这种encoder-decoder结构很重要,同时也可以作为学习GAN的前置
Autoencoders
autoencoders是在深度学习经常听到的词,简单来说是基于latent vector,manifold这种概念上的模型,
利用输入数据 本身作为监督,来指导神经网络尝试学习一个映射关系,从而得到一个重构输出 。在时间序列异常检测场景下,异常对于正常来说是少数,所以我们认为,如果使用自编码器重构出来的输出跟原始输入的差异超出一定阈值(threshold)的话,原始时间序列即存在了异常。
An autoencoder is a type of algorithm with the primary purpose of learning an “informative” representation of the data that can be used for different applicationsa by learning to reconstruct a set of input observations well enough.
latent feature又可以叫做潜在向量,潜在特征,bottleneck等等,叫法很多,不要听见新的说法发怵.简单来说就是encoder-decoder架构,不过进行自监督,使用损失函数比较输入和输出. 使用,重建误差(Reconsrtuction Error)体现,重建误差(RE)是一个指标,它可以指示自动编码器能够重建输入观测x的好坏。相比于全连接网络和卷积网络,AE并不需要labeled data, 我们可以使用图像同时作为输入和输出.
The main idea of autoencoder is that we will have an encoder network that converts input image into some latent space (normally it is just a vector of some smaller size), then the decoder network, whose goal would be to reconstruct the original image
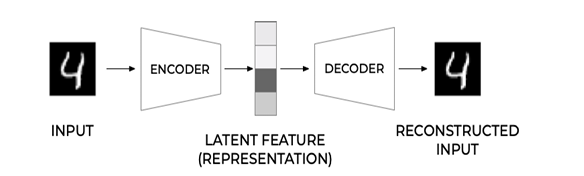
常用于如下用途
- 降低图像的维度以进行可视化或训练图像嵌入。通常,自动编码器比PCA给出更好的结果,因为它考虑了图像的空间性质和层次特征。
- 去噪,即从图像中去除噪声。由于噪声携带了大量无用的信息,自动编码器无法将其全部放入相对较小的潜在空间,因此只能捕获图像的重要部分。在训练去噪器时,我们从原始图像开始,并使用带有人工添加噪声的图像作为自动编码器的输入。
- 超分辨率,提高图像分辨率。我们从高分辨率图像开始,使用分辨率较低的图像作为自动编码器输入。
- 生成模型。一旦我们训练了自动编码器,解码器部分就可以用来从随机潜在向量开始创建新的对象。
缺点是 传统的AE(autoencoders)潜在向量往往没有太多的语义含义,换句话说,以MNIST数据集为例,弄清楚哪些数字对应于不同的潜在向量并不是一项容易的任务,因为接近的潜在向量不一定对应于同一个数字
尝试改变潜变量大小,看看效果.
尝试看看不同图像的潜变量,增加噪声后再查看效果.
AE常用去噪和超分.
对于去噪来说,将没有噪声的图片人工加噪,训练时使用噪声图片作为输入,正常无噪图片作为输出.
To train super-resolution network, we will start with high-resolution images, and automatically downscale them to produce network inputs. We will then feed autoencoder with small images as inputs and high-resolution images as outputs.
对于超分将宽高缩小的图片作为输入,将正常图作为输出.
训练1
2
3
4
5
6
7model = AutoEncoder().to(device)
optimizer = optim.Adam(model.parameters(), lr=lr, eps=eps)
loss_fn = nn.BCELoss()
noisy_tensor = torch.FloatTensor(noisify([256, 1, 28, 28])).to(device)
test_noisy_tensor = torch.FloatTensor(noisify([1, 1, 28, 28])).to(device)
noisy_tensors = (noisy_tensor, test_noisy_tensor)
train(dataloaders, model, loss_fn, optimizer, 100, device, noisy=noisy_tensors)
预测1
2
3
4
5
6
7
8
9
10
11
12
13model.eval()
predictions = []
noise = []
plots = 5
for i, data in enumerate(test_dataset):
if i == plots:
break
shapes = data[0].shape
noisy_data = data[0] + test_noisy_tensor[0].detach().cpu()
noise.append(noisy_data)
predictions.append(model(noisy_data.to(device).unsqueeze(0)).detach().cpu())
plotn(plots, noise)
plotn(plots, predictions)
对于超分,因为输入变化了,考虑潜变量不变,所以encoder需要做一些变化.
