介绍现在的各种各样(空间上,通道上)的attention模块以及相关代码.
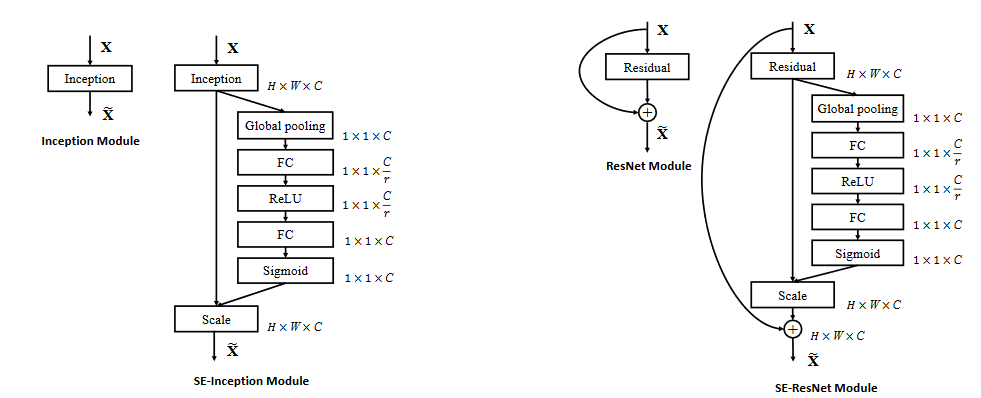
Squeeze-and-Excitation Networks 2018

- SENet通过学习channel之间的相关性,筛选出了针对通道的注意力,稍微增加了一点计算量,但是效果提升较明显
- Squeeze-and-Excitation(SE) block是一个子结构,可以有效地嵌到其他分类或检测模型中。
- SENet的核心思想在于通过网络根据loss去学习feature map的特征权重来使模型达到更好的结果
- SE模块本质上是一种attention机制
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38import numpy as np
import torch
from torch import nn
from torch.nn import init
# implement SEAttention
class SEAttention(nn.Module):
def __init__(self, channel=512, reduction=16):
super(SEAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction),
nn.ReLU(),
nn.Linear(channel // reduction, channel),
nn.Sigmoid()
)
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
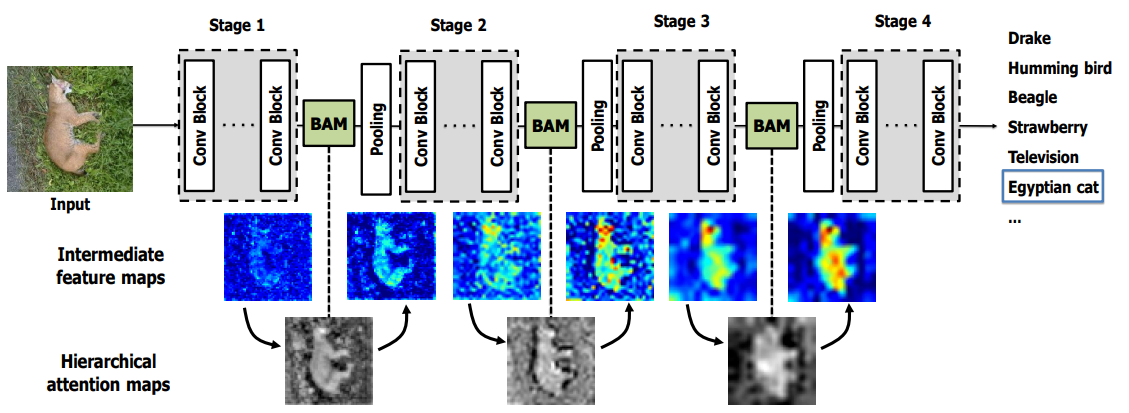
Bottlenet attention Module (BAM) 2018
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83import torch
import torch.nn as nn
from torch.nn import init
class Flatten(nn.Module):
def forward(self, input):
return input.view(input.size(0), -1)
class ChannelAttention(nn.Module):
def __init__(self,channel,reduction:int=16,num_layer:int=3):
super().__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
gate_channels = [channel]
gate_channels += [channel // reduction] * num_layer
gate_channels += [channel]
self.ca = nn.Sequential()
self.ca.add_module('flatten',Flatten())
for i in range(num_layer):
self.ca.add_module('fc{}'.format(i),nn.Linear(gate_channels[i],gate_channels[i+1]))
self.ca.add_module('bn%d' % i, nn.BatchNorm1d(gate_channels[i+1]))
self.ca.add_module('relu{}'.format(i),nn.ReLU())
self.ca.add_module('last_fc',nn.Linear(gate_channels[-2],gate_channels[-1]))
