之前写过modern cpp学习,但是只是过了一遍文字. 最近我在使用c++重写karpathy的micrograd,学到了很多.这里记录一下重要的东西
模板黑魔法
黑魔法是常人无法参透的,这里仅作简单介绍
1 |
|
1 |
|
1 |
|
1 |
|
- 模板元编程:在编译时执行计算,生成和优化代码.
- SFINAE:当模板参数替换失败时,编译器不会报错,而是忽略该模板.
- 静态断言:在编译时进行断言,确保某些条件成立.
- 类型 traits:查询和操作类型信息.
模板特化
模板特化是C++模板机制中的一个重要特性,它允许程序员针对特定的数据类型或一组数据类型对模板进行定制.当编译器遇到一个特化的模板实例时,它会使用特化版本而不是通用模板版本.这可以用于优化特定类型的性能,处理不同数据类型之间的差异,或者实现完全不同的行为.
模板特化概述
假设你有一个模板函数identity,它的作用是返回传入的参数本身:1
2
3
4template<typename T>
T identity(T x) {
return x;
}
基本模板
1 | template<typename T> |
函数模板特化
你可以为特定类型(如std::string)特化这个模板:1
2
3
4
5
6
7
8template<>
std::string identity<std::string>(const std::string& s) {
// 可以添加一些特定于std::string的操作
// 例如,转换为大写
std::string result = s;
std::transform(result.begin(), result.end(), result.begin(), ::toupper);
return result;
}
在这个例子中,对于std::string类型,identity函数将返回一个全部字符转为大写的字符串,而对其他类型则保持原样.
类模板特化
类模板也可以被特化.例如,假设我们有一个类模板Box,它可以存储任何类型的数据:1
2
3
4
5
6
7
8template<typename T>
class Box {
public:
void set(const T& value) { data = value; }
T get() const { return data; }
private:
T data;
};
我们可以为int类型特化Box类,以便为整数添加额外的功能,比如自动增加:1
2
3
4
5
6
7
8template<>
class Box<int> {
public:
void set(int value) { data = value + 1; } // 自动增加
int get() const { return data; }
private:
int data;
};
这样,Box<int>的行为就与Box<T>的通用版本不同了.
完全特化与部分特化
完全特化是指为模板的所有参数指定特定类型,如上面的例子所示.部分特化是指只指定模板的部分参数,通常用于多参数模板,例如:1
2
3
4
5
6
7
8template<typename T1, typename T2>
class Pair;
// 部分特化Pair<int, int>
template<>
class Pair<int, int> {
// ...
};
函数模板实例化
1 | template<typename T> |
限定类型
1 | template<typename T,typename = std::enable_if_t<std::is_arithmetic_v<T>>> |
c++20以上使用concept能够好做限制,这里不做详细介绍.Concepts library (since C++20) - cppreference.com
1 |
|
SFINAE与enable_if
使用 std::enable_if 和 SFINAE(Substitution Failure Is Not An Error,替代错误不是错误)来限定类型.这种方法允许你在模板的定义阶段就排除不符合要求的类型1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
template<typename T, typename = void>
class NumericWrapper {
private:
T data;
public:
NumericWrapper(T value) : data(value) {}
void setData(T value) {
data = value;
}
T getData() const {
return data;
}
};
template<typename T>
class NumericWrapper<T, std::enable_if_t<std::is_arithmetic_v<T>>> {
private:
T data;
public:
NumericWrapper(T value) : data(value) {}
void setData(T value) {
data = value;
}
T getData() const {
return data;
}
};
int main() {
NumericWrapper<int> intWrapper(10);
NumericWrapper<double> doubleWrapper(3.14);
// 下面的声明不会导致编译错误,但会生成一个空模板实例
NumericWrapper<std::string> stringWrapper("Hello"); // 不符合要求的类型
return 0;
}
使用场景
模板特化常用于:
- 为特定类型提供更高效的实现.
- 解决某些类型不适用的通用算法问题.
- 提供对基本类型和用户定义类型的统一接口,同时保持内部实现的差异性.
智能指针的使用场景
智能指针是C++中用来自动管理动态分配内存的一种手段,能帮助避免内存泄漏和其他与手动管理内存相关的问题.
智能指针本身也是指针,但是会通过编译器自动管理,表现行为像一个栈上的变量一样,在作用域之外就会自动析构.
