开始计划做点计算机课程lab,涉及到操作系统、并行分布式系统,计算机网络,数据库系统等等.
代码lian’jiebuild-my-own-x/cs144 at main · drowning-in-codes/build-my-own-x (github.com)
Lab0
第一个项目minnow,看看CMakeLists.txt,写得是真的好.
首先确保generator必须是Unix Makefiles,然后保证out of build(也就是src和build目录不同,使用cmake -B build)
然后添加其他辅助cmake脚本,这里通过include指令添加,应该是为了访问父作用域的变量. 然后添加头文件目录,最后使用add_subdirectory添加需要编译的子项目.每个目录下都是一个CMakeLists.txt,设置CMAKE_EXPORT_COMPILE_COMMANDS得到编译指令(也是为了搭配一些编辑器使用).光是CmakeLists.txt就学到很多c++项目组织的知识.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26cmake_minimum_required(VERSION 3.24.2)
project(minnow CXX)
if(${CMAKE_GENERATOR} STREQUAL "Unix Makefiles")
set(CMAKE_MAKE_PROGRAM "${PROJECT_SOURCE_DIR}/scripts/make-parallel.sh" CACHE STRING "" FORCE)
endif()
if(${PROJECT_SOURCE_DIR} STREQUAL ${CMAKE_BINARY_DIR})
message(FATAL_ERROR "Minnow must be built outside its source directory, e.g. `cmake -B build`.")
endif()
include(etc/build_type.cmake)
include(etc/cflags.cmake)
include(etc/scanners.cmake)
include(etc/tests.cmake)
include_directories("${PROJECT_SOURCE_DIR}/util")
include_directories("${PROJECT_SOURCE_DIR}/src")
add_subdirectory("${PROJECT_SOURCE_DIR}/util")
add_subdirectory("${PROJECT_SOURCE_DIR}/src")
add_subdirectory("${PROJECT_SOURCE_DIR}/tests")
add_subdirectory("${PROJECT_SOURCE_DIR}/apps")
set(CMAKE_EXPORT_COMPILE_COMMANDS ON)
在添加的cmake脚本中,包括设置构建类型的(Debug或Release),一些编译器设置,clang-tidy和format用于语法提示和格式化,以及一些测试.
在代码中,许多c++17和20新东西都用上了,比如string_view,span等,
第一次作业要求写一个bytestream的reader和writer,分别读取和写入字节流. 我看了一些网上的实现,太吓人了,还使用`std::deque等容器,根本没必要,还可能在提交测试时出现heap overflow. 直接使用string即可,熟悉一下一些STL常用操作.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
using namespace std;
ByteStream::ByteStream(uint64_t capacity) : capacity_(capacity) {}
bool Writer::is_closed() const {
// Your code here.
return _is_closed;
}
void Writer::push(string data) {
// Your code here.
std::size_t data_len = data.length();
std::size_t avai_cap = this->available_capacity();
if (data_len >= avai_cap) {
_buffer.insert(_buffer.end(), data.begin(), data.begin() + avai_cap);
push_counts += avai_cap;
} else {
_buffer.insert(_buffer.end(), data.begin(), data.end());
push_counts += data_len;
}
}
void Writer::close() {
// Your code here.
_is_closed = true;
}
uint64_t Writer::available_capacity() const {
// Your code here.
return capacity_ - _buffer.size();
}
uint64_t Writer::bytes_pushed() const {
// Your code here.
return push_counts;
}
bool Reader::is_finished() const {
// Your code here.
return _is_closed && _buffer.empty();
}
uint64_t Reader::bytes_popped() const {
// Your code here.
return pop_counts;
}
string_view Reader::peek() const {
// Your code here.
if (_buffer.empty()) {
return {};
}
string_view sv{&*_buffer.begin(), _buffer.size()};
return sv;
}
void Reader::pop(uint64_t len) {
// Your code here.
if (_buffer.size() <= len) {
pop_counts += _buffer.size();
_buffer.clear();
} else {
_buffer.assign(_buffer.begin() + len, _buffer.end());
pop_counts += len;
}
}
uint64_t Reader::bytes_buffered() const {
// Your code here.
return _buffer.size();
}
后面我看到有人使用queue\
,效果还不错.所以我又改了😅 逻辑是每次push数据,都是推一个新的string,如果没有超过容量直接推,如果超了就截断后再推.
pop数据时,如果queue中string数据长度大于len,就不需要将该数据pop掉,而是设置为removed_prefix,方便peek时返回. 如果小于等于,就将其推掉再看下一个string的长度.
