这个方向的技术目前没有那么火了,但是能应用的场景非常之多.
综述
Deep Unsupervised Domain Adaptation: A Review of Recent Advances and Perspectives
深度学习已经成为解决不同领域现实问题的首选方法,部分原因是它能够从数据中学习,并在广泛的应用中取得了令人印象深刻的性能。
然而,它的成功通常依赖于两个假设:( i )精确的模型拟合需要大量有标签的数据集,( ii )训练和测试数据是独立同分布的.因此,它在看不见的目标域上的性能得不到保证,特别是在适应阶段遇到分布外数据时。
在目标域数据上的性能下降是部署在源域数据上成功训练的深度神经网络的一个关键问题.
无监督域适应( Unsupervised Domain Adaptation,UDA )正是针对这一问题提出的,通过同时利用已标记的源域数据和未标记的目标域数据,在目标域中执行各种任务
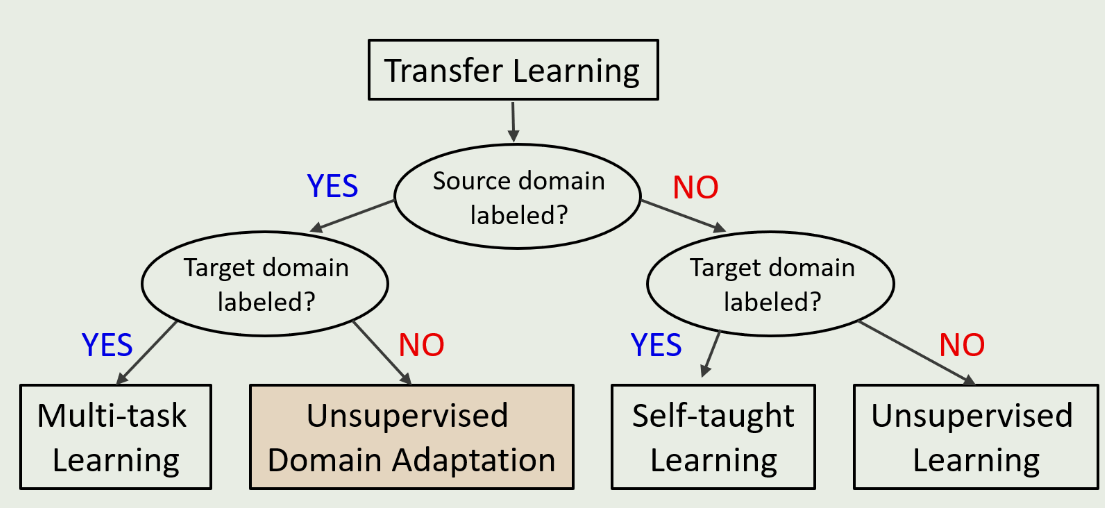
Although supervised deep learning is the most prevalent and successful approach for a variety of tasks, its success hinges on (i) vast troves of labeled training data and (ii) the assumption of independent and identically distributed (i.i.d.) training and testing datasets.
Because reliable labeling of massive datasets for various application domains is often expensive and prohibitive, for a task without sufficient labeled datasets in a target domain, there is strong demand to apply trained models, by leveraging rich labeled data from a source domain
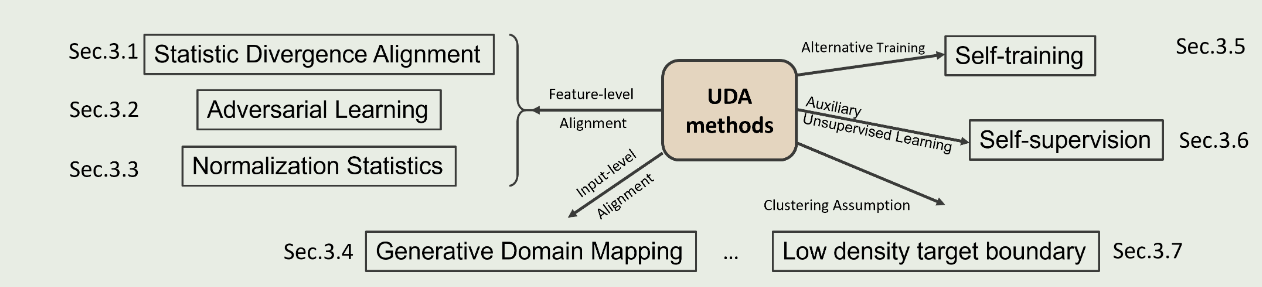
常用的方法分类如图.