def forward(self,x):
res = self.avg_pool(x)
res = self.ca(res)
return res.unsqueeze(-1).unsqueeze(-1).expand_as(x)
class SpatialAttention(nn.Module):
def __init__(self,channel,reduction=16,num_layers=3,dia_val=2):
super().__init__()
self.sa = nn.Sequential()
self.sa.add_module('conv_reduce1',nn.Conv2d(in_channels=channel,out_channels=channel//reduction,kernel_size=1))
self.sa.add_module('bn_reduce1',nn.BatchNorm2d(channel//reduction))
self.sa.add_module('relu_reduce1',nn.ReLU())
for i in range(num_layers):
self.sa.add_module('conv_%d' % i,nn.Conv2d(in_channels=channel//reduction,out_channels=channel//reduction,kernel_size=3,padding=1,dilation=dia_val))
self.sa.add_module('bn_%d' % i,nn.BatchNorm2d(channel//reduction))
self.sa.add_module('relu_%d' % i,nn.ReLU())
self.sa.add_module('conv_last',nn.Conv2d(in_channels=channel//reduction,out_channels=channel,kernel_size=1))
def forward(self,x):
res = self.sa(x)
return res.expand_as(x)
class BAMBlock(nn.Module):
def __init__(self,channel:int=512,reduction:int=16,dia_val:int=2):
super().__init__()
self.ca = ChannelAttention(channel=channel,reduction=reduction)
self.sa = SpatialAttention(channel=channel,reduction=reduction,dia_val=dia_val)
self.sigmoid = nn.Sigmoid()
self.init_weights()
def forward(self,x):
b, c, _, _ = x.size()
sa_out = self.sa(x)
ca_out = self.ca(x)
weight = self.sigmoid(sa_out + ca_out)
out = (1 + weight) * x
return out
def init_weights(self):
# initial weights for the model
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_in', nonlinearity='relu')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m,nn.BatchNorm2d):
init.constant_(m.weight,1)
