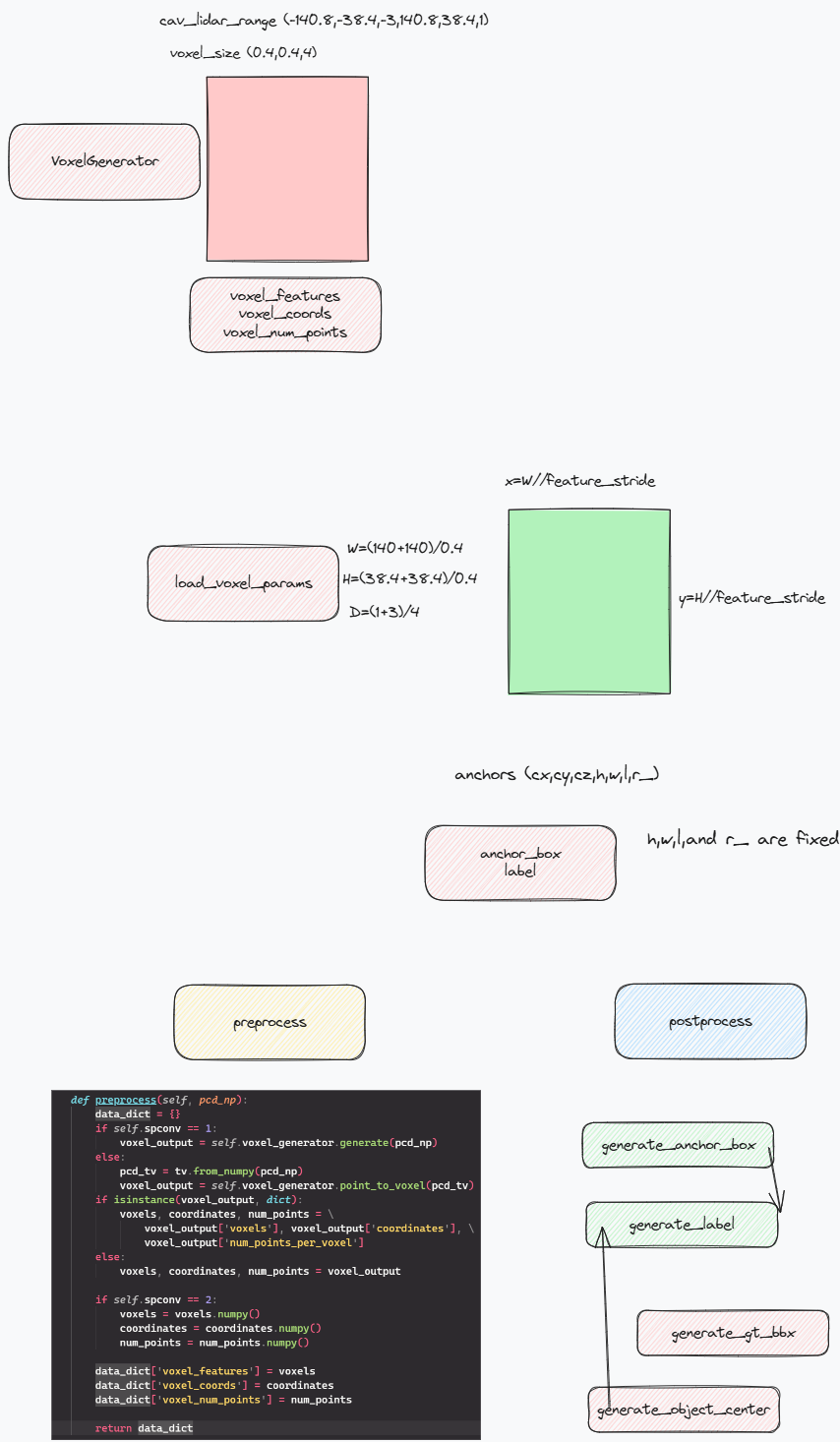
代码还是很重要的,虽然发现有些代码库不怎么样.
目前协同感知算法主要就是利用注意力机制和图神经网络,利用backbone(包括voxelNet,Point Pillar等网络)处理后的特征进行融合,具体的codebase我找到三个(此外还有很多基于OpenCOOD的多模态、关注其他问题的代码,这里就放一些基础的).
- 一个是coperception/where2comm: [NeurIPS 2022] Where2comm (github.com),
- 还有GT-RIPL/MultiAgentPerception: Official source code to CVPR’20 paper, “When2com: Multi-Agent Perception via Communication Graph Grouping” (github.com).
- 另一个是DerrickXuNu/OpenCOOD: [ICRA 2022] An opensource framework for cooperative detection. Official implementation for OPV2V. (github.com).可以说包含许多20年到现在的经典车辆协同感知的算法代码了,此外还有一些零散的算法代码,这里咱就细细把玩一下.
Coperceptions
包括where2comm,v2vnet,disconet,v2x-vit以及when2comm的代码.

本身有mean,max,cat以及agent的融合方式.1
2
3
4
5
6
7
8class MeanFusion(FusionBase):
def __init__(self, n_channels, n_classes, num_agent=5, compress_level=0, only_v2i=False):
super().__init__(
n_channels, n_classes, num_agent=num_agent, compress_level=compress_level, only_v2i=only_v2i
)
def fusion(self):
return torch.mean(torch.stack(self.neighbor_feat_list), dim=0)
继承自FusionBase,而FusionBase又继承自SegModelBase,后者实现了一系列模型.在FusionBase中,首先对特征进行下采样,然后转换除了ego agent的特征,然后进行融合,最后再上采样.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84from coperception.models.seg.SegModelBase import SegModelBase
import torch
import torch.nn.functional as F
class FusionBase(SegModelBase):
def __init__(
self, n_channels, n_classes, num_agent=5, kd_flag=False, compress_level=0, only_v2i=False
):
super().__init__(
n_channels, n_classes, num_agent=num_agent, compress_level=compress_level, only_v2i=only_v2i
)
self.neighbor_feat_list = None
self.tg_agent = None
self.current_num_agent = None
self.kd_flag = kd_flag
self.only_v2i = only_v2i
def fusion(self):
raise NotImplementedError(
"Please implement this method for specific fusion strategies"
)
def forward(self, x, trans_matrices, num_agent_tensor):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3) # b 512 32 32
size = (1, 512, 32, 32)
if self.compress_level > 0:
x4 = F.relu(self.bn_compress(self.com_compresser(x4)))
x4 = F.relu(self.bn_decompress(self.com_decompresser(x4)))
batch_size = x.size(0) // self.num_agent
feat_list = super().build_feat_list(x4, batch_size)
local_com_mat = torch.cat(tuple(feat_list), 1)
local_com_mat_update = torch.cat(tuple(feat_list), 1)
for b in range(batch_size):
self.com_num_agent = num_agent_tensor[b, 0]
agent_feat_list = list()
for nb in range(self.com_num_agent):
agent_feat_list.append(local_com_mat[b, nb])
for i in range(self.com_num_agent):
self.tg_agent = local_com_mat[b, i]
self.neighbor_feat_list = list()
self.neighbor_feat_list.append(self.tg_agent)
for j in range(self.com_num_agent):
if j != i:
if self.only_v2i and i != 0 and j != 0:
continue
self.neighbor_feat_list.append(
super().feature_transformation(
b,
j,
i,
local_com_mat,
size,
trans_matrices,
)
)
local_com_mat_update[b, i] = self.fusion()
feat_mat = super().agents_to_batch(local_com_mat_update)
x5 = self.down4(feat_mat)
x6 = self.up1(x5, feat_mat)
x7 = self.up2(x6, x3)
x8 = self.up3(x7, x2)
x9 = self.up4(x8, x1)
logits = self.outc(x9)
if self.kd_flag:
return logits, x9, x8, x7, x6, x5, feat_mat
else:
return logits
使用了连续的下采样和上采样,先下采样,然后进行融合再进行上采样.这几种融合方式真是一层套一层,这么多参数效果不变强才怪…1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80class SegModelBase(nn.Module):
def __init__(
self, n_channels, n_classes, bilinear=True, num_agent=5, compress_level=0, only_v2i=False
):
super().__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
self.num_agent = num_agent
self.only_v2i = only_v2i
self.inc = DoubleConv(n_channels, 64)
self.down1 = Down(64, 128)
self.down2 = Down(128, 256)
self.down3 = Down(256, 512)
factor = 2 if bilinear else 1
self.down4 = Down(512, 1024 // factor)
self.up1 = Up(1024, 512 // factor, bilinear)
self.up2 = Up(512, 256 // factor, bilinear)
self.up3 = Up(256, 128 // factor, bilinear)
self.up4 = Up(128, 64, bilinear)
self.outc = OutConv(64, n_classes)
self.compress_level = compress_level
if compress_level > 0:
assert compress_level <= 9
feat_map_channel_num = 512
compress_channel_num = feat_map_channel_num // (2**compress_level)
self.com_compresser = nn.Conv2d(
feat_map_channel_num, compress_channel_num, kernel_size=1, stride=1
)
self.bn_compress = nn.BatchNorm2d(compress_channel_num)
self.com_decompresser = nn.Conv2d(
compress_channel_num, feat_map_channel_num, kernel_size=1, stride=1
)
self.bn_decompress = nn.BatchNorm2d(feat_map_channel_num)
def build_feat_list(self, feat_maps, batch_size):
feat_maps = torch.flip(feat_maps, (2,))
tmp_feat_map = {}
feat_list = []
for i in range(self.num_agent):
tmp_feat_map[i] = torch.unsqueeze(
feat_maps[batch_size * i : batch_size * (i + 1)], 1
)
feat_list.append(tmp_feat_map[i])
return feat_list
def feature_transformation(b, j, agent_idx, local_com_mat, size, trans_matrices):
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
nb_agent = torch.unsqueeze(local_com_mat[b, j], 0)
tfm_ji = trans_matrices[b, j, agent_idx]
M = (
torch.hstack((tfm_ji[:2, :2], -tfm_ji[:2, 3:4])).float().unsqueeze(0)
) # [1,2,3]
M = M.to(device)
mask = torch.tensor([[[1, 1, 4 / 128], [1, 1, 4 / 128]]], device=M.device)
M *= mask
grid = F.affine_grid(M, size=torch.Size(size))
warp_feat = F.grid_sample(nb_agent, grid).squeeze()
return warp_feat
def agents_to_batch(self, feats):
feat_list = []
for i in range(self.num_agent):
feat_list.append(feats[:, i, :, :, :])
feat_mat = torch.cat(feat_list, 0)
feat_mat = torch.flip(feat_mat, (2,))
return feat_mat1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50class DoubleConv(nn.Module):
def __init__(self, in_channels, out_channels, mid_channels=None):
super().__init__()
if not mid_channels:
mid_channels = out_channels
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
)
def forward(self, x):
return self.double_conv(x)
class Down(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.maxpool_conv = nn.Sequential(
nn.MaxPool2d(2),
DoubleConv(in_channels, out_channels),
)
def forward(self, x):
return self.maxpool_conv(x)
class Up(nn.Module):
def __init__(self, in_channels, out_channels, bilinear=True):
super().__init__()
if bilinear:
self.up = nn.Upsample(scale_factor=2, mode="bilinear", align_corners=True)
self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)
else:
self.up = nn.ConvTranspose2d(
in_channels, in_channels // 2, kernel_size=2, stride=2
)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
