作为既对AI又对sys、hpc感兴趣的人来说,cuda编程应该是不可不看的,我也早有耳闻.这里简单学习一下.
目前AI大模型的推理以及AI+HPC、深度学习系统构建等都需要了解cuda以及使用cuda编程,通过使用cuda、c++以及pybind写一些深度学习算子等提升运行速度都是一些常见应用途径.
介绍CUDA
CUDA stands for Compute Unified Device Architecture. It is an extension of C/C++ programming. CUDA is a programming language that uses the Graphical Processing Unit (GPU). It is a parallel computing platform and an API (Application Programming Interface) model, Compute Unified Device Architecture was developed by Nvidia. This allows computations to be performed in parallel while providing well-formed speed. Using CUDA, one can harness the power of the Nvidia GPU to perform common computing tasks, such as processing matrices and other linear algebra operations, rather than simply performing graphical calculations.
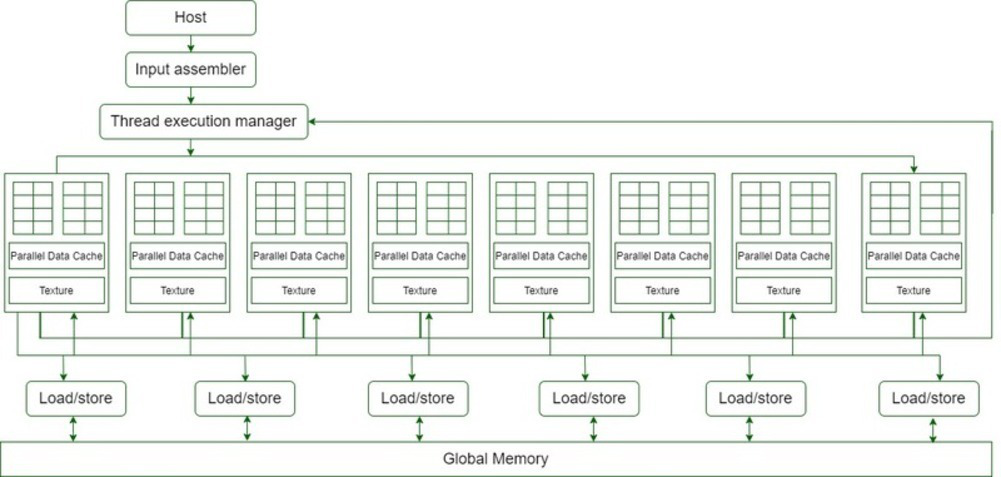
- 上图展示了16个并行(流)多(streaming multiprocessor)处理块(digrams)
- 每个并行多处理块有8个并行处理器(streanming processors),所以一共128个并行处理器
- 每个并行处理器有一个乘加单元 (Multiplication and Addition Unit)和一个加单元(multiplication unit).
- 一张GT200显卡有30个并行多处理器,每个处理器有8个并行处理器,所以一共240个并行处理器,有多余1的TFLOP处理能力
- 每个流处理器都是线程,每个应用程序可以运行数千个线程
- G80卡有16个流多处理器(SMs),每个SM有8个流处理器(SPs),即总共128个SPs,每个流多处理器支持768个线程(注意:不是每个SP)。
- 最终,每个流式多处理器有 8 个 SP 后,每个 SP 最多支持 768/8 = 96 个线程。可在 128 个 SP 上运行的线程总数 - 128* 96 = 12 228 次(=16*768)
- 因此,这些处理器被称为大规模并行处理器(massively parallel)。
- G80 芯片的内存带宽为 86.4GB/s。
- G80 芯片的内存带宽为 86.4GB/s,与 CPU 之间的通信通道为 8GB/s(4GB/s 上传到 CPU RAM,4GB/s 从 CPU RAM 下载)。
CUDA工作
- GPU 一次运行一个内核(一组任务)。
- 每个内核由独立的 ALU 组块组成。
- 每个区块包含线程,线程是计算的层次。
- 每个块中的线程通常共同计算一个值。
- 同一区块中的线程可以共享内存。
- 在 CUDA 中,从 CPU 向 GPU 发送信息通常是计算中最典型的部分。
- 对每个线程而言,本地内存速度最快,共享内存次之,全局、静态和纹理内存速度最慢。
CUDA以及工作流程
- 将数据加载到 CPU 内存
- 将数据从 CPU 复制到 GPU 内存 - 例如,cudaMemcpy(…, cudaMemcpyHostToDevice)
- 使用设备变量调用 GPU 内核 - 例如,kernel<<<>> (gpuVar)
- 将结果从 GPU 复制到 CPU 内存 - 例如,cudaMemcpy(…, cudaMemcpyDeviceToHost)
- 在 CPU 上使用结果
编写CUDA代码
需要在Nvidia显卡下安装cudatoolkit,以使用nvcc编译器和一些库.1
2
3
4
5
6
7
8__global__ void cuda_hello(){
printf("Hello World from GPU!\n");
}
int main() {
cuda_hello<<<1,1>>>();
return 0;
}
_global_说明符表示在设备(GPU)上运行的函数.这样的函数可以通过宿主代码调用,例如示例中的main()函数,也被称为“kernel”
当调用内核时,它的执行配置通过<<<…>>>语法,例如cuda_hello<<<1 ,1>>>()。在CUDA术语中,这被称为“kernel launch”
CPU和GPU是独立的实体。它们都有自己的内存空间。CPU不能直接访问GPU内存,反之亦然。在CUDA术语中,CPU内存称为主机内存,GPU内存称为设备内存。指向CPU和GPU内存的指针分别称为主机指针和设备指针.
对于GPU可以访问的数据,它必须呈现在设备内存中。CUDA提供了用于分配设备内存和主机与设备内存之间数据传输的api。
- 分为宿主内存给宿主数据
- 分配设备内存
- 将输入数据从宿主内存转到设备内存
- 执行kernels(_global\_标识 )
- 将输出从设备转移到宿主
CUDA提供了几个用于分配设备内存的函数。最常见的是cudaMalloc()和cudaFree()
分配了GPU内存后需要将cpu内存上的数据copy到设备上,利用cudaMemcpy
然后调用kernel(内核执行配置<<1 ,1>>>表示内核启动时只有1个线程),在设备上执行,最后进行freecudaFree(void *devPtr); 1
2
3cudaMalloc(void **devPtr, size_t count);
cudaFree(void *devPtr);
cudaMemcpy(void *dst, void *src, size_t count, cudaMemcpyKind kind)
性能评估
NVIDIA提供了一个名为nvprof的命令行分析器工具,它可以更深入地了解CUDA程序的性能。
CUDA使用内核执行配置<<<…>>>告诉CUDA运行时在GPU上启动多少线程
CUDA将线程组织成一个称为“thread block”的组。内核可以启动多个线程块,组织成一个“grid”结构。
1 | <<< M , T >>> |
表示启动M个线程块,每个线程块包括T个线程.
thread
CUDA为访问线程信息提供了内置变量。其中的threadIdx.x和blockDim.x分别表示,一个块内线程的索引以及一个块中线程数量.
假设在一个块内的多个线程执行并行程序.
1 | __global__ void vector_add(float *out, float *a, float *b, int n) { |