VAE
对于图像降维来说影响不大,但要训练生成模型,最好对潜在空间有一些了解。这个想法使我们想到了变分自动编码器(VAE)
VAE是一种自动编码器,它学习预测潜在参数的统计分布,即所谓的潜在分布。

VAE是一种自动编码器,它学习预测潜在参数的统计分布,即所谓的潜在分布。例如,我们可能希望潜在向量正态分布,具有一些均值z~mean~和标准差z~sigma~(均值和标准差都是一些维度d的向量)。VAE中的编码器学习预测这些参数,然后解码器从这个分布中提取一个随机向量来重建对象。
相比于AE简单的损失函数,变分自动编码器使用由两部分组成的复杂损失函数:
- 重建损失是显示重建图像离目标有多近的损失函数(它可以是均方误差或MSE)。它与普通自动编码器中的损失函数相同。
- KL损失,确保潜在变量分布保持接近正态分布。它基于Kullback-Leibler散度的概念,这是一个估计两个统计分布相似程度的指标。
VAE的一个重要优势是,它们使我们能够相对容易地生成新图像,因为我们知道从哪个分布对潜在向量进行采样。例如,如果我们在MNIST上用2D潜在向量训练VAE,那么我们可以改变潜在向量的分量以获得不同的数字1
2
3
4
5
6
7def vae_loss(preds, targets, z_vals):
mse = nn.MSELoss()
reconstruction_loss = mse(preds, targets.view(targets.shape[0], -1)) * 784.0
temp = 1.0 + z_vals[1] - torch.square(z_vals[0]) - torch.exp(z_vals[1]) # ?尽可能使得潜变量与期望的分布kl相近
# 期望正态分布 均值0 方差1
kl_loss = -0.5 * torch.sum(temp, axis=-1) #
return torch.mean(reconstruction_loss + kl_loss)
关键是这里的KL loss,需要使得潜变量与正态分布kl更小,分布更相似. 当我们通过encoder计算出均值和方差的log之后,需要计算其与正态分布的KL,
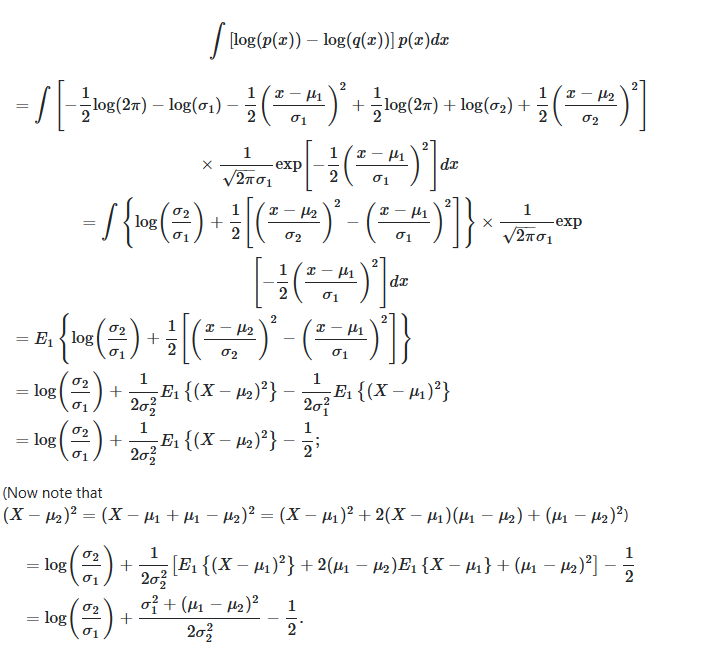
计算正态分布之间的KL散度公式如上.关于VAE这里的KL 散度比较好的回答kullback leibler - Deriving the KL divergence loss for VAEs - Cross Validated (stackexchange.com)
KL散度,是指当某分布q (x)被用于近似p (x)时的信息损失。 KL Divergence 也就是说,q (x)能在多大程度上表达p (x)所包含的信息,KL散度越大,表达效果越差。
所以计算KL时应该是KL(z|n)其中z表示潜变量,n表示正态分布. 目的是利用正态分布描述潜变量的损失.