x1 = self.up(x1)
diff_y = x2.size()[2] - x1.size()[2]
diff_x = x2.size()[3] - x1.size()[3]
x1 = F.pad(
x1, [diff_x // 2, diff_x - diff_x // 2, diff_y // 2, diff_y - diff_y // 2]
)
x = torch.cat([x2, x1], dim=1)
return self.conv(x)
mean,max和sum不用多说,1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32import torch
from coperception.models.seg.FusionBase import FusionBase
class SumFusion(FusionBase):
def __init__(self, n_channels, n_classes, num_agent=5, compress_level=0, only_v2i=False):
super().__init__(
n_channels, n_classes, num_agent=num_agent, compress_level=compress_level, only_v2i=only_v2i
)
def fusion(self):
return torch.sum(torch.stack(self.neighbor_feat_list), dim=0)
class MeanFusion(FusionBase):
def __init__(self, n_channels, n_classes, num_agent=5, compress_level=0, only_v2i=False):
super().__init__(
n_channels, n_classes, num_agent=num_agent, compress_level=compress_level, only_v2i=only_v2i
)
def fusion(self):
return torch.mean(torch.stack(self.neighbor_feat_list), dim=0)
class MaxFusion(FusionBase):
def __init__(self, n_channels, n_classes, num_agent=5, compress_level=0, only_v2i=False):
super().__init__(
n_channels, n_classes, num_agent=num_agent, compress_level=compress_level, only_v2i=only_v2i
)
def fusion(self):
return torch.max(torch.stack(self.neighbor_feat_list), dim=0).values
catFusion将其他特征做个mean然后与自己的特征连接起来.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27class CatFusion(FusionBase):
def __init__(self, n_channels, n_classes, num_agent, compress_level, only_v2i):
super().__init__(
n_channels, n_classes, num_agent=num_agent, compress_level=compress_level, only_v2i=only_v2i
)
self.modulation_layer_3 = ModulationLayer3()
def fusion(self):
mean_feat = torch.mean(torch.stack(self.neighbor_feat_list), dim=0) # [c, h, w]
cat_feat = torch.cat([self.tg_agent, mean_feat], dim=0)
cat_feat = cat_feat.unsqueeze(0) # [1, 1, c, h, w]
return self.modulation_layer_3(cat_feat)
# FIXME: Change size
class ModulationLayer3(nn.Module):
def __init__(self):
super(ModulationLayer3, self).__init__()
self.conv1_1 = nn.Conv2d(1024, 512, kernel_size=1, stride=1, padding=0)
self.bn1_1 = nn.BatchNorm2d(512)
def forward(self, x):
x = x.view(-1, x.size(-3), x.size(-2), x.size(-1))
x_1 = F.relu(self.bn1_1(self.conv1_1(x)))
return x_1
此外还有个AgentWiseWeightedFusion,每个ego_agent单独和每个其他特征cat在一起再通过,然后计算一个融合特征,再计算一个softmax作为特征的权重.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27class AgentWiseWeightedFusion(FusionBase):
def __init__(self, n_channels, n_classes, num_agent=5, compress_level=0, only_v2i=False):
super().__init__(
n_channels, n_classes, num_agent=num_agent, compress_level=compress_level, only_v2i=only_v2i
)
self.agent_weighted_fusion = AgentWeightedFusion()
def fusion(self):
agent_weight_list = list()
for k in range(self.com_num_agent):
cat_feat = torch.cat([self.tg_agent, self.neighbor_feat_list[k]], dim=0)
cat_feat = cat_feat.unsqueeze(0)
agent_weight = self.agent_weighted_fusion(cat_feat)
agent_weight_list.append(agent_weight)
soft_agent_weight_list = torch.squeeze(
F.softmax(torch.tensor(agent_weight_list).unsqueeze(0), dim=1)
)
agent_wise_weight_feat = 0
for k in range(self.com_num_agent):
agent_wise_weight_feat = (
agent_wise_weight_feat
+ soft_agent_weight_list[k] * self.neighbor_feat_list[k]
)
return agent_wise_weight_feat
discoNet特别之处就在于使用了所谓学生-教师模型进行知识蒸馏,在代码中添加了这个.1
2
3
4
5
6
7
8parser.add_argument(
"--kd_flag",
default=0,
type=int,
help="Whether to enable distillation (only DiscNet is 1 )",
)
# 还添加了权重参数,可见权重加得还挺大的.
parser.add_argument("--kd_weight", default=100000, type=int, help="KD loss weight")
然后类似AgentWiseWeightedFusion,将ego的特征与通信的单独每辆车的特征cat在一起传入一个网络中,计算得到所有值的幂和.然后再用各自的值乘以和(跟softmax差不多).算按出来权重再乘以对应的特征.最后的值是相加起来1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39class DiscoNet(FusionBase):
def __init__(
self, n_channels, n_classes, num_agent, kd_flag=True, compress_level=0, only_v2i=False
):
super().__init__(
n_channels,
n_classes,
num_agent,
kd_flag=kd_flag,
compress_level=compress_level,
only_v2i=only_v2i,
)
self.pixel_weighted_fusion = PixelWeightedFusionSoftmax(512)
def fusion(self):
tmp_agent_weight_list = list()
sum_weight = 0
nb_len = len(self.neighbor_feat_list)
for k in range(nb_len):
cat_feat = torch.cat([self.tg_agent, self.neighbor_feat_list[k]], dim=0)
cat_feat = cat_feat.unsqueeze(0)
agent_weight = torch.squeeze(self.pixel_weighted_fusion(cat_feat))
tmp_agent_weight_list.append(torch.exp(agent_weight))
sum_weight = sum_weight + torch.exp(agent_weight)
agent_weight_list = list()
for k in range(nb_len):
agent_weight = torch.div(tmp_agent_weight_list[k], sum_weight)
agent_weight.expand([256, -1, -1])
agent_weight_list.append(agent_weight)
agent_wise_weight_feat = 0
for k in range(nb_len):
agent_wise_weight_feat = (
agent_wise_weight_feat
+ agent_weight_list[k] * self.neighbor_feat_list[k]
)
return agent_wise_weight_feat
V2VNet

说实话,看了代码感觉也就那样…1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149# -*- coding: utf-8 -*-
# Author: Hao Xiang <haxiang@g.ucla.edu>
# License: TDG-Attribution-NonCommercial-NoDistrib
"""
Implementation of V2VNet Fusion
"""
import torch
import torch.nn as nn
from opencood.models.sub_modules.torch_transformation_utils import \
get_discretized_transformation_matrix, get_transformation_matrix, \
warp_affine, get_rotated_roi
from opencood.models.sub_modules.convgru import ConvGRU
class V2VNetFusion(nn.Module):
def __init__(self, args):
super(V2VNetFusion, self).__init__()
in_channels = args['in_channels']
H, W = args['conv_gru']['H'], args['conv_gru']['W']
kernel_size = args['conv_gru']['kernel_size']
num_gru_layers = args['conv_gru']['num_layers']
self.discrete_ratio = args['voxel_size'][0]
self.downsample_rate = args['downsample_rate']
self.num_iteration = args['num_iteration']
self.gru_flag = args['gru_flag']
self.agg_operator = args['agg_operator']
self.msg_cnn = nn.Conv2d(in_channels * 2, in_channels, kernel_size=3,
stride=1, padding=1)
self.conv_gru = ConvGRU(input_size=(H, W),
input_dim=in_channels * 2,
hidden_dim=[in_channels],
kernel_size=kernel_size,
num_layers=num_gru_layers,
batch_first=True,
bias=True,
return_all_layers=False)
self.mlp = nn.Linear(in_channels, in_channels)
def regroup(self, x, record_len):
cum_sum_len = torch.cumsum(record_len, dim=0)
split_x = torch.tensor_split(x, cum_sum_len[:-1].cpu())
return split_x
def forward(self, x, record_len, pairwise_t_matrix):
"""
Fusion forwarding.
