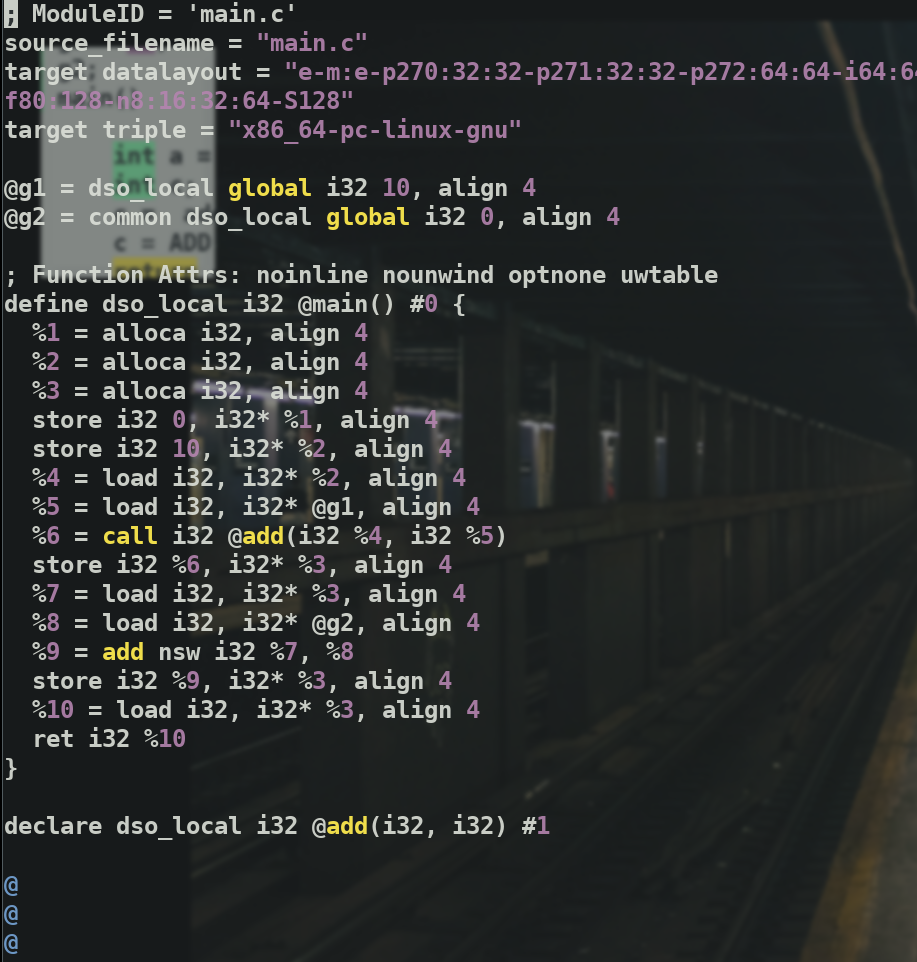
下面来分析一下这个IR代码.
arget triple与target datalayout是程序的标签属性说明align
字段描述了程序的对齐属性;dso_local是变量和函数的的运行时抢占说明符` dso_local 是一个Runtime Preemption,表明该变量会在同一个链接单元内解析符号; 开头的字符串是 LLVM IR 的注释
根据源程序我们知道g1,g2是全局变量.且g1进行了初始化,g2没有所以分配在.bss段
在ll文件中 所有的全局变量都以 @ 为前缀,后面的 global 关键字表明了它是一个全局变量.
i32显而易见表示32位整数.后面跟着值. align表示对齐字节数.
common表示的是未初始化的全局变量.
这几行语句就是声明与初始化全局变量1
2int g1 = 10;
int g2;
对于main函数1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17define dso_local i32 @main() #0 {
%1 = alloca i32, align 4
%2 = alloca i32, align 4
%3 = alloca i32, align 4
store i32 0, i32* %1, align 4
store i32 10, i32* %2, align 4
%4 = load i32, i32* %2, align 4
%5 = load i32, i32* @g1, align 4
%6 = call i32 @add(i32 %4, i32 %5)
store i32 %6, i32* %3, align 4
%7 = load i32, i32* %3, align 4
%8 = load i32, i32* @g2, align 4
%9 = add nsw i32 %7, %8
store i32 %9, i32* %3, align 4
%10 = load i32, i32* %3, align 4
ret i32 %10
}
可以看出 main函数返回值是一个32位整数(就是c语言中的int).
ret i32 %10表明返回一个值存储在%10(类似寄存器),其类型为int.