Lab1
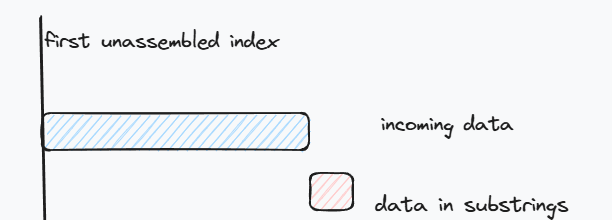
第一个实验就折磨了我很久,写一个对乱序(是指的发送的数据段的序列是乱的,数据段substring内部是顺序的)的字节流进行重排的reassembler.
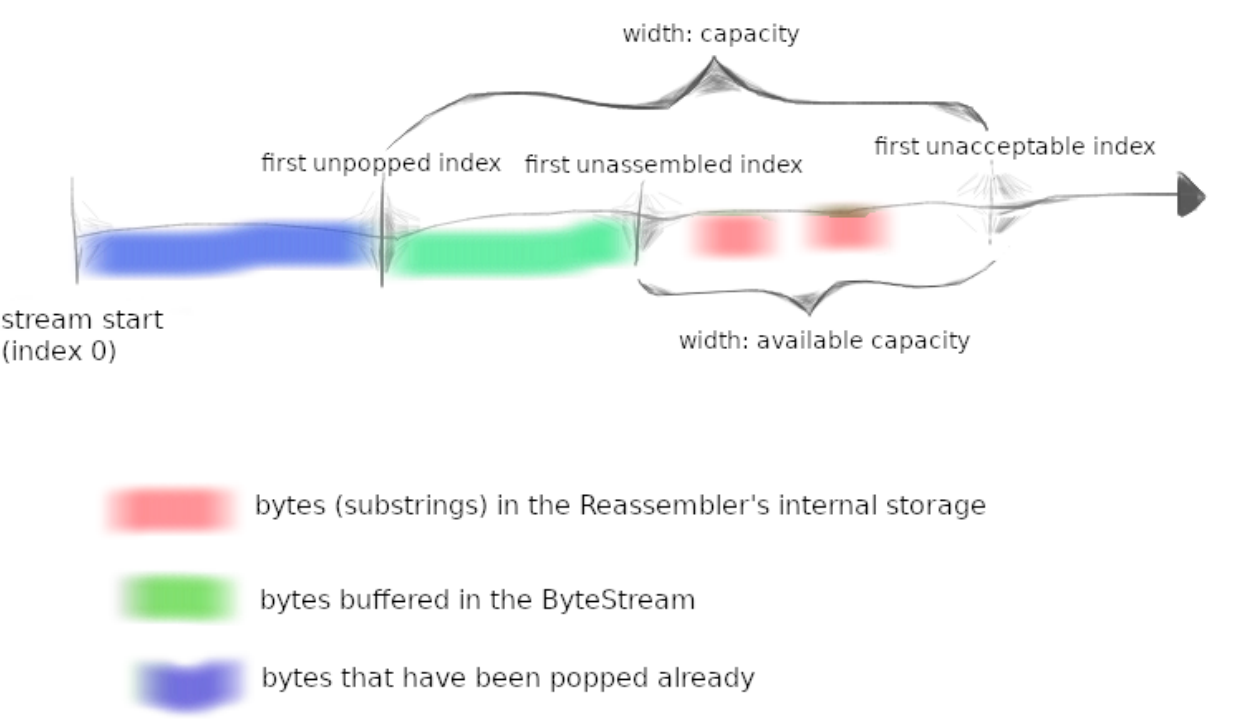
重点就是上面的图,绿色加红色的段落是固定长度并且只会往右移动到发送过来的数据最大长度.