Parameters
----------
x : torch.Tensor
input data, (B, C, H, W)
record_len : list
shape: (B)
pairwise_t_matrix : torch.Tensor
The transformation matrix from each cav to ego,
shape: (B, L, L, 4, 4)
Returns
-------
Fused feature.
"""
_, C, H, W = x.shape
B, L = pairwise_t_matrix.shape[:2]
# split x:[(L1, C, H, W), (L2, C, H, W)]
split_x = self.regroup(x, record_len)
# (B,L,L,2,3)
pairwise_t_matrix = get_discretized_transformation_matrix(
pairwise_t_matrix.reshape(-1, L, 4, 4), self.discrete_ratio,
self.downsample_rate).reshape(B, L, L, 2, 3)
# (B*L,L,1,H,W)
roi_mask = get_rotated_roi((B * L, L, 1, H, W),
pairwise_t_matrix.reshape(B * L * L, 2, 3))
roi_mask = roi_mask.reshape(B, L, L, 1, H, W)
batch_node_features = split_x
# iteratively update the features for num_iteration times
for l in range(self.num_iteration):
batch_updated_node_features = []
# iterate each batch
for b in range(B):
# number of valid agent
N = record_len[b]
# (N,N,4,4)
# t_matrix[i, j]-> from i to j
t_matrix = pairwise_t_matrix[b][:N, :N, :, :]
updated_node_features = []
# update each node i
for i in range(N):
# (N,1,H,W)
mask = roi_mask[b, :N, i, ...]
current_t_matrix = t_matrix[:, i, :, :]
current_t_matrix = get_transformation_matrix(
current_t_matrix, (H, W))
# (N,C,H,W)
neighbor_feature = warp_affine(batch_node_features[b],
current_t_matrix,
(H, W))
# (N,C,H,W)
ego_agent_feature = batch_node_features[b][i].unsqueeze(
0).repeat(N, 1, 1, 1)
#(N,2C,H,W)
neighbor_feature = torch.cat(
[neighbor_feature, ego_agent_feature], dim=1)
# (N,C,H,W)
message = self.msg_cnn(neighbor_feature) * mask
# (C,H,W)
if self.agg_operator=="avg":
agg_feature = torch.mean(message, dim=0)
elif self.agg_operator=="max":
agg_feature = torch.max(message, dim=0)[0]
else:
raise ValueError("agg_operator has wrong value")
# (2C, H, W)
cat_feature = torch.cat(
[batch_node_features[b][i, ...], agg_feature], dim=0)
# (C,H,W)
if self.gru_flag:
gru_out = \
self.conv_gru(cat_feature.unsqueeze(0).unsqueeze(0))[
0][
0].squeeze(0).squeeze(0)
else:
gru_out = batch_node_features[b][i, ...] + agg_feature
updated_node_features.append(gru_out.unsqueeze(0))
# (N,C,H,W)
batch_updated_node_features.append(
torch.cat(updated_node_features, dim=0))
batch_node_features = batch_updated_node_features
# (B,C,H,W)
out = torch.cat(
[itm[0, ...].unsqueeze(0) for itm in batch_node_features], dim=0)
# (B,C,H,W)
out = self.mlp(out.permute(0, 2, 3, 1)).permute(0, 3, 1, 2)
return out
有的实现没有RNN比如上面代码,也有的用了RNN和LSTM.后者代码代码简直就是屎…
V2xvit
1 | import math |
关键是脱离了agent2agent,而是vehicle2everything,向异构多模态发展.
DiscoNet
主要是利用了蒸馏,教师-学生模型这种理论.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16if args.kd_flag == 1:
teacher = TeacherNet(config)
teacher = nn.DataParallel(teacher)
teacher = teacher.to(device)
faf_module = FaFModule(
model, teacher, config, optimizer, criterion, args.kd_flag
)
checkpoint_teacher = torch.load(args.resume_teacher)
start_epoch_teacher = checkpoint_teacher["epoch"]
faf_module.teacher.load_state_dict(checkpoint_teacher["model_state_dict"])
print(
"Load teacher model from {}, at epoch {}".format(
args.resume_teacher, start_epoch_teacher
)
)
faf_module.teacher.eval()
先使用tearcherNet拿数据进行训练,然后拿训练后的模型加载1
2
3
4
5
6
7
8
9
10class TeacherNet(NonIntermediateModelBase):
"""The teacher net for knowledged distillation in DiscoNet."""
def __init__(self, config):
super(TeacherNet, self).__init__(config, compress_level=0)
def forward(self, bevs, maps=None, vis=None):
bevs = bevs.permute(0, 1, 4, 2, 3) # (Batch, seq, z, h, w)
# vis = vis.permute(0, 3, 1, 2)
return self.stpn(bevs)
使用教师模型得到的结果和原本模型得到的结果(一些中间融合层)计算损失,代码中用的KL交叉熵损失1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78def get_kd_loss(self, batch_size, data, fused_layer, num_agent, x_5, x_6, x_7):
if self.kd_flag:
bev_seq_teacher = data["bev_seq_teacher"]
kd_weight = data["kd_weight"]
(
x_8_teacher,
x_7_teacher,
x_6_teacher,
x_5_teacher,
x_3_teacher,
x_2_teacher,
) = self.teacher(bev_seq_teacher)
# for k, v in self.teacher.named_parameters():
# if k != 'xxx.weight' and k != 'xxx.bias':
# print(v.requires_grad) # should be False
# for k, v in self.model.named_parameters():
# if k != 'xxx.weight' and k != 'xxx.bias':
# print(v.requires_grad) # should be False
# -------- KD loss---------#
kl_loss_mean = nn.KLDivLoss(size_average=True, reduce=True)
# target_x8 = x_8_teacher.permute(0, 2, 3, 1).reshape(5 * batch_size * 256 * 256, -1)
# student_x8 = x_8.permute(0, 2, 3, 1).reshape(5 * batch_size * 256 * 256, -1)
# kd_loss_x8 = kl_loss_mean(F.log_softmax(student_x8, dim=1), F.softmax(target_x8, dim=1))
# #
target_x7 = x_7_teacher.permute(0, 2, 3, 1).reshape(
num_agent * batch_size * 128 * 128, -1
)
student_x7 = x_7.permute(0, 2, 3, 1).reshape(
num_agent * batch_size * 128 * 128, -1
)
kd_loss_x7 = kl_loss_mean(
F.log_softmax(student_x7, dim=1), F.softmax(target_x7, dim=1)
)
#
target_x6 = x_6_teacher.permute(0, 2, 3, 1).reshape(
num_agent * batch_size * 64 * 64, -1
)
student_x6 = x_6.permute(0, 2, 3, 1).reshape(
num_agent * batch_size * 64 * 64, -1
)
kd_loss_x6 = kl_loss_mean(
F.log_softmax(student_x6, dim=1), F.softmax(target_x6, dim=1)
)
# #
target_x5 = x_5_teacher.permute(0, 2, 3, 1).reshape(
num_agent * batch_size * 32 * 32, -1
)
student_x5 = x_5.permute(0, 2, 3, 1).reshape(
num_agent * batch_size * 32 * 32, -1
)
kd_loss_x5 = kl_loss_mean(
F.log_softmax(student_x5, dim=1), F.softmax(target_x5, dim=1)
)
target_x3 = x_3_teacher.permute(0, 2, 3, 1).reshape(
num_agent * batch_size * 32 * 32, -1
)
student_x3 = fused_layer.permute(0, 2, 3, 1).reshape(
num_agent * batch_size * 32 * 32, -1
)
kd_loss_fused_layer = kl_loss_mean(
F.log_softmax(student_x3, dim=1), F.softmax(target_x3, dim=1)
)
kd_loss = kd_weight * (
kd_loss_x7 + kd_loss_x6 + kd_loss_x5 + kd_loss_fused_layer
)
# kd_loss = kd_weight * (kd_loss_x6 + kd_loss_x5 + kd_loss_fused_layer)
# print(kd_loss)
else:
kd_loss = 0
return kd_loss
KL损失定义如下
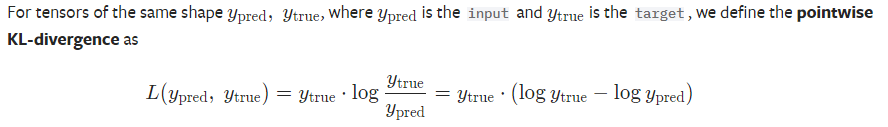
Comunicaton Mechanism
之前的方法基本都是使用通信范围内固定车辆的所有特征,之后有了自定义的通信机制,对通信的车辆,特征等进行选择.