Statistic Divergence Alignment
学习领域不变特征表示是许多深度UDA方法中应用最广泛的思想,其关键在于最小化潜在特征空间中的领域差异.为了实现这一目标,选择合适的divergence measure是这些方法的核心。
Deep visual domain adaptation: A survey
深度域适应已经成为一种新的学习技术,以解决缺乏大量标记数据的问题。与传统的学习共享特征子空间或重用具有浅层表示的重要源实例的方法相比,深度域适应方法通过将域适应嵌入到深度学习的流水线中,利用深度网络来学习更多的可迁移表示。已有针对浅域自适应的全面调查,但很少有人及时评论基于深度学习的新兴方法。在本文中,我们对计算机视觉应用中的深度域自适应方法进行了全面调查,主要有四大贡献。首先,我们根据定义两个域如何偏离的数据属性,提出了不同深度域适配场景的分类法。其次,我们根据训练损失将深域适应方法归纳为几个类别,并简要分析和比较了这些类别下的最先进方法。第三,我们概述了图像分类之外的计算机视觉应用,如人脸识别、语义分割和物体检测。第四,重点介绍当前方法的一些潜在不足和未来的几个发展方向。
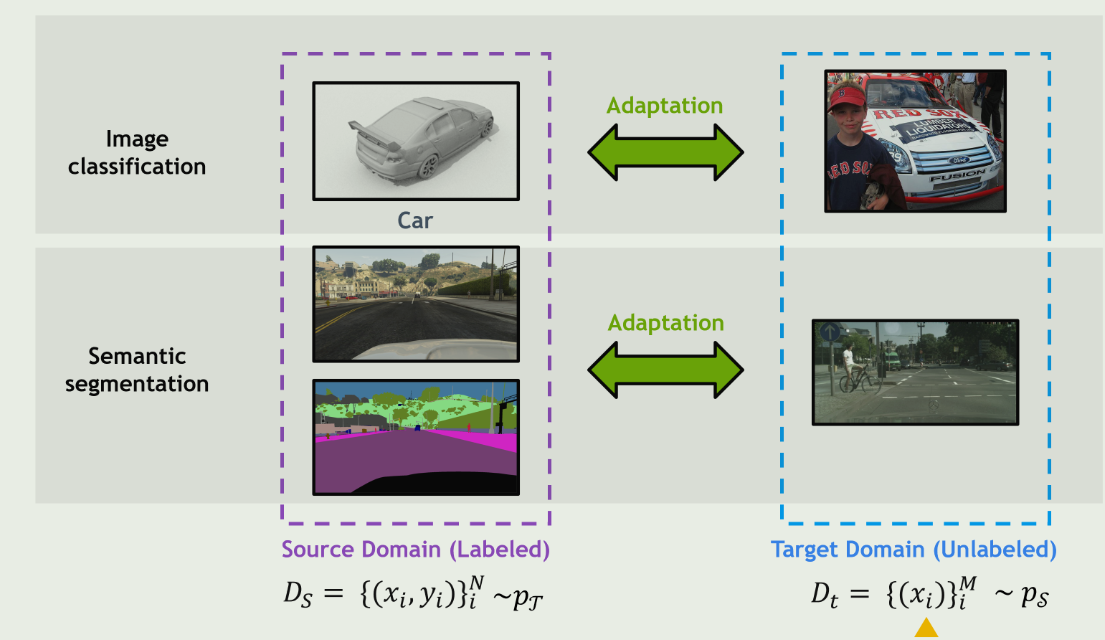
域 D 由特征空间 X 和边际概率分布 P(X) 组成,其中 X = {x1, ., xn}∈ X。给定一个特定的域 D = {X , P(X )},任务 T 由一个特征空间 Y 和一个客观预测函数 f( - ) 组成,从概率论的角度来看,f( - ) 也可以看作是条件概率分布 P(Y|X)。一般来说,我们可以从标注数据 {xi, yi}(其中 xi∈X 和 yi∈Y )中以有监督的方式学习 P(Y|X)。
假设有两个域:有足够标注数据的训练数据集是源域 Ds = {X s, P(X )s}, 有少量标注数据或无标注数据的测试数据集是目标域 Dt = {X t , P(X )t }。部分标注的部分 Dtl 和未标注的部分 Dtu 构成了整个目标域,即 Dt = Dtl ∪ Dtu。每个域都有其任务:前者为 T s = {Ys, P(Y s|Xs )}, 后者为 T t = {Yt , P(Y t |Xt )} 。
同样,P(Ys|Xs) 可以从源标签数据 {xs i , ys i } 中学习,而 P(Yt|Xt) 可以从标签目标数据 {xtl i , ytl i } 和非标签数据 {xtu i } 中学习。
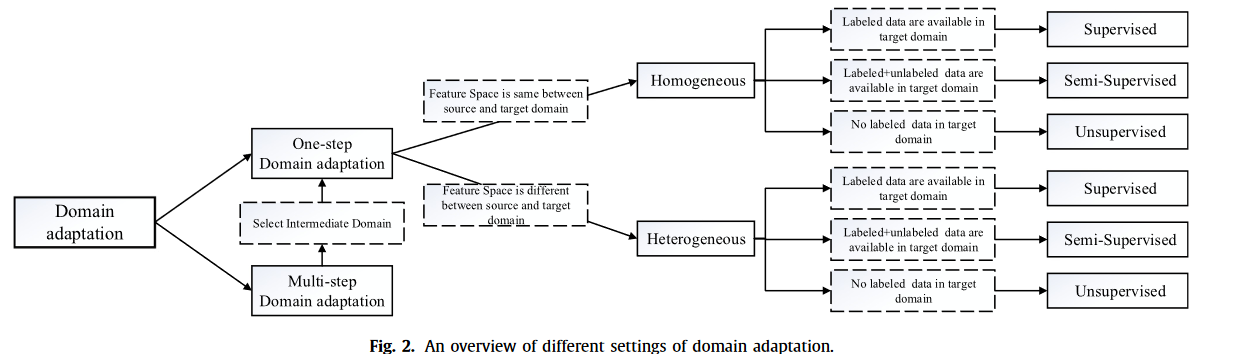
对DA方法进行分类
在同质数据中,源域和目标域之间的特征空间是相同的(X s = X t),维度也相同(ds = dt)。因此,源数据集和目标数据集的数据分布一般是不同的(P(X)s = P(X)t)。
在异构数据中,源域和目标域之间的特征空间是不等同的(X s = X t),维度一般也可能不同(ds = dt)。
此外,我们还可以将同质 DA 设置进一步分为三种情况:
在有监督的 DA 中,存在少量有标签的目标数据(D^tl^)。然而,标签数据通常不足以完成任务。
在半监督 DA 中,训练阶段既有有限的目标域标记数据(D^tl^),也有冗余的非标记数据(D^tu^),这使得网络可以学习目标域的结构信息。
在无监督 DA 中,训练网络时无法观察到有标签但足够多的无标签目标域数据(D^tu^)
与同质类似,异质也可分为有监督、半监督和无监督。
上述所有 DA 设置都假定源领域和目标领域直接相关,因此,知识转移只需一步即可完成。我们称其为一步式设计。

然而,在现实中,这一假设偶尔也会落空。两个域之间几乎没有重叠,因此执行单步 DA 将不会有效。幸运的是,有一些中间域能够拉近源域和目标域之间的距离。使用一系列中间桥梁来连接两个看似不相关的域,然后通过该桥梁执行一步式 DA,这就是多步式(或反式)DA .例如,人脸图像和车辆图像由于形状或其他方面的不同而互不相似,因此单步检测会失败.但是,可以引入一些中间图像,如 “足球头盔”,作为中间域,从而顺利实现知识转移.