Training a VAE with The Reparametrization Trick
VAE在反向传播时存在一些计算问题.使用了Reparametrization Trick
AAE
结合GAN和VAE的结构
对抗性自动编码器是生成对抗性网络和变分自动编码器的组合。编码器将是生成器,鉴别器将学习区分编码器输出的真实图像和生成的图像。编码器的输出是一个分布,从这个输出解码器将尝试解码图像。

众所周知,GAN的生成器在训练时使用噪声作为输入,
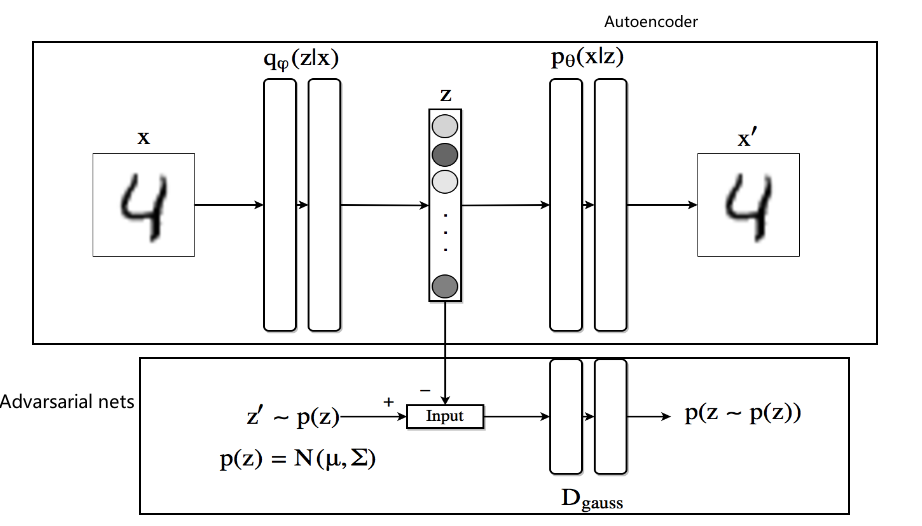
纠正:是Adversarial. 注意,上面一层的autoencoder的encoder也是一个generator,相当于共用了GAN的generator和autoencoder的encoder.首先encoder使用一张图像作为输入,生成的潜变量在VAE中需要减小其与正态分布之间的相似度,也就是优化KL散度,但由于KL散度项的积分除了少数分布之外没有闭合形式的解析解,所以利用GAN的鉴别器,从正态分布中采样的数据与生成的潜变量作为鉴别器的输入进行鉴别,利用这个鉴别器的损失更新鉴别器
更新后,再使用encoder(同时也是generator)以原始图像作为输入,生成潜变量,输入给更新后的鉴别器,鉴别器将其判断为真的概率.
以这种方式定义的损失将迫使鉴别器能够识别假样本,同时推动生成器欺骗鉴别器.
