所以, 编译器通常会将 AST 转换为另一种形式的数据结构, 我们把它称作 IR. IR 的抽象层次比 AST 更低, 但又不至于低到汇编代码的程度. 在此基础上, 无论是直接把 IR 进一步转换为汇编代码, 还是在 IR 之上做出一些优化, 都相对更容易.
有了 IR 的存在, 我们也可以大幅降低编译器的开发成本: 假设我们想开发 MM 种语言的编译器, 要求它们能把输入编译成 NN 种指令系统的目标代码, 在没有统一的 IR 的情况下, 我们需要开发 M \times NM×N 个相关模块. 如果我们先把所有源语言都转换到同一种 IR, 然后再将这种 IR 翻译为不同的目标代码, 我们就只需要开发 M + NM+N 个相关模块.
对于使用 C/C++ 的同学, 在上一条的基础上, 你可以考虑把这种结构转换成 raw program, 然后使用 libkoopa 中的相关接口, 将 raw program 转换成其他形式的 Koopa IR 程序
第一种思路可能是大部分同学会采用的思路, 因为它相当简单且直观, 实现难度很低. 但其缺点是, 你在生成目标代码之前, 不得不再次将文本形式的 Koopa IR 转换成某种数据结构——这相当于再写一个编译器. 否则, 你的程序几乎无法直接基于文本形式 IR 生成汇编.
不过好在, 我们为大家提供了能够处理 Koopa IR 的库, 你可以使用其中的实现, 来将文本形式的 IR 转换为内存形式.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
// 解析字符串 str, 得到 Koopa IR 程序 koopa_program_t program; koopa_error_code_t ret = koopa_parse_from_string(str, &program); assert(ret == KOOPA_EC_SUCCESS); // 确保解析时没有出错 // 创建一个 raw program builder, 用来构建 raw program koopa_raw_program_builder_t builder = koopa_new_raw_program_builder(); // 将 Koopa IR 程序转换为 raw program koopa_raw_program_t raw = koopa_build_raw_program(builder, program); // 释放 Koopa IR 程序占用的内存 koopa_delete_program(program);
// 处理 raw program // ...
// 处理完成, 释放 raw program builder 占用的内存 // 注意, raw program 中所有的指针指向的内存均为 raw program builder 的内存 // 所以不要在 raw program 处理完毕之前释放 builder koopa_delete_raw_program_builder(builder);
/***************************************************** * Definition of the AST nodes. * * Please read the description of each class for details. * * Keltin Leung */
// the prefix of an ast attribution #define ATTR(x) ast_attr_##x##_
namespace mind {
#define MIND_AST_DEFINED namespace ast {
/* The base class of all AST nodes. * * NOTE: Don't instantiate this class. * Please read the description of the subclasses. */ classASTNode { public: // types of the AST nodes typedefenum { ADD_EXPR, AND_EXPR, ASSIGN_EXPR, BOOL_CONST, BIT_NOT_EXPR, BOOL_TYPE, BREAK_STMT, CONTINUE_STMT, CALL_EXPR, COMP_STMT, DIV_EXPR, EQU_EXPR, EMPTY_STMT, EXPR_STMT, FUNC_DEFN, GEQ_EXPR, GRT_EXPR, IF_STMT, IF_EXPR, INT_CONST, INT_TYPE, LEQ_EXPR, LES_EXPR, LVALUE_EXPR, MOD_EXPR, MUL_EXPR, NEG_EXPR, NEQ_EXPR, NOT_EXPR, OR_EXPR, PROGRAM, RETURN_STMT, SUB_EXPR, VAR_DECL, VAR_REF, WHILE_STMT, FOR_STMT, FOD, INDEX_EXPR } NodeType; // 定义了一个,枚举类型 ast节点类型
protected: // names of each kind of the AST nodes staticconstchar *node_name[]; // kind of this node NodeType kind; //上面声明的节点类型 // position in the source text Location *loc; //在另一各文件中声明的 是一个结构体 有构造函数 表示ast节点位置 // for subclass constructors only virtual voidsetBasicInfo(NodeType, Location *); //she
public: // gets the node kind virtual NodeType getKind(void); // gets the location virtual Location *getLocation(void); // prints to the specified output stream virtual voiddumpTo(std::ostream &); // for Visitor virtual voidaccept(Visitor *) = 0; // remember: let alone the memory deallocation stuff virtual ~ASTNode(void) {} };
/* Node representing a type. * * NOTE: * it is purely an interface. * IMPLEMENTATION: * IntType, BoolType, ArrayType */ classType : public ASTNode { public: type::Type *ATTR(type); // for semantic analysis };
/* Node representing a statement. * * NOTE: * it is purely an interface. * IMPLEMENTATION: * AssignStmt, ReturnStmt, * IfStmt, WhileStmt, */ classStatement : public ASTNode { /* pure interface */ };
/* Node representing an expression. * * NOTE: * it is purely an interface. * IMPLEMENTATION: * ... */ classEmptyStmt : public Statement { public: EmptyStmt(Location *l);