init.constant_(m.bias,0)
elif isinstance(m,nn.Linear):
init.normal_(m.weight,std=0.001)
if m.bias is not None:
init.constant_(m.bias,0)

DANet: Dual Attention Network 2018

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46class PositionAttentionModule(nn.Module):
def __init__(self,d_model=512,kernel_size=3,H=7,W=7):
super().__init__()
self.cnn=nn.Conv2d(d_model,d_model,kernel_size=kernel_size,padding=(kernel_size-1)//2)
self.pa=ScaledDotProductAttention(d_model,d_k=d_model,d_v=d_model,h=1)
def forward(self,x):
bs,c,h,w=x.shape
y=self.cnn(x)
y=y.view(bs,c,-1).permute(0,2,1) #bs,h*w,c
y=self.pa(y,y,y) #bs,h*w,c
return y
class ChannelAttentionModule(nn.Module):
def __init__(self,d_model=512,kernel_size=3,H=7,W=7):
super().__init__()
self.cnn=nn.Conv2d(d_model,d_model,kernel_size=kernel_size,padding=(kernel_size-1)//2)
self.pa=SimplifiedScaledDotProductAttention(H*W,h=1)
def forward(self,x):
bs,c,h,w=x.shape
y=self.cnn(x)
y=y.view(bs,c,-1) #bs,c,h*w
y=self.pa(y,y,y) #bs,c,h*w
return y
class DAModule(nn.Module):
def __init__(self,d_model=512,kernel_size=3,H=7,W=7):
super().__init__()
self.position_attention_module=PositionAttentionModule(d_model=512,kernel_size=3,H=7,W=7)
self.channel_attention_module=ChannelAttentionModule(d_model=512,kernel_size=3,H=7,W=7)
def forward(self,input):
bs,c,h,w=input.shape
p_out=self.position_attention_module(input)
c_out=self.channel_attention_module(input)
p_out=p_out.permute(0,2,1).view(bs,c,h,w)
c_out=c_out.view(bs,c,h,w)
return p_out+c_out
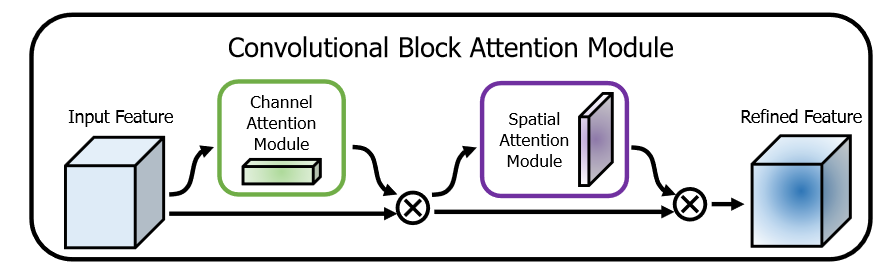
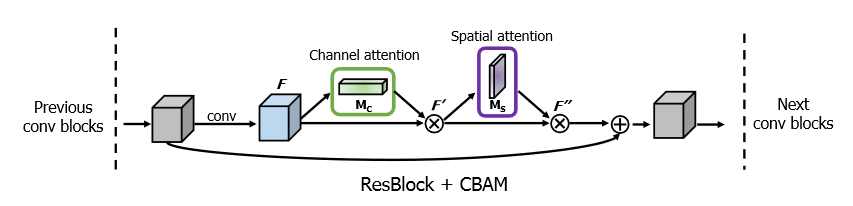
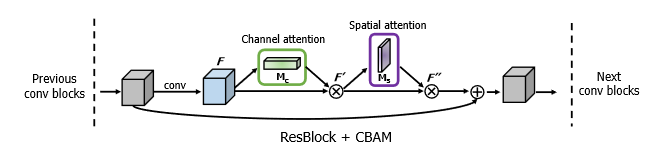
CBAM: Convolutional Block Attention Module 2018
