课程作业
abs
介绍图像融合概念,回顾sota模型,其中包括数字摄像图像融合,多模态图像融合,
接着评估一些代表方法
介绍一些常见应用,比如RGBT目标跟踪,医学图像检查,遥感监测
Intro
动机:
由于硬件设备的理论和技术限制,单一传感器或单一拍摄设置所拍摄的图像无法有效、全面地描述成像场景
图像融合:图像融合能够将不同源图像中的有意义信息结合起来,生成单一图像,该图像包含更丰富的信息,更有利于后续应用
由于融合图像的优异特性,图像融合作为一种图像增强方法已被广泛应用于许多领域,例如摄影可视化
传统融合方法:
在深度学习盛行之前,图像融合已经得到了深入的研究。早期实现图像融合的方法采用相关的数学变换,在空间域或变换域人工分析活动水平并设计融合规则,称为传统融合方法。
典型的传统融合方法包括基于多尺度变换的方法、基于稀疏表示的方法、基于子空间的方法、基于显著性的方法、基于total-variance的方法等。
传统图像融合方法的缺点:
- 为了保证后续图像融合的可行性,传统方法会对不同源的图像采用相同变换来提取特征。这种方法没有考虑到源图像的特征差异,可能导致提取的特征表现力较差。
- 融合策略粗糙,表现较差。
引入深度学习的优势:
可以利用不同的网络实现差异化的特征提取
在良好设计的损失函数下,融合策略可以学到更合理的特征
现有的深度学习方法致力于解决图像融合中的三个主要问题:“feature extraction, feature fusion and image reconstruction.” (Zhang 等, 2021, p. 323)
现有方法可以分为 AutoEncoder-based,CNN- based,GAN-based。
1.AE-based
AE 方法通常会预先训练一个自动编码器。然后利用训练好的自编码器实现特征提取和图像重建,中间的特征融合则根据传统的融合规则实现。
DenseFuse
2.CNN-based
他们通常以两种不同的形式将卷积神经网络引入图像融合。一种是通过使用精心设计的损失函数和网络结构,实现端到端的特征提取、特征融合和图像重建
PMGI。它提出了梯度和强度的比例维护损失,引导网络直接生成融合图像。
另外还有使用CNN得到融合规则,而使用传统的特征提取和重建方法
3.GAN-baesd
GAN 方法依靠生成器和判别器之间的对抗博弈来估计目标的概率分布,从而以隐含的方式共同完成特征提取、特征融合和图像重构
比如FusionGAN 是基于 GAN 的图像融合的先驱,它在融合图像和可见图像之间建立对抗博弈,以进一步丰富融合图像的纹理细节。由于各种图像融合任务存在显著差异,这些方法在不同融合场景中的实现方式也不尽相同。
图像融合场景
digital photography image fusion
由于数字成像设备的性能限制,传感器无法在单一设置完全表征成像场景中的信息
例如,数码摄影产生的图像只能承受有限的光照变化,并具有预定的景深。
多曝光度图像融合和多聚焦图像融合
以产生高动态范围和完全清晰的效果。
人们使用摄像机拍摄时,希望可以获得同一场景中所有景物都清晰的图像。但是摄像机镜头受景深的限制,无法同时聚焦所有目标,因此拍摄的照片中部分区域清晰,部分区域模糊。多聚焦图像融合技术可以将多幅同一场景下聚焦区域不同的图像融合成一幅全清晰的图像,从而有效地解决这个问题,提高图像的信息利用率。
multi-modal image fusion
由于成像原理的限制,单个传感器只能捕捉到部分场景信息。多模态图像融合将多个传感器获取的图像中最重要的信息结合起来,从而实现对场景的有效描述。
典型的多模态图像融合包括红外和可见光图像融合
sharpening fusion
在保证信噪比的前提下,光谱/滤镜与瞬时视场(IFOV)之间存在一定的矛盾。
换句话说,没有任何传感器能同时捕捉高空间分辨率和高光谱分辨率的图像。
锐化融合专门用于融合不同空间/光谱分辨率的图像,以生成所需的结果,这些结果不仅具有高空间分辨率,还具有高光谱分辨率。
