这方面的知识实在是很多
首先写一下计算机视觉方向的,介绍一下各种Net的发展史.
基础知识
卷积神经网络
Padding Stride 卷积核大小
p表示填充padding,k表示卷积核宽高,s表示stride
LeNet
LeNet,它是最早发布的卷积神经网络之一,因其在计算机视觉任务中的高效性能而受到广泛关注。 这个模型是由AT&T贝尔实验室的研究员Yann LeCun在1989年提出的(并以其命名),目的是识别图像 (LeCun et al., 1998)中的手写数字。 当时,Yann LeCun发表了第一篇通过反向传播成功训练卷积神经网络的研究,这项工作代表了十多年来神经网络研究开发的成果
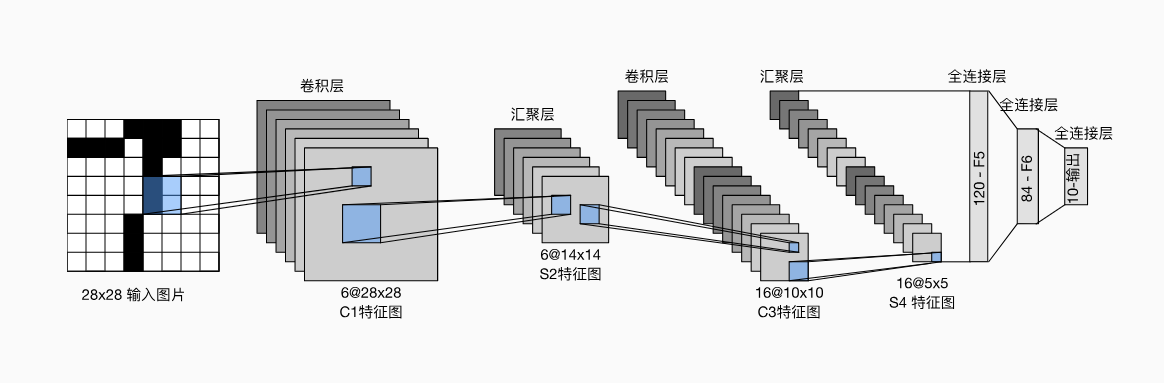
每个卷积块中的基本单元是一个卷积层、一个sigmoid激活函数和平均汇聚层。请注意,虽然ReLU和最大汇聚层更有效,但它们在20世纪90年代还没有出现。每个卷积层使用5×5卷积核和一个sigmoid激活函数。这些层将输入映射到多个二维特征输出,通常同时增加通道的数量。第一卷积层有6个输出通道,而第二个卷积层有16个输出通道。每个2×2池操作(步幅2)通过空间下采样将维数减少4倍。卷积的输出形状由批量大小、通道数、高度、宽度决定。
为了将卷积块的输出传递给稠密块,我们必须在小批量中展平每个样本。换言之,我们将这个四维输入转换成全连接层所期望的二维输入。这里的二维表示的第一个维度索引小批量中的样本,第二个维度给出每个样本的平面向量表示。LeNet的稠密块有三个全连接层,分别有120、84和10个输出。因为我们在执行分类任务,所以输出层的10维对应于最后输出结果的数量。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(in_features=16*5*5, out_features=120)
self.fc2 = nn.Linear(in_features=120, out_features=84)
self.fc3 = nn.Linear(in_features=84, out_features=10)
def forward(self,x):
out = F.relu(self.conv1(x)) # 3*32*32 -> 6*28*28
out = F.max_pool2d(out,2) # 6*28*28 -> 6*14*14
out = F.relu(self.conv2(out)) # 6*14*14 -> 16*10*10
out = F.max_pool2d(out, 2) # 16*10*10 -> 16*5*5
out = out.view(out.size(0), -1) # 16*5*5 -> 400
out = F.relu(self.fc1(out))
out = F.relu(self.fc2(out))
out = self.fc3(out)
return out
AlexNet
2012年,AlexNet横空出世。它首次证明了学习到的特征可以超越手工设计的特征。它一举打破了计算机视觉研究的现状。 AlexNet使用了8层卷积神经网络,并以很大的优势赢得了2012年ImageNet图像识别挑战赛。
AlexNet和LeNet的架构非常相似
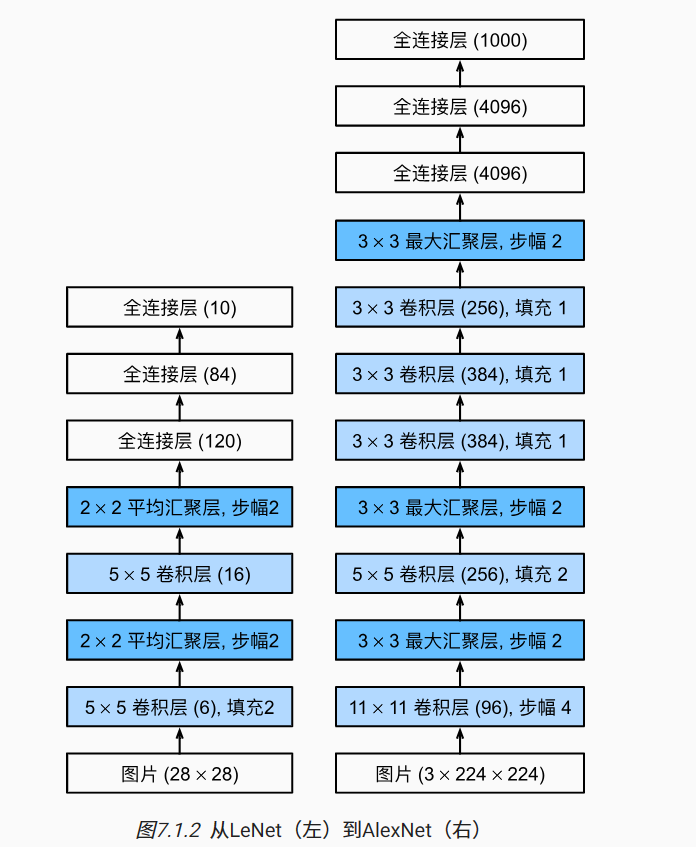
AlexNet和LeNet的设计理念非常相似,但也存在显著差异。
- AlexNet比相对较小的LeNet5要深得多。AlexNet由八层组成:五个卷积层、两个全连接隐藏层和一个全连接输出层。
- AlexNet使用ReLU而不是sigmoid作为其激活函数。
AlexNet通过DropOut控制全连接层的模型复杂度,而LeNet只使用了权重衰减。 为了进一步扩充数据,AlexNet在训练时增加了大量的图像增强数据,如翻转、裁切和变色。 这使得模型更健壮,更大的样本量有效地减少了过拟合。 在 13.1节中更详细地讨论数据扩增。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25class AlexNet(nn.Module):
def __init__(self):
super().__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2), # 3*224*224 -> 64*55*55
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2), # 64*55*55 -> 64*27*27
nn.Conv2d(64, 192, kernel_size=5, padding=2), # 64*27*27 -> 192*27*27
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2), # 192*27*27 -> 192*13*13