who2com 2020
[2003.09575] Who2com: Collaborative Perception via Learnable Handshake Communication (arxiv.org)
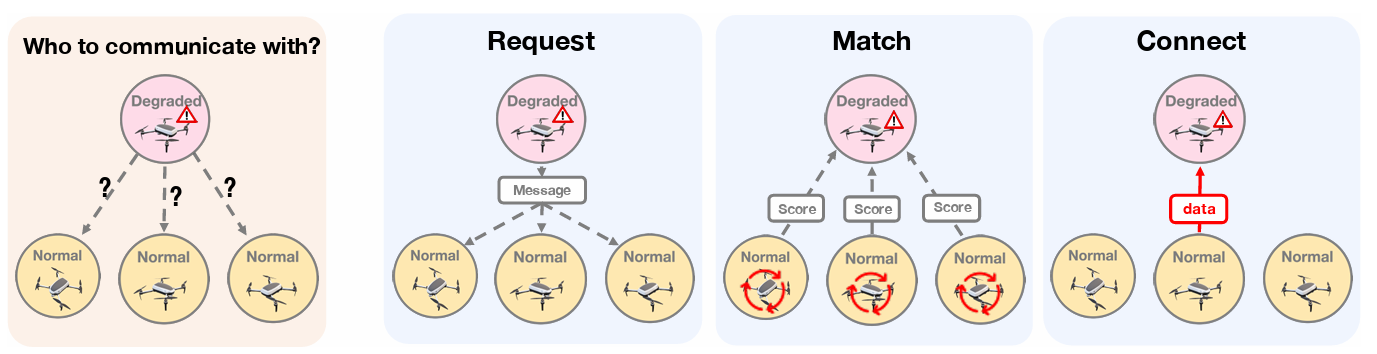
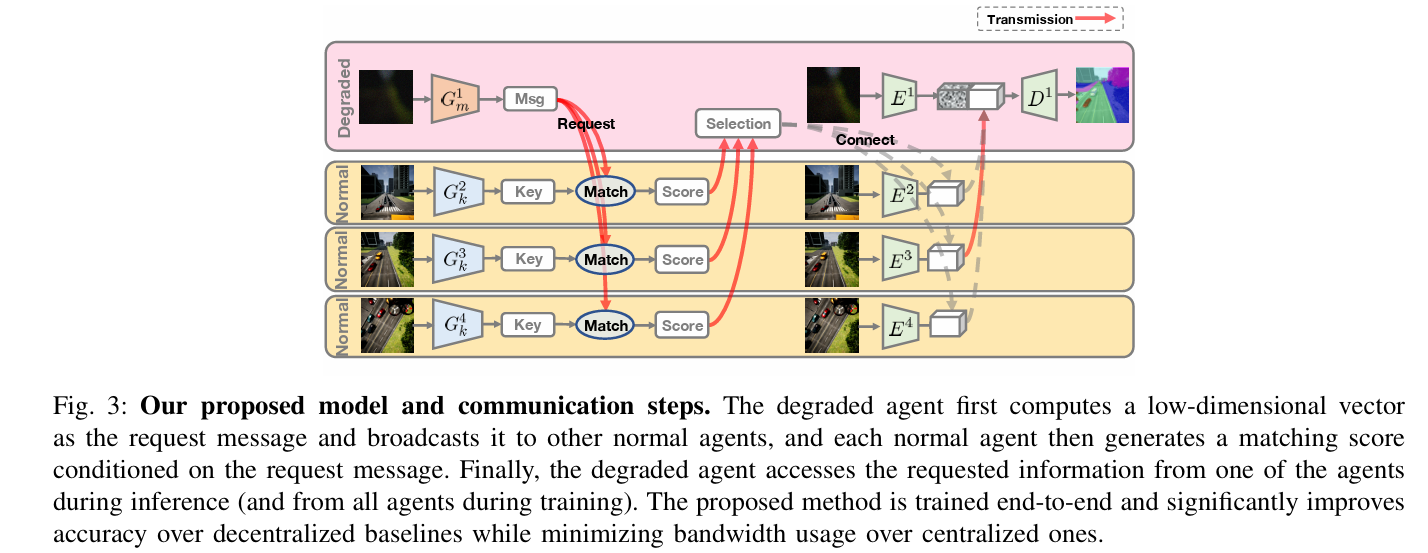
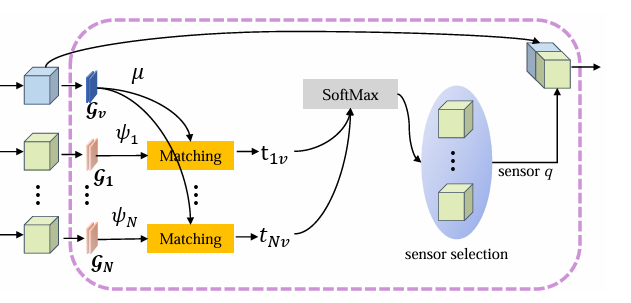
Who2com 建立了首个带宽限制下的通信机制,通过三阶段握手实现.具体来说,Who2com 使用一般注意力函数计算代理之间的匹配分数,并选择最需要的代理,从而有效减少带宽.
定义了一个三阶段的handshake通信机制,分为request,match,connect.
具体来说,代理首先向邻近的代理广播其请求信息 μ~j~∈ R~m~,代理计算其keys κi∈ R~k~ 与请求信息之间的匹配得分 s~ji~.
一旦理将其匹配分数返回给降级ego代理,ego代理会进一步选择最佳的 n 个代理与之连接
在每个步骤中,每个代理 i 可以通过key生成器 G~i~^k^、信息生成器 G~i~^m^、图像编码器 E~i~ 和任务解码器 D~i~ 对信息进行压缩.
简单来说,对于一个ego代理,首先使用一个request生成器(就是一个网络)得到一个信息.此外其他车也会生成一个key发送给ego代理,然后使用注意力机制计算两者值作为相似度.1
2
3
4
5
6
7
8
9
10
11
12# # Message generator
self.query_key_net = policy_net4(n_classes=n_classes, in_channels=in_channels, enc_backbone=enc_backbone)
if self.has_query:
self.query_net = linear(out_size=self.query_size, input_feat_sz=image_size / 32)
self.key_net = linear(out_size=self.key_size, input_feat_sz=image_size / 32)
if attention == 'additive':
self.attention_net = AdditiveAttentin()
elif attention == 'general':
self.attention_net = GeneralDotProductAttention(self.query_size, self.key_size)
else:
self.attention_net = ScaledDotProductAttention(128 ** 0.5)
α~j,i~ is ith element of α~j~ = ρ([s~j1~; …; s~jN~ ]) ∈ R^N^ and ρ is a softmax operation
attention方法如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71class ScaledDotProductAttention(nn.Module):
''' Scaled Dot-Product Attention '''
def __init__(self, temperature, attn_dropout=0.1):
super().__init__()
self.temperature = temperature
self.sparsemax = Sparsemax(dim=1)
self.softmax = nn.Softmax(dim=1)
def forward(self, q, k, v, sparse=True):
attn_orig = torch.bmm(k, q.transpose(2, 1))
attn_orig = attn_orig / self.temperature
if sparse:
attn_orig = self.sparsemax(attn_orig)
else:
attn_orig = self.softmax(attn_orig)
attn = torch.unsqueeze(torch.unsqueeze(attn_orig, 3), 4)
output = attn * v # (batch,4,channel,size,size)
output = output.sum(1) # (batch,1,channel,size,size)
return output, attn_orig.transpose(2, 1)
class AdditiveAttentin(nn.Module):
def __init__(self):
super().__init__()
# self.dropout = nn.Dropout(attn_dropout)
self.softmax = nn.Softmax(dim=1)
self.sparsemax = Sparsemax(dim=1)
self.linear_feat = nn.Linear(128, 128)
self.linear_context = nn.Linear(128, 128)
self.linear_out = nn.Linear(128, 1)
def forward(self, q, k, v, sparse=True):
# q (batch,1,128)
# k (batch,4,128)
# v (batch,4,channel,size,size)
temp1 = self.linear_feat(k) # (batch,4,128)
temp2 = self.linear_context(q) # (batch,1,128)
attn_orig = self.linear_out(temp1 + temp2) # (batch,4,1)
if sparse:
attn_orig = self.sparsemax(attn_orig) # (batch,4,1)
else:
attn_orig = self.softmax(attn_orig) # (batch,4,1)
attn = torch.unsqueeze(torch.unsqueeze(attn_orig, 3), 4) # (batch,4,1,1,1)
output = attn * v
output = output.sum(1) # (batch,1,channel,size,size)
return output, attn_orig.transpose(2, 1)
class GeneralDotProductAttention(nn.Module):
''' Scaled Dot-Product Attention '''
def __init__(self, query_size, key_size, attn_dropout=0.1):
super().__init__()
self.sparsemax = Sparsemax(dim=1)
self.softmax = nn.Softmax(dim=1)
self.linear = nn.Linear(query_size, key_size)
print('Msg size: ',query_size,' Key size: ', key_size)
def forward(self, q, k, v, sparse=True):
# q (batch,1,128)
# k (batch,4,128)
# v (batch,4,channel*size*size)
query = self.linear(q) # (batch,1,key_size)
attn_orig = torch.bmm(k, query.transpose(2, 1)) # (batch,4,1)
if sparse:
attn_orig = self.sparsemax(attn_orig) # (batch,4,1)
else:
attn_orig = self.softmax(attn_orig) # (batch,4,1)
attn = torch.unsqueeze(torch.unsqueeze(attn_orig, 3), 4) # (batch,4,1,1,1)
output = attn * v # (batch,4,channel,size,size)
output = output.sum(1) # (batch,1,channel,size,size)
return output, attn_orig.transpose(2, 1)
when2comm 2020
who2comm的同作者.