一个函数定义的最简单的语法形如
define + 返回值 (i32) + 函数名 (@foo) + 参数列表 ((i32 %a,i32 %b)) +函数体 ({ret i32 0})
这里的 #0 与main.ll中靠后的attributes #0 = ...是对应的,他们被用来给函数加上特定的标记,例如是否是能够被内联。
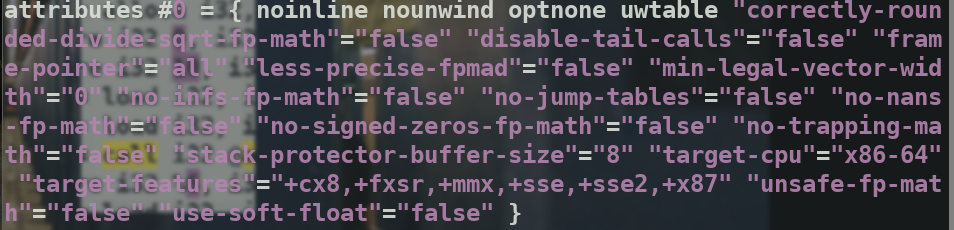
表示的是main函数的特性,比如noinline是不进行内联.说实话,这里有点复杂而且没必要进一步阐述了.可以查阅官方文档LLVM Language Reference Manual — LLVM 15.0.0git documentation
接下来分析main函数内部1
2
3
4
5%1 = alloca i32, align 4
%2 = alloca i32, align 4
%3 = alloca i32, align 4
store i32 0, i32* %1, align 4
store i32 10, i32* %2, align 4
alloca表示分配空间,i32类型 4字节对齐1
以 % 开头的符号表示虚拟寄存器,你可以把它当作一个临时变量(与全局变量相区分),或称之为临时寄存器
其余同理.
store i32 0表示将0存入%1. i32*表示i32类型内存的值,是一个地址.类似指针的感觉.
store i32 10类似将10存入另一个寄存器.
这几行语句类似main函数中1
2int a = 10;
int c;1
2
3
4
5
6
7%4 = load i32, i32* %2, align 4 //1
%5 = load i32, i32* @g1, align 4 //2
%6 = call i32 @add(i32 %4, i32 %5) //3
store i32 %6, i32* %3, align 4 //4
%7 = load i32, i32* %3, align 4 //5
%8 = load i32, i32* @g2, align 4 //6
%9 = add nsw i32 %7, %8 //7
第一行表示 从 %2(i32*)中 load 出一个值(类型为 i32),这个值的名字为 %4
第二行表示将全局变量g1赋值给%5. 第三行表示执行call函数.call函数声明在后面,顺便实参是%4与%5.
第四行表示将上一行得到的结果存入%3. 第5行表示将%3结果load出给%7.
第六行表示将全局变量g2赋给%8. 关于nsw查阅官方文档.表示不进行有符号转换.即无符号运算.
nuwandnswstand for “No Unsigned Wrap” and “No Signed Wrap”, respectively. If thenuwand/ornswkeywords are present, the result value of theaddis a poison value if unsigned and/or signed overflow, respectively, occurs.A poison value is a result of an erroneous operation.
所以第七行表示将%7和%8值相加赋给%9.
接着将%9的值存入%3.再将%3的值load给%10.然后返回%10.1
2
3store i32 %9, i32* %3, align 4
%10 = load i32, i32* %3, align 4
ret i32 %10
这样main函数中代码说明完了.1
declare dso_local i32 @add(i32, i32) #1
表示声明函数add. add有两个参数均为i32类型.1
2
3
4
5!llvm.module.flags = !{!0}
!llvm.ident = !{!1}
!0 = !{i32 1, !"wchar_size", i32 4}
!1 = !{!"clang version 10.0.0-4ubuntu1 "}
这些就是一些信息了,不用在意.
LLVM中也有SSA.
在 LLVM IR 中,变量是以 SSA 形式存在的,为了生成正确的 LLVM IR 并实现我们的实验,对 SSA 的知识是必不可少的,LLVM IR 的代码有两种状态,分别是存取内存形式的 IR 以及带有
phi指令的 SSA IR
我们其实可以看出LLVM的IR与汇编代码还是有很大类似之处的,不过IR需要SSA.即程序中的每个变量都有且只有一个赋值语句,这是比较大的差别.
再看一下分支和循环语句的IR.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
int g1 = 10;
int g2;
int main()
{
int a = 10;
int c;
if(a<5)
{
c = 2;
}
while(a>5)
{
a = a-5;
}
return 0;
}
看一下得到的ll文件1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32define dso_local i32 @main() #0 {
%1 = alloca i32, align 4 //分配空间i32
%2 = alloca i32, align 4
%3 = alloca i32, align 4
store i32 0, i32* %1, align 4 //赋值 0 c
store i32 10, i32* %2, align 4 //赋值10 a
%4 = load i32, i32* %2, align 4 //将%2所存的值赋给%4 t=a
%5 = icmp slt i32 %4, 5 //icmp就是有符号比较 即%4与5比较如果%4小于5则slt=1
br i1 %5, label %6, label %7 //i1表示一个类型即%5 比较%5是否为1,若是则跳转%6否则跳%7
6: ; preds = %0
store i32 2, i32* %3, align 4 //即c语言c=2
br label %7//跳出 至此if分支语句结束
7: ; preds = %6, %0
br label %8// a>=5跳转到这
8: ; preds = %11, %7
%9 = load i32, i32* %2, align 4 //将%2赋值给%5 t = a
%10 = icmp sgt i32 %9, 5 // 又是进行比较sgt与slt相反 大于则置为1 t>5
br i1 %10, label %11, label %14 //如果%10=1则跳转到11处否则跳转14处
11: ; preds = %8
%12 = load i32, i32* %2, align 4 //t>5则跳转到这 将%2赋给%12 t2 = a
%13 = sub nsw i32 %12, 5 //t3 = t2-5
store i32 %13, i32* %2, align 4 // a = t3
br label %8
14: ; preds = %8
ret i32 0
}
slt在mips指令集有解释
如果第一个源寄存器的内容小于第二个源寄存器的内容,则 SLT 指令将目标寄存器的内容设置为值 1。 否则,它被设置为值 0。
br指令的语法为br + 标志位 + truelabel + falselabel,或者br + label.是跳转指令.