典型的锐化融合包括多光谱(MS)锐化和高光谱锐化。从源图像成像的角度来看,锐化融合也属于多模态图像融合。不过,就融合目标而言,锐化融合比上述多模态图像融合要求更高的光谱/空间保真度,能直接提高分辨率。因此,锐化融合将作为一个单独的类别进行讨论。
多光谱锐化是将低空间分辨率(LRMS)的多光谱图像与全色(PAN)图像融合,生成高空间分辨率的多光谱图像。
与多光谱图像相比,高光谱图像具有更高的光谱分辨率和更低的空间分辨率。
多光谱: 谱段有多个,可以看做是高光谱的一种情况,即成像的波段数量比高光谱图像少,一般只有几个到十几个。由于光谱信息其实也就对应了色彩信息,所以多波段遥感图像可以得到地物的色彩信息,但是空间分辨率较低。更进一步,光谱通道越多,其分辨物体的能力就越强,即光谱分辨率越高。
高光谱:高光谱由更窄的波段(10-20 nm)组成,具有较高的光谱分辨率,可以检测物体的光谱特效,可提供更多无形的数据,图像可能有数百或数千个波段
全色图:全色图像是单通道的,其中全色是指全部可见光波段0.38~0.76um,全色图像为这一波段范围的混合图像。因为是单波段,所以在图上显示为灰度图片。全色遥感图像一般空间分辨率高,但无法显示地物色彩,也就是图像的光谱信息少。
digital photography image fusion
数字成像设备利用光学镜头捕捉反射的可见光然后采用CCD和CMOS等书子模块记录场景信息。另一方面,由于动态范围有限,这些数字模块无法承受过大的成像曝光差异。
一方面,由于光学镜头受景深限制,通常无法同时聚焦所有物体。
Infrared and visible image fusion”
红外图像具有明显的对比度,即使在恶劣天气下也能从背景中有效地突出目标。可见光图像包含丰富的纹理细节,更符合人类的视觉感知。红外和可见光图像融合就是要将这两种特性结合起来,生成对比度高、纹理丰富的图像。为了实现这一目标,AE、CNN 和 GAN 方法都被引入到这项任务中。
高对比度,恶劣条件下也能有效突出目标。
可见光图像包含丰富的纹理信息,更符合人类视觉感知。红外和可见光图像融合就是要将这两种特性结合起来,生成对比度高、纹理丰富的图像。为了实现这一目标,AE、CNN 和 GAN 方法都被引入到这项任务中。
AE方法
首先使用数据集训练一个autoencoder,训练好的自动编码器自然可以用来解决图像融合中的两个子问题:特征提取和图像重建
图像融合的关键在于特征融合策略的设计。目前,在红外和可见光图像融合中,特征融合的策略仍然是手工计算的,无法学习,如加法、l1-norm [19]、注意力加权等。这种手工计算的融合策略比较粗糙,限制了红外图像和可见光图像融合的进一步改进。
一种用于红外和可见光图像融合的 CNN 方法是端对端地实现三个子问题。这种CNN结构通常需要残差连接,全连接以及双端结构。
由于红外图像和可见光图像融合没有ground truth,因此损失函数的设计在于确定融合结果和源图像之间对比度和纹理的相似性。
参与红外和可见光图像融合的另一种 CNN 形式是使用预先训练好的网络(如 VGGNet)从源图像中提取特征,并根据这些特征生成融合权重图。
从这个角度看,卷积神经网络只实现了融合,而不考虑特征提取和图像重建,带来的融合性能非常有限。
GAN
GAN 方法是目前红外和可见光图像融合领域最流行的方法,它能够以隐含的方式完成特征提取、特征融合和图像重建。
一般来说,GAN 方法依赖于两种损失函数,即内容损失和对抗损失。内容损失与 CNN 方法类似,用于初步融合源图像,而对抗损失则进一步限制信息融合的趋势。
早期GAN方法 fusionGAN,只是在融合后的图像和可见光图像之间建立对抗博弈,以进一步增强对可见光图像丰富细节的保留。
为了更好地平衡红外信息和可见光信息,随后的方法 [25,66-69] 开始使用具有多个分类约束条件的单一判别器或双判别器来同时估计源图像的两种概率分布。
一般来说,GAN 方法可以产生很好的融合结果。然而,在训练过程中保持生成器和判别器之间的平衡并非易事。
评估
评估指标包括:EN,SSIM,PSNR,SF,SD,CC,SF,VIF以及融合运行时间等等.
EN
熵值