std::unique_ptr是一种独占所有权的智能指针,它保证了对所指向对象的独占访问.这意味着在同一时刻,只有一个std::unique_ptr可以指向同一个对象.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
int main() {
// 使用new分配内存,并使用std::unique_ptr管理
std::unique_ptr<int> uptr(new int(10));
// 使用std::make_unique简化创建过程
std::unique_ptr<int> uptr2 = std::make_unique<int>(20);
// 访问智能指针所指向的对象
std::cout << "uptr points to: " << *uptr << std::endl;
std::cout << "uptr2 points to: " << *uptr2 << std::endl;
// unique_ptr在离开作用域时自动释放内存
return 0;
}
std::shared_ptr允许多个指针共享同一对象的所有权.当最后一个指向该对象的std::shared_ptr销毁时,对象的内存会被释放1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
int main() {
// 创建一个shared_ptr
std::shared_ptr<int> sptr1 = std::make_shared<int>(10);
// 从sptr1复制所有权
std::shared_ptr<int> sptr2 = sptr1;
// 访问智能指针所指向的对象
std::cout << "sptr1 points to: " << *sptr1 << std::endl;
std::cout << "sptr2 points to: " << *sptr2 << std::endl;
// shared_ptr在引用计数变为0时释放内存
return 0;
}
std::weak_ptr不增加引用计数,它用于观察std::shared_ptr所管理的对象,而不会影响对象的生命周期.当std::shared_ptr不再存在时,std::weak_ptr可以被用来检查对象是否还活着,并锁定一个std::shared_ptr.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
int main() {
// 创建一个shared_ptr
std::shared_ptr<int> sptr = std::make_shared<int>(10);
// 创建一个weak_ptr
std::weak_ptr<int> wptr = sptr;
// 检查weak_ptr是否过期
if (!wptr.expired()) {
std::shared_ptr<int> sptr2 = wptr.lock(); // 锁定一个shared_ptr
std::cout << "wptr points to: " << *sptr2 << std::endl;
}
// 释放shared_ptr,观察weak_ptr的行为
sptr.reset();
// 再次检查weak_ptr是否过期
if (wptr.expired()) {
std::cout << "The object has been deleted." << std::endl;
}
return 0;
}
模板类的友元函数重载<<符号
给一个模板类写个友元函数重载<<方便ostream输出信息,但是报错链接出错.
函数模板和友元重载运算符报”无法解析的外部符”的解决方法_输出运算符重载 无法解析-CSDN博客
两次编译的函数头不一样,因为友元函数并不属于类的成员函数,所以需要单独声明此友元函数是函数模板,如果没有声明,但是后面在实现的时候又使用了template <class T>,就会导致错误的发生.
右值和移动
Use std::move(x) to turn x, an l-value, to an r-value so that you can immediately take its resources
泛左值(“泛化 (generalized)”的左值)是一个求值可确定某个对象或函数的标识的表达式;
纯右值
(“纯 (pure)”的右值)是求值符合下列之一的表达式:
- 计算某个运算符的操作数的值(这种纯右值没有结果对象)
- 初始化某个对象(称这种纯右值有一个结果对象)
亡值(“将亡 (expiring)”的值)是代表它的资源能够被重新使用的对象或位域的泛左值;
- 左值 (lvalue) 是并非亡值的泛左值;
移动语义允许在对象从一个位置移动到另一个位置时,通过移动而非复制对象的状态,从而避免了昂贵的复制操作.这在处理大型对象或资源(如文件句柄、智能指针)时尤其重要,因为移动语义可以显著提升性能.
右值通常用来表示临时对象或字面量,这些对象在表达式求值后就不再需要.例如,函数返回的临时对象、构造函数参数中的字面量等都是右值
右值引用用于实现移动语义
OOP in C++
C++中的面向对象设计也许并不好或者说糟糕
编译器会为每个类默认生成特别方法,包括
- 无参构造
- 拷贝构造
- 拷贝赋值
- 移动构造
- 移动赋值
- 析构方法
如果类中的变量没有人为内存的分配,也许你并不需要显式声明拷贝、移动与析构方法.
当声明拷贝构造、赋值时,最好声明移动构造、赋值以及析构方法.
std::move在移动构造、赋值中使用,表明需要使用移动操作,而不要在main中使用.
Type Safety
Type Safety: The extent to which a language prevents typing errors
使用std::optional
Beyond C++2a
Concept
1 | concept Addable = requries(T a, T b) { |
限制泛型中参数的类型.
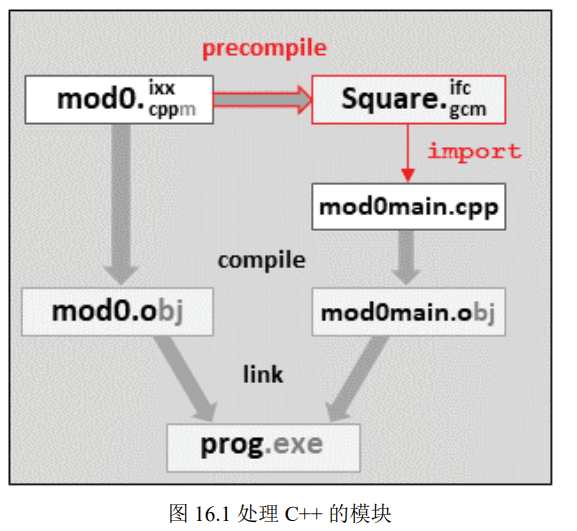
Module
目前我认为模块机制在c++生态用得不是很多,权当了解即可.模块允许程序员为代码定义 API1
2
3//该名称仅用作导入模块的标识符,不会引入新的作用域或命名空间,模块导出的任何名称仍然在导出时所在的作用域中
export module myModule
export void sayHello(){}1
2
3
4import myModule
int main(){
sayHello();
}
Modules in C++ 20 - GeeksforGeeks
代码可能由多个类、多个文件、几个函数和包括模板在内的各种辅助工具组成.通过关键字 export,可以指定导出的内容为模块的 API,该模块包装提供特定功能的所有代码,所以可以为在不同文件中实现组件,定义一个干净的 API
模块可由多个文件定义,模块文件扩展名.cppm(不同编译器可能不一样),主模块接口单元中定义模块定义export module xxx.