通道注意力1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes // 16, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // 16, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
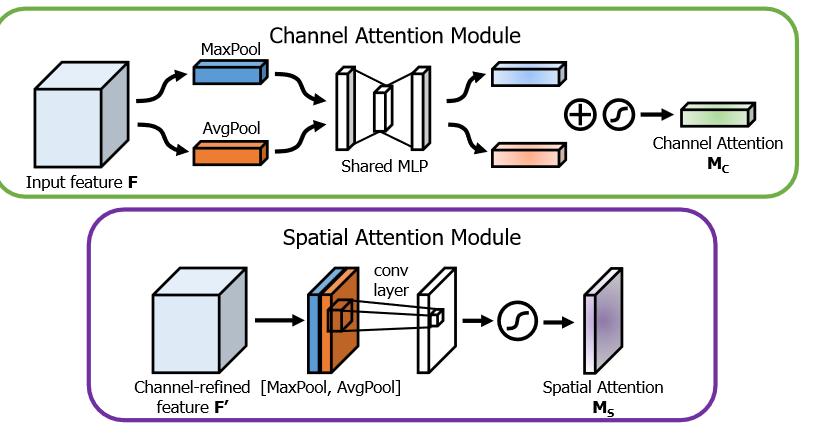
空间注意力1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
Non-Local 2018
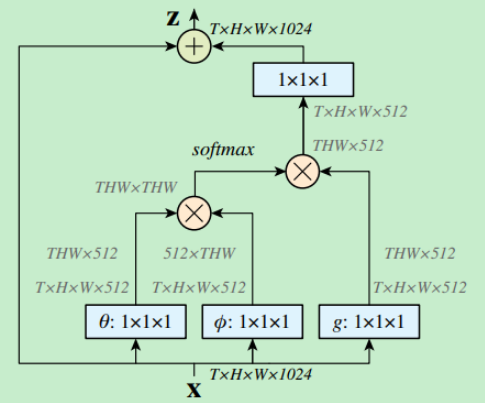
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24import torch
import torch.nn as nn
class NonLocalNet(nn.Module):
def __init__(self, input_dim=64, output_dim=64):
super(NonLocalNet, self).__init__()
intermediate_dim = input_dim // 2
self.to_q = nn.Conv2d(input_dim, intermediate_dim, 1)
self.to_k = nn.Conv2d(input_dim, intermediate_dim, 1)
self.to_v = nn.Conv2d(input_dim, intermediate_dim, 1)
self.conv = nn.Conv2d(intermediate_dim, output_dim, 1)
def forward(self, x):
q = self.to_q(x).squeeze()
k = self.to_k(x).squeeze()
v = self.to_v(x).squeeze()
u = torch.bmm(q, k.transpose(1, 2))
u = torch.softmax(u, dim=1)
out = torch.bmm(u, v)
out = out.unsqueeze(2)
out = self.conv(out)
return out + x
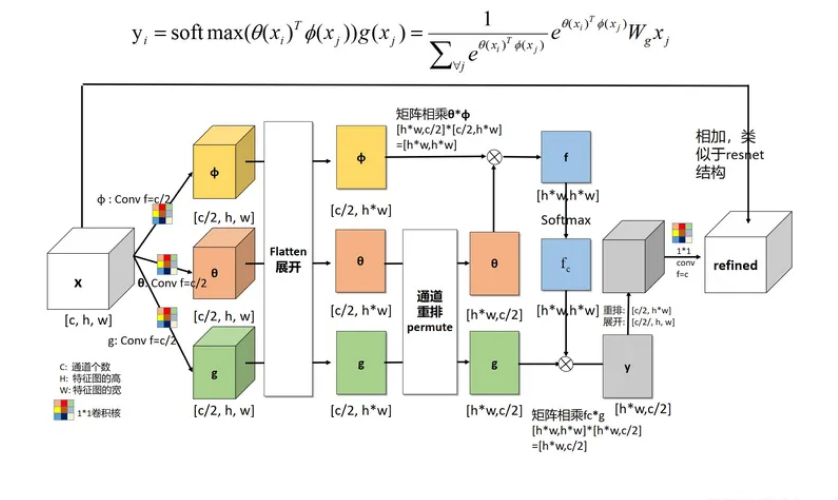
SKNet 2019
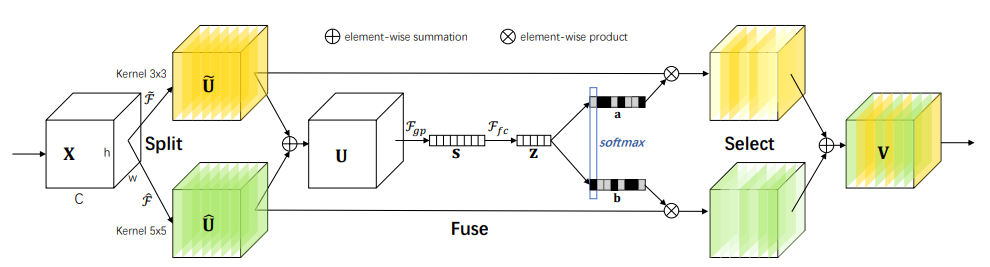
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57class SKConv(nn.Module):
"""
https://arxiv.org/pdf/1903.06586.pdf
"""
def __init__(self, feature_dim, WH, M, G, r, stride=1, L=32):
""" Constructor
Args:
features: input channel dimensionality.
WH: input spatial dimensionality, used for GAP kernel size.
M: the number of branchs.
G: num of convolution groups.
r: the radio for compute d, the length of z.
stride: stride, default 1.
L: the minimum dim of the vector z in paper, default 32.