在 Who2com 的基础上,When2com引入了缩放一般注意力来决定何时与他人交流.这样,自我代理只有在信息不足时才会与他人交流,从而有效地节省了协作资源.
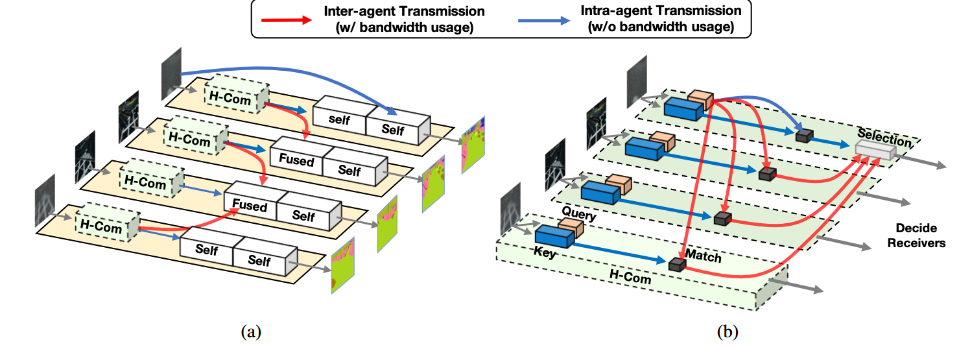
when2comm的代码就要复杂的多,它构建了很多块.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63class KmGenerator(nn.Module):
def __init__(self, out_size=128, input_feat_sz=32.0):
super(KmGenerator, self).__init__()
feat_map_sz = input_feat_sz // 4
self.n_feat = int(256 * feat_map_sz * feat_map_sz)
self.fc = nn.Sequential(
nn.Linear(self.n_feat, 256), #
nn.ReLU(inplace=True),
nn.Linear(256, 128), #
nn.ReLU(inplace=True),
nn.Linear(128, out_size),
) #
def forward(self, features_map):
outputs = self.fc(features_map.view(-1, self.n_feat))
return outputs
class PolicyNet4(nn.Module):
def __init__(self, in_channels=13, input_feat_sz=32):
super(PolicyNet4, self).__init__()
feat_map_sz = input_feat_sz // 4
self.n_feat = int(256 * feat_map_sz * feat_map_sz)
self.lidar_encoder = LidarEncoder(height_feat_size=in_channels)
# Encoder
# down 1
self.conv1 = Conv2DBatchNormRelu(512, 512, k_size=3, stride=1, padding=1)
self.conv2 = Conv2DBatchNormRelu(512, 256, k_size=3, stride=1, padding=1)
self.conv3 = Conv2DBatchNormRelu(256, 256, k_size=3, stride=2, padding=1)
# down 2
self.conv4 = Conv2DBatchNormRelu(256, 256, k_size=3, stride=1, padding=1)
self.conv5 = Conv2DBatchNormRelu(256, 256, k_size=3, stride=2, padding=1)
def forward(self, features_map):
_, _, _, _, outputs1 = self.lidar_encoder(features_map)
outputs = self.conv1(outputs1)
outputs = self.conv2(outputs)
outputs = self.conv3(outputs)
outputs = self.conv4(outputs)
outputs = self.conv5(outputs)
return outputs
class LidarEncoder(Backbone):
"""The encoder class. Encodes input features in forward pass."""
def __init__(self, height_feat_size=13, compress_level=0):
super().__init__(height_feat_size, compress_level)
def forward(self, x):
return super().encode(x)
class LidarDecoder(Backbone):
"""The decoder class. Decodes input features in forward pass."""
def __init__(self, height_feat_size=13):
super().__init__(height_feat_size)
def forward(self, x, x_1, x_2, x_3, x_4, batch, kd_flag=False):
return super().decode(x, x_1, x_2, x_3, x_4, batch, kd_flag)
首先使用encode进行降采样,选择某一层采样后的输出,利用采样后的输出计算q,k,v使用注意力机制融合.1
2
3
4
5
6
7
8
9
10
11
12
13self.key_net = KmGenerator(
out_size=self.key_size, input_feat_sz=image_size / 32
)
self.attention_net = MIMOGeneralDotProductAttention(
self.query_size, self.key_size, self.warp_flag
)
# # Message generator
self.query_key_net = PolicyNet4(in_channels=in_channels)
if self.has_query:
self.query_net = KmGenerator(
out_size=self.query_size, input_feat_sz=image_size / 32
)
利用query_key_net生成特征,再利用key_net生成key,query_net生成query,使用attention_net利用注意力机制进行融合.val_mat就是采样后的输出1
2key_mat = torch.cat(tuple(key_list), 1)
query_mat = torch.cat(tuple(query_list), 1)
用的就是点积注意力,然后使用decoder回去.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36 # hand-shake
class MIMOGeneralDotProductAttention(nn.Module):
"""Scaled Dot-Product Attention"""
def __init__(self, query_size, key_size, warp_flag, attn_dropout=0.1):
super().__init__()
self.sparsemax = Sparsemax(dim=1)
self.softmax = nn.Softmax(dim=1)
self.linear = nn.Linear(query_size, key_size)
self.warp_flag = warp_flag
print("Msg size: ", query_size, " Key size: ", key_size)
def forward(self, qu, k, v, sparse=True):
query = self.linear(qu) # (batch,5,key_size)
attn_orig = torch.bmm(
k, query.transpose(2, 1)
)
attn_orig_softmax = self.softmax(attn_orig) # (batch,5,5)
attn_shape = attn_orig_softmax.shape
bats, key_num, query_num = attn_shape[0], attn_shape[1], attn_shape[2]
attn_orig_softmax_exp = attn_orig_softmax.view(
bats, key_num, query_num, 1, 1, 1
)
if self.warp_flag == 1:
v_exp = v
else:
v_exp = torch.unsqueeze(v, 2)
v_exp = v_exp.expand(-1, -1, query_num, -1, -1, -1)
output = attn_orig_softmax_exp * v_exp # (batch,5,channel,size,size)
output_sum = output.sum(1) # (batch,1,channel,size,size)
return output_sum, attn_orig_softmax
训练的时候基本就拿这些特征给分类和回归的head做输出了.但是inference的时候设置了多种输出.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18if inference == 'softmax':
action = torch.argmax(prob_action, dim=2)
num_connect = 4
return pred, prob_action, action, num_connect
elif inference == 'argmax_test':
action = torch.argmax(prob_action, dim=2)
feat_argmax, num_connect = self.argmax_select(feat_map1, feat_map2, feat_map3, feat_map4, feat_map5,
action, batch_size)
featmaps_argmax = feat_argmax.detach()
pred_argmax = self.decoder(featmaps_argmax)
return pred_argmax, prob_action, action, num_connect
elif inference == 'activated':
feat_act, action, num_connect = self.activated_select(vals, prob_action)
featmaps_act = feat_act.detach()
pred_act = self.decoder(featmaps_act)
return pred_act, prob_action, action, num_connect
else:
raise ValueError('Incorrect inference mode')
argmax_select和activated分别如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43def argmax_select(self, val_mat, prob_action):
# v(batch, query_num, channel, size, size)
cls_num = prob_action.shape[1]
# 进行one hot编码,
coef_argmax = F.one_hot(prob_action.max(dim=1)[1], num_classes=cls_num).type(torch.cuda.FloatTensor)
coef_argmax = coef_argmax.transpose(1, 2)
attn_shape = coef_argmax.shape
bats, key_num, query_num = attn_shape[0], attn_shape[1], attn_shape[2]
coef_argmax_exp = coef_argmax.view(bats, key_num, query_num, 1, 1, 1)
v_exp = torch.unsqueeze(val_mat, 2)
v_exp = v_exp.expand(-1, -1, query_num, -1, -1, -1)
output = coef_argmax_exp * v_exp # (batch,4,channel,size,size)
feat_argmax = output.sum(1) # (batch,1,channel,size,size)
# compute connect
count_coef = copy.deepcopy(coef_argmax)
ind = np.diag_indices(self.agent_num)
count_coef[:, ind[0], ind[1]] = 0
num_connect = torch.nonzero(count_coef).shape[0] / (self.agent_num * count_coef.shape[0])
return feat_argmax, coef_argmax, num_connect
def activated_select(self, val_mat, prob_action, thres=0.2):
coef_act = torch.mul(prob_action, (prob_action > thres).float())
attn_shape = coef_act.shape
bats, key_num, query_num = attn_shape[0], attn_shape[1], attn_shape[2]
coef_act_exp = coef_act.view(bats, key_num, query_num, 1, 1, 1)
v_exp = torch.unsqueeze(val_mat, 2)
v_exp = v_exp.expand(-1, -1, query_num, -1, -1, -1)
output = coef_act_exp * v_exp # (batch,4,channel,size,size)
feat_act = output.sum(1) # (batch,1,channel,size,size)
# compute connect
count_coef = coef_act.clone()
ind = np.diag_indices(self.agent_num)
count_coef[:, ind[0], ind[1]] = 0
num_connect = torch.nonzero(count_coef).shape[0] / (self.agent_num * count_coef.shape[0])
return feat_act, coef_act, num_connect\
where2comm 2022

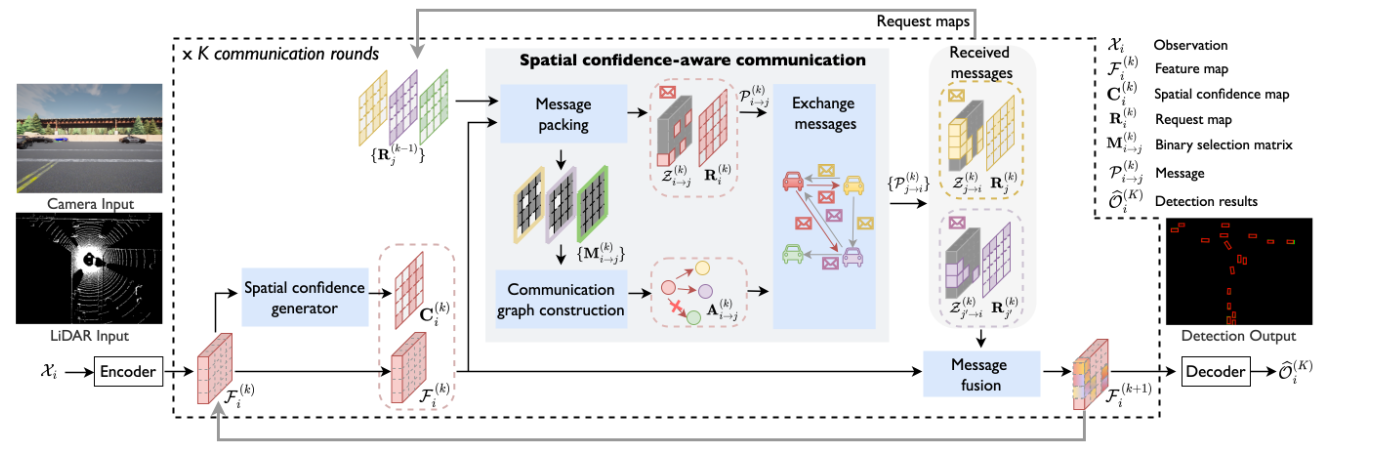
其中 where2comm 包括observation encoder、spatial confidence generator、the spatial confidence-aware communication module、the spatial confidence-aware message fusion和detection decoder.
