接着上一篇 从论文中看AI绘画(一)写,主要关注animation甚至video级别的生成了.
InstructPix2Pix: Learning to Follow Image Editing Instructions

将基于指令的图像编辑视为一个监督学习问题:( 1 )首先生成一个文本编辑指令和图像前/后和编辑的配对训练数据集,然后( 2 )在生成的数据集( Sec . 3.2 ,图2d)上训练一个图像编辑扩散模型。
尽管模型使用生成的图像和编辑指令进行训练但模型能够泛化到使用任意人写指令编辑真实图像。
DreamPose: Fashion Image-to-Video Synthesis via Stable Diffusion
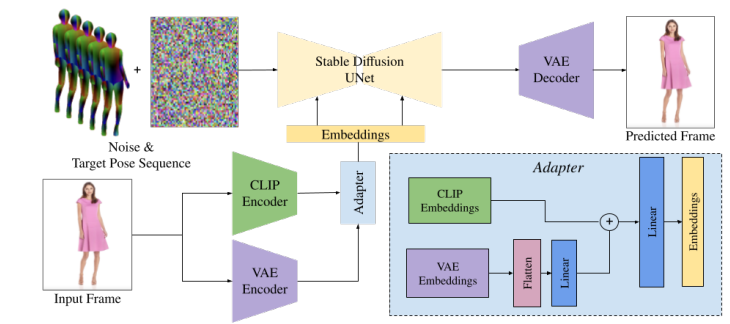
提出了DreamPose,一种基于扩散的从静态图像生成动画时尚视频的方法.给定一幅图像和人体姿态序列,合成了一个同时包含人体和运动的视频
为了实现这一点,将预训练的文本到图像模型(stable diffusion)转换为姿态和图像引导的视频合成模型,使用了一种新颖的微调策略,一组结构变化来支持添加的条件信号,以及鼓励时间一致性的技术.
修改了原有的stable diffusion架构,以启用图像和姿态调节.首先,将CLIP文本编码器替换为双CLIP-VAE图像编码器和适配器模块(在蓝色框中显示).适配器模块对预训练的CLIP和VAE输入图像嵌入进行联合建模和重塑.
然后,将围绕目标姿态的5个连续姿态组成的目标姿态表示串联到输入噪声中.在训练过程中,在完整数据集上对去噪UNet和Adapter模块进行微调,并进一步在单个输入图像上对UNet、Adapter和VAE解码器进行特定主题的微调
通过将CLIP文本编码器替换为自定义的条件适配器来实现图像调整,该适配器结合了预训练的CLIP图像和VAE编码器的编码信息
Animate Anyone: Cosistent and Controllable Image-to-Video Synthesis for Character Animation
在图像到视频领域仍然存在挑战,特别是在角色动画中,在时间上保持与角色详细信息的一致性仍然是一个艰巨的问题.利用扩散模型的力量,提出了一种为角色动画量身定制的新颖框架
为了保持参考图像中错综复杂的外观特征的一致性,设计了Reference Net,通过空间注意力来合并细节特征.