nn.Conv2d(192, 384, kernel_size=3, padding=1), # 192*13*13 -> 384*13*13
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1), # 384*13*13 -> 256*13*13
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1), # 256*13*13 -> 256*13*13
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2), # 256*13*13 -> 256*6*6
)
self.fc = nn.Linear(256,10)
def forward(self,x):
out = self.features(x)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out
VGGNet
AlexNet证明深层神经网络卓有成效,但它没有提供一个通用的模板来指导后续的研究人员设计新的网络

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45import torch
import torch.nn as nn
from torch.autograd import Variable
cfg = {
'VGG11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'VGG13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'VGG16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'VGG19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
class VGG(nn.Module):
def __init__(self, vgg_name):
super(VGG, self).__init__()
self.features = self._make_layers(cfg[vgg_name])
self.classifier = nn.Linear(512, 10)
def forward(self, x):
out = self.features(x)
out = out.view(out.size(0), -1)
out = self.classifier(out)
return out
def _make_layers(self, cfg):
layers = []
in_channels = 3
for x in cfg:
if x == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
layers += [nn.Conv2d(in_channels, x, kernel_size=3, padding=1),
nn.BatchNorm2d(x),
nn.ReLU(inplace=True)]
in_channels = x
layers += [nn.AvgPool2d(kernel_size=1, stride=1)]
return nn.Sequential(*layers)
def VGG16():
return VGG('VGG16')
def VGG19():
return VGG('VGG19')
LeNet、AlexNet和VGG都有一个共同的设计模式:通过一系列的卷积层与汇聚层来提取空间结构特征;然后通过全连接层对特征的表征进行处理。
NiN
1x1卷积
LeNet、AlexNet和VGG都有一个共同的设计模式:通过一系列的卷积层与汇聚层来提取空间结构特征;然后通过全连接层对特征的表征进行处理。 AlexNet和VGG对LeNet的改进主要在于如何扩大和加深这两个模块。 或者,可以想象在这个过程的早期使用全连接层。然而,如果使用了全连接层,可能会完全放弃表征的空间结构。 网络中的网络(NiN)提供了一个非常简单的解决方案:在每个像素的通道上分别使用多层感知机
1 | import torch |
NiN的想法是在每个像素位置(针对每个高度和宽度)应用一个全连接层。 如果我们将权重连接到每个空间位置,我们可以将其视为1×1卷积层,或作为在每个像素位置上独立作用的全连接层。从另一个角度看,即将空间维度中的每个像素视为单个样本,将通道维度视为不同特征(feature)
GoogleNet
GoogLeNet吸收了NiN中串联网络的思想,并在此基础上做了改进。 GoogleNet核心是提出了Inception这种模块.
这篇论文的一个重点是解决了什么样大小的卷积核最合适的问题。

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
