大模型参数多,结构复杂,因此对于它的压缩非常重要,压缩方法包括pruning,Knowledge Distillation,Quantization等等.事实上这方面的论文相对来说并没有那么多.
这里介绍一下剪枝和蒸馏相关技术.
[2308.07633] A Survey on Model Compression for Large Language Models (arxiv.org)论文整理了一下四种作为大模型压缩的大方法.
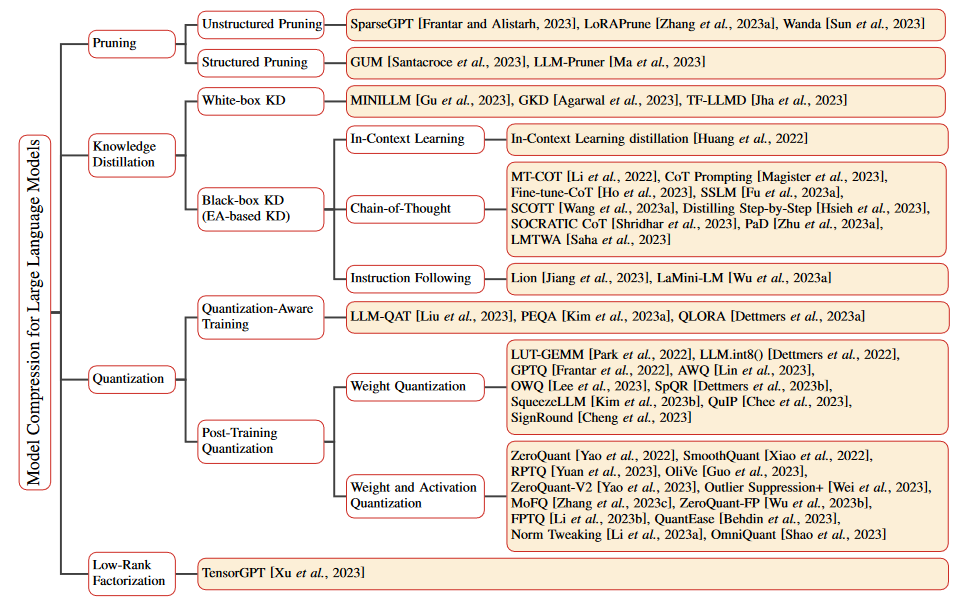
剪枝
剪枝是一种强大的技术,通过去除不必要或冗余的成分来减小模型的大小或复杂度.
可以分为结构化剪枝和非结构化剪枝,区别在于修剪目标和产生的网络结构.
结构化修剪根据特定规则删除连接或层次结构,同时保留整体网络结构。
非结构化修剪法修剪单个参数,形成不规则的稀疏结构。
非结构化修剪
非结构化修剪是在不考虑 LLM 内部结构的情况下,通过删除特定参数来简化 LLM。这种方法的目标是 LLM 中的单个权重或神经元,通常是通过应用一个阈值将低于该阈值的参数清零。然而,这种方法忽略了 LLM 的整体结构,导致模型构成不规则稀疏。
SparseGPT 是这一领域的创新方法。它引入了一种无需重新训练的单次剪枝策略。该方法将剪枝作为一个稀疏回归问题,并使用近似稀疏回归求解器进行求解。SparseGPT 实现了显著的非结构稀疏性,在最大的 GPT 模型(如 OPT-175B 和 BLOOM-176B)上甚至达到了 60%,而复杂度的增加却微乎其微。
与此相反,Syed 等人提出了一种迭代剪枝技术,在剪枝过程中以最少的训练步骤对模型进行微调。另一个进步是 LoRAPrune ,它将参数效率调整(PEFT)方法与剪枝相结合,以提高下游任务的性能。
结构剪枝通过去除神经元、通道或层等整个结构部分来简化 LLM。这种方法一次针对整组权重,具有降低模型复杂性和内存使用量的优势,同时又能保持 LLM 的整体结构不变。
知识蒸馏
知识蒸馏(KD)[Hinton等人,2015;Kim和Rush,2016;Tung和Mori,2019]是一种宝贵的机器学习技术,旨在提高模型性能和泛化能力。它通过将复杂模型(称为教师模型)中的知识转移到较简单的对应模型(称为学生模型)中来实现这一目标。KD 背后的核心思想是将教师模型的综合知识转化为更精简、更有效的表示。
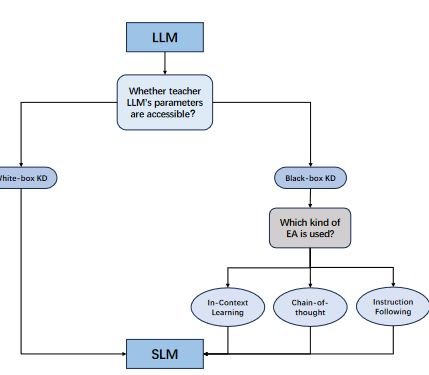
论文中又分为了white-box KD和black-box KD.黑箱 KD,即只能获取教师的预测;白箱 KD,即教师的参数可供使用。
在白盒 KD 中,不仅可以访问教师 LLM 的预测,还可以访问和利用教师 LLM 的参数。这种方法能让学生 LLM 更深入地了解教师 LLM 的内部结构和知识表征,往往能带来更高层次的性能提升。
感觉目前大模型的压缩主要不是剪枝和蒸馏了,而是使用类似LoRA或者Adapter的方法进行微调.