从广义上讲,深度 DA 是一种利用深度网络提高 DA 性能的方法。根据这一定义,具有深度特征的浅层方法可视为深度 DA 方法。浅层方法采用 DA,而深度网络只能提取矢量特征,无助于直接传递知识。例如,Lu 等人从 CNN 中提取卷积激活作为张量表示,然后进行张量对齐。
从狭义上讲,深度 DA 基于专为 DA 设计的深度学习架构,可以通过反向传播从深度网络中获得第一手效果。其直观思路是将 DA 嵌入到学习表征的过程中,学习一种既有语义意义又有领域不变性的深度特征表征。有了 “好 “的特征表示,目标任务的性能就会显著提高。
一步式数据采集的深度方法可归纳为三种情况.
第一种情况是基于差异(Discrepancy-based)的深度数据挖掘方法,该方法假定用标注或未标注的目标数据微调深度网络模型可以减少两个域之间的偏移.类判据(class criterion)、统计判据(statistic criterion)、架构判据(architecture criterion)和几何判据(geometric criterion)是进行微调的四种主要技术。
class criterion:使用类标签信息作为在不同领域间转移知识的指南.在有监督的数据分析中,当目标领域的标签样本可用时,软标签和度量学习总是有效的.当无法获得此类样本时,可采用其他一些技术来替代类标签数据,如伪标签和属性表示法.
statistic criterion:利用某些机制对源域和目标域之间的统计分布偏移进行配准。最常用的比较和减少分布偏移的方法有最大均值差异(MMD)、相关对齐(CORAL)、KullbackLeibler发散和 H 发散等。
Architecture criterion:这些技术旨在通过调整深度网络的架构,提高学习更多可迁移特征的能力。已被证明具有成本效益的技术包括自适应批量归一化(BN)、弱相关权重、域引导剔除等。
Geometric criterion:根据源域和目标域的几何特性将其连接起来。这一标准假定几何结构的关系可以减少域的偏移.
第二种情况可称为基于对抗(Adversarial-based)的深度 DA 方法。在这种情况下,会使用一个领域判别器来对数据点是来自源领域还是目标领域进行分类,通过对抗目标来鼓励领域混淆,从而使经验源映射分布和目标映射分布之间的距离最小化。
此外,根据是否存在生成模型,基于对抗的深度数据挖掘方法可分为两种情况。
生成模型:将判别模型与一般基于生成对抗网络(GAN)的生成组件相结合。其中一种典型情况是使用源图像、噪声矢量或两者生成与目标样本相似的模拟样本,并保留源域的注释信息。
非生成模型:特征提取器不是利用输入图像分布生成模型,而是利用源域中的标签学习判别表征,并通过域混淆损失将目标数据映射到同一空间,从而得到域不变表征.
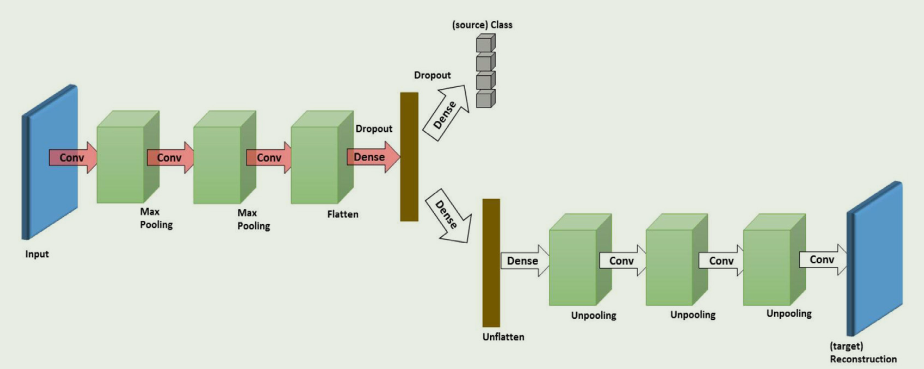
第三种情况可称为基于重构(Reconstruction-based)的 DA 方法,它假定源样本或目标样本的数据重构有助于提高 DA 的性能。重构器既能确保域内表征的特异性,又能确保域间表征的不可分性。
- 编码器-解码器重构:通过使用堆叠自动编码器(SAE),编码器-解码器重构方法将用于表征学习的编码器网络与用于数据重构的解码器网络结合起来.