class Inception(nn.Module):
# c1--c4是每条路径的输出通道数
def __init__(self, in_channels, c1, c2, c3, c4, **kwargs):
super(Inception, self).__init__(**kwargs)
# 线路1,单1x1卷积层
self.p1_1 = nn.Conv2d(in_channels, c1, kernel_size=1)
# 线路2,1x1卷积层后接3x3卷积层
self.p2_1 = nn.Conv2d(in_channels, c2[0], kernel_size=1)
self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1)
# 线路3,1x1卷积层后接5x5卷积层
self.p3_1 = nn.Conv2d(in_channels, c3[0], kernel_size=1)
self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2)
# 线路4,3x3最大汇聚层后接1x1卷积层
self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.p4_2 = nn.Conv2d(in_channels, c4, kernel_size=1)
def forward(self, x):
p1 = F.relu(self.p1_1(x))
p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))
p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))
p4 = F.relu(self.p4_2(self.p4_1(x)))
# 在通道维度上连结输出
return torch.cat((p1, p2, p3, p4), dim=1)

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=1),
nn.ReLU(),
nn.Conv2d(64, 192, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b3 = nn.Sequential(Inception(192, 64, (96, 128), (16, 32), 32),
Inception(256, 128, (128, 192), (32, 96), 64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b4 = nn.Sequential(Inception(480, 192, (96, 208), (16, 48), 64),
Inception(512, 160, (112, 224), (24, 64), 64),
Inception(512, 128, (128, 256), (24, 64), 64),
Inception(512, 112, (144, 288), (32, 64), 64),
Inception(528, 256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b5 = nn.Sequential(Inception(832, 256, (160, 320), (32, 128), 128),
Inception(832, 384, (192, 384), (48, 128), 128),
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten())
net = nn.Sequential(b1, b2, b3, b4, b5, nn.Linear(1024, 10))
对由多个输入平面组成的输入信号进行二维自适应平均池化处理。
对于任何输入尺寸,输出的尺寸都是 H x W。输出特征的数量等于输入平面的数量。
nn.AdaptiveAvgPool2d((1,1)),首先这句话的含义是使得池化后的每个通道上的大小是一个1x1的,也就是每个通道上只有一个像素点。(1,1)表示的outputsize。
Inception V1
使用了全局平均池化
Inception V2
使用Batch Normalization,加快模型训练速度;
使用两个3x3的卷积代替5x5的大卷积,降低了参数数量并减轻了过拟合
Inception V3
Inception V3一个最重要的改进是卷积分解(Factorization),将7x7卷积分解成两个一维的卷积串联(1x7和7x1),3x3卷积分解为两个一维的卷积串联(1x3和3x1),这样既可以加速计算,又可使网络深度进一步增加,增加了网络的非线性(每增加一层都要进行ReLU)