为了保证可控性和连续性,引入了一个有效的姿势引导器来指导人物的运动,并采用了一种有效的时间建模方法来确保视频帧之间的平滑帧间转换
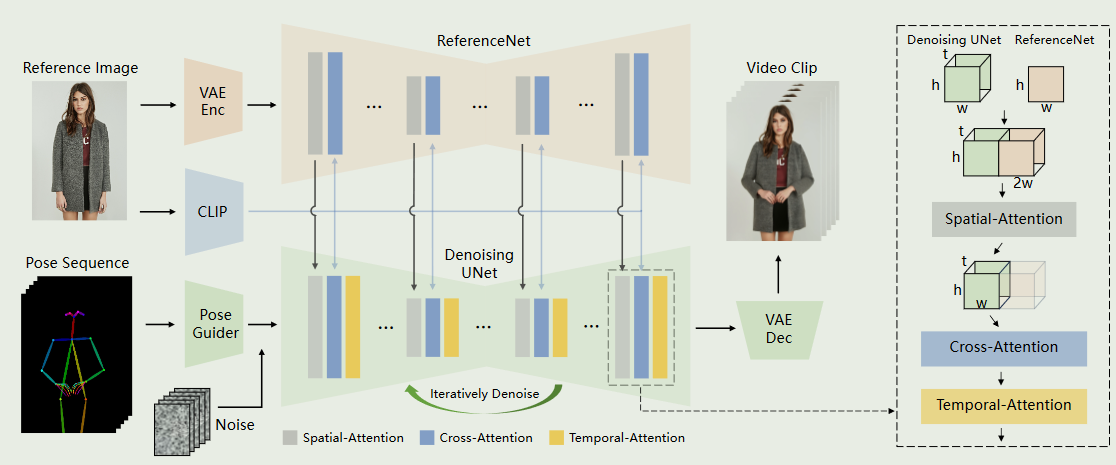
网络的初始输入由多帧噪声组成.去噪UNet基于SD的设计进行配置,采用相同的框架和分块单元,并继承了SD的训练权重.此外包含三个关键部分:1 ) Reference Net,从参考图像中编码字符的外观特征;2 )姿态引导器,对运动控制信号进行编码,实现可控的人物动作;3 )时间层,对时间关系进行编码,保证字符运动的连续性
UniAnimate: Taming Unified Video Diffusion Models for Consistent Human Image Animation
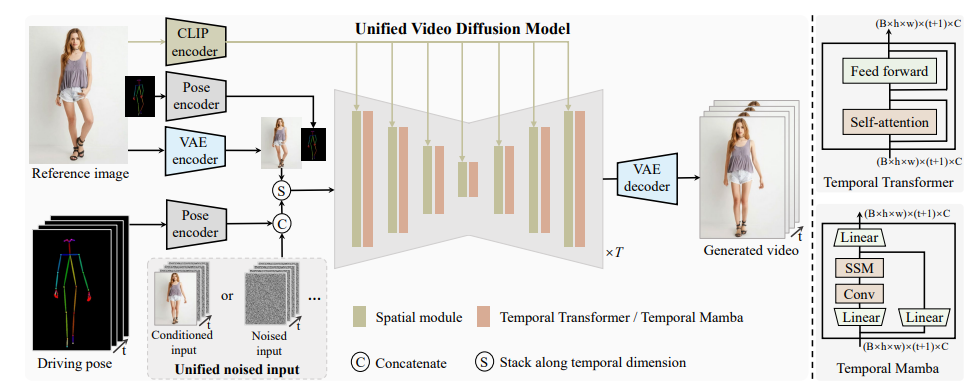
首先,利用CLIP编码器和VAE编码器提取给定参考图像的潜在特征.
为了便于学习参考图像中的人体结构还将参考姿态的表示融入到最终的参考引导中.随后,使用位姿编码器对目标driving pose序列进行编码,并将其与沿通道维度的噪声输入串联.含噪输入来自第1帧条件化视频或含噪视频.然后,将串联的含噪输入与参考引导沿时间维度进行堆叠,并输入到统一的视频扩散模型中,以去除噪声.统一视频扩散模型中的时态模块可以是时态Transformer或者时态Mamba.最后,采用VAE解码器将生成的潜在视频映射到像素空间