模块文件不仅仅是一个改进的头文件.模块文件可以同时扮演头文件和源文件的角色, 可以包含声明和定义.模块文件中,不必使用内联或预处理器保护来指定定义.当模块导出的实体在不同翻译单元导入时,不能违反同一定义规则
源模块文件不需要特定的文件扩展名,预编译模块文件也没有标准化后缀, 这是由编译器决定的
导入模块,模块不会自动引入新的命名空间,,在导出模块时所处的作用域中使用导出的模块符号1
import Square
可以将模块中的所有内容,导出到具有其命名空间中. 要么声明命名空间,在命名空间中export内容,要么将要export的内容都放在namespace中再export整个命名空间.
模块由多个模块单元组成.模块单元是属于一个模块的翻译单元
所有模块单元都必须以某种方式编译,只包含声明 (传统代码中的头文件),也需要进行某种预编译.因此,这些文件总可转换成某种特定于平台的内部格式,以避免不得不一次又一次地 (预) 编 译相同的代码.
除了主要的模块接口单元,C++ 还提供了另外三种单元类型来将模块的代码拆分为多个文件:
- 模块实现单元允许开发者在自己的文件中实现定义,这样就可以单独编译 (类似于传统的 C++ 源代码在.cpp 文件中)
- 内部分区允许开发者在单独的文件中,提供仅在模块内可见的声明和定义
- 接口分区允许开发者将导出的模块 API 拆分为多个文件
主接口
带有全局模块的主接口
主接口1
2
3
4
5
6
7
8
9
10
11module; // 全局模块
#include <string>
#include <vector>
// 声明模块
export module Mod1;
struct Order {
int count;
std::string name;
double price;
Order(int c, const std::string &n, double p) : count{c}, name{n}, price{p} {}
};
模块实现单元
模块实现单元不导出任何东西.导出只允许在模块 (主接口或接口分区) 的接口文件中进行,这些文件是用 export module 声明1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16module;
module Mod1;
double Customer::sumPrice() const {
double sum = .0;
for (const Order &od : orders) {
sum += od.count * od.price;
}
return sum;
}
double Customer::averagePrice() const {
if (orders.empty()) {
return .0;
}
}
实现单元也可以有全局模块,模块实现单元使用传统 C++ 翻译单元的文件扩展名 (大多数情况下是.cpp),编译器就像处理其 他非模块的 C++ 代码一样处理
使用模块1
2
3
4import Mod1;
int main(){
...
}
内部分区
使用内部分区可以在单独的文件中声明和定义模块的内部类型和函数.分区还可以用于在单独的文件中定义导出接口的各个部分
主接口必须导入内部分区,因为它使用 Order 类型.通过导入,分区在模块的所有单元中都可用.若主接口不需要 Order 类型,也不导入内部分区,则所有需要 Order 类型的模块单元都必须直接导入内部分区.
不支持 Mod2:Order:Main 的子分区,主接口只能使用名称:Order来导入这个分区.该文件使用了另一个新的文件扩展名:.cppp1
2
3
4
5
6
7
8module;
#include <string>
#include <vector>
module Mod2:Order; // internal partition declaration
struct Order {
int count;
Order(int c) : count(c) {}
};1
2export module Mod2;
import :Order;
分区只是模块的内部实现方面.对于代码的用户来说,代码是在主模块中、实现中还是在内部分区中都无关紧要,但不能导出内部分区中的代码.