- 对抗重构:重构误差是通过 GAN 识别器(如 dual GAN、cycle GAN和 disco GAN)获得的循环映射测量的每个图像域内重构图像与原始图像之间的差异。
在多步骤 DA 中,我们首先要确定与源域和目标域的关系比直接联系更密切的中间域。其次,知识转移过程将在源域、中间域和目标域之间以较少信息损失的方式通过一步 DA 完成。因此,多步骤 DA 的关键在于如何选择和利用中间域;此外,根据文献,它可以分为三类:手工选择机制、基于特征的选择机制和基于表征的选择机制。
Hand-crafted:用户根据经验确定中间域
Instance-based:从辅助数据集中选择某些部分的数据来组成中间域,以训练深度网络
Representation-based:通过冻结先前训练好的网络,并将其中间表征作为新网络的输入,可以实现转移
Discrepancy-based approaches
Yosinski 等人证明,由于脆弱的共适应性和表征特异性,深度网络学习到的可迁移特征具有局限性,而微调可以提高泛化性能.微调(也可视为基于差异的深度数据挖掘方法)是用源数据训练基础网络,然后直接重用前 n 层来构建目标网络.目标网络的其余层是随机初始化的,并根据差异损失进行训练.在训练过程中,可以根据目标数据集的大小及其与源数据集的相似度,对目标网络的前 n 层进行微调或冻结。
class criterion
类标准是深度 DA 中最基本的训练损耗。在使用源数据对网络进行预训练后,目标模型的其余各层将类标签信息作为训练网络的指南。因此,假定可以从目标数据集中获得少量带标签的样本。理想情况下,类标签信息在有监督的数据分析中直接给出。大多数工作通常使用地面真实类的负对数似然与 softmax 作为训练损失,即 L = - ∑N i=0 yi log ˆ yi(ˆ yi 是模型的 softmax 预测,代表类概率)
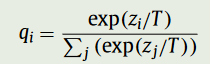
受 Tzeng 等人的启发, 通过同时最小化领域混淆损失(属于基于对抗的方法)和软标签损失,对网络进行了微调。使用软标签而不是硬标签可以保持跨域类之间的关系。Gebru 等人在的基础上修改了现有的适应算法,在细粒度的类级别 Lcsoft 和属性级别 Lasoft 上使用了软标签损失。
除了 softmax 损失外,还有其他方法可用作训练损失,以微调有监督 DA 中的目标模型。深度网络中的嵌入度量学习是另一种方法,它可以使来自不同领域、具有相同标签的样本距离更近,而具有不同标签的样本距离更远。基于这一思想构建了相应的语义对齐损失和分离损失。Hu 等人提出了深度转移度量学习,它应用了边际费雪分析准则和 MMD 准则.
然而,如果目标域中没有直接的类标签信息,我们该怎么办呢?众所周知,人类可以仅凭高层次的描述来识别未见过的类。例如,当我们得到 “高大的棕色长颈动物 “的描述时,我们就能识别出长颈鹿。为了模仿人类的能力,为每个类引入了高级语义属性。假设 a^c^ = (a^c^~1~, … , a^c^~m~ ) 是 c 类的属性表示,它具有固定长度的二进制值,在所有类中有 m 个属性.分类器为每个属性 a^m^ 提供 p(a^m^|x) 的估计值
Statistic criterion
虽然有些基于差异的方法会寻找伪标签、属性标签或其他标签目标数据的替代品,但更多的工作侧重于在无监督 DA 中通过最小化域分布差异来学习域不变表示。MMD 是通过核双样本测试比较两个数据集分布的有效指标。
在此基础上,Ghifary 等人提出了一种模型,在单隐层前馈神经网络中引入 MMD 指标。MMD 指标在每个域的表征之间进行计算,以减少潜在空间中的分布失配。
Long 等人没有使用单层和线性 MMD,而是提出了深度适应网络 (DAN),通过添加多个适应层和探索多个内核来匹配跨域边际分布的变化,同时假设条件分布保持不变(图 6)。然而,在实际应用中,这一假设相当强;换句话说,源分类器不能直接用于目标域。为了使其更具通用性,联合适应网络(JAN)基于联合最大均值差异(JMMD)准则,在多个特定领域层中调整输入特征和输出标签联合分布的偏移。Zhang 等人提出了 DTN,其中边际分布和条件分布都根据 MMD 进行匹配。
如果 φ 是特征核(即高斯核或拉普拉斯核),MMD 将比较所有阶次的统计量矩。与 MMD 不同,CORAL学习的是一种线性变换,它能使域之间的二阶统计量保持一致。Sun 和 Saenko 利用非线性变换将 CORAL 扩展到深度神经网络(深度 CORAL)。
其中,‖-‖F^2^ 表示矩阵弗罗贝尼斯准则平方。C~S~ 和 C~T~ 分别表示源数据和目标数据的协方差矩阵。
Architecture criterion
其他一些方法则会优化网络架构,使分布差异最小化。这种适应行为可以在大多数深度 DA 模型中实现,如监督和非监督设置。Rozantsev 等人认为,对应层的权重不是共享的,而是通过权重正则化器 rw( - ) 进行关联,以考虑两个域的差异。

Geometric criterion
几何准则通过整合从源域到目标域的路径上的中间子空间来减轻域偏移。
Adversarial-based approaches
GAN这里就不细说了.