在五个模块中,spatial confidence generator可生成空间置信度图,基于该空间置信度图,空间置信度感知通信(spatial confidence-aware communication)可生成紧凑的信息和稀疏的通信图,以节省通信带宽.spatial confidence-aware message fusion module利用信息丰富的空间置信度先验来实现更好的聚合.
我们使用检测解码器结构来生成检测置信度图.给定第 k 轮通信的特征图 F (k) i,相应的空间置信度图为
为了在不影响感知的情况下减少通信带宽,我们利用空间置信度图来选择特征图中信息量最大的空间区域(在哪里通信),并决定最有利的合作对象(谁来通信).
这个communication包括message packing.message packing决定了要发送的信息中应包含哪些信息.包括:i) 一张request图,表明代理需要了解哪些空间区域的更多信息;ii) 一张空间稀疏但感知关键的特征图.
what2comm 2023
摘要
多智能体协同感知作为驾驶场景的新兴应用受到越来越多的关注.尽管以前的方法取得了进步,但由于冗余的通信模式和脆弱的协作过程,挑战仍然存在.
为了解决这些问题,我们提出了What2comm,一个端到端协作感知框架,以实现感知性能和通信带宽之间的权衡.我们的新奇性在于三个方面
首先,我们设计了一种基于特征解耦的高效通信机制,在异构代理之间传输排他的和共同的特征映射,以提供感知上的整体消息.
其次,引入了一个时空协作模块来整合来自协作者的互补信息和时间自我线索,从而形成一个针对传输延迟和定位误差的鲁棒协作过程.
最后,我们提出了一种公共感知的融合策略来细化具有信息共同特征的最终表示.
在真实世界和模拟场景中进行的综合实验证明了What2通信的有效性.
DAIR-V2X:第一个用于支持协作感知的大规模真实世界数据集,它包含了标记的车辆和基础设施的激光雷达点云.它包括100个自动驾驶场景和18000个数据样本,其中训练/验证/测试集以5:2:3的比例被分割.
V2XSet
OPV2V
方法
元数据编码和特征投影、基于解耦的通信机制、时空协作模块、common感知融合策略和检测解码器.
This framework comprises five parts: metadata encoding and feature projection, decoupling-based communication mechanism, spatio-temporal collaboration module, common-aware
fusion strategy, and detection decoders
特征解耦前提是学习特征,解耦是分离出任务相关特征和无关特征,以分类为例,解耦的是类别特征和无关的背景及样式等特征.特征解耦一般利用信息熵或者变换空间后的数学特性来完成.
只要两个对象之间存在一方依赖一方的关系,那么我们就称这两个对象之间存在耦合.
作者:大虎甜面酱
链接:https://www.jianshu.com/p/67dc5f5e05da
来源:简书
著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明出处.
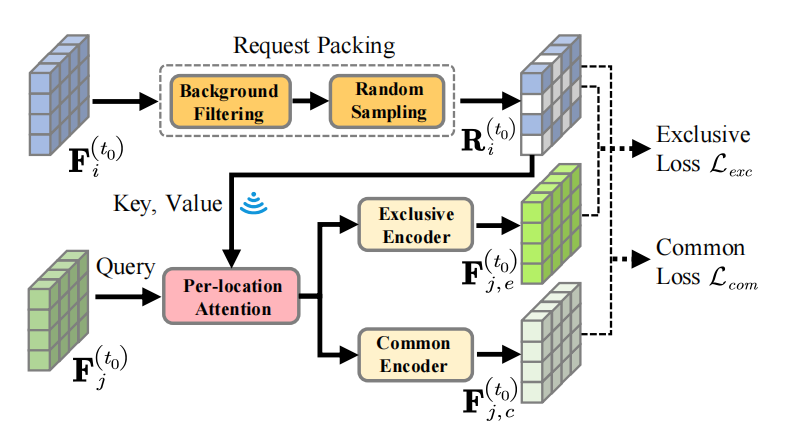
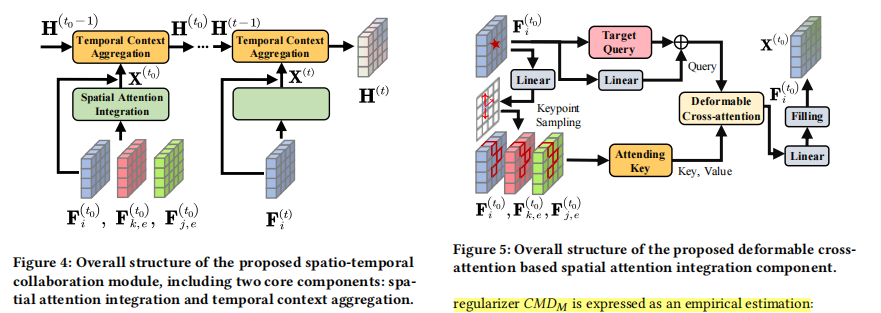
创新点:feature decoupling,latency-aware 使用过去的特征.
how2comm 2023
系what2comm同作者
pose error rectification
ego智能体在接收其他数据时会利用坐标进行转换.1
2
3
4if self.proj_first:
lidar_np[:, :3] = \
box_utils.project_points_by_matrix_torch(lidar_np[:, :3],
transformation_matrix)
那这里的transformatiion_matrix怎么获得的呢?1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72def reform_param(self, cav_content, ego_content, timestamp_cur,
timestamp_delay, cur_ego_pose_flag):
"""
Reform the data params with current timestamp object groundtruth and
delay timestamp LiDAR pose for other CAVs.
Parameters
----------
cav_content : dict
Dictionary that contains all file paths in the current cav/rsu.
ego_content : dict
Ego vehicle content.
timestamp_cur : str
The current timestamp.
timestamp_delay : str
The delayed timestamp.
cur_ego_pose_flag : bool
Whether use current ego pose to calculate transformation matrix.
Return
------
The merged parameters.