如注释.
update
现在更新一下clang对于一个源程序文件的整体编译过程.之前只分析了前端.
clang的官方文档还是有点复杂.
-fmodules:启用“模块”语言功能。关于Modules特性,详见此处,大意为使用import代替include,编译速度快。
-fsyntax-only:运行预处理器,解析器和类型检查阶段。
-Xclang <arg>:传递参数到clang的编译器。
dump-tokens:运行预处理器,转储Token的内部表示
这里参照博客编译器与Clang编译过程 - 简书 (jianshu.com)看一下clang的使用
预处理
1 | clang -E test.c |
预处理
1、删除所有的#define,代码中使用宏定义的地方会进行替换
2、将#include包含的文件插入到文件的位置,这个插入的过程是递归的
3、删除掉注释符号及注释
4、添加行号和文件标识,便于调试
查看文件发现前几行都是注释,大致是包含一些文件路径.再下面是typedef定义变量.
还定义了一些结构体,声明了函数.最后是源代码
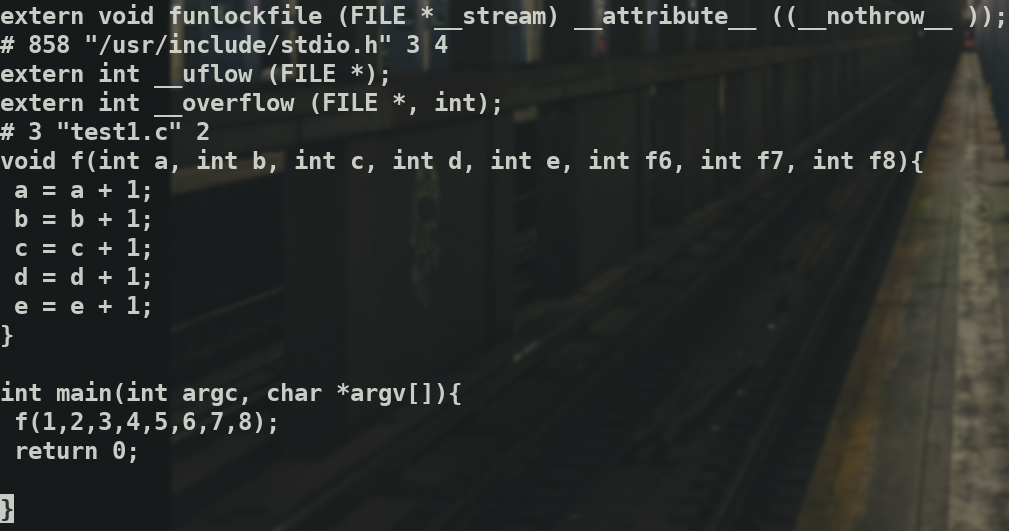
分析词法功能
1 | clang -fsyntax-only -Xclang -dump-tokens test.c |
这一步顾名思义是词法分析,得到valueType value loc这样形式的数据
有标识符identifier类型,有comma逗号类型,const类型等等
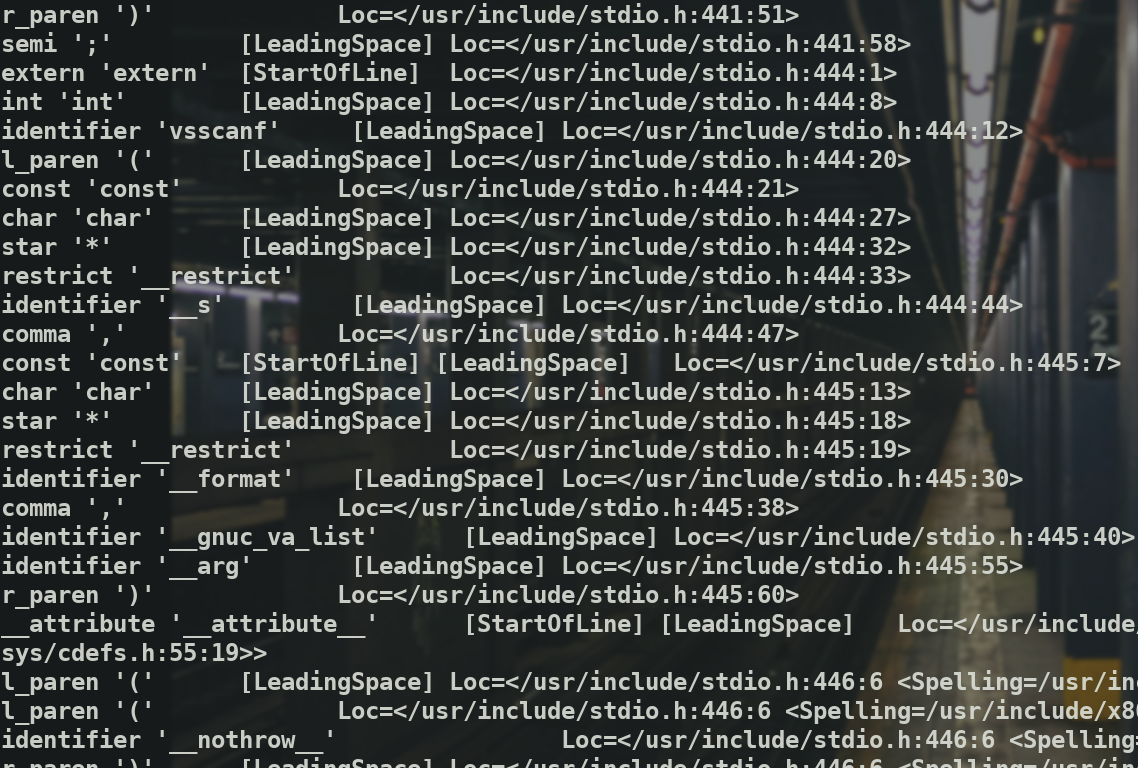
处理文件后可以得到三元组,即属性,值以及位置.