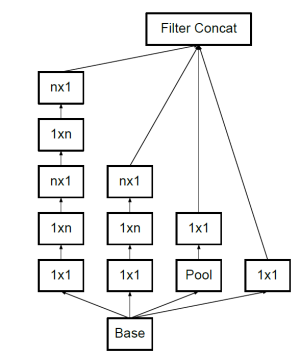
Inception V4
inception v4把原来的inception结构中加入了ResNet中的Residual Blocks结构,把一些层的输出加上前几层的输出,这样中间这几层学习的实际上是残差。
ResNet
假设我们的原始输入为x,而希望学出的理想映射为f(x)(作为上方激活函数的输入)。左图虚线框中的部分需要直接拟合出该映射f(x),而右图虚线框中的部分则需要拟合出残差映射f(x)−x。 残差映射在现实中往往更容易优化。 以本节开头提到的恒等映射作为我们希望学出的理想映射f(x),我们只需将右图虚线框内上方的加权运算(如仿射)的权重和偏置参数设成0,那么f(x)即为恒等映射。 实际中,当理想映射f(x)极接近于恒等映射时,残差映射也易于捕捉恒等映射的细微波动。 右图是ResNet的基础架构–残差块(residual block)。 在残差块中,输入可通过跨层数据线路更快地向前传播。

ResNet沿用了VGG完整的3×3卷积层设计。 残差块里首先有2个有相同输出通道数的3×3卷积层。 每个卷积层后接一个批量规范化层和ReLU激活函数。 然后我们通过跨层数据通路,跳过这2个卷积运算,将输入直接加在最后的ReLU激活函数前。 这样的设计要求2个卷积层的输出与输入形状一样,从而使它们可以相加。 如果想改变通道数,就需要引入一个额外的1×1卷积层来将输入变换成需要的形状后再做相加运算


1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25# 残差块 通过卷积
class Residual(nn.Module):
def __init__(self, input_channels, num_channels,
use_1x1conv=False, strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels,
kernel_size=3, padding=1, stride=strides)
self.conv2 = nn.Conv2d(num_channels, num_channels,
kernel_size=3, padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels,
kernel_size=1, stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return F.relu(Y)1
2
3
4
5
6
7
8
9
10
11#残差模块
def resnet_block(input_channels, num_channels, num_residuals,
first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(Residual(input_channels, num_channels,
use_1x1conv=True, strides=2))
else:
blk.append(Residual(num_channels, num_channels))
return blk1
2
3
4
5
6
7
8
9net = nn.Sequential()
net.add(nn.Conv2D(64, kernel_size=7, strides=2, padding=3),
nn.BatchNorm(), nn.Activation('relu'),
nn.MaxPool2D(pool_size=3, strides=2, padding=1))
net.add(resnet_block(64, 2, first_block=True),
resnet_block(128, 2),
resnet_block(256, 2),
resnet_block(512, 2))
net.add(nn.GlobalAvgPool2D(), nn.Dense(10))
DenseNet

ResNet和DenseNet的关键区别在于,DenseNet输出是连接(用图中的[,]表示)而不是如ResNet的简单相加

稠密网络主要由2部分构成:稠密块(dense block)和过渡层(transition layer)。 前者定义如何连接输入和输出,而后者则控制通道数量,使其不会太复杂
denseblock
1 | def conv_block(input_channels, num_channels): |
transition layer
1 | def transition_block(input_channels, num_channels): |
由于每个稠密块都会带来通道数的增加,使用过多则会过于复杂化模型。 而过渡层可以用来控制模型复杂度。 它通过1×1卷积层来减小通道数,并使用步幅为2的平均汇聚层减半高和宽,从而进一步降低模型复杂度.