p~l~是融合图像中相应灰度级的归一化直方图
熵越大,融合图像包含的信息就越多,融合方法的性能就越好。
SD
标准差

对比度高的区域总是能吸引人的注意力,而对比度高的融合图像往往能产生较大的标清值,这意味着融合图像能达到更好的视觉效果。
SSIM
结构相似性,取值[-1,1],数值越接近1表示结构相似性越高
SSIM 用于建立图像损失和失真的模型,衡量源图像和融合图像之间的结构相似性。SSIM 主要由三部分组成:相关性损失、亮度失真和对比度失真。
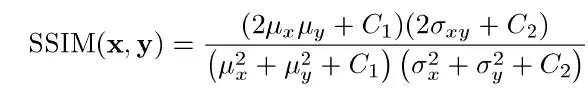
在融合任务中,计算两张源图与融合后图像的SSIM和

PSNR
峰值信噪比,衡量图像有效信息与噪声之间的比率,能够反映图像是否失真.数值越大表示失真越小

Z表示理想参考图像灰度最大值与最小值之差,通常为255。PSNR的值越大,表示融合图像的质量越好。
PSNR值的范围通常在0到100之间,单位为分贝(dB)。 通常情况下,PSNR值越高,表示原始图像与重建图像之间的差异越小,图像质量越接近原始图像。 一般来说,PSNR值在30到40dB之间被认为是可以接受的
CC
CC 衡量融合图像与源图像的线性相关程度,CC 越大,融合后的图像与源图像越相似,融合效果越好


SF 空间频率

测量图像的梯度分布


SF 越大,融合图像的边缘和纹理就越丰富
VIF 空间信息保真度
VIF 衡量融合图像的信息保真度,其计算方法分为四个步骤:首先,将源图像和融合图像划分为不同的区块;然后,评估每个区块在失真和未失真情况下的视觉信息;接着,评估每个子波段的 VIF;最后,根据 VIF 计算总体指标。
数据集
TNO TNO影像融合数据集包含不同军事相关场景的单光谱(增强视觉、近红外和长波红外或热)夜间影像,在不同的多波段camnera系统中注册。
INO RoadScene MSRS LLVIP MFD
实战
主要关注红外图像与可见光图像融合以及多焦点图像融合,从这些出发,最后到一个统一的图像融合框架.
FusionGAN
2019年较早的使用GAN作为图像融合算法融合红外和可见光

Generator

注意损失函数设计
使用了一个对于GAN对抗的融合损失以及一个内容损失,对抗损失,这种想法来源LSGAN,a 和 b 分别表示虚假数据和真实数据的标签,c表示生成器希望鉴别器相信的虚假数据值。
有两种方法可以确定公式中的 a、b 和 c 值。第一种是设置 b - c = 1 和 b - a = 2,从而最小化公式 ,使 P~data~ +P~g~ 与 P~g~ 之间的 Pearson χ2 最小化
第二种是设置 c = b,使生成器生成的样本尽可能真实。上述两种方法通常能获得相似的性能。
第二项 L~content~代表内容损失,λ 用于在 V~FusionGAN~(G) 和 L~content~之间取得平衡。由于红外图像的热辐射信息由其像素强度表征,而可见光图像的纹理细节信息可部分由其梯度表征. 当然可以有其他用于表征图片的某些特性的指标,比如上面介绍的SSIM等.
实际上,如果没有 D~θ~,我们也可以得到融合图像,它可以保留红外图像中的热辐射信息和可见光图像中的梯度信息。
但这往往还不够,因为仅使用梯度信息无法完全表现可见图像中的纹理细节。因此,我们在生成器 G~θG~和判别器 D~θD~ 之间建立了一个对抗博弈,以调整基于可见光图像 IIv 的融合图像 If。
Discriminator
从第一层到第四层,我们在卷积层中使用 3 × 3 滤波器,并将stride设为 2,不带填充。这与生成器网络不同。其根本原因在于,鉴别器是一个分类器,它首先从输入图像中提取特征图,然后进行分类。因此,它的工作方式与池化层相同,将stride设置为 2。