"""
super().__init__()
d = max(int(feature_dim / r), L)
self.M = M
self.feature_dim = feature_dim
self.convs = nn.ModuleList()
for i in range(M):
self.convs.append(nn.Sequential(
nn.Conv2d(feature_dim, feature_dim, kernel_size=3 + i * 2, stride=stride, padding=1 + i, groups=G),
nn.BatchNorm2d(feature_dim),
nn.ReLU(inplace=False)
))
self.gap = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(feature_dim, d)
self.fcs = nn.ModuleList()
for i in range(M):
self.fcs.append(
nn.Linear(d, feature_dim)
)
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
for i, conv in enumerate(self.convs):
feat = conv(x).unsqueeze_(dim=1)
if i == 0:
feas = feat
else:
feas = torch.cat((feas, feat), dim=1)
fea_U = torch.sum(feas, dim=1)
fea_s = self.gap(fea_U).squeeze_()
fea_z = self.fc(fea_s)
for i, fc in enumerate(self.fcs):
vector = fc(fea_z).unsqueeze_(dim=1)
if i == 0:
attention_vectors = vector
else:
attention_vectors = torch.cat((attention_vectors, vector), dim=1)
attention_vectors = self.softmax(attention_vectors)
attention_vectors = attention_vectors.unsqueeze(-1).unsqueeze(-1)
fea_v = (feas*attention_vectors).sum(dim=1)
return fea_v
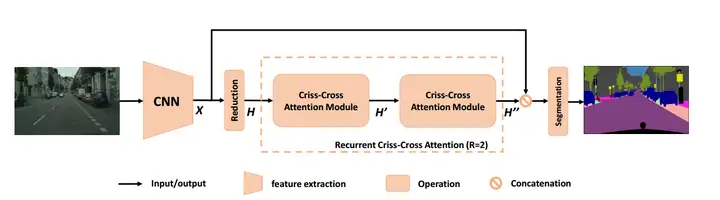
CC-Net和Axial Attention
看论文时提到了CC-Net使用了交叉注意了.
参考Axial Attention 和 Criss-Cross Attention及其代码实现 | 码农家园 (codenong.com)这篇blog,写的不错.
Axial Attention
轴向注意力,Axial Attention 的感受野是目标像素的同一行(或者同一列) 的W(或H)个像素
比如row attention1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73#实现轴向注意力中的 row Attention
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn import Softmax
# device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
device = torch.device('cuda:0' if torch.cuda.device_count() > 1 else 'cpu')
class RowAttention(nn.Module):
def __init__(self, in_dim, q_k_dim, device):
'''
Parameters
----------
in_dim : int
channel of input img tensor
q_k_dim: int
channel of Q, K vector
device : torch.device
'''
super(RowAttention, self).__init__()
self.in_dim = in_dim
self.q_k_dim = q_k_dim
self.device = device
self.query_conv = nn.Conv2d(in_channels=in_dim, out_channels = self.q_k_dim, kernel_size=1)
self.key_conv = nn.Conv2d(in_channels=in_dim, out_channels = self.q_k_dim, kernel_size=1)
self.value_conv = nn.Conv2d(in_channels=in_dim, out_channels = self.in_dim, kernel_size=1)
self.softmax = Softmax(dim=2)
self.gamma = nn.Parameter(torch.zeros(1)).to(self.device)
def forward(self, x):
'''
Parameters
----------
x : Tensor
4-D , (batch, in_dims, height, width) -- (b,c1,h,w)
'''