接口分区
给分区写接口,将模块的接口拆分为多个文件,可以声明接口分区,这些分区本身可以导出相应的内容1
2
3
4
5
6
7
8
9
10
11
12
13
14
15module;
#include <string>
#include <vector>
export module Mod3:Customer;
import :Order;
export class Customer {
private:
std::string name;
std::vector<Order> orders;
public:
Customer(const std::string &n) : name(n);
}
主接口是指定模块导出内容的唯一地方,但主模块可以将导出委托给接口分区.这样做的 方法是将导入的接口分区作为一个整体直接导出.不允许导入接口分区,而不导出接口分区1
2export module Mod3;
export import :Customer; //通过同时导入接口分区和导出接口分区 (两个关键字都要写),主接口导出分区 Customer 的接口作为自己的接口
要导出导入的符号,可以使用 using1
2
3
4export module MyMod; // declare module
export import OtherModule;//export all symbls form othermodule
import LogModule // import to export
export using LogModule::Logger;
私有模块
若在主接口中声明一个模块,有时可能需要一个私有模块.这允许开发者在主接口中拥有声明 和定义,这些声明和定义对任何其他模块或翻译单元都是不可见或不可达的.使用私有模块片段的 一种方法是禁用导出类或函数的定义1
2
3
4
5
6
7
8
9
10
11
12
13
14
15export module MyMod;
export class C;
export void print(const C &c);
module :private;
class C {
private:
int value;
public:
void print() const;
};
void print(const C &c) { c.print(); }
通过将定义移动到私有模块中,导入代码就不能再使用其中的任何定义
编译器具体实践

小结
主接口将所有内容集合在一起,并指定导出给模块用户的内容 (通过直接导出符号或导出导入的接口分区). 拥有的模块单元类型取决于 C++ 源文件中的模块声明 (可以在注释和预处理器命令的全局模块之后):
- export module name; 主接口.对于每个模块,只能在 C++ 程序中存在一次.
- module name; 仅提供定义 (可能使用局部声明) 的实现单元.想要多少提供多少.
- module name:partname; 一个内部分区,声明和定义仅在模块内使用.可以有多个分区,但是对于每个 partname,只能 有一个内部分区文件.
- export module name:partname; 一个接口分区.可以有多个接口分区,但是对于每个 partname,只能有一个接口分区文件
使用传统头文件的基本方法是使用全局模块.
- 用 module 开启模块;
- 在进行模块声明之前放置所有必要的预处理器命令:
- 包含的头文件中未使用的所有内容都将丢弃.
- 使用的所有内容都将获得模块链接,所以只在整个模块单元中可见,而在其他模块单元和模 块外部都不可见.
- 在 #include 之前使用 #define
对于标准的 C++ 头文件,已经可以使 用 import,然后可以在模块中使用1
2export module ModTest;
import <chrono>
此功能只保证在标准 C++ 头文件上工作,不适用于 C++ 使用的标准 C 头文件
若想在模块中封装定义,以便导入代码只看到声明,并且仍然希望在主接口中拥有定义,必须 将定义放在私有模块中
std::ranges
引入头文件#include<ranges>和#include<algorithms>
常用的一些算法通常是对迭代器进行操作(STL)1
2std::sort(v.begin(),v.end());
std::sort(v.begin()+1,v.end());
在引入ranges后,有了更加统一的方法
ranges是“项的集合”或“可迭代的东西”的抽象.最基本的定义只要求在ranges上存在begin()和end()
1 | std::ranges::sort(std::views::drop(v,5)); |
有多个关于ranges的concept
| Concept | Description |
|---|---|
std::ranges::input_range | can be iterated from beginning to end at least once |
std::ranges::forward_range | can be iterated from beginning to end multiple times |
std::ranges::bidirectional_range | iterator can also move backwards with -- |
std::ranges::random_access_range | you can jump to elements in constant-time [] |
std::ranges::contiguous_range | elements are always stored consecutively in memory |
std::forward_list | std::list | std::deque | std::array | std::vector | |
|---|---|---|---|---|---|
std::ranges::input_range | ✅ | ✅ | ✅ | ✅ | ✅ |
std::ranges::forward_range | ✅ | ✅ | ✅ | ✅ | ✅ |
std::ranges::bidirectional_range | ✅ | ✅ | ✅ | ✅ | |
std::ranges::random_access_range | ✅ | ✅ | ✅ | ||
std::ranges::contiguous_range | ✅ | ✅ |
views的一个关键特性是,无论它们应用了什么转换,它们都是在请求元素的时候进行的,而不是在创建views的时候1
2
3
4std::vector vec{1, 2, 3, 4, 5, 6};
auto v = vec | std::views::reverse | std::views::drop(2);
std::cout << *v.begin() << '\n';
views是一种特定类型的ranges,在std::ranges::view中被形式化.
C++20之后定义比较运算符
为了检查是否相等,现在定义 == 操作符就够了. 当编译器找不到表达式的匹配声明 a!=b 时,编译器会重写表达式并查找!(a\==b).若这不起作用,编译器也会尝试改变操作数的顺序,所以也会尝试!(b==a)1
2
3
4
5
6
7bool operator==(const TypeA&, const TypeB&);
//
struct NullTerm {
bool operator== (auto pos) const {
return *pos == '\0'; // end is where iterator points to \verb+'\0'+
}
};
对于所有的关系操作符,没有等价的规则说定义小于操作符就足够了.但现在,只需要定义新的操作符 <=> 即可.