DenseNet
1 | def transition_block(input_channels, num_channels): |
在每个模块之间,ResNet通过步幅为2的残差块减小高和宽,DenseNet则使用过渡层来减半高和宽,并减半通道数。
- 在跨层连接上,不同于ResNet中将输入与输出相加,稠密连接网络(DenseNet)在通道维上连结输入与输出。
- DenseNet的主要构建模块是稠密块和过渡层。
- 在构建DenseNet时,我们需要通过添加过渡层来控制网络的维数,从而再次减少通道的数量
正则化方式
不同的normalization
为什么需要批量规范化层呢?让我们来回顾一下训练神经网络时出现的一些实际挑战。
首先,数据预处理的方式通常会对最终结果产生巨大影响。 使用真实数据时,我们的第一步是标准化输入特征,使其平均值为0,方差为1。 直观地说,这种标准化可以很好地与我们的优化器配合使用,因为它可以将参数的量级进行统一。
第二,对于典型的多层感知机或卷积神经网络。当我们训练时,中间层中的变量(例如,多层感知机中的仿射变换输出)可能具有更广的变化范围:不论是沿着从输入到输出的层,跨同一层中的单元,或是随着时间的推移,模型参数的随着训练更新变幻莫测。 批量规范化的发明者非正式地假设,这些变量分布中的这种偏移可能会阻碍网络的收敛。 直观地说,我们可能会猜想,如果一个层的可变值是另一层的100倍,这可能需要对学习率进行补偿调整。
第三,更深层的网络很复杂,容易过拟合。 这意味着正则化变得更加重要。
Normalization有多种方式,包括BN,IN,GN,LN.
BN Batch Normalization
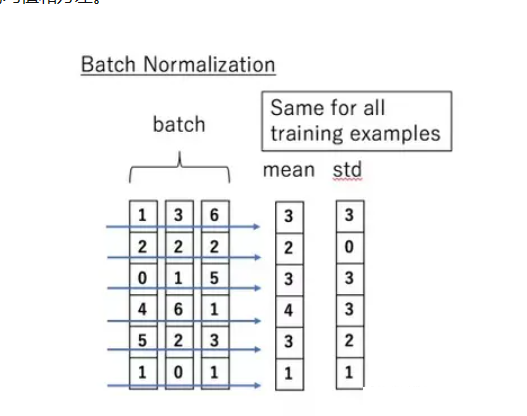
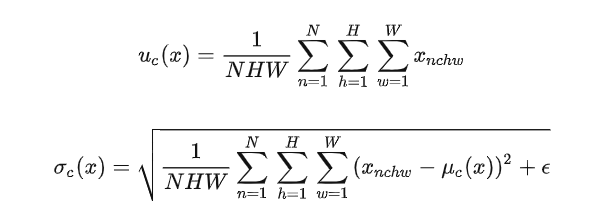
其中N表示样本数,H、W表示高和宽.得到均值和标准差,利用这两个值标准化.
批量规范化应用于单个可选层(也可以应用到所有层),其原理如下:在每次训练迭代中,我们首先规范化输入,即通过减去其均值并除以其标准差,其中两者均基于当前小批量处理。 接下来,我们应用比例系数和比例偏移。 正是由于这个基于批量统计的标准化,才有了批量规范化的名称. 简单来说,就是对于每个batch每个通道计算.得到三对均值和方差,然后对每个通道规范化.