假设N个数据,一共256个线程,那么对于第k个线程,它会执行N/256次iteration,每次执行kernel中的代码
thread blocks
CUDA gpu有几个并行处理器,称为流多处理器或SMs。每个SM由多个并行处理器组成,可以运行多个并发线程块。为了利用CUDA gpu,内核应该启动多个线程块。
对于block,有blockIdx.x以及gridDim.x分别表示块索引和块的数量.

要将线程分配给特定元素,我们需要知道每个线程的唯一索引。该指数可计算如下
1 | int tid = blockIdx.x * blockDim.x + threadaddx.x |
为了利用并行多线程的优势(否则就是多个线程计算相同的代码),需要将对应的数据索引修改为线程的索引.
1 | #include <iostream> |
一些例子
1 | #include <iostream> |
1 | #include <math.h> |
学习资料
- cuda-mode/lectures: Material for cuda-mode lectures (github.com)
- CodedK/CUDA-by-Example-source-code-for-the-book-s-examples-: CUDA by Example, written by two senior members of the CUDA software platform team, shows programmers how to employ this new technology. The authors introduce each area of CUDA development through working examples. (github.com)
- CUDA Books: Self taught (github.com) maybe this is what all we need.
- An Even Easier Introduction to CUDA | NVIDIA Technical Blog
- whutbd/cuda-learn-note: 🎉CUDA 笔记 / 高频面试题汇总 / C++笔记,个人笔记,更新随缘: sgemm、sgemv、warp reduce、block reduce、dot product、elementwise、softmax、layernorm、rmsnorm、hist etc. (github.com)
- Tutorial 01: Say Hello to CUDA - CUDA Tutorial (cuda-tutorial.readthedocs.io)

- 本文链接: https://www.sekyoro.top/2024/08/16/CUDA101/
- 版权声明: 本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
欢迎关注我的其它发布渠道