通常,== 可以通过定义 == 和!= 操作符来处理对象的相等性,而 <=> 操作符通过定义关系操作 符来处理对象的顺序.若通过 =default 声明操作符 <=>,则可以使用了一个特殊的规则,即默认成员操作符 <=>:
• 若比较成员不抛出异常,则是 noexcept
• 若可在编译时比较成员,则是 constexpr
• 因为重写,还可以支持第一个操作数的隐式类型转换
通常情况下,== 和 <=> 操作符处理不同但相关的事情: • == 操作符定义相等性,可由相等操作符 == 和!= 使用. • <=> 操作符定义了排序,可以由关系操作符 <、<=、> 和 >= 使用
auto类型推断
c++20之后,在普通函数中即可使用.使用 auto 替代模板参数 T,该特性也称为“函数模板化”的语法
因为带有 auto 的函数是函数模板,所以适用于函数模板的所有规则.从而不能在一个翻译单元 (CPP 文件) 中实现带有自动参数的函数,并在另一个翻译单元中调用.
对于具有 auto 参数的函数,实现存在于头文件,以便可以在多个 CPP 文件中使用(否则,必须在一个翻译单元中显式地实例化函数).另一方面,因为函数模板总是内联,所以不需要声明为内联
模板约束与concept
concept是用于约束模板参数的, 当然约束模板参数可以不使用concept,而是使用type_traits提供的约束,1
2
3
4
5template<typename T>
requires (!std::is_pointer_v<T>)
T maxValue(T a,T b) {
return b<a? a:b;
}
但是上面略显繁琐,如果将约束形象化,声明为类似变量一样的东西,这样就引入了concept.1
2template<typename T>
concept IsPointer = std::is_pointer_v<T>
concept可以约束别名模板、变量模板、成员函数和非类型模板参数.
概念可同时检查语法和语义约束:
• 语法约束在编译时,可以检查是否满足某些功能需求 (“是否支持特定的操作?”或“特定操 作是否产生特定类型?”).
• 语义约束满足了某些只能在运行时检查的需求 (“操作是否具有相同的效果?”或“对特定值 执行相同的操作是否总是产生相同的结果?”).
有时,概念允许开发者通过接口来指定是否满足语义约束,从而将语义约束转换为语法约束.
语义约束的一些例子
- 概念应该分组
- 谨慎定义概念
- 概念与类型特征和布尔表达式
C++17 引入了编译时 if,允许根据特定的编译时条件切换代码.当泛型代码必须为不同类型的参数提供不同的实现,但签名相同时,使用这种方法比提供重载 或特化的模板更具可读性.1
2
3
4
5
6
7
8template<typename Coll, typename T>
void add(Coll& coll, const T& val) // for floating-point value types
{
if constexpr(std::is_floating_point_v<T>) {
... // special code for floating-point values
}
coll.push_back(val);
}
requires 子句使用关键字 requires 和编译时布尔表达式来限制模板的可用性.
布尔表达式可以是:
• 编译时的布尔表达式
• 概念
• requires 表达式
可以使用布尔表达式的地方都可以使用约束 (特别是以 if constexpr 作为条件的).
编译时布尔表达式包括类型谓词(比如类型特征),编译时变量和编译时函数.
简单需求
需求表达式,需求表达式 (不同于 requires 子句) 提供了一种简单而灵活的语法,用于在一个或多个模板参数 上指定多个需求: • 必需的类型定义 • 表达式必须有效 • 对表达式产生类型的要求
类型需求,类型需求是在使用类型名称时必须格式良好的表达式,所以名称必须定义为有效类型.
复合需求允许将简单需求和类型需求结合起来,可以指定一个表达式 (大括号内),然后添加以 下一个或两个:
• noexcept 要求表达式保证不抛出异常
• -> type-constraint 将概念应用于表达式的求值
且不能在 requires 表达式的结果中,使用带有类型特性的嵌套表达式.要么先定义相应的概念,要么使用嵌套需求.
嵌套需求可用于在 requires 表达式中指定附加约束.以 requires 开头,后跟一个编译时布尔表 达式,该表达式本身也可能是或使用 requires 表达式.嵌套需求的好处是,可以确保编译时表达式 (使用所需表达式的参数或子表达式) 产生特定的结果,而不是仅仅确保表达式有效.
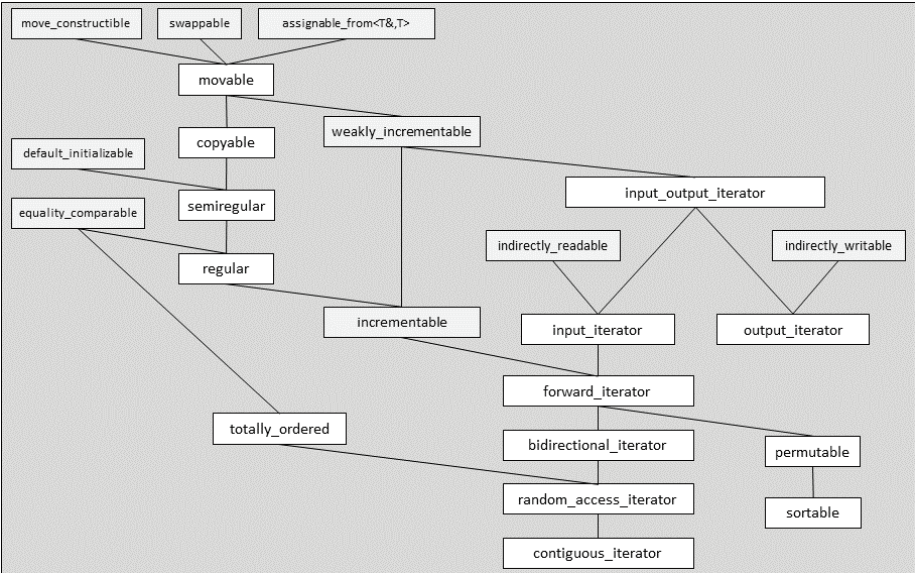
标准概念
视图的范围性
容器和字符串不是视图,因为不够轻量级: 没有提供低成本的复制构造函数,所以必须复制元 素.