"""
cur_params = load_yaml(cav_content[timestamp_cur]['yaml'])
delay_params = load_yaml(cav_content[timestamp_delay]['yaml'])
cur_ego_params = load_yaml(ego_content[timestamp_cur]['yaml'])
delay_ego_params = load_yaml(ego_content[timestamp_delay]['yaml'])
# we need to calculate the transformation matrix from cav to ego
# at the delayed timestamp
delay_cav_lidar_pose = delay_params['lidar_pose']
delay_ego_lidar_pose = delay_ego_params["lidar_pose"]
cur_ego_lidar_pose = cur_ego_params['lidar_pose']
cur_cav_lidar_pose = cur_params['lidar_pose']
if not cav_content['ego'] and self.loc_err_flag:
delay_cav_lidar_pose = self.add_loc_noise(delay_cav_lidar_pose,
self.xyz_noise_std,
self.ryp_noise_std)
cur_cav_lidar_pose = self.add_loc_noise(cur_cav_lidar_pose,
self.xyz_noise_std,
self.ryp_noise_std)
if cur_ego_pose_flag:
transformation_matrix = x1_to_x2(delay_cav_lidar_pose,
cur_ego_lidar_pose)
spatial_correction_matrix = np.eye(4)
else:
transformation_matrix = x1_to_x2(delay_cav_lidar_pose,
delay_ego_lidar_pose)
spatial_correction_matrix = x1_to_x2(delay_ego_lidar_pose,
cur_ego_lidar_pose)
# This is only used for late fusion, as it did the transformation
# in the postprocess, so we want the gt object transformation use
# the correct one
gt_transformation_matrix = x1_to_x2(cur_cav_lidar_pose,
cur_ego_lidar_pose)
# we always use current timestamp's gt bbx to gain a fair evaluation
delay_params['vehicles'] = cur_params['vehicles']
delay_params['transformation_matrix'] = transformation_matrix
delay_params['gt_transformation_matrix'] = \
gt_transformation_matrix
delay_params['spatial_correction_matrix'] = spatial_correction_matrix
return delay_params
delay_params返回的是supporter的delay(也有可能没有延时,看具体设置),cur_ego_pose_flag(默认为true)表示是否使用目前ego的坐标计算相对位置. transformation_matrix就是ego和cav的相对位置,如果设置cur_ego_pose_flag,则计算的是cav延时后的位置相对于当前ego的相对位置,否则计算的是延时的cav相对延时的ego的位置,spatial_correction_matrix计算的延时前后的相对位置(注意这些相对位置大小都是4x4).
如果没有延时,cur_ego_pose_flag其实就没有什么意义了.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15transformation_matrix = x1_to_x2(delay_cav_lidar_pose,
cur_ego_lidar_pose)
spatial_correction_matrix = np.eye(4)
# This is only used for late fusion, as it did the transformation
# in the postprocess, so we want the gt object transformation use
# the correct one
gt_transformation_matrix = x1_to_x2(cur_cav_lidar_pose,
cur_ego_lidar_pose)
# we always use current timestamp's gt bbx to gain a fair evaluation
delay_params['vehicles'] = cur_params['vehicles']
delay_params['transformation_matrix'] = transformation_matrix
delay_params['gt_transformation_matrix'] = \
gt_transformation_matrix
delay_params['spatial_correction_matrix'] = spatial_correction_matrix
所以spatial_correction_matrix就成了$I$恒等矩阵,transformation_matrix是cav和ego的坐标转换矩阵4x4,gt_transformation_matrix是label. 而当由于proj_first默认是true,首先将cav的特征按照transformation_matrix$\in R^{4\times 4}$进行了转换,而transformation_matrix在没有时延的情况下就是ego和cav的位置转换,proj_first之后,pairwise_t_matrix$\in R^{5\times5\times4\times}$也成了$I$恒等矩阵1
2
3
4
5pairwise_t_matrix = np.zeros((max_cav, max_cav, 4, 4))
if self.proj_first:
# if lidar projected to ego first, then the pairwise matrix
# becomes identity
pairwise_t_matrix[:, :] = np.identity(4)
Effective Fusion
Spatio-Temporal Domain Awareness for Multi-Agent Collaborative Perception
在接收到自我代理播放的元数据(如姿势和外部特征)后,合作者将其本地激光雷达点云投射到自我代理的坐标系中.同样,自我代理之前的点云帧也会同步到当前帧.
给定第 k 个代理在时间戳 t 处的点云 X (t) k,提取的特征为 F (t) k =f enc (X (t) k )∈R C ×H ×W ,其中 f enc (-) 是所有代理共享的 PointPillar编码器,C、H、W 分别代表通道、高度和宽度.
Context-aware Information Aggregation
解决latency的问题
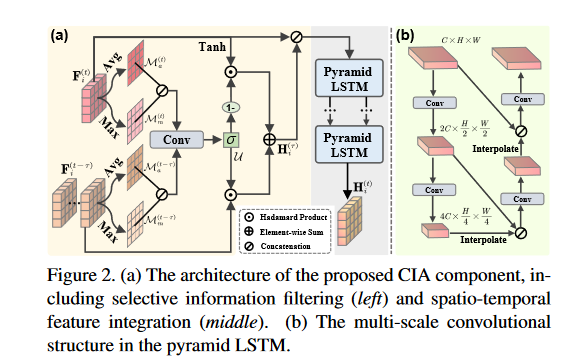
遗憾的是,目前的多机器人协作总是专注于探索当前帧,而忽略了之前帧的上下文线索.由于点云的稀疏性和不足,单帧解决方案无法有效检测快速移动的物体(如周围的车辆).为此,我们提出了一个情境感知信息聚合(CIA)组件,用于捕捉自我代理之前帧的时空表征,以融合有价值的语义.
选择性信息过滤.这一阶段的目的是通过过滤目标 F (t) i ∈R C ×H ×W 中的冗余特征,并从先前的 F^(t-τ)^~i~ ∈R τ ×C×H×W 中提炼出有意义的特征,从而提取精炼信息,其中 τ 是时间偏移.
具体来说,首先利用通道平均和最大池化运算 Ψ a/m (-) 聚合丰富的通道语义
将过去帧相加做个max与avg池化然后concat起来,当前的帧也同样处理,然后加起来做个conv.将这些细化的特征图结合起来,就能得到一个精心选择的空间选择图
Spatio-temporal Feature Integration.
为了整合historical prototype以提高当前表征的感知能力,我们引入了金字塔 LSTM来学习帧间特征 F (t) i ∥H (τ ) i 的上下文依赖关系.
在实践中,多尺度空间特征是通过在不同尺度之间连续进行两次二维卷积,然后进行批量归一化和 ReLU 激活来提取的.为了实现多层次空间语义融合,降低采样率的特征会通过横向连接逐步插值到提高采样率的层.
Confidence-aware Cross-agent Collaboration
跨代理协作的目标是通过聚合协作者共享特征的互补语义来增强自我代理的视觉表征.
现有研究提出了基于注意力的per-location特征融合方法,但这种方法容易受到定位误差的影响,而且忽略了点云的稀疏性.为了解决这些问题,我们采用了a novel Confidenceaware Cross-agent Collaboration (CCC) component
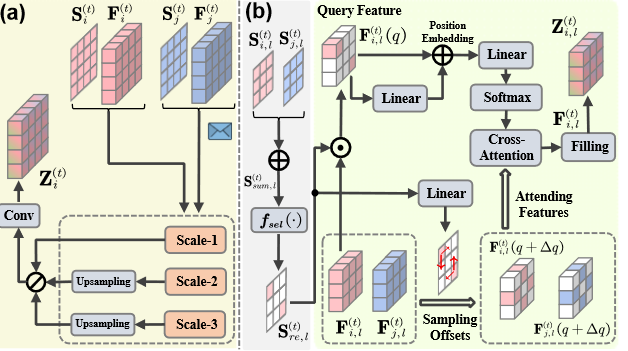
CCC 组件将特征和置信度图编码为三个尺度,并在每个尺度上进行特征融合.
F^(t)^~k,l~ 和 S^(t)^~k,l~ 表示第 l 个尺度的特征图和置信度图.
为了预测包含有意义物体信息的空间位置,我们将所有置信度图的元素求和.
由于置信度图反映的是空间临界水平,S^(t)^~sum,l~ 显示的是探测范围内目标的潜在位置,称为参考点.
因此,我们采用基于阈值的选择函数 fsel(-) 来提取参考点 S^(t)^~re,l~.这种设计可以积极引导后续的融合网络集中在重要的空间区域.
Deformable Cross-attention Module 我们在参考点提取自我代理的特征 F^(t)^ ~i,l~ 作为初始查询嵌入,并应用线性层将参考点的位置编码为位置嵌入
为了解决特征图的不对齐问题,并获得更稳健的表征以抵御定位误差,可变形交叉注意模块(DCM)通过可变形交叉注意层聚合来自采样关键点的信息
Wa/b 是可学习权重,φ(-) 是软最大函数.最后,我们得出一个填充操作,根据初始位置 q 将 DCM(q) 填充到自我代理的特征 F (t) i,l 中,并输出 Z(t) i,l
三个尺度下的输出增强特征被编码成相同的大小,并在通道维度上进行串联.我们利用 1 × 1 卷积层融合三个尺度的信息,得到最终的协作特征 Z^(t)^~i~∈ R^C×H×W^
Importance-aware Adaptive Fusion
尽管之前的研究通过汇总协作信息的自我特征取得了令人印象深刻的性能,但它们可能会受到异步测量的协作者带来的噪声干扰.A promising solution is to consider purely ego-centered characteristics, which contain the natural perception advantages of the target agent.
我们提出了一种重要性感知自适应融合(IAF)组件,根据多源特征的互补性对其进行融合.
FPV-RCNN 2021
Collaborative 3d object detection for automatic vehicle systems via learnable communications 2022
Customized Loss
除了分类和回归损失之外,虽然 V2V 通信为自我车辆提供了相对丰富的感知视野,但共享信息的冗余性和不确定性带来了新的挑战.
在协作场景中,邻居代理提供的类似信息对自我车辆来说是冗余的.为了有效利用协作信息,Luo 等人提出了一种互补增强和冗余最小化的协作网络(CRCNet).具体来说,CRCNet 有两个模块来引导网络.在互补性增强模块中,CRCNet 利用对比学习来增强信息增益.在冗余最小化模块中,CRCNet 利用互信息鼓励融合特征对中的依赖性.在上述模块的指导下,CRCNet 能够在融合特征时从相邻代理中选择互补信息.