Non-generative models
深度DA的关键在于从源样本和目标样本中学习与领域无关的表征。有了这些表征,两个领域的分布就会足够相似,这样分类器就会被骗过,即使它是在源样本上训练出来的,也能直接用于目标领域。因此,表征是否存在领域混淆对于知识迁移至关重要。受 GAN 的启发引入了由判别器产生的领域混淆损失,以提高无生成器的深度 DA 性能。
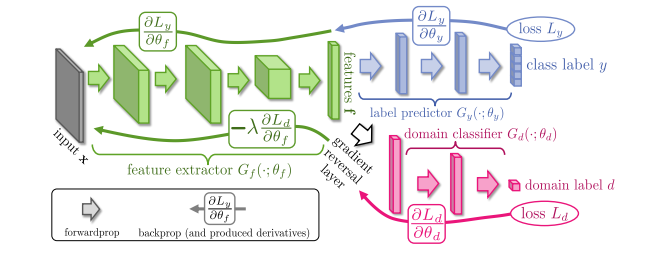
域对抗神经网络(DANN)将梯度反转层(GRL)集成到标准架构中,以确保两个域的特征分布相似)。该网络由共享特征提取层和两个分类器组成。
DANN 通过使用 GRL 使域混淆损失(所有样本)和标签预测损失(源样本)最小化,同时使域混淆损失最大化。
与上述方法相比,对抗性判别域适应(ADDA) 通过取消权重来考虑独立的源和目标映射,目标模型的参数由预训练的源模型初始化。这种方法更加灵活,因为可以学习更多特定领域的特征提取。
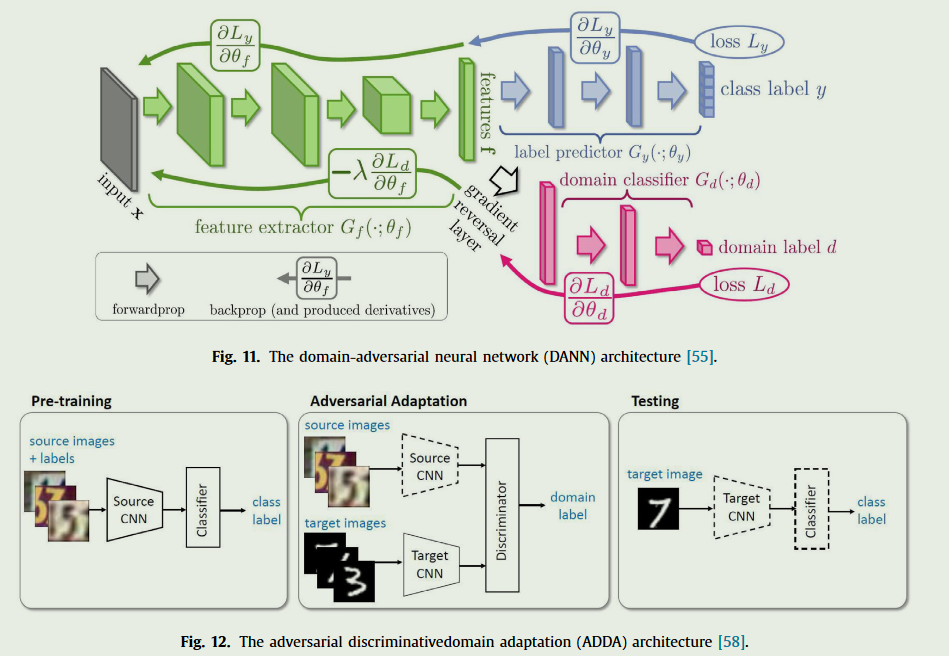
Reconstruction-based approaches
在 DA 中,源样本或目标样本的数据重构是一项辅助任务,它同时侧重于在两个域之间创建共享表征,并保持每个域的各自特点。
这篇文章分了一个同构和异构的DA方法,个人感觉其实没有太大的必要,下面直接介绍.
一些方法比较
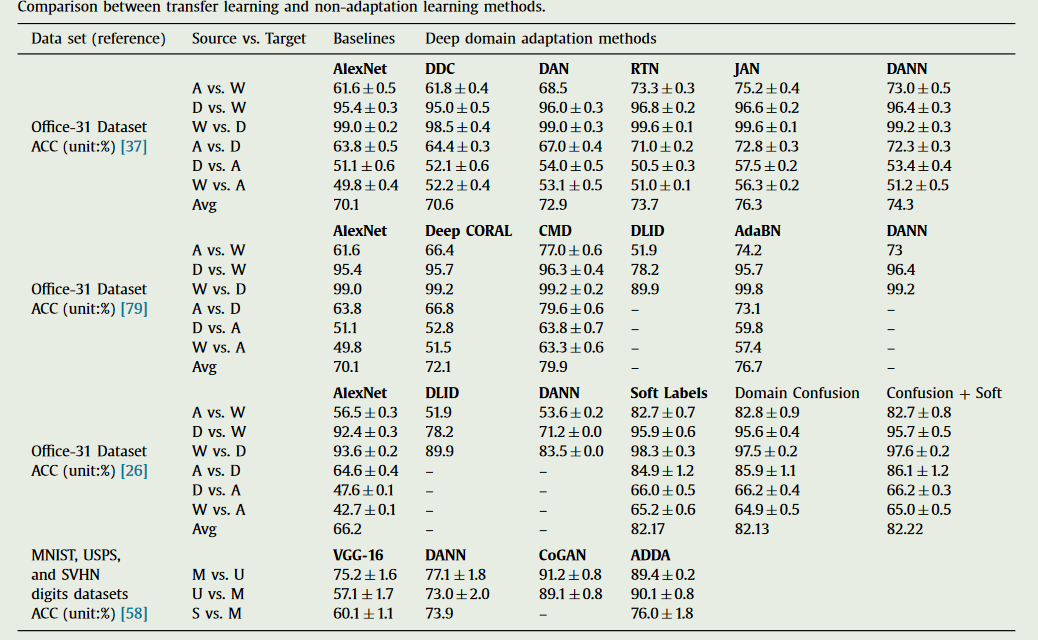
一些具体工作
Unsupervised Domain Adaptation by Backpropagation
https://arxiv.org/pdf/1409.7495与[1505.07818 (arxiv.org)](https://arxiv.org/pdf/1505.07818)
较早的域自适应工作,时间上跟GAN类似,本身也跟GAN很像.