Sourece Location:表示Token开始的位置,比如:Loc=<main.m:11:5>;Token Kind:表示Token的类型,比如:identifier、numeric_constant、string_literal;Flags:词法分析器和处理器跟踪每个Token的基础,目前有四个Flag分别是:
StartOfLine:表示这是每行开始的第一个Token;LeadingSpace:当通过宏扩展Token时,在Token之前有一个空格字符。该标志的定义是依据预处理器的字符串化要求而进行的非常严格地定义。DisableExpand:该标志在预处理器内部使用,用来表示identifier令牌禁用宏扩展。NeedsCleaning:如果令牌的原始拼写包含三字符组或转义的换行符,则设置此标志
分析语法产生出的抽象语法树
1 | clang -fsyntax-only -Xclang -ast-dump test.c |
-ast-dump: Build ASTs and then debug dump them
表示生成抽象语法树
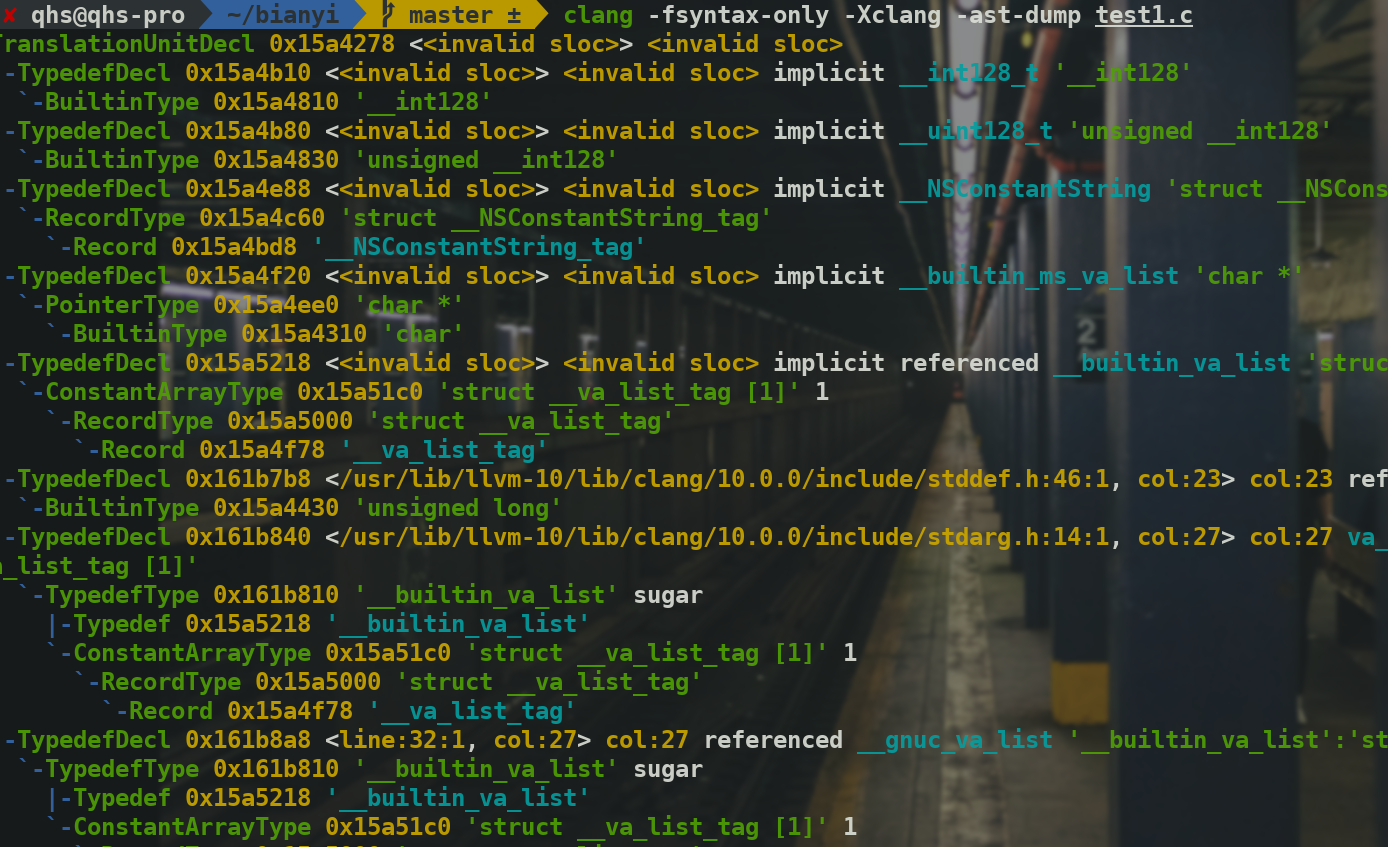
很好,我并不是和能看懂这个东西.