首先,由于编码器的输出必须遵循高斯分布,我们在其最后一层不使用任何非线性。解码器的输出具有S形非线性,这是因为我们使用的输入以其值在0和1之间的方式归一化。鉴别器网络的输出只是0和1之间的一个数字,表示输入来自真实先验分布的概率1
2
3
4
5
6
7
8
9
10
11
12
13
14#Encoder
class Q_net(nn.Module):
def __init__(self):
super(Q_net, self).__init__()
self.lin1 = nn.Linear(X_dim, N)
self.lin2 = nn.Linear(N, N)
self.lin3gauss = nn.Linear(N, z_dim)
def forward(self, x):
x = F.droppout(self.lin1(x), p=0.25, training=self.training)
x = F.relu(x)
x = F.droppout(self.lin2(x), p=0.25, training=self.training)
x = F.relu(x)
xgauss = self.lin3gauss(x)
return xgauss1
2
3
4
5
6
7
8
9
10
11
12
13
14
15# Decoder
class P_net(nn.Module):
def __init__(self):
super(P_net, self).__init__()
self.lin1 = nn.Linear(z_dim, N)
self.lin2 = nn.Linear(N, N)
self.lin3 = nn.Linear(N, X_dim)
def forward(self, x):
x = self.lin1(x)
x = F.dropout(x, p=0.25, training=self.training)
x = F.relu(x)
x = self.lin2(x)
x = F.dropout(x, p=0.25, training=self.training)
x = self.lin3(x)
return F.sigmoid(x)1
2
3
4
5
6
7
8
9
10
11
12
13# Discriminator
class D_net_gauss(nn.Module):
def __init__(self):
super(D_net_gauss, self).__init__()
self.lin1 = nn.Linear(z_dim, N)
self.lin2 = nn.Linear(N, N)
self.lin3 = nn.Linear(N, 1)
def forward(self, x):
x = F.dropout(self.lin1(x), p=0.2, training=self.training)
x = F.relu(x)
x = F.dropout(self.lin2(x), p=0.2, training=self.training)
x = F.relu(x)
return F.sigmoid(self.lin3(x))
所以这里的损失函数定义为重建损失(一般为BCEloss或者cross-entropy loss)和GAN的损失,而GAN的训练一般都是G和D一个训练一下,而之前autoencoder训练时也是把encoder-decoder作为整个模型训练的loss.而这里为了在编码器(也是对抗性网络的生成器)的优化过程中具有独立性,我们为网络的这一部分定义了两个优化器,1
2
3
4
5
6
7
8
9
10
11
12
13
14
15torch.manual_seed(10)
Q, P = Q_net() = Q_net(), P_net(0) # Encoder/Decoder
D_gauss = D_net_gauss() # Discriminator adversarial
if torch.cuda.is_available():
Q = Q.cuda()
P = P.cuda()
D_cat = D_gauss.cuda()
D_gauss = D_net_gauss().cuda()
# Set learning rates
gen_lr, reg_lr = 0.0006, 0.0008
# Set optimizators
P_decoder = optim.Adam(P.parameters(), lr=gen_lr)
Q_encoder = optim.Adam(Q.parameters(), lr=gen_lr)
Q_generator = optim.Adam(Q.parameters(), lr=reg_lr)
D_gauss_solver = optim.Adam(D_gauss.parameters(), lr=reg_lr)
通过编码器/解码器部分进行正向计算,计算重建损失并更新编码器Q和解码器P网络的参数1
2
3
4
5
6
7z_sample = Q(X)
X_sample = P(z_sample)
recon_loss = F.binary_cross_entropy(X_sample + TINY,
X.resize(train_batch_size, X_dim) + TINY)
recon_loss.backward()
P_decoder.step()
Q_encoder.step()
创建一个潜在表示z=Q(x),并从先前的p(z)中提取样本z’,通过鉴别器运行每个样本,并计算分配给每个样本的分数(D(z)和D(z’))1
2
3
4
5Q.eval()
z_real_gauss = Variable(torch.randn(train_batch_size, z_dim) * 5) # Sample from N(0,5)
if torch.cuda.is_available():
z_real_gauss = z_real_gauss.cuda()
z_fake_gauss = Q(X)
训练过程,首先利用encoder-decoder,得到重建后的输出,这里使用二分类交叉熵,计算梯度后更新encoder和decoder的值.然后使用generator(同时也是encoder)使用从高斯分布采样得到的变量作为输入,注意此时需要设置dropout和normalization模式为测试,因为正则目的是为了防止过拟合、加快拟合过程,所以测试、验证时并不需要正则了. 这里Q.eval目的是只需要得到一个生成的潜变量,而不是进行训练.1
2
3
4
5# Compute discriminator outputs and loss
D_real_gauss, D_fake_gauss = D_gauss(z_real_gauss), D_gauss(z_fake_gauss)
D_loss_gauss = -torch.mean(torch.log(D_real_gauss + TINY) + torch.log(1 - D_fake_gauss + TINY))
D_loss_gauss.backward() # Backpropagate loss
D_gauss_solver.step() # Apply optimization step
计算Generator的loss,并相应地更新Q网络1
2
3
4
5
6
7
8# Generator
Q.train() # Back to use dropout
z_fake_gauss = Q(X)
D_fake_gauss = D_gauss(z_fake_gauss)
G_loss = -torch.mean(torch.log(D_fake_gauss + TINY))
G_loss.backward()
Q_generator.step()
由于需要更新Generator,恢复训练模式,
Supervised approach
特征学习最稳健的方法是尽可能多地分解因素,尽可能少地丢弃有关数据的信息
通常来说,如果我们能提供更多信息,将其作为一个全监督的模型.