virtual voidaccept(Visitor *); virtual voiddumpTo(std::ostream &); }; classExpr : public ASTNode { public: type::Type *ATTR(type); // for semantic analysis tac::Temp ATTR(val); // for tac generation };
/* Node representing a left-value expression (lvalue). * * NOTE: * it is purely an interface. * IMPLEMENTATION: * VarRef, ArrayRef */ classLvalue : public ASTNode { public: enum { SIMPLE_VAR, // referencing simple variable ARRAY_ELE // referencing array element } ATTR(lv_kind);
type::Type *ATTR(type); // for semantic analysis };
public: std::string name; Type *ret_type; VarList *formals; StmtList *stmts; bool forward_decl; // is this FuncDefn a forward declaration or full // definition? symb::Function *ATTR(sym); // for semantic analysis };
/* Names of the AST nodes. * * NOTE: The order of node_name's must be the same with that of NodeType's. */ constchar *ASTNode::node_name[] = {"add", "and", "assign", "bconst", "bitnot",
/* Whether to print the decorated abstract syntax tree. */ bool print_decorated_ast = false;
/* Sets the basic information of a node. * * PARAMETERS: * k - the node kind * l - position in the source text */ voidASTNode::setBasicInfo(NodeType k, Location *l) { kind = k; loc = l; }
/* Gets the node kind. * * RETURNS: * the node kind */ ASTNode::NodeType ASTNode::getKind(void) { return kind; }
/* Gets the source text location of this node * * RETURNS: * the source text location */ Location *ASTNode::getLocation(void) { return loc; }
/* Dumps this node to an output stream. * * PARAMETERS: * os - the output stream */ voidASTNode::dumpTo(std::ostream &os) { os << "(" << node_name[kind]; if (Option::getLevel() != Option::PARSER) os << " (" << loc->line << " " << loc->col << ")"; incIndent(os); }
/* Outputs an ASTNode. * * PARAMETERS: * os - the output stream * p - the ASTNode * RETURNS: * the output stream */ std::ostream &mind::operator<<(std::ostream &os, ASTNode *p) { if (p == NULL) os << "!!NULL!!"; else p->dumpTo(os); return os; } /* Outputs a FuncList. * * PARAMETERS: * os - the output stream * l - the Func list * RETURNS: * the output stream */ std::ostream &mind::operator<<(std::ostream &os, FuncList *l) { os << "["; if (!l->empty()) { incIndent(os); os << " "; FuncList::iterator it = l->begin(); os << *it; while (++it != l->end()) { newLine(os); os << *it; } decIndent(os); newLine(os); } os << "]";
return os; };
/* Outputs a VarList. * * PARAMETERS: * os - the output stream * l - the VarDecl list * RETURNS: * the output stream */ std::ostream &mind::operator<<(std::ostream &os, VarList *l) { os << "["; if (!l->empty()) { incIndent(os); os << " "; VarList::iterator it = l->begin(); os << *it; while (++it != l->end()) { newLine(os); os << *it; } decIndent(os); newLine(os); } os << "]";
return os; }
/* Outputs a StmtList. * * PARAMETERS: * os - the output stream * l - the Statement list * RETURNS: * the output stream */ std::ostream &mind::operator<<(std::ostream &os, StmtList *l) { os << "["; if (!l->empty()) { incIndent(os); os << " "; StmtList::iterator it = l->begin(); os << *it; while (++it != l->end()) {
newLine(os); os << *it; } decIndent(os); newLine(os); } os << "]";
return os; }