Type :表示类型,比如BuiltinType
Decl :表示一个声明declaration或者一个定义definition,比如:变量,函数,结构体,typedef;
DeclContext :用来声明表示上下文的特定decl类型的基类;
Stmt :表示一条陈述statement;
Expr:在Clang的语法树中也表示一条陈述statements;
中间代码生成
1 | clang -S -emit-llvm -o test.ll test.c |
这个中间代码之前已经分析过了点击查看

这是f函数的中间代码,i32表示类型,align表示对齐.alloca分配空间,store存储值.
汇编语言生成
1 | llc test.ll -o test.s |
汇编语言生成
到这一步生成汇编代码与及其相关,就没有太多可以说了.
可执行程序生成
1 | clang test.s -o test |

反汇编程序
1 | objdump -dS test |
clang -g -o test test.c可以直接生成目标程序.
objdump -S命令可以显示源代码,但需要编译时加上-g
使用clang -g test.c -o test得到的可执行程序反汇编.
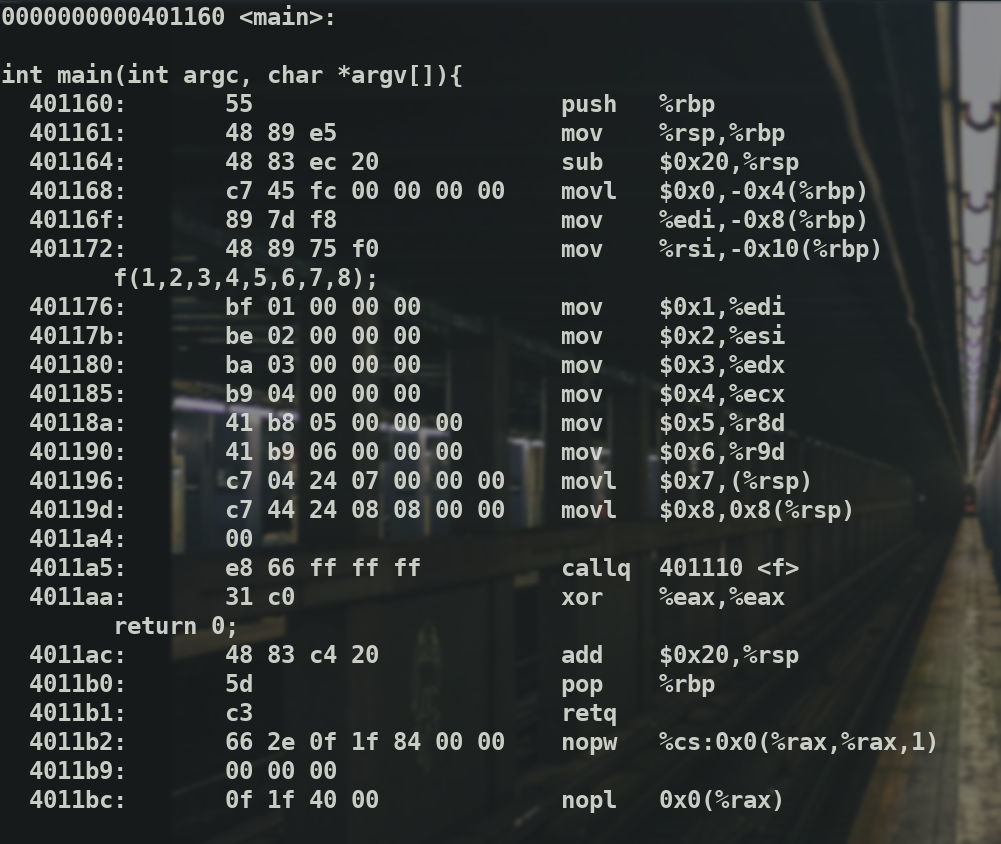
可以看到这里有更多的调试信息.
2.