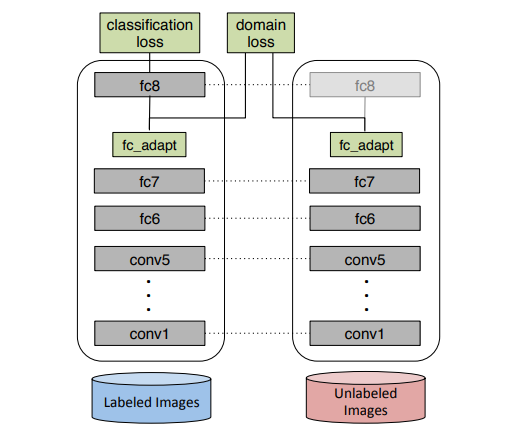
Simultaneous Deep Transfer Across Domains and Tasks
https://arxiv.org/pdf/1510.02192
同样也是远古时期论文
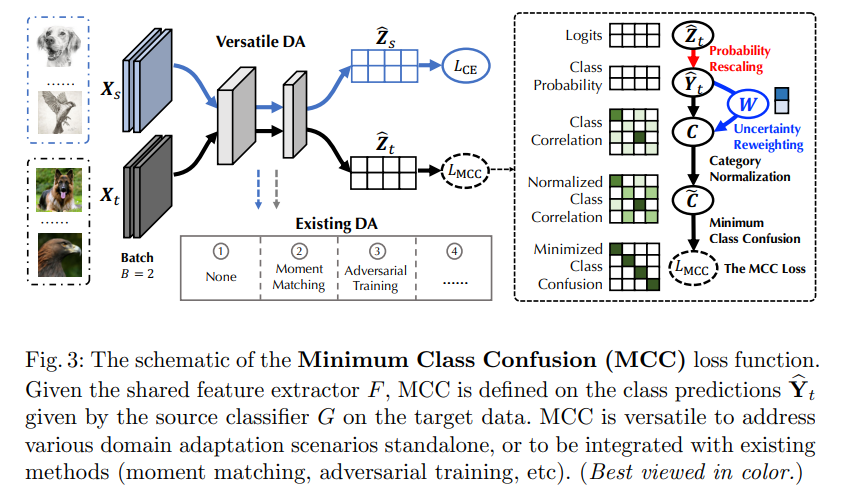
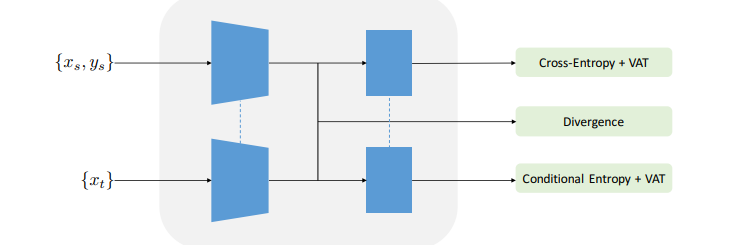
Minimum Class Confusion for Versatile Domain Adaptation
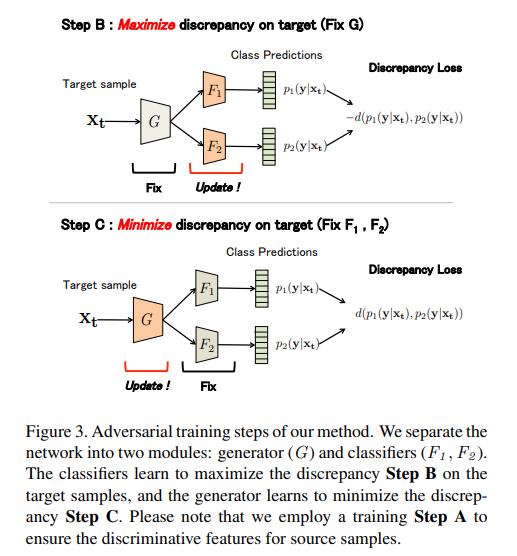
Maximum Classifier Discrepancy for Unsupervised Domain Adaptation
Deep Domain Confusion: Maximizing for Domain Invariance
Taking A Closer Look at Domain Shift: Category-level Adversaries for Semantics Consistent Domain Adaptation
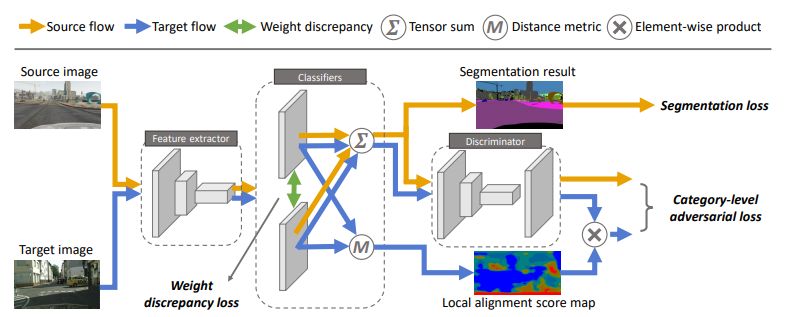
提出catergory-level的对齐.
da的关键在于减少领域偏移,即强制两个领域的数据分布相似。常见的策略之一是通过对抗学习来对齐特征空间中的边际分布。然而,这种全局对齐策略并不考虑类别级的联合分布,这种全局移动的一个可能后果是,一些原本在源域和目标域之间对齐良好的类别可能会被错误地映射,从而导致目标域的分割结果变差。
为了解决这个问题,我们引入了一个类别级对抗网络,目的是在全局对齐趋势中执行局部语义一致性。我们的想法是仔细观察类别级联合分布,并通过自适应对抗损失来对齐每个类别。具体来说,我们降低了类别级对齐特征的对抗损失权重,同时增加了那些对齐不佳特征的对抗力。
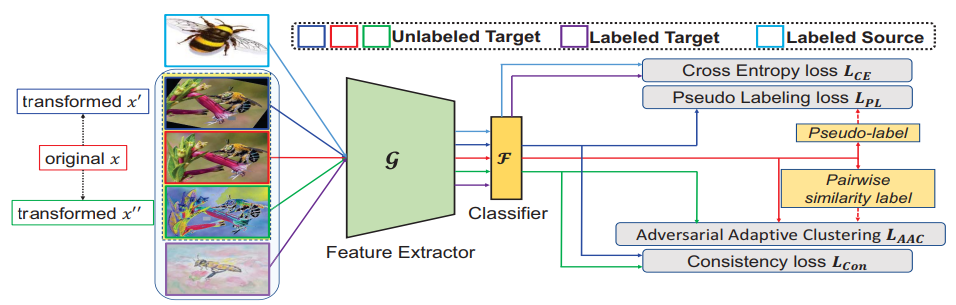
Cross-domain adaptive clustering for semisupervised domain adaptation
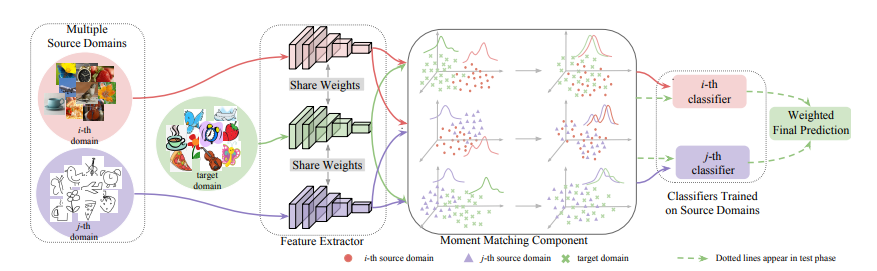
Moment Matching for Multi-Source Domain Adaptation
A DIRT-T APPROACH TO UNSUPERVISED DOMAIN ADAPTATION
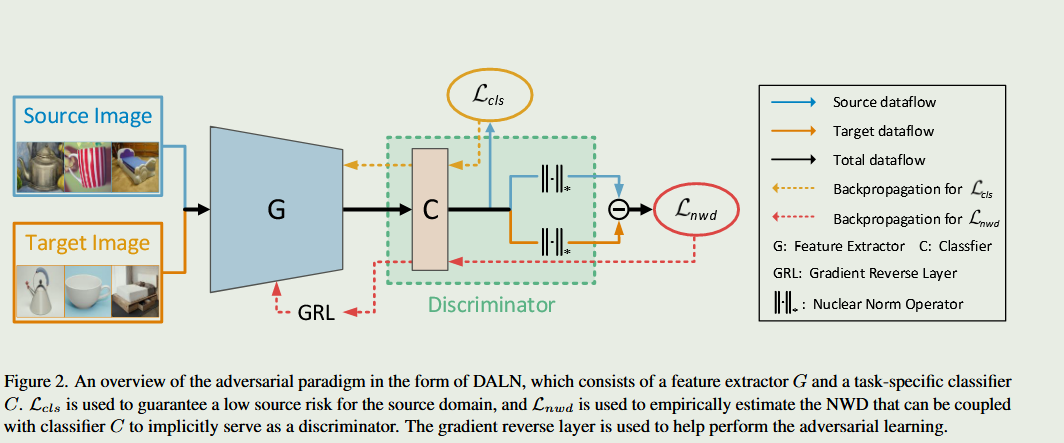
Reusing the Task-specific Classifier as a Discriminator: Discriminator-free Adversarial Domain Adaptation