/* Outputs an ExprList . * * PARAMETERS: * os - the output stream * l - the Expr list * RETURNS: * the output stream */ std::ostream &mind::operator<<(std::ostream &os, ExprList *l) { os << "["; if (!l->empty()) { incIndent(os); os << " "; ExprList::iterator it = l->begin(); os << *it; while (++it != l->end()) { newLine(os); os << *it; } decIndent(os); newLine(os); } os << "]";
return os; } std::ostream &mind::operator<<(std::ostream &os, DimList *l) { os << "["; if (!l->empty()) { incIndent(os); os << " "; DimList::iterator it = l->begin(); os << *it; while (++it != l->end()) { newLine(os); os << *it; } decIndent(os); newLine(os); } os << "]";
return os; } std::ostream &mind::operator<<(std::ostream &os, FuncOrGlobalList *l) { os << "["; if (!l->empty()) { incIndent(os); os << " "; FuncOrGlobalList::iterator it = l->begin(); os << *it; while (++it != l->end()) {
newLine(os); os << *it; } decIndent(os); newLine(os); } os << "]";
/***************************************************** * Definition of the AST visitor pattern. * * It is only an interface (we provide an empty body * just to make your life easier..). * * Keltin Leung */
#ifndef __MIND_VISITOR__ #define __MIND_VISITOR__
#include"ast/ast.hpp"
namespace mind {
namespace ast {
/* AST Visitor Pattern. * * HOW TO USE: * 1. Create a subclass of Visitor; * 2. Implement visit(ast::Program*) (required); * 3. Implement the other visiting functions as you need; * 4. We provide an empty function body ({ }) instead of * setting it pure (= 0) so that you do not need to * implement all the functions as you do with a pure * interface. */ classVisitor { public: // Expressions virtual voidvisit(CallExpr *) {} virtual voidvisit(AddExpr *) {} virtual voidvisit(AndExpr *) {} virtual voidvisit(AssignExpr *) {} virtual voidvisit(IfExpr *) {} virtual voidvisit(OrExpr *) {} virtual voidvisit(BoolConst *) {} virtual voidvisit(DivExpr *) {} virtual voidvisit(EquExpr *) {} virtual voidvisit(GeqExpr *) {} virtual voidvisit(GrtExpr *) {} virtual voidvisit(NeqExpr *) {} virtual voidvisit(IntConst *) {} virtual voidvisit(LeqExpr *) {} virtual voidvisit(LesExpr *) {} virtual voidvisit(LvalueExpr *) {} virtual voidvisit(ModExpr *) {} virtual voidvisit(MulExpr *) {} virtual voidvisit(NegExpr *) {} virtual voidvisit(NotExpr *) {} virtual voidvisit(BitNotExpr *) {} virtual voidvisit(SubExpr *) {} virtual voidvisit(IndexExpr *) {}
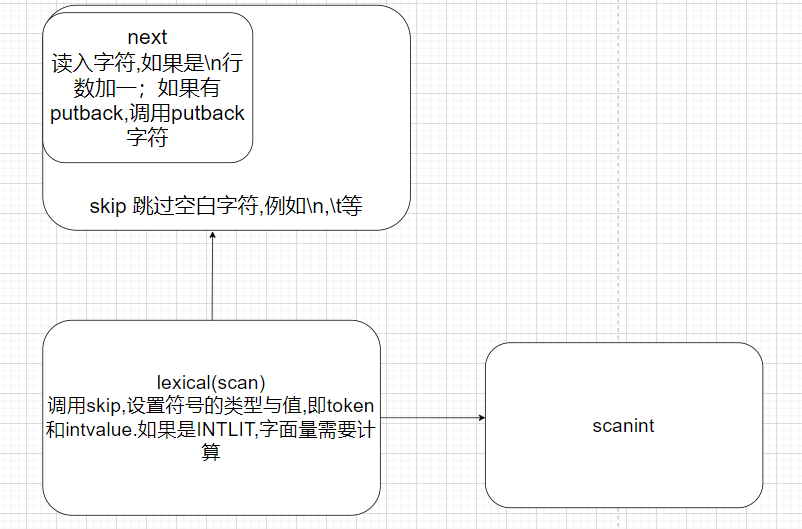
However, there will be times when we need to “put back” a character if we have read too far ahead in the input stream. We also want to track what line we are currently on so that we can print the line number in our debug messages. All of this is done by the next() function:
// Abstract Syntax Tree structure structASTnode { int op; // "Operation" to be performed on this tree structASTnode *left;// Left and right child trees structASTnode *right; int intvalue; // For A_INTLIT, the integer value };
defs文件新增ASTnode
1 2 3 4 5 6 7 8 9
structASTnode { // op to be performed on this tree // e.g. A_ADD int op; // left and right child tree structASTnode *left; structASTnode *right; int intvalue; //for integer };
struct ASTnode *binexpr(void) { structASTnode *n, *left, *right; int nodetype;
// 左值 // Get the integer literal on the left. // Fetch the next token at the same time. left = primary(); if (Token.token == _EOF) { return left; } nodetype = tok2aop(Token.token);
scan(&Token); // 创建右值 right = binexpr();
n = mkastnode(nodetype, left, right, 0); return n; }