我使用了这个模型
TarDAL
面向检测的融合
我们采用双层优化公式同时进行图像融合和物体检测,不仅检测精度高,而且融合后的图像视觉效果更好。
我们设计了一种参数较少的目标感知双对抗学习网络(TarDAL),用于面向检测的融合。这种 “求同存异 “的单生成器双判别器网络可保留红外目标信息和可见光纹理细节。
我们从双层表述中推导出一种合作训练方案,为快速推理(融合和检测)提供最佳网络参数。
与以往追求高视觉质量的方法不同,我们认为,IVIF 必须生成既有利于视觉检测又有利于计算机感知的图像,即面向检测的融合。
问题建模

假设红外图像、可见光图像和融合图像都是大小为 m×n 的灰度图像,分别用列向量 x、y 和 u∈R^mn×1^ 表示。
L~d~ 是目标检测相关的训练损失,Ψ是一个目标检测网络,f () 是一个基于能量的保真度项,包含融合图像 u 以及源图像 x 和 y,而 g~T~ () 和 g~D~ () 则是两个可行性约束条件,分别定义在红外图像和可见光图像上。

引入一个带有学习参数 ω~f~的融合网络 Φ,并将双级优化转换为单级优化.
因此,我们将优化分解为两个学习网络 Φ 和 Ψ。我们采用 YOLOv53 作为检测网络 Ψ 的主干,其中 L~d~也沿用其设置,并精心设计了融合网络 Φ 。
典型的深度融合方法致力于学习两种不同成像模式的共同特征。相反,我们的融合网络在学习这两种成像方式互补特征的差异的同时,也在寻求共性。通常情况下,红外图像能突出显示目标的独特结构,而可见光图像则能提供背景的纹理细节。
Target-aware dual adversarial network

生成器G生成一张逼真的融合图像,目标判别器D~T~使用强度一致性评估红外图像中的目标与G提供的融合图像中被mask的目标.细节判别器 D~D~判别的是可见光梯度分布与融合图像的梯度分布
生成器
生成器的作用是生成能保留整体结构并保持与源图像相似强度分布的融合图像。常用的结构相似性指数(SSIM)作为损失函数.
为了平衡源图像的像素强度分布,引入了基于突出度权重(SDW)的像素损失。
另外提出了一个基于显著性pixel loss
其中H~x~(i)表示直方图中i的值,x(k)表示第k个值,因为x为一个大小为mn的vector
pixel loss如上,其中
使用 5 层密集块作为 G 来提取共同特征,然后使用包含三个卷积层的合并块进行特征聚合。每个卷积层由一个卷积运算、批处理归一化和 ReLU 激活函数组成。生成的融合图像 u 与源图像大小相同。
目标鉴别器与细节鉴别器
目标判别器 D~T~ 用于将融合结果的前景热目标与红外目标区分开来。而细节判别器 D~D~ 的作用是将融合结果的背景细节与可见光图像的细节区分开来。
采用了预训练的显著性检测网络从红外图像中计算出目标掩码 m,这样两个判别器就能在各自的区域(目标和背景)进行判别(也就是将图像中的目标与背景分割)
对抗损失如下,R(x)表示红外图像中的目标,R(u)表示融合后图像中的目标,R^^^则表示背景
R = x*m ,R^^^= 1 − R. m表示使用预训练模型得到mask.
对于鉴别器,损失分别是
两个鉴别器 D~T~ 和 D~D~ 具有相同的网络结构,即四个卷积层和一个全连接层。