对所编写的例子尝试编写一个Makefile文件,然后进行make编译,然后通过make -j #n来编译,也可采用cmake.证明并行编译确实提高了.
makefile编写本身就遵循一定技巧,好的makefile能让人一眼看上去知道规则.由于我编写的比较少,makefile写的不是很好,但是勉强能用.
make并行编译
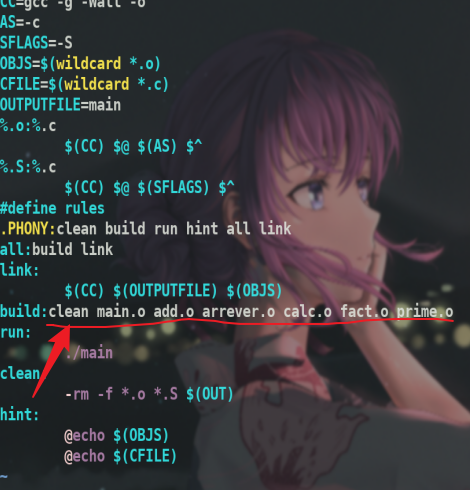
重点关注编译,即build这一行.进行了main.c主文件的编译以及引入的其他五个c文件的编译
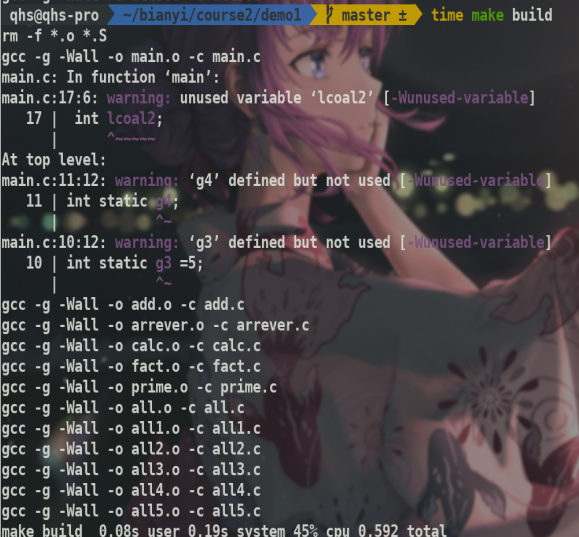
time命令可以得到运行时间6,0.08s是执行用户态代码所耗费的 CPU 时间
0.19s是内核态运行所耗费的CPU时间,0.592包括了阻塞时间和其他进程耗费时间
每次编译时间或多说少有一点差异,
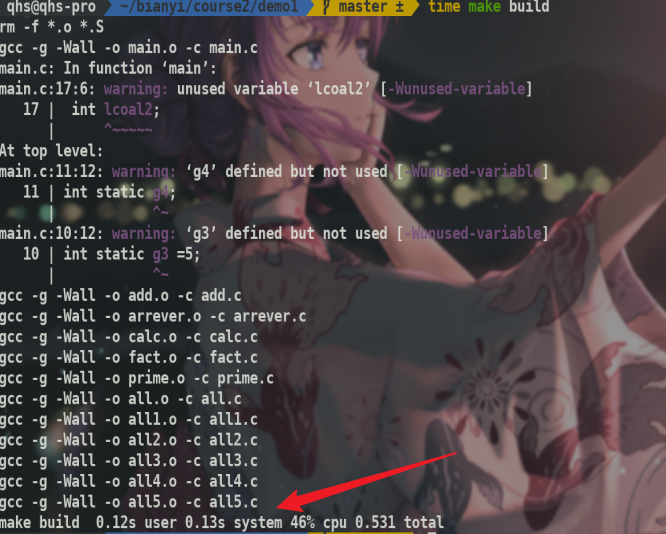
但基本上用户态时间0.1s左右,管态时间要多一点
可以看见make -j 3,并行三条指令编译时间减少了.
看来编译的任务还不够多,于是我又增加了几个个源文件进行编译,每个源文件代码二三十行也不算多.
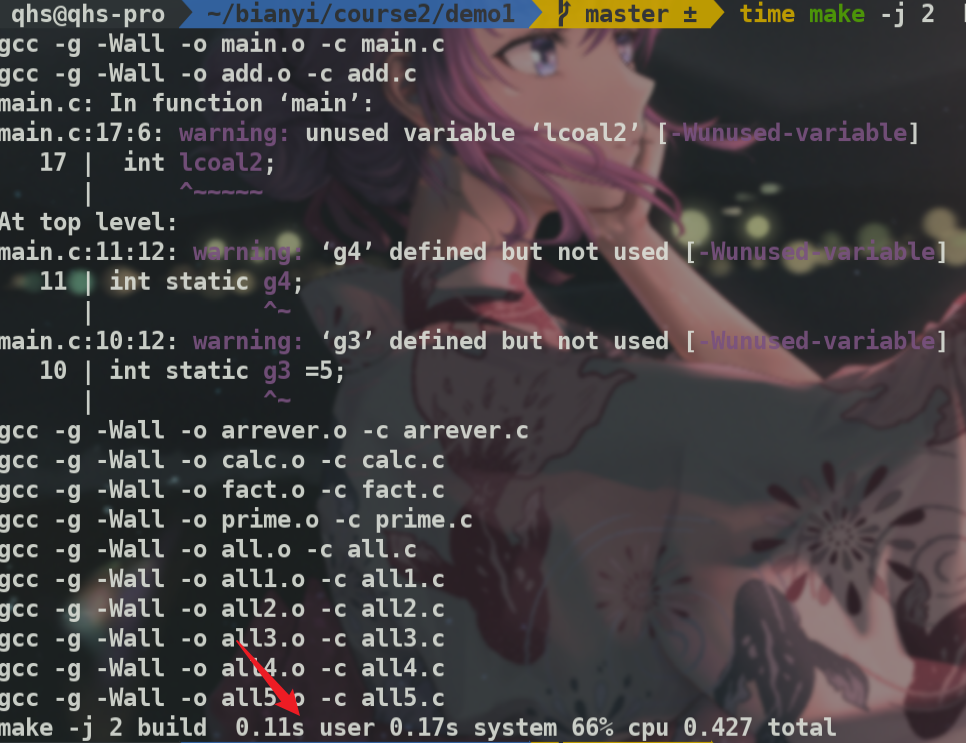
可以看到时间减少了,但不是很明显.可能是因为我用的虚拟机,分配的cpu与实机有一定差别.