DisCo: Disentangled Control for Realistic Human Dance Generation
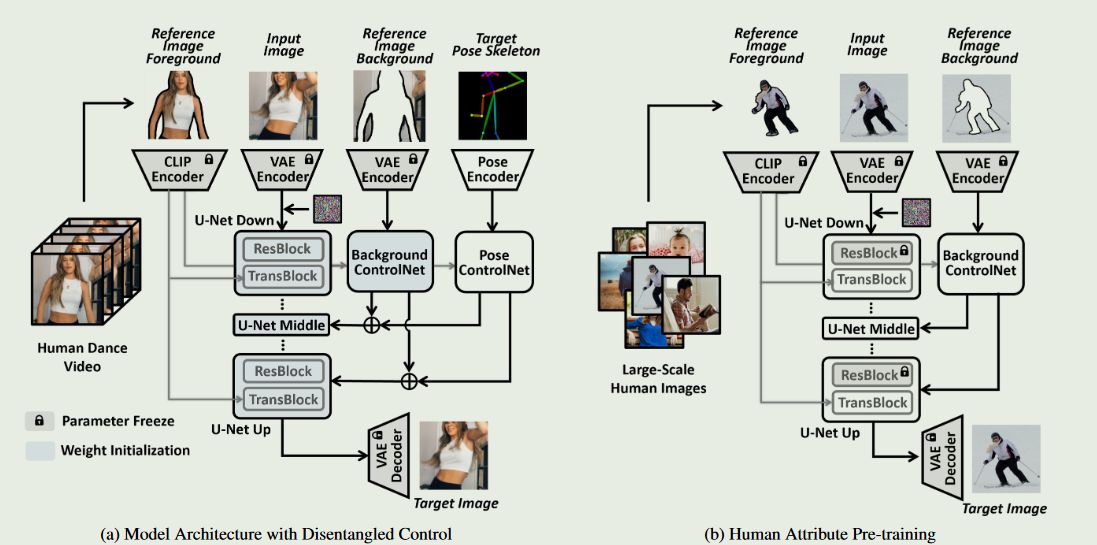
最近在图像变化方面的探索以图像嵌入为条件代替CLIP文本嵌入,可以从参考图像中保留一些高级语义.尽管如此,生成图像的几何/结构控制仍然缺失.同时,简单地将这两种设计结合在一起并不能很好地在实际中发挥作用
为了利用这两种不同控制设计的独特优势,引入了一种新颖的具有解纠缠控制的模型架构,以实现对人体姿态的精确改变,同时保持属性和背景的稳定性
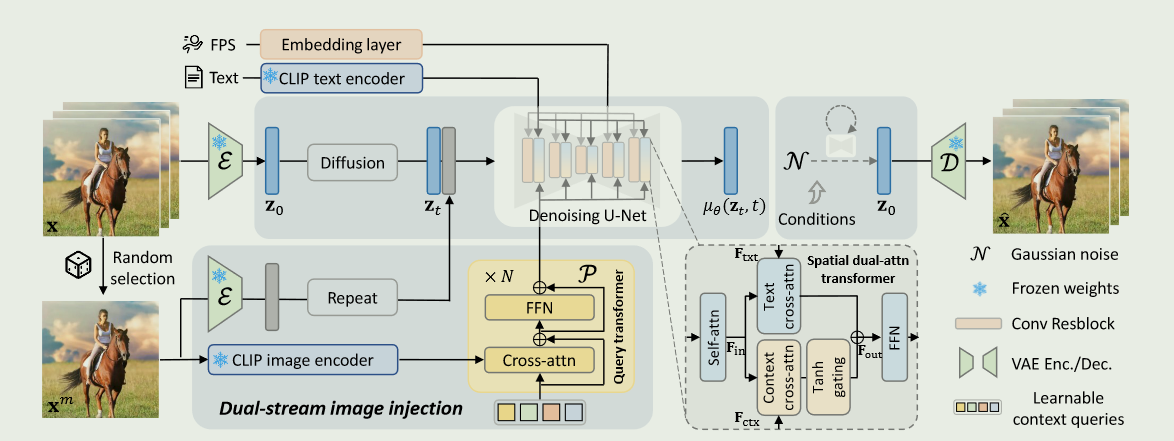
DynamiCrafter: Animating Open-domain Images with Video Diffusion Priors
传统的图像动画技术主要集中在用随机动力学(例如,云和流体)或特定领域的运动(例如,人的头发或身体运动)对自然场景进行动画,因而限制了它们对更一般视觉内容的适用性.为了克服这一限制,探索了开放域图像的动态内容合成,将其转换为动画视频.其核心思想是利用文像转换扩散模型的运动先验,将图像纳入到生成过程中作为指导.
给定一幅图像,我们首先使用query transformer将其投影到文本对齐的丰富上下文表示空间中,这有利于视频模型以兼容的方式消化图像内容.
然而,一些视觉细节仍然难以在生成的视频中得到保留.为了补充更精确的图像信息,进一步将完整图像与初始噪声级联,将其输入到扩散模型中.