disentangled representations类似于风格迁移中概念,可以将一张图像中的东西分为内容和风格,进行解耦表示。
我们可以加上类标签的独热码,这其实就是所谓的Conditional GAN
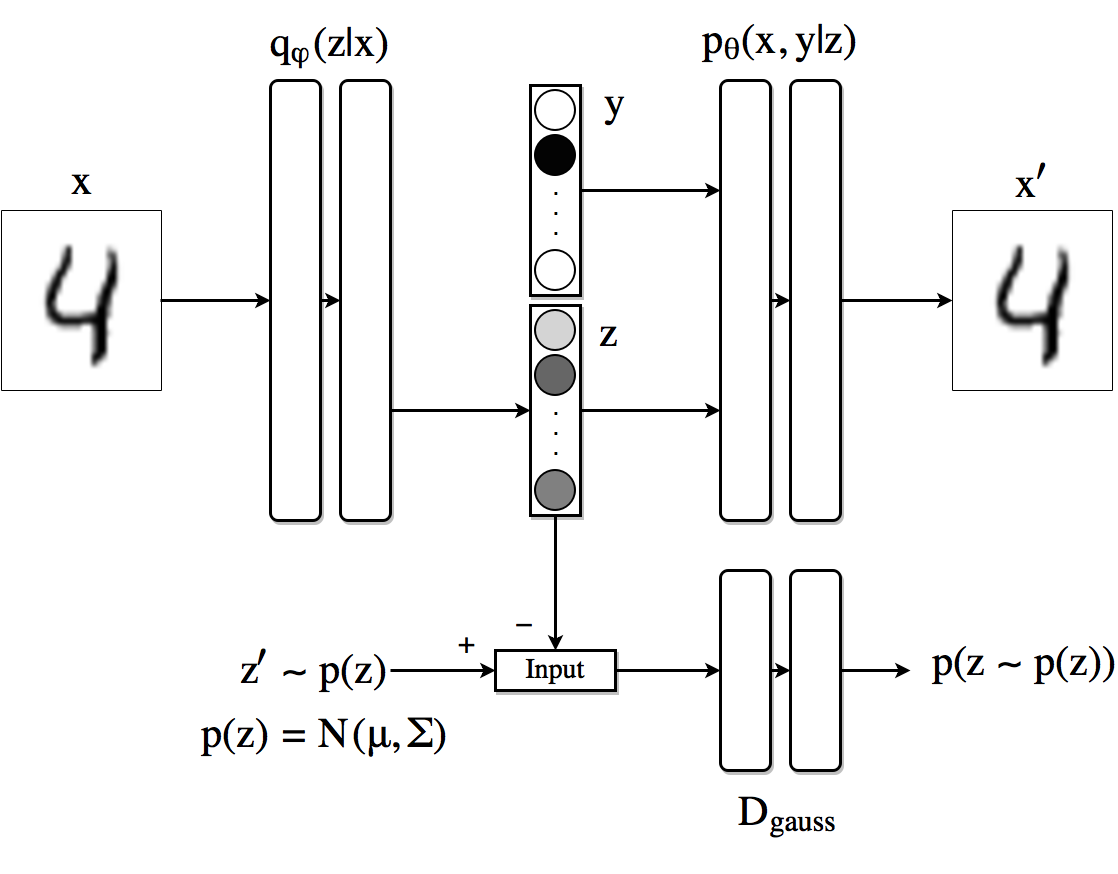
这样在代码上就会增加两个损失函数和一个鉴别器用于分辨产生的label的独热码和真实的label的独热码.