摘要
对抗学习在无监督领域适应(UDA)方面取得了卓越的成绩。现有的对抗性 UDA 方法通常采用额外的判别器与特征提取器进行最小-最大博弈.
现有的对抗性 UDA 方法通常采用额外的判别器与特征提取器进行最小-最大博弈.然而,这些方法大多不能有效利用预测的判别信息,从而导致生成器的模式崩溃。
在这项工作中,我们从不同的角度来解决这个问题,设计了一种简单而有效的对抗范式,即无判别器对抗学习网络(DALN),其中类别分类器被重新用作判别器,通过统一的目标实现明确的领域对齐和类别区分,使 DALN 能够利用预测的判别信息进行充分的特征对齐。
基本上,我们引入了一种Nuclear-norm Wasserstein discrepancy,NWD,它对进行判别具有明确的指导意义。这种 NWD 可以与分类器相结合,作为满足 K-Lipschitz 约束的判别器,而无需额外的权重剪切或梯度惩罚策略。
引言
深度神经网络(DNN)在许多计算机视觉任务中取得了重大进展。然而,这些方法的成功在很大程度上取决于大量的注释数据,而获取这些数据极其耗时且昂贵。
此外,由于训练数据与真实世界测试数据之间存在差异,尽管进行了大量标注工作,但在标注数据上训练的 DNN 模型在测试集上的性能可能会急剧下降。为了解决这个问题,人们深入探讨了无监督领域适应(UDA)],其目的是在领域转移的情况下,将知识从有标注的源领域转移到无标注的目标领域。
受 Ben-David 等人理论分析的启发,现有的 UDA 方法通常都在探索学习领域不变特征表征的思路。一般来说,这些方法可分为两个分支,即矩匹配方法和对抗学习方法。矩匹配方法通过匹配源域和目标域特征的明确分布差异,明确减少域偏移。
对抗性学习方法通过进行对抗性最小-最大双人博弈,隐含地减轻了领域转移的影响,这促使生成器提取不可区分的特征,以欺骗鉴别器
有一种方法利用两个特定任务分类器 C 和 C′的差异(可将其视为判别器)来隐式地实现对抗学习并提高特征的可转移性。这种范式使 UDA 方法能够减少类级域差异。但是,遵循这种范式的方法容易受到模糊预测的影响,从而阻碍适应性优化。
另一种方法直接构建了一个额外的域判别器 D,通过充分混淆跨域特征表示来提高特征的可转移性。然而,遵循这一范式的方法通常侧重于领域级特征混淆,这可能会损害类别级信息,从而导致模式崩溃问题
Domain Adaptation in Object Detection
Domain Adaptive Faster R-CNN for Object Detection in the Wild
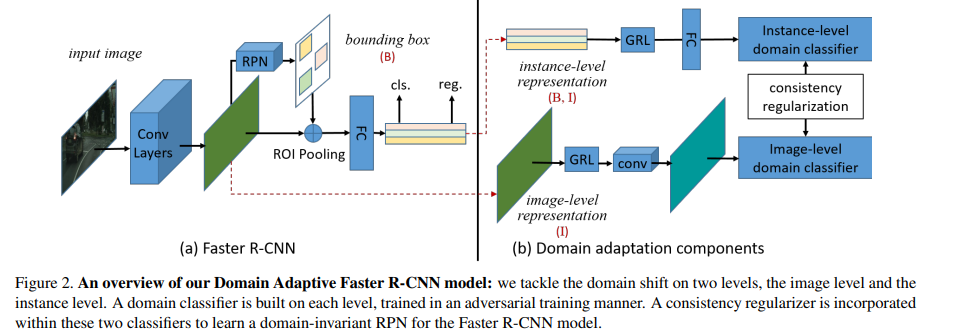
较早的用于目标检测的domain adaptation方法,使用GRL和不同level的分类器.