## c1 = in_dims; c2 = q_k_dim
b, _, h, w = x.size()
Q = self.query_conv(x) #size = (b,c2, h,w)
K = self.key_conv(x) #size = (b, c2, h, w)
V = self.value_conv(x) #size = (b, c1,h,w)
Q = Q.permute(0,2,1,3).contiguous().view(b*h, -1,w).permute(0,2,1) #size = (b*h,w,c2)
K = K.permute(0,2,1,3).contiguous().view(b*h, -1,w) #size = (b*h,c2,w)
V = V.permute(0,2,1,3).contiguous().view(b*h, -1,w) #size = (b*h, c1,w)
#size = (b*h,w,w) [:,i,j] 表示Q的所有h的第 Wi行位置上所有通道值与 K的所有h的第 Wj列位置上的所有通道值的乘积,
# 即(1,c2) * (c2,1) = (1,1)
row_attn = torch.bmm(Q,K)
########
#此时的 row_atten的[:,i,0:w] 表示Q的所有h的第 Wi行位置上所有通道值与 K的所有行的 所有列(0:w)的逐个位置上的所有通道值的乘积
#此操作即为 Q的某个(i,j)与 K的(i,0:w)逐个位置的值的乘积,得到行attn
########
#对row_attn进行softmax
row_attn = self.softmax(row_attn) #对列进行softmax,即[k,i,0:w] ,某一行的所有列加起来等于1,
#size = (b*h,c1,w) 这里先需要对row_atten进行 行列置换,使得某一列的所有行加起来等于1
#[:,i,j]即为V的所有行的某个通道上,所有列的值 与 row_attn的行的乘积,即求权重和
out = torch.bmm(V,row_attn.permute(0,2,1))
#size = (b,c1,h,2)
out = out.view(b,h,-1,w).permute(0,2,1,3)
out = self.gamma*out + x
return out
#实现轴向注意力中的 cols Attention
x = torch.randn(4, 8, 16, 20).to(device)
row_attn = RowAttention(in_dim = 8, q_k_dim = 4,device = device).to(device)
print(row_attn(x).size())
列注意力同理1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79#实现轴向注意力中的 column Attention
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn import Softmax
# device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
device = torch.device('cuda:0' if torch.cuda.device_count() > 1 else 'cpu')
class ColAttention(nn.Module):
def __init__(self, in_dim, q_k_dim, device):
'''
Parameters
----------
in_dim : int
channel of input img tensor
q_k_dim: int
channel of Q, K vector
device : torch.device
'''
super(ColAttention, self).__init__()
self.in_dim = in_dim
self.q_k_dim = q_k_dim
self.device = device
self.query_conv = nn.Conv2d(in_channels=in_dim, out_channels = self.q_k_dim, kernel_size=1)
self.key_conv = nn.Conv2d(in_channels=in_dim, out_channels = self.q_k_dim, kernel_size=1)
self.value_conv = nn.Conv2d(in_channels=in_dim, out_channels = self.in_dim, kernel_size=1)
self.softmax = Softmax(dim=2)
self.gamma = nn.Parameter(torch.zeros(1)).to(self.device)
def forward(self, x):
'''
Parameters
----------
x : Tensor
4-D , (batch, in_dims, height, width) -- (b,c1,h,w)
'''
## c1 = in_dims; c2 = q_k_dim
b, _, h, w = x.size()
Q = self.query_conv(x) #size = (b,c2, h,w)
K = self.key_conv(x) #size = (b, c2, h, w)
V = self.value_conv(x) #size = (b, c1,h,w)