这是教程Adversarial Autoencoders (with Pytorch) (paperspace.com)的图片,使得每一列潜变量第一部分也就是正态分布一样,但类标签不一样,
Semi-supervised approach
下面这种半监督的方式,我们需要将label加入,而这种加入并不是直接把label作为输入给decoder的,而是类似刚才AAE的方式通过GAN使得潜变量分为两个部分,分别是想要的某种分布和label,将class label的one-hot编码,比如说MNIST数据集中,3这个图像的label就是数字三,one-hot编码是0011(因为一共十个数字,需要4位.
我们可以修改以前的体系结构,使AAE产生一个由矢量级联组成的潜变量y指示类或标签(使用Softmax)和连续潜在变量z(使用线性层). 使用softmax作为最后一层的激活函数,这样最后一层输出shape就是(Batch_size,4) 每个值在0-1之间,
通过这种方法还能通过encoder产生的潜变量中的类标签的独热码进行对图像分类,
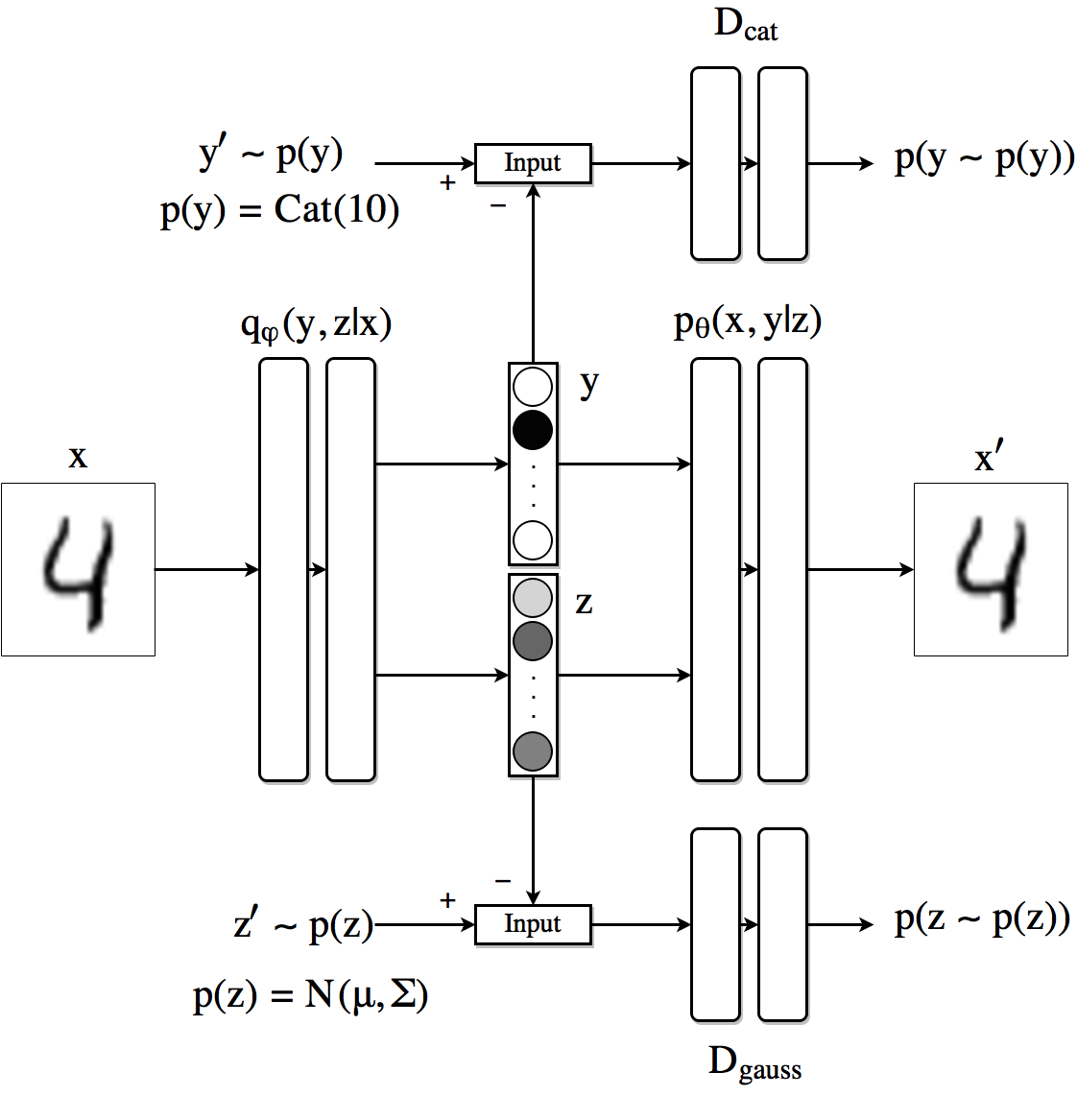
希望向量y表现为一个独热码,我们通过使用鉴别器Dcat的对抗性网络来强制它遵循类别分布。
编码器现在是q(z,y|x)。解码器使用类标签和连续潜变量来重建图像
Conditional Variational Autoencoders
条件变分自动编码器对编码器和解码器都有一个额外的输入。

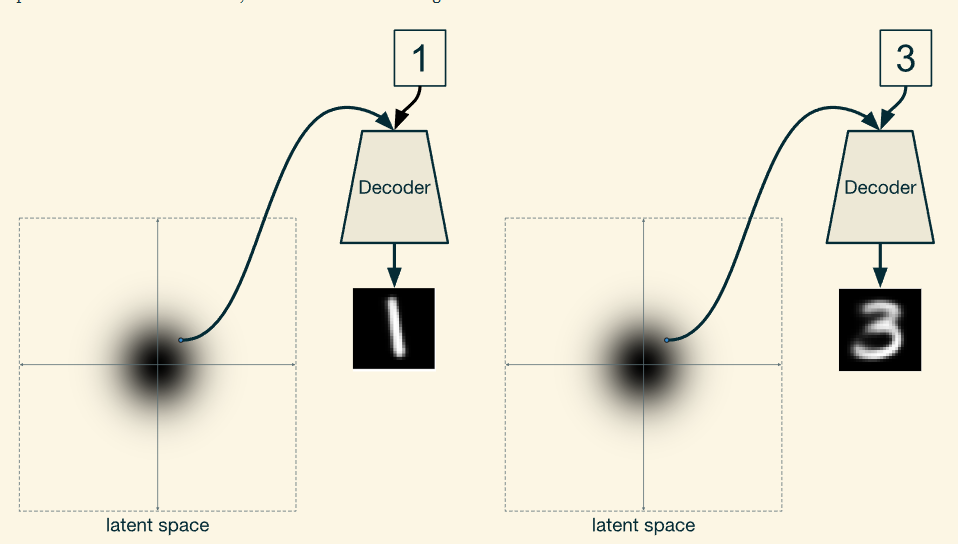
在训练时,将其图像被馈送的数字提供给编码器和解码器。在这种情况下,它将被表示为一个热向量。
要生成特定数字的图像,只需将该数字与从标准正态分布采样的潜在空间中的随机点一起输入解码器即可。即使输入同一点来产生两个不同的数字,这个过程也会正确工作,因为系统不再依赖潜在空间来编码你正在处理的数字。相反,潜在空间对其他信息进行编码,如笔划宽度或数字写入的角度。
参考资料
- AI-For-Beginners/lessons/4-ComputerVision/09-Autoencoders/README.md at main · microsoft/AI-For-Beginners (github.com)
- *2201.03898.pdf (arxiv.org)
- Kullback-Leibler Divergence Explained — Count Bayesie
- normal distribution - KL divergence between two univariate Gaussians - Cross Validated (stackexchange.com)
- Adversarial Autoencoders (with Pytorch) (paperspace.com)
- Conditional Variational Autoencoders (ijdykeman.github.io)
- mathematical statistics - How does the reparameterization trick for VAEs work and why is it important? - Cross Validated (stackexchange.com)