CDTRANS: CROSS-DOMAIN TRANSFORMER FOR UNSUPERVISED DOMAIN ADAPTATION
无监督领域适应(UDA)旨在将从标注源领域学习到的知识转移到不同的无标注目标领域。大多数现有的无监督领域适应方法都侧重于学习领域不变的特征表征,无论是从领域层面还是从类别层面,都使用基于卷积神经网络(CNN)的框架。基于类别层的 UDA 面临的一个基本问题是,目标域中的样本会产生伪标签,而伪标签通常噪声过大,无法进行准确的域对齐,这不可避免地会影响 UDA 的性能。
随着 Transformer 在各种任务中的成功应用,我们发现 Transformer 中的交叉关注对噪声输入对具有鲁棒性,可以更好地进行特征对齐,因此本文采用 Transformer 来完成具有挑战性的 UDA 任务。
具体来说,为了生成准确的输入对,设计了一种双向中心感知标签算法,为目标样本生成伪标签。除了伪标签,我们还提出了一个权重共享的三重分支transformer框架,分别用于源/目标特征学习和源/目标域对齐的自我关注和交叉关注.这种设计明确地强化了该框架,使其能够同时学习具有区分性的特定领域表征和领域不变表征。所提出的方法被称为 CDTrans(跨域transformer)它是用纯transformer解决方案解决 UDA 任务的首次尝试之一.
相关工作
UDA方法主要有两个层次:领域级和类别级。域级 UDA 通过将源域和目标域拉入不同尺度级别的相同分布中,来缓解源域和目标域之间的分布分歧。常用的分歧度量包括最大均值差异(MMD)和相关对齐(CORAL)。
最近,一些研究侧重于通过特征提取器和两个特定领域分类器之间的对抗方式进行细粒度类别级标签分布对齐。与领域尺度的粗粒度对齐不同,这种方法通过将目标样本推向源样本在每个类别中的分布,来对齐源和目标领域数据之间的每个类别分布。显然,细粒度配准能在同一标签空间内实现更精确的分布配准。尽管对抗方法通过在类别级别上融合源样本和目标样本的细粒度配准操作实现了新的改进,但它仍然无法解决噪声样本在错误类别中的问题。我们的方法采用了类别级 UDA 的 Transformers 来解决噪声问题。
伪标签法首次被引入半监督学习,并在领域适应任务中得到普及.它利用预测概率学习标记未标记数据,并与标记数据一起执行微调.在将伪标签用于领域适应任务方面,采用伪标签进行条件分布对齐;将伪标签作为领域适应的正则化;Zou 等通过交替求解伪标签设计了一种自训练框架;Caron 等提出了一种深度自监督方法,通过 k-means 聚类生成伪标签来逐步训练模型;Liang 等开发了一种自监督伪标签方法来减轻噪声伪标签的影响。在Liang 等人的基础上,本文提出了一种双向中心感知标注算法,以进一步过滤噪声伪标签对

Uncertainty-Aware Unsupervised Domain Adaptation in Object Detection

ConfMix: Unsupervised Domain Adaptation for Object Detection via Confidence-based Mixing
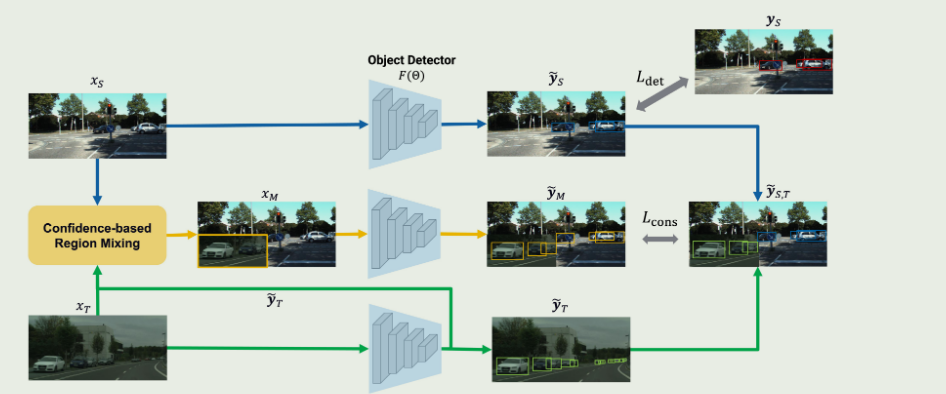
用于对象检测的无监督域自适应 (UDA) 旨在调整在源域上训练的模型,以检测来自注释不可用的新目标域的实例。与传统方法不同,我们提出了ConfMix,这是第一种引入基于区域级检测置信度的样本混合策略的方法,用于自适应目标检测器学习。我们将对应于最可靠伪检测的目标样本的局部区域与源图像混合,并应用额外的一致性损失项以逐渐适应目标数据分布。为了稳健地定义一个区域的置信度分数,我们利用了每次伪检测的置信度分数,该置信度同时考虑了检测器依赖的置信度和边界框的不确定性
参考资料
论文与代码库
adapt-python/adapt: Awesome Domain Adaptation Python Toolbox (github.com)
barebell/DA: Unsupervised Domain Adaptation Papers and Code (github.com)
目标检测的域适应
- kinredon/DA_Detection_Material: A Collection of Domain Adaptation for Object Detection Material (github.com)
- wangs311/awesome-domain-adaptation-object-detection: A collection of papers about domain adaptation object detection. Welcome to PR the works (papers, repositories) that are missed by the repo. (github.com)
- 【领域自适应目标检测】论文及代码整理 - 知乎 (zhihu.com)