Q = Q.permute(0,3,1,2).contiguous().view(b*w, -1,h).permute(0,2,1) #size = (b*w,h,c2)
K = K.permute(0,3,1,2).contiguous().view(b*w, -1,h) #size = (b*w,c2,h)
V = V.permute(0,3,1,2).contiguous().view(b*w, -1,h) #size = (b*w,c1,h)
#size = (b*w,h,h) [:,i,j] 表示Q的所有W的第 Hi行位置上所有通道值与 K的所有W的第 Hj列位置上的所有通道值的乘积,
# 即(1,c2) * (c2,1) = (1,1)
col_attn = torch.bmm(Q,K)
########
#此时的 col_atten的[:,i,0:w] 表示Q的所有W的第 Hi行位置上所有通道值与 K的所有W的 所有列(0:h)的逐个位置上的所有通道值的乘积
#此操作即为 Q的某个(i,j)与 K的(i,0:h)逐个位置的值的乘积,得到列attn
########
#对row_attn进行softmax
col_attn = self.softmax(col_attn) #对列进行softmax,即[k,i,0:w] ,某一行的所有列加起来等于1,
#size = (b*w,c1,h) 这里先需要对col_atten进行 行列置换,使得某一列的所有行加起来等于1
#[:,i,j]即为V的所有行的某个通道上,所有列的值 与 col_attn的行的乘积,即求权重和
out = torch.bmm(V,col_attn.permute(0,2,1))
#size = (b,c1,h,w)
out = out.view(b,w,-1,h).permute(0,2,3,1)
out = self.gamma*out + x
return out
#实现轴向注意力中的 cols Attention
x = torch.randn(4, 8, 16, 20).to(device)
col_attn = ColAttention(8, 4, device = device)
print(col_attn(x).size())
Criss-Cross Attention Module 2019
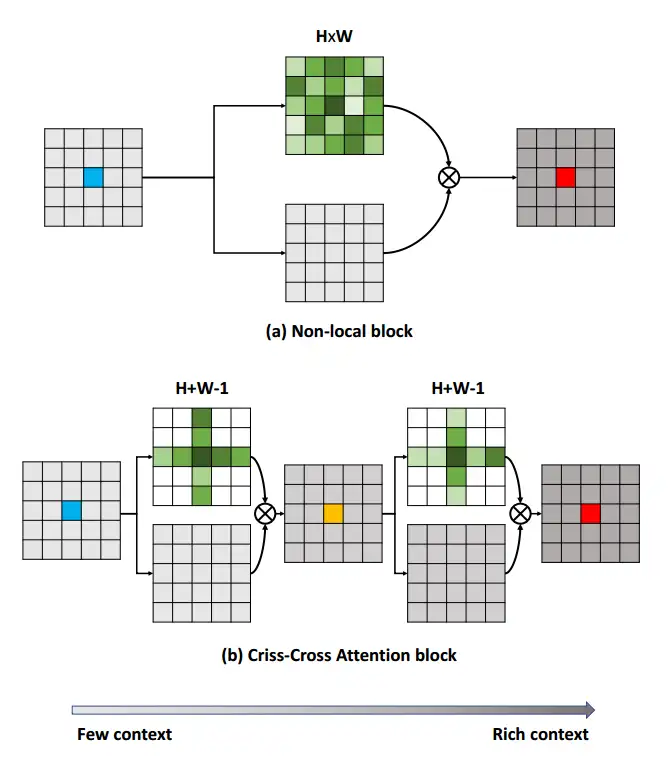
CC-Attention 的感受野是与目标像素的同一行和同一列的(H + W - 1)个像素,目标元素的同一行和同一列.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58class CrissCrossAttention(nn.Module):
""" Criss-Cross Attention Module
reference: https://github.com/speedinghzl/CCNet
"""
def __init__(self, in_dim):
super(CrissCrossAttention,self).__init__()
self.query_conv = nn.Sequential(
nn.Conv2d(in_channels=in_dim, out_channels=in_dim, kernel_size=1),
nn.BatchNorm2d(in_dim,eps=1e-5, momentum=0.01, affine=True),
nn.ReLU()
)
self.key_conv = nn.Sequential(
nn.Conv2d(in_channels=in_dim, out_channels=in_dim, kernel_size=1),
nn.BatchNorm2d(in_dim,eps=1e-5, momentum=0.01, affine=True),
nn.ReLU()
)
self.value_conv = nn.Sequential(
nn.Conv2d(in_channels=in_dim, out_channels=in_dim, kernel_size=1),
nn.BatchNorm2d(in_dim,eps=1e-5, momentum=0.01, affine=True),
nn.ReLU()
)
self.softmax = Softmax(dim=3)
self.INF = INF
self.gamma = nn.Parameter(torch.zeros(1))
def forward(self, query, key, value):
m_batchsize, _, height, width = query.size()
proj_query = self.query_conv(query)
proj_query_H = proj_query.permute(0,3,1,2).contiguous().view(m_batchsize*width,-1,height).permute(0, 2, 1)
proj_query_W = proj_query.permute(0,2,1,3).contiguous().view(m_batchsize*height,-1,width).permute(0, 2, 1)
proj_key = self.key_conv(key)
proj_key_H = proj_key.permute(0,3,1,2).contiguous().view(m_batchsize*width,-1,height)
proj_key_W = proj_key.permute(0,2,1,3).contiguous().view(m_batchsize*height,-1,width)