使用容器作为视图:
• 通过将容器传递给范围适配器 std::views::all(),可以显式地将容器转换为视图.
• 通过将 begin 迭代器和 end(哨兵) 或大小传递给 std::ranges::subrange 或 std::views::counted(),可以显式地将容器的元素转换为视图.
• 可以通过将容器传递给其中一个自适应视图来隐式地将其转换为视图,这些视图通常通过将 容器隐式地转换为视图来获取容器
所有对作为左值传递的范围 (作为第一个构造函数参数或使用管道) 进行操作的视图,都在内部 存储对传递范围的引用. 使用视图时,底层范围必须存在
• std::counted_iterator 用于迭代器,该迭代器本身有一个计数来指定范围的结束
• std::common_iterator 用于公共迭代器类型,可用于不同类型的两个迭代器
• std::default_sentinel_t 用于结束迭代器,强制迭代器检查其结束
• std::unreachable_sentinel_t 表示永远无法到达的 end 迭代器,表示无限范围
• std::move_sentinel 用于将副本映射到 move 的 end 迭代器
FAQ
static,inline和extern. 链接类型
链接使用linker将多个编译得到.o文件链接为可执行程序. 多个链接单元不允许重复定义的变量或函数等.

inline,避免多次定义
inline 修饰的函数具有外部链接属性(externallinkage).在链接时,只会保留一个定义.C++17 引入了内联变量(inline variable)的概念,允许在头文件中定义变量而不会违反 One Definition Rule(ODR).
要声明内联变量,可以在变量声明前加上 inline 关键字.这告诉编译器允许多个编译单元中都有这个变量的定义,而不会引发 ODR 错误
static,内部链接属性(internal linkage),修饰的全局变量的作用域仅限于定义它的文件.这意味着其他文件无法访问该变量,使用 static 可以避免命名冲突,因为每个源文件中的 static变量是独立的,即使它们同名也不会互相干扰
extern,用于声明一个全局变量或函数,表明该变量或函数在其他文件中定义.它允许在一个文件中使用另一个文件中定义的变量
当 extern 用于声明一个变量或函数时,它指定该符号具有外部链接属性
通常在头文件中定义/声明全局变量,以便其他源文件可以包含该头文件并使用这些变量
在多个文件中重复定义同名的 extern 变量,会导致链接错误
外部链接属性意味着该符号可以被程序中的其他翻译单元访问.
对于函数,默认情况下它们就具有外部链接属性,无需使用 extern 关键字.
在 C++ 中,类的成员方法如果在类的定义中直接实现,则默认是 inline 的.内联函数具有外部链接属性,是弱符号.在类外实现默认不是inline,对应强符号.
一般将不需要内联的成员函数的定义编写在.cpp文件中,这样可以避免此类错误,这样多个其他文件引入头文件时不会造成重定义.
模板声明和定义放一个文件的目的.
在使用模板时,这种习惯性做法将变得不再有用,因为当实例化一个模板时,编译器必须看到模板确切的定义,而不仅仅是它的声明.因此,最好的办法就是将模板的声明和定义都放置在同一个.h文件
因为在编译时模板并不能生成真正的二进制代码,而是在编译调用模板类或函数的CPP文件时才会去找对应的模板声明和实现,在这种情况下编译器是不知道实现模板类或函数的CPP文件的存在,所以它只能找到模板类或函数的声明而找不到实现,而只好创建一个符号寄希望于链接程序找地址.但模板类或函数的实现并不能被编译成二进制代码,结果链接程序找不到地址只好报错了.