我在windows上的测试.
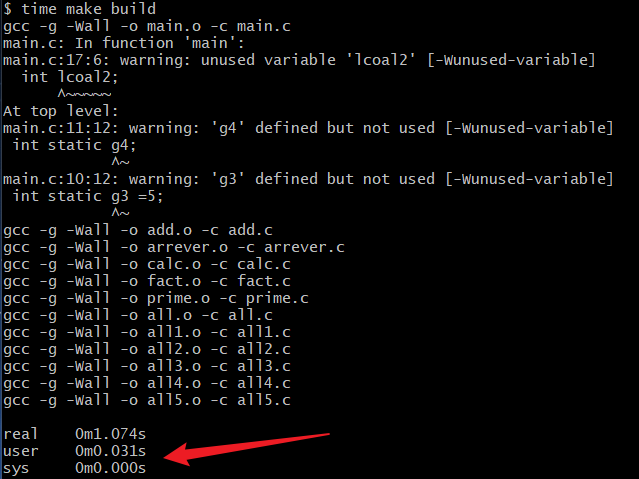
进行并行编译
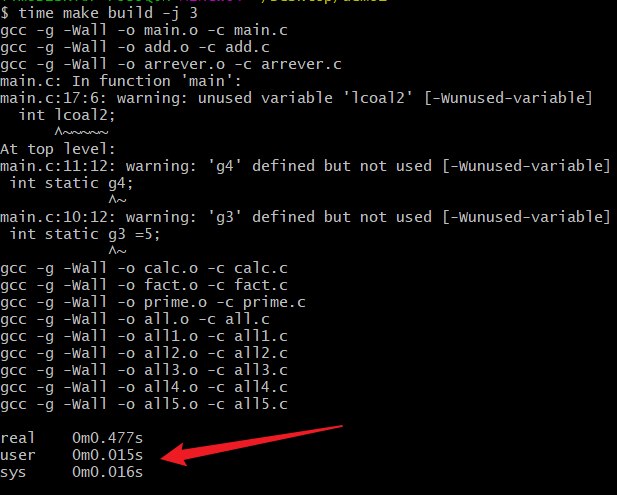
可以看到时间由用户态的0.03s->0.015s,可以说明并行编译时间变短了.
update
由于之前做的编译量有一点少,运行时间太短以及测试次数不够.这里继续做一下补充.
我继续增加源文件的代码量.
由于我使用的是虚拟机,查看我主机电脑配置信息6核cpu.
所以这里我设置虚拟机分配了3个虚拟cpu.
同时我增加了一些代码,当时并不是很多.
可惜的是还是因为代码量不够的原因导致差别不是很大.考虑到make -j使用多处理器并行,所以time命令结果看total time更合适.因为使用并行减少时间

由于代码还是写的不规范,有warning不过不影响
make -j2 make -j3 make -j6




进行了7组实验,根据total时间结果,也就是进程从开始到结束所用的实际时间。这个时间包括其他进程使用的时间片和进程阻塞的时间.因为使用了多处理器并行处理编译.
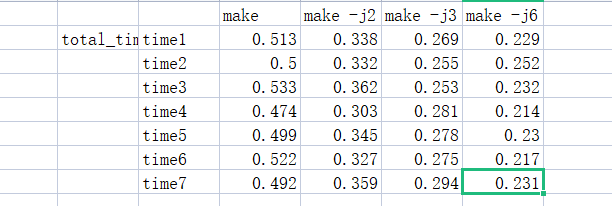
但是user时间也就是用户态时间并没有明显变化.估计是代码还是不够
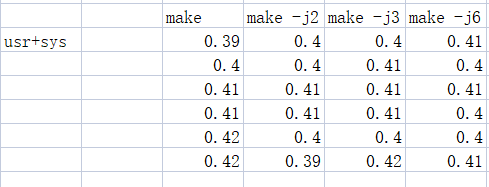
经过我的考虑,认为make -j本是是让多个cpu内核并行处理指令,这也不意味着优化.即usr+sys时间变化不大是正常的,real时间即总时间(包括其他进程及IO)应该变化,因为多个cpu并行就像多个人一起干同一件事一样,总的来说时间减少了.但放在每个人身上都花了一点时间,这个时间是变化不大的11.
现在进行Linux源码部分模块的编译12

由于编译全部代码太耗时了,这里编译部分代码.1
time make SUBDIRS=./samples/kprobes modules
网上教程有点难,直接使用这个命令.选择某个模块的文件夹编译.