proj_value = self.value_conv(value)
proj_value_H = proj_value.permute(0,3,1,2).contiguous().view(m_batchsize*width,-1,height)
proj_value_W = proj_value.permute(0,2,1,3).contiguous().view(m_batchsize*height,-1,width)
energy_H = (torch.bmm(proj_query_H, proj_key_H)+self.INF(m_batchsize, height, width)).view(m_batchsize,width,height,height).permute(0,2,1,3)
energy_W = torch.bmm(proj_query_W, proj_key_W).view(m_batchsize,height,width,width)
concate = self.softmax(torch.cat([energy_H, energy_W], 3))
att_H = concate[:,:,:,0:height].permute(0,2,1,3).contiguous().view(m_batchsize*width,height,height)
att_W = concate[:,:,:,height:height+width].contiguous().view(m_batchsize*height,width,width)
out_H = torch.bmm(proj_value_H, att_H.permute(0, 2, 1)).view(m_batchsize,width,-1,height).permute(0,2,3,1)
out_W = torch.bmm(proj_value_W, att_W.permute(0, 2, 1)).view(m_batchsize,height,-1,width).permute(0,2,1,3)
return self.gamma*(out_H + out_W) + value
Coordinate Attention 2021
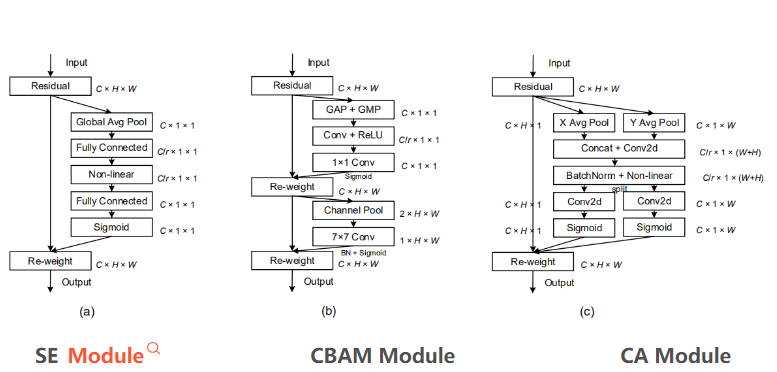
在通道注意力的基础上兼顾其位置关系,将通道注意力与空间注意力联合起来1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(
class CA(nn.Module):
def __init__(self, inp, reduction):
super(CA, self).__init__()
# h:height(行) w:width(列)
self.pool_h = nn.AdaptiveAvgPool2d((None, 1)) # (b,c,h,w)-->(b,c,h,1)
self.pool_w = nn.AdaptiveAvgPool2d((1, None)) # (b,c,h,w)-->(b,c,1,w)
# mip = max(8, inp // reduction) 论文作者所用
mip = inp // reduction
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, inp, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, inp, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n, c, h, w = x.size()
x_h = self.pool_h(x) # (b,c,h,1)
x_w = self.pool_w(x).permute(0, 1, 3, 2) # (b,c,w,1)
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = identity * a_w * a_h
return out
Attentional Feature Fusion 2021
WACV 2021 Open Access Repository (thecvf.com)
YimianDai/open-aff: code and trained models for “Attentional Feature Fusion” (github.com)
这些注意力模块通常用在一些block(或叫unit)块中,然后一般把这些块放到多尺度的网络下
参考资料
- Axial Attention 和 Criss-Cross Attention及其代码实现_cross attention代码-CSDN博客
- sknet阅读笔记及pytorch实现代码_pytorch sknet-CSDN博客
- 【注意力机制集锦】Channel Attention通道注意力网络结构、源码解读系列一_通道注意力机制结构图-CSDN博客
- 【注意力机制集锦2】BAM&SGE&DAN原文、结构、源码详解_bam注意力机制-CSDN博客
Thanks to lyp2333/External-Attention-pytorch (github.com) and xmu-xiaoma666/External-Attention-pytorch: 🍀 Pytorch implementation of various Attention Mechanisms, MLP, Re-parameter, Convolution, which is helpful to further understand papers.⭐⭐⭐ (github.com)