合作训练策略
双层优化自然会衍生出一种合作训练策略,以获得最佳网络参数 ω = (ω~d~, ω~f~)
引入了一个融合正则因子 L^f^,将受融合约束的检测优化转换为相互优化
损失函数包含目标检测的损失函数以及融合的损失函数.
红外与可见光图像的融合结果
定性比较
首先,可以很好地保留红外图像中的分辨目标。如图 6(第二组的绿色缠结)所示,我们的方法中的人表现出高对比度和独特的突出轮廓,因此有利于视觉观察.
其次,我们的结果可以保留可见光图像中丰富的纹理细节(第一组和第三组的绿色缠结),这更符合人类的视觉系统。
定量比较
在 400 个图像对(20 个来自 TNO 的图像对、40 个来自 RoadScene 的图像对和 340 个来自 M3FD 的图像对)上对我们的 TarDAL 和上述竞争对手进行了定量比较。
使用了MI,EN和SD作为评估指标.
红外与可见光目标检测结果
多聚焦图像融合
MFIF-GAN
针对多焦点图像融合
在数码摄影领域,有限的景深(DOF)导致单一场景中可能存在多种图像焦点区域,并产生散焦效应(DSE)[1]。作为一种图像增强技术,多焦点图像融合(MFIF)被用来融合图 1(a) 和图 1(b) 所示的多焦点图像,使融合结果(如图 1(c) 所示)能够清晰地保留来源信息。这一操作是各类计算机视觉(CV)任务的前提条件,例如物体检测和定位、识别和分割
网络结构
MFIF-GAN 中的生成器将源彩色图像 IA 和 IB 作为输入,旨在生成焦点图 ̂ F。判别器的输入是 IA、IB 和(真实或生成的)焦点图的连接。生成器的目的是尽可能精确地重建焦点图,而鉴别器的目的是将生成的焦点图与真实的焦点图区分开来。
G 包括一个编码器、一个张量连接模块和一个解码器。为了有效处理彩色图像,编码器被设计成六个并行子网络分支,共享源图像每个通道的参数。
FuseGAN
我们的目标是通过构建基于 cGAN 的网络 FuseGAN,学习从源图像到置信度图的映射,从而为融合任务提供重点信息。我们首先详细介绍了该架构,然后分析了其目标函数;最后阐述了融合方案.
生成器 G:如图所示,生成器 G 由三个部分组成:编码器、张量并合器和解码器。它将一对多焦点图像作为输入,并输出置信度图。具体来说,编码器有两个分支,每个分支包含 12 个块。为简单起见,我们将卷积层、批规范层和转置卷积层分别称为 Conv、BN 和 Decov。其中,第一块是 Conv-BN-ReLu,滤波器尺寸较大,为 7×7,步长为 1,目的是粗略提取特征。

我们利用 中的 PatchGAN 作为判别器 D。从概念上讲,它试图辨别图像中每个大小为 K×K 的patch是真是假。鉴别器对图像中的所有响应进行卷积平均,最后生成输出。。

因此,我们利用自适应权重块设计的特定内容损失函数可以自适应地引导融合图像在像素级逼近源图像中重点区域的强度分布和梯度分布
此外,由于我们的优化目标是基于每个像素,为了避免融合后的图像出现色差,保证整体的自然度,我们增加了 SSIM 损失项。根据统计学原理,计算每个源图像片段中较大分数的平均值,作为相应 SSIM 损失项的权重。
MFFGAN
图像融合的理念是从源图像中提取并组合最有意义的信息。对于多焦点图像融合来说,最有意义的信息是源图像中的锐利区域,这些区域反映在强度分布和纹理细节上。自然,在信息提取过程中,应保留锐利区域的这些信息,而摒弃模糊区域的这些信息。
当然,在信息提取过程中,尖锐区域的信息应该保留,模糊区域的信息应该舍弃。因此,有必要在优化过程中引入损失函数的调整机制,以约束网络有选择地提取和重构信息。
首先,我们设计了一个自适应决策块,它可以根据重复模糊原理评估每个像素的清晰度,也就是说,清晰度较高的图像,经过模糊处理后,像素值变化较大。根据这一观察结果,生成screening map来描述有效信息的位置。screening map作用于我们构建的特定内容损失函数,从而在像素尺度上调整优化目标。
判定块可以自适应地引导融合结果在像素尺度上逼近清晰源图像的强度分布和梯度分布
.我们的具体方法是选择分数较大的像素(放弃较小的分数)作为两个源图像相应像素位置的优化目标。在决策块和内容损失的共同作用下,生成器可以得到相对清晰自然的结果。
我们将联合梯度图定义为真实数据,将融合图像的梯度图定义为假数据。持续的对抗性学习可以引导生成器更专注于纹理的保留。因此,我们可以获得更高质量的融合结果,其中包含更丰富的纹理细节。
损失函数
损耗函数由生成器损耗L~G~和鉴别器损耗L~D~组成。
生成器
生成器的损失有两部分,即用于提取和重构信息的内容损失L~Gcon~,以及用于增强纹理细节的对抗性损失L~Gadv~。
其中 N 是训练期间批次中融合图像的数量,a 是生成器期望判别器确定融合图像的概率标签
重复模糊函数
LP (⋅) 表示低通滤波器函数。值得注意的是,S(⋅)的大小也是H × W。
判别器
判别器的损失功能使判别器能够准确识别真假数据。在我们的方法中,假数据是融合图像的梯度图。真实数据是我们构建的联合梯度图。
其中 b 是融合图像梯度图的标签,应设置为 0。c 是联合梯度图的标签,应设置为 1。
也就是说,判别器期望准确地将联合梯度图识别为真实数据,将融合图像的梯度图识别为假数据。在这种约束下,判别器可以引导生成器在信息维护方面的倾向,即有利于强纹理保存.
总体架构