现代c++中类似函数式编程思想中的一些操作,比如filter,map,reduce(fold)等
std::transform(类似 map)
std::transform 是 C++ 标准库中的一个算法,位于 <algorithm> 头文件中.它可以对容器中的元素应用一个函数,并将结果存储到另一个容器中.这类似于函数式编程中的 map 操作.1
2
3
4
5
6
7
std::vector<int> numbers = {1, 2, 3, 4, 5};
std::vector<int> squares(numbers.size());
std::transform(numbers.begin(), numbers.end(), squares.begin(), [](int x) { return x * x; });
std::remove_if和std::erase(类似 filter)
虽然 C++ 标准库中没有直接对应 filter 的算法,但可以使用 std::remove_if 和 std::erase 来实现类似的功能.1
2
3
4
5
6
std::vector<int> numbers = {1, 2, 3, 4, 5};
numbers.erase(std::remove_if(numbers.begin(), numbers.end(), [](int x) { return x % 2 == 0; }), numbers.end());
注意remove和remove_if一般需要搭配std::erase进行实际删除,因为前两者会返回一个新容器,而旧的容器没有被改变. 被remove的值会在后面,前面的值保持原来的相对位置,使用erase(new_it_end,old_end)进行删除.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21int main() {
std::vector<int> numbers = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
// 谓词:如果元素是偶数,则返回 true
auto is_even = [](int n) { return n % 2 == 0; };
// 使用 std::ranges::remove_if 将偶数元素移到容器的末尾
auto new_end = std::ranges::remove_if(numbers, is_even);
// 使用 std::erase 删除这些元素
numbers.erase(new_end, numbers.end());
// 输出结果
for (int num : numbers) {
std::cout << num << " ";
}
std::cout << std::endl;
// 输出结果:1 3 5 7 9
return 0;
}
std::views中存在filter可以在不改变原数据实现上述功能,或者使用copy_if搭配
视图是一种在范围上应用并执行某些操作的东西.视图不拥有数据,它的复制、移动或赋值时间复杂度为常数.
1 |
|
std::back_inserter返回一个后向插入迭代器,当被解引用并赋值时,会在容器末尾执行push_back()操作.- 允许通常会覆盖元素的算法(如
std::copy)改为在容器末尾插入新元素. - 可与支持
push_back()成员函数的容器一起使用,例如std::vector和std::deque. - 不能用于不支持
push_back()的容器,如std::set或std::map,这种情况下可以使用std::inserter代替. 使用
std::back_inserter比在算法循环内手动调用push_back()更高效.std::accumulate(类似 reduce/fold)
std::accumulate 是 C++ 标准库中的一个算法,位于 <numeric> 头文件中.它可以对容器中的元素进行累积操作,类似于函数式编程中的 reduce 或 fold 操作.1
2
3
4
5
std::vector<int> numbers = {1, 2, 3, 4, 5};
int sum = std::accumulate(numbers.begin(), numbers.end(), 0);
c++中也有std::reduce, 更适合于可以并行处理的场景,尤其是当操作是可交换和可结合的(例如加法和乘法)时.以选择不提供初始值,在这种情况下,它会默认构造一个初始值.这可能导致潜在的问题
std::ranges(C++20 中的函数式编程风格)
C++20 引入了 std::ranges 库,它提供了一种更函数式编程风格的操作容器的方式.使用 std::views 命名空间中的算法,可以实现类似 map、filter 和 reduce 的操作.1
2
3
4
5cpp
std::vector<int> numbers = {1, 2, 3, 4, 5};
auto squares = numbers | std::views::transform([](int x) { return x * x; });
- Lambda 表达式
C++11 引入了 lambda 表达式,它允许你定义匿名函数.Lambda 表达式可以与上述算法一起使用,提供了类似函数式编程中的 map、filter 和 reduce 的功能.1
2
3
4
5cpp
std::vector<int> numbers = {1, 2, 3, 4, 5};
int sum = std::accumulate(numbers.begin(), numbers.end(), 0, [](int acc, int x) { return acc + x; });
使用mutable使得lambda函数可以修改闭包的值.1
2
3
4// 按引用捕获
auto modifyByReference = [&value]()mutable {
value += 5; // 修改外部变量
};
上面我最想提到的就是std::ranges和std::views,有了它们通过|符号,才有了函数式编程的感觉😋 下面更细致介绍一下
C++20 引入了 Ranges 库,这是对传统算法和迭代器库的扩展和概括,使得操作数据结构(如数组、向量等)更加简洁和强大.
范围(Range):范围是一个可以迭代的对象,通常由两个迭代器(一个指向起始位置,另一个指向结束位置)表示.C++ 标准库中的容器(如
std::vector和std::list)都是范围的实现.适配器(Adaptor):范围适配器是用于转换一个范围为另一个范围的功能.例如,
std::views::filter可以创建一个新范围,其中只包含满足特定条件的元素.视图不拥有数据.因此,视图不会延长其数据的生命周期.因此,视图只能对左值操作.如果在临时范围上定义视图,则编译将失败.
组合性:Ranges 允许将多个算法通过管道符号
|组合在一起,形成更简洁的代码.例如,可以将过滤和变换操作组合在一起,而无需创建中间容器.惰性求值:许多范围适配器是惰性求值的,意味着它们不会立即计算结果,而是在实际需要时才会执行.这可以提高性能,尤其是在处理大型数据集时.
简化语法:使用 Ranges,可以避免显式地获取迭代器的繁琐步骤,直接在容器上调用算法.