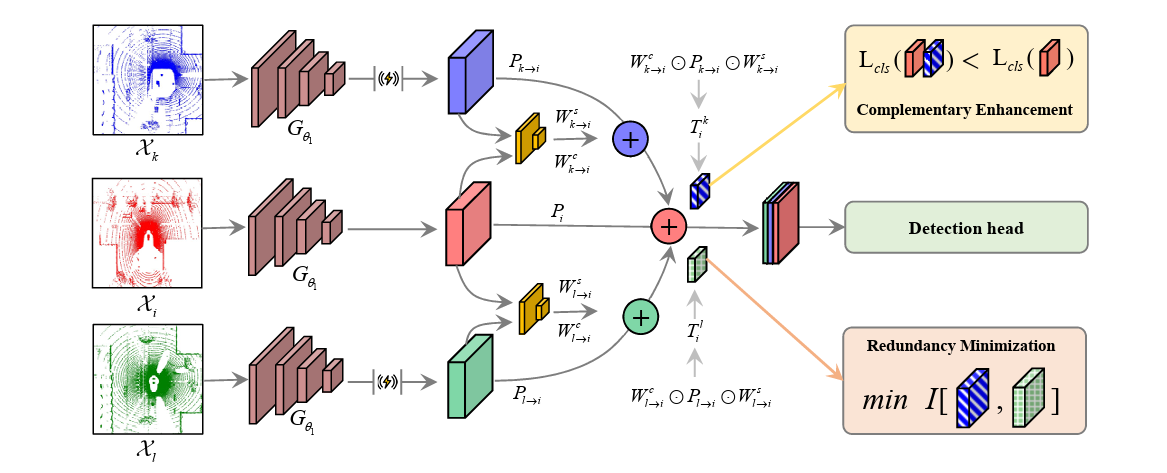
除了冗余信息,协作信息还包含感知上的不确定性,这反映了感知上的不准确或传感器噪声.Su 等人首先探讨了协作感知中的不确定性.具体来说,他们设计了一种量身定制的移动块引导方法来估计模型和数据的不确定性,并设计了一个良好的损失函数来直接捕捉数据的不确定性.实验表明,在不同的协作方案中,不确定性估计可以减少不确定性并提高准确性.
FeaCo 2023 MM

主要看其中的融合模块

摘要
协作感知为克服遮挡和远程数据处理等挑战提供了一种有前景的解决方案.然而,有限的传感器精度会导致车辆姿态出现噪声,导致车辆之间的观察不一致.
为了解决这个问题,我们提出了 FeaCo,它可以在嘈杂的姿势条件下在协作代理之间实现强大的特征级共识,而无需额外的训练.
我们设计了一个高效的姿态误差校正模块(PRM)来对齐来自不同车辆的派生特征图,减少噪声姿态和带宽要求的不利影响.我们还提供了有效的多尺度跨级注意力模块(CAM)来增强各种尺度之间的信息聚合和交互.
我们的 FeaCo 优于所有其他定位校正方法,经协作感知模拟数据集 OPV2V 和现实数据集 V2V4Real 验证,减少了航向误差并提高了各种误差级别的定位精度.
重点是一个姿态误差校正模块用于提升检测鲁棒性.
Proposal Regions Localization
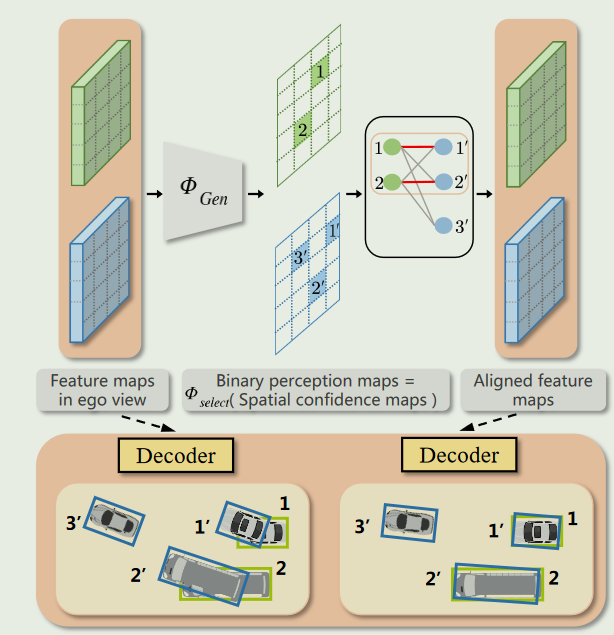
由于视角的重叠,在感知过程中,同一目标可以被多个AV检测并存储在它们的特征级表示中.因此,对特征图上的目标位置和关系进行建模变得尤为重要.理性建模可以更好地定位候选匹配区域,从而得到精确的变换矩阵.
我们使用空间置信图作为包含语义信息的置信水平的表示.它由检测头从$\phi_{Enc}$提取的特征中生成,反映了不同空间区域的感知关键程度.具体来说,感知临界水平高的区域表示潜在的匹配区域,而较低的区域通常表示冗余背景.二值感知图是通过极大值选择得到的,其中取值为1的像素代表建议像素,取值为0的像素代表背景.此外,二进制感知图的稀疏形式有助于进一步降低带宽需求
为了进行特征级匹配,需要收集像素级的局部信息作为区域级的表示。因此,我们将每个连通矩形区域的中心作为候选匹配区域的代表。将自我AV得到的中心点集合记为P,将噪声姿态条件下CAV得到的中心点集合记为Q
Proposal Centers Matching
为了获得细粒度的变换矩阵,需要对不同集合中的导出建议中心进行匹配。对于集合P中的每个点,我们的目标是在集合Q中分配一个唯一的检测框。然而,由于视觉遮挡和距离的原因,一些建议匹配区域可能无法匹配,因此关键是找到一种有效的策略,在具有不均匀匹配和高姿态噪声的对齐特征图中达到鲁棒的一致性。
对于集合P中的每个点,我们的目标是在集合Q中分配一个唯一的检测框。然而,由于视觉遮挡和距离的原因,一些建议匹配区域可能无法匹配,因此关键是找到一种有效的策略,在具有不均匀匹配和高姿态噪声的对齐特征图中达到鲁棒的一致性。
然而,一些建议匹配区域可能由于视觉遮挡和距离而无法匹配,因此关键是找到一种有效的策略,在具有不均匀匹配和高位姿噪声的对齐特征图中达成鲁棒的共识。

我们采用了特征级建议中心匹配方法.将Q~k~中与自我特征中任何提议匹配区域接近的每个中心视为贡献中心,并将其包含在Q~near~中.类似地,我们将自我AV的贡献中心集记为P~near~
接下来,构建一个带权二部图G,分别使用端点来自P~near~和Q~near~,每条边的权重由两个中心之间的距离决定,记录在成本矩阵C中.然后将匹配过程转化为G上的线性分配任务,旨在寻找边权重之和最小的匹配方案.位姿误差会导致特征图之间的定位不准.经过赋值过程,编号为1和2的自我特征图中的提议中心分别成功匹配到CAVk的中心1′和2′
还使用中位数绝对偏差( Median Absolute Deviation,MAD )算法对选择的匹配代价进行聚类,并通过剔除异常值来去除不正确的匹配关系。为了利用高精度的匹配关系获得细粒度的变换矩阵,使用了受ICP启发的奇异值分解( SVD )方法
该方法通过最小化由导出的旋转矩阵R和平移向量t变换后的原始M~p~和M′~q~之间的距离,得到最终的精确矩阵
利用精确矩阵T~k~得到了CAV~k~的修正特征
Multi-scale Cross-level Attention
根据得到的CAV~k~的变换矩阵T~k~ { k = 1 .. ..M },自我车辆首先在通道维度上进行堆叠,然后通过多尺度融合模块进行跨层注意力处理。
大卷积窗口生成的特征图具有感知大的、近距离目标的能力,而小卷积窗口对小的、远距离的目标更加敏感。因此,采用多尺度策略生成N个层次的特征丰富表示,其中特征为Φ^FN^~Enc~得到的伪图像表示I^(i)^
经过反卷积操作后,不同层次的特征图被统一为( C、H、W)的形状。然而,简单的串联方法可能会遗漏探索层次之间丰富的关系信息。为了解决这个问题在融合阶段提供了多尺度策略的跨层注意力模块(CAM)
形式上,将N个层次的特征图在通道维度上进行串联,并进行深度卷积,以最小的计算量提取额外的信息。将得到的张量改写成( N , C × H × W)进行跨层注意力操作
将还原后的特征图重新塑造成( N × C × H × W)格式,并通过输出投影层。为了解决CAM模块引起的潜在退化问题,我们通过将原始特征添加到导出的表示中,并结合残差连接
Opencood
domain invariant/domain adaptation
https://excalidraw.com/#json=RsdlTMprI5adS4gGXEmiK,EdJP3iORYwuBFhBkVf5WSA

使用仿真数据(有标签)和真实数据一起训练,分别得到经过网络的融合特征和经过cls_head和psm(类别图),根据这些结果计算检测的loss. 再将融合特征和psm数据给DomainAdaptation Module,计算domain adaptation loss. 利用这两个loss优化网络提升在真实数据上的检测效果.
domain adaptation loss计算的是将两者融合特征和psm经过一系列网络计算entropy loss.