IN Instance Normalization
Instance Normalization (IN) 最初用于图像的风格迁移。作者发现,在生成模型中, feature map 的各个 channel 的均值和方差会影响到最终生成图像的风格,因此可以先把图像在 channel 层面归一化,然后再用目标风格图片对应 channel 的均值和标准差“去归一化”,以期获得目标图片的风格。IN 操作也在单个样本内部进行,不依赖 batch。
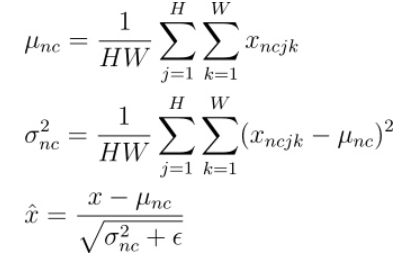
简单点来说,就是对于每个样本,一张彩图三个通道计算,batch=1 用在特定任务比如风格迁移上.
GN Group Normalization
对于特定任务,batch不能过大,否则存在显存占用问题.而一般的BN这时候表现较差.GN 计算均值和标准差时,把每一个样本 feature map 的 channel 分成 G 组,每组将有 C/G 个 channel,然后将这些 channel 中的元素求均值和标准差。各组 channel 用其对应的归一化参数独立地归一化。
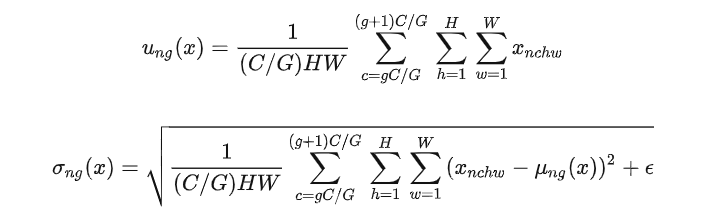
对通道进行分组,统计每个分组通道的高度和宽度,增强对批量大小的稳定性
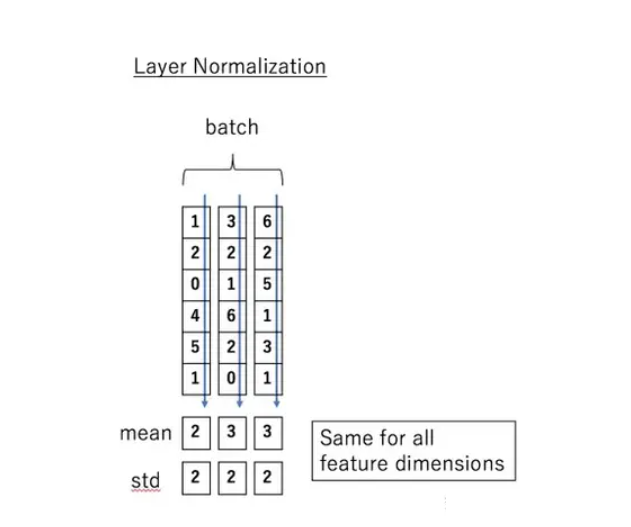
LN Layer Normalization
在使用BN层时,需要的假设是每个mini batch应该是同分布(或者近似同分布)的,如果不同mini batch的分布差异较大,相当于这个BN层需要学习不同的变换,这便无法解决Internal Covariate Shift(ICS,也就是内部偏移)问题。因此,在使用BN层时,batchsize尽可能调大、且数据集彻底打乱,否则BN的效果会显著变差。显而易见,BN也并不适用于需要先后输入数据的RNN模型。
BN并不适用于序列模型(RNN),对于序列数据,我们其实更加关心独立的数据样本(例如一个句子的特定位置的单词),因此Layer Normalization将每一条数据做归一化。
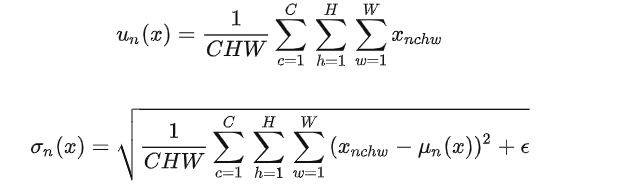
简单来说,就是计算所有通道上的数据得到均值和标准差.