并行支持:C++20 Ranges 还支持并行执行,允许在多核处理器上高效地处理数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37// 使用copy_if拷贝数组
int main() {
std::vector<int> numbers = {1, 2, 3, 4, 5, 6};
std::vector<int> even_numbers;
std::ranges::copy_if(numbers, std::back_inserter(even_numbers), [](int n) { return n % 2 == 0; });
for (auto num : even_numbers) {
std::cout << num << " "; // 输出: 2 4 6
}
return 0;
}
// 使用filter和transform变换容器
int main() {
std::vector<int> numbers = {1, 2, 3, 4, 5, 6};
// 使用范围适配器过滤出偶数并平方
auto even_squares = numbers
| std::views::filter([](int n) { return n % 2 == 0; })
| std::views::transform([](int n) { return n * n; });
for (auto num : even_squares) {
std::cout << num << " "; // 输出: 4 16 36
}
return 0;
}此外还有std::views::reverse,take,drop等等操作.在我看来可以直接使用ranges替代很多algorithm中的操作了.
范围算法(Range Algorithms)
std::ranges::copy1
2
3
4
5
6cpp
std::vector<int> destination;
std::ranges::copy(numbers, std::back_inserter(destination));std::ranges::transform1
2cppstd::vector<int> transformed;
std::ranges::transform(numbers, std::back_inserter(transformed), [](int n) { return n * 2; });1
2cppint count = std::ranges::count_if(numbers, [](int n) { return n % 2 == 0; });
std::cout << "Even numbers count: " << count; // 输出: 3std::ranges::for_each1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
int main() {
std::vector<int> numbers = {1, 2, 3, 4, 5, 6};
// 使用 std::views::filter 过滤偶数,然后遍历并打印
std::ranges::for_each(numbers | std::views::filter([](int n) { return n % 2 == 0; }),
[](int n) {
std::cout << n << " ";
});
std::cout << std::endl;
return 0;
}std::views::iota是一个范围工厂,用于通过逐渐增加初始值来创建元素序列.这个序列可以是有限的或无限的1
2
3
4
5
6
7
8
9int main() {
std::cout << std::boolalpha;
std::vector<int> vec;
std::vector<int> vec2;
for (int i: std::views::iota(0, 10)) vec.push_back(i);
for (int i: std::views::iota(0) | std::views::take(10)) vec2.push_back(i);
std::cout << "vec == vec2: " << (vec == vec2) << '\n';
for (int i: vec) std::cout << i << " ";
}对于map也有像python那样的操作了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
int main() {
std::unordered_map<std::string, int> m{{"jack", 10086},{"black", 10010}};
auto names = std::views::keys(m);
for (const auto &name: names) {
std::cout << name << " ";
}
std::cout << "\n";
auto values = std::views::values(m);
for (const auto &value: values) {
std::cout << value << " ";
}
std::cout << "\n";
}
decay蜕变类型
std::decay 是 C++ 标准库中的一个类型特征,用于对类型进行转换,主要用于在模板编程中简化类型处理.它的主要功能是将类型转换为其“衰变”类型(decayed type)
具体来说,std::decay 进行以下三种类型转换:
- 去除引用:如果类型是引用类型(如
int&或const int&),std::decay会去掉引用,返回原始类型(如int). - 去除常量和易变性修饰符:如果类型是常量(
const)或易变(volatile)的,std::decay会去掉这些修饰符. - 数组和函数转换:如果类型是数组(如
int)或函数(如int()),std::decay会将其转换为指针类型(如int*或int(*)()).
1 |
|
volatile是 C++ 中的一个类型修饰符,用于告诉编译器某个变量的值可能会在程序的控制之外发生变化.这意味着编译器在优化代码时不应假设该变量的值是固定的
multimap
在 multimap 中,键可以重复.这意味着多个键值对可以具有相同的键,而在 map 中,键是唯一的,插入相同的键会覆盖之前的值.
multimap 通常是基于红黑树实现的,这使得插入、删除和查找操作的时间复杂度为 O(log n),其中 n 是元素的数量.multimap 不支持使用下标运算符([])或 at() 方法直接访问元素,因为相同的键可能对应多个值.
要访问特定键的所有值,可以使用 equal_range() 方法,该方法返回一个包含所有匹配键的值的迭代器范围.
multimap 中的元素是按照键的顺序存储的,默认情况下,使用 std::less<Key> 进行排序,确保元素按升序排列.相同的键值会按照插入顺序排列
参考资料
- Learn C++ – Skill up with our free tutorials (learncpp.com)
- cplusplus.com
- cppreference.com
- 现代 C++ 教程: 高速上手 C++ 11/14/17/20 - Modern C++ Tutorial: C++ 11/14/17/20 On the Fly (changkun.de)
- 首页 | 谷雨同学的 C++ 教程 (guyutongxue.site)
- CS 106L: Standard C++ Programming (stanford.edu)
- Best Practiceshttps://lefticus.gitbooks.io/cpp-best-practices/content
- Cpp 文档 - 入门、教程、参考. | Microsoft Learn
cpp书单c++ faq - The Definitive C++ Book Guide and List - Stack Overflow
感谢大模型的辅助