生成器架构
我们将生成器拆分为两条路径来提取信息,对应于两个源图像。生成器网络的设计灵感来自pseudo-Siamese,它擅长处理两种相对不同的输入。由于多焦点图像对在相应的像素位置清晰或模糊,因此pseudo-Siamese网络适用于此类图像

在这两条路径中,都有四个卷积层来提取特征。第一个卷积层使用 5 × 5 卷积核,其余三个卷积层使用 3 × 3 卷积核。它们都使用 Leaky ReLU 作为激活函数。为了防止卷积过程中的信息丢失,我们根据 DenseNet 的思想重用了这些特征.
同时,为了提取更充分的信息,我们在两条路径之间交换信息。具体来说,交换的信息是通过连接和卷积的方法生成的。然后,交换的信息与所有前一个卷积层的输出连接在一起,作为下一个卷积层的输入。
最后,我们将两条路径中所有卷积层的输出串联起来,然后通过卷积层生成融合图像。卷积层的核大小为 1 × 1,激活函数为 tanh。值得注意的是,在所有卷积层中,填充模式设置为“SAME”,即特征图的大小在整个卷积过程中没有变化,这与源图像的大小相同。
判别器架构

判别器中的输入有两种类型,一种是基于源图像的联合梯度图和融合图像的梯度图。鉴别器由四个卷积层和一个线性层组成。四个卷积层的卷积核大小为 3 × 3,它们都使用了LeakyReLU 激活函数。这些卷积层的步幅设置为 2。最后一层是用于查找分类概率的线性层。
训练细节
我们的实验是在两个数据集上进行的,比如Lytro数据集[34]和我们基于公共数据库构建的MFI-WHU数据集。
在 Lytro 数据集和 MFI-WHU 数据集上,用于测试的图像对数分别为 10 和 30。对于训练,为了获得更多的训练数据,我们采用了剪裁分解的扩展策略。具体来说,对于 Lytro 数据集,我们将其余图像裁剪为 22,090 个大小为 60 × 60 的图像图块对进行训练;对于 MFI-WHU 数据集,我们将其余图像裁剪为 202,246 个大小为 60 × 60 的图像patch对进行训练。
batch_size=32,epochs=20,训练一个epoch需要m步数,将一张图片分为多个patch,m设置为所有patch数除以b. 一般考虑训练更多的判别器,训练判别器次数是生成器的p倍.

我们将图像从 RGB 转换为 YCbCr 色彩空间。由于 Y 通道(亮度通道)可以表示结构细节和亮度变化,因此我们只致力于融合 Y 通道值。对于 Cb 和 Cr 通道(色度通道),我们以传统方式融合它们。然后,将这些通道的融合分量转移到RGB以获得最终结果。
一些结果
多焦图像融合


红外可见光图像融合

代码链接
drowning-in-codes/UFGAN: GAN for Image Fusion which is inspired by FusionGAN and U-net (github.com)
colab 链接UFGAN.ipynb - Colaboratory (google.com)
一些想法
利用预训练模型提供内容和风格 transfer learning?
利用cGAN思想? 此外损失函数的设计有必要换成神经网络而不是人工设计的一些值了.可以看看一篇CVPR的TARDALhttp://arxiv.org/abs/2203.16220