上图是直接make的编译时间
下图是 -j3编译内核某模块时间

-j6编译时间


由于是虚拟机并且因为编译内核时间有点久只做了一组实验.
但是结果还是比较清晰的,usr和sys时间并没有太大变化.主要是total时间减少.
有意思的是-j6情况下编译时间并没有想象的减小的那么多,初步估计是虚拟机的逻辑cpu机制导致.
Cmake使用
同时,由于makefile编写较为麻烦,这里用cmake实现一下,不过本质上差别不大.
CMake是一个跨平台的编译(Build)工具,可以用简单的语句来描述所有平台的编译过程。
CMake能够输出各种各样的makefile或者project文件.也就是说只要我们配置好了cmake文件(CMakeLists.txt),就能输出对应的makefile,我们再make就行了7.
cmake是跨平台的,我在windows上编写cmakelists,cmake可以指定构建的目的,可以是一般的MinGW,也可以是Ninja等.
需要在CMakeLists.txt文件中指定如下几项,cmake版本、工程名、构建目标app的源文件
cmake_minimum_required:指定运行此配置文件所需的 CMake 的最低版本;project:参数值是Demo1,该命令表示项目的名称是Demo1。add_executable: 将名为 main.cc 的源文件编译成一个名称为 Demo 的可执行文件
cmake在不同平台默认的构建目标(generators)不一样,我的在Windows上是visual studio,Linux上是Unix Makefiles,需要按照自己要求修改.
执行cmake后会在根据指定路径找到CMakeLists.txt,然后按照要求构建,构建文件等在执行命令的本目录下产生.由CMakeCache.txt,cmake_install.cmake,Makefile和CMakeFiles文件夹等.
我们主要关注生成的Makefile.然后在该目录下make即可.
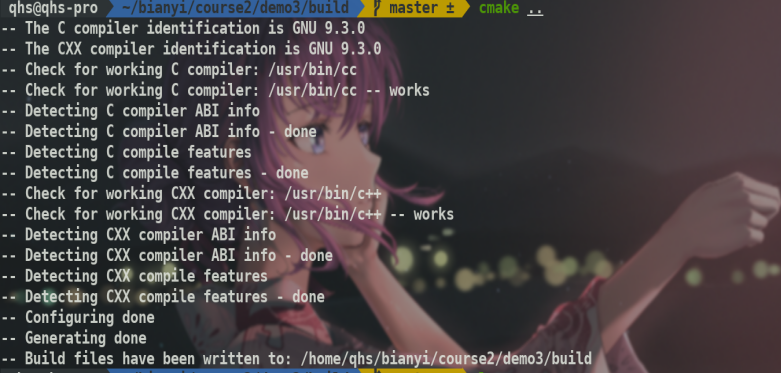
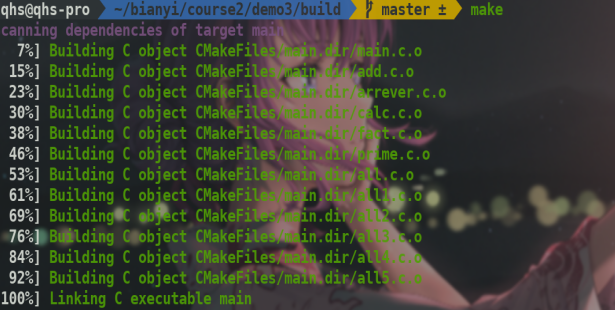
这样按照generator的makefile等构建就完成了.
参考资料
1:C语言未初始化的局部变量是多少? - 知乎 (zhihu.com) 事实上,未初始化的局部变量不一定为0,这与编译器有关.
2:(58条消息) 代码段(.text)、数据区(.data)和bss段baymaxly的博客-CSDN博客.text段
3:C语言全局未初始化数据段分析 - Class Xman - 博客园 (cnblogs.com)很好的文章
4:(58条消息) ARM中的—-汇编指令老鹏-CSDN博客汇编.quad
5:(深入理解计算机系统) bss段,data段、text段、堆(heap)和栈(stack) - 跑马灯的忧伤 - 博客园 (cnblogs.com)
6:time命令_Linux time命令:测量命令的执行时间或者系统资源的使用情况 (biancheng.net)
7:超详细的CMake教程 - 一杯清酒邀明月 - 博客园 (cnblogs.com)
8:readelf 和 objdump 例子详解及区别_哈尼的博客-CSDN博客_readelf和objdump
9:使用readelf和objdump解析目标文件 - 简书 (jianshu.com)
个人感想
我更加熟悉了变量和函数在段的分配以及ELF文件链接视图和执行视图.
LLVM相对于gcc确实是好很多,中间代码很容易懂也很容易研究,模块更加分离.了解了编译器的大概设计,从词法,语法到语义的前端生成AST,再由AST得到IR,再对IR进行优化.后端根据优化后的IR生成对应平台的机器代码.这个过程中IR的代码就显得很重要.
最后使用了make并行编译.不过我写的代码量还是上不去,real时间0.5秒左右,不过也能看到并行编译带来的优势了.编译了Linux部分模块源码,耗时比较久,并没有多做几组实验.