如果来的数据段first_index为first_unasembled_index,那就说明来对了.但是在push到bytestream之前,需要注意可能有重叠部分,
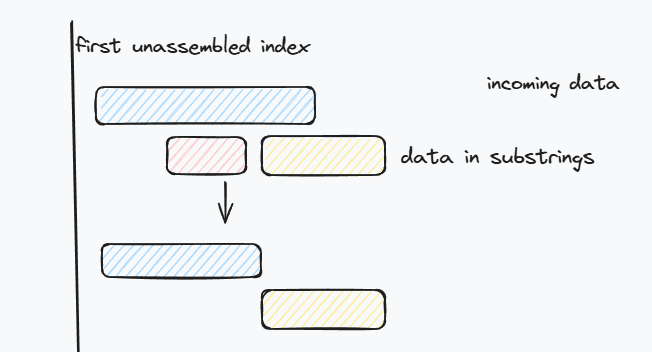
比如上面有重叠部分,需要截断数据,比较好的方法是将incoming data前面没有重叠的部分取出来作为新的数据,后面准备直接push到bytestream
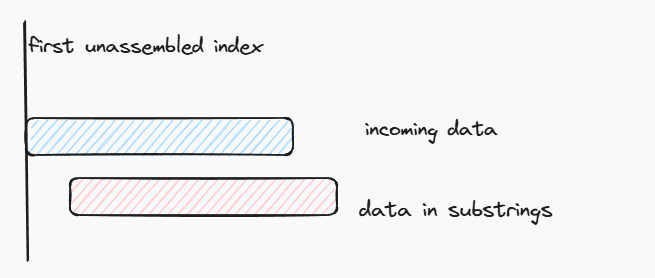
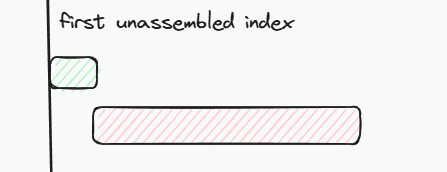
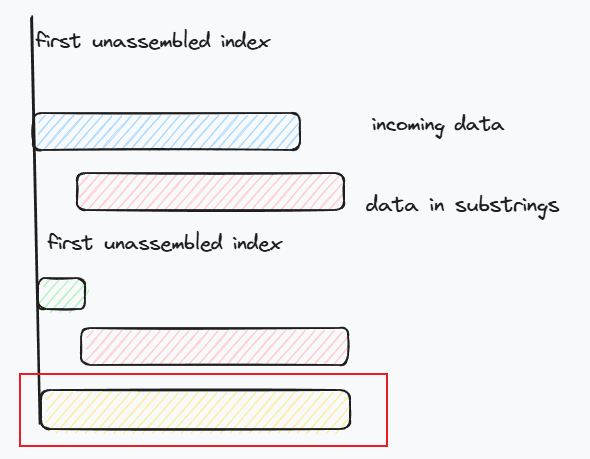
有人就要问了,为啥不直接将这段数据直接都推进去,就像下图中红框这样,如果像上面那样截断,不就要后面多推一次吗?
理论上来说也是可行的,包括也可以像下面这样截断,但隐含的问题是,这两种方法后面的数据都有可能overlap.
而像第一种截断方法中绿色那一段数据就不会有overlap. 而且后面的数据重复段可能不止一个,需要连续处理知道处理完后面的所有数据或者部分重叠.
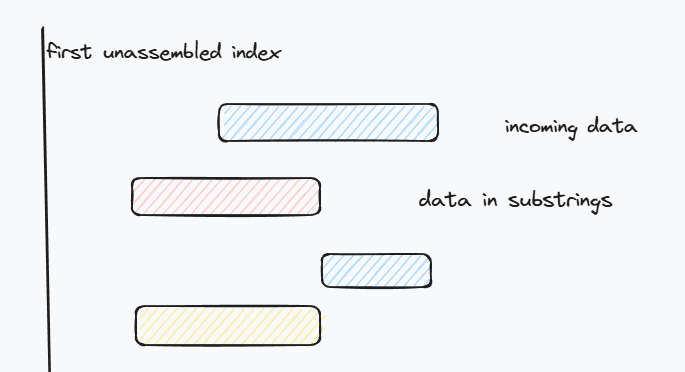
如果是完全重叠,就可以直接删掉这段,比如下面的红色段数据.
除了对后面的数据做截断,针对排在前面的数据也是类似. 注意,在这里并没有对超过first_unaccepted_index的数据段进行截取.
总的来说,首先需要对数据的first_index和大小进行调整,比如截断啥的. 使得它没有与其他数据段重叠.
然后就是判断更新后的first_index与first_unassemble_index,如果相等,push数据(由于在上一节push的实现中,如果数据长度大于capacity,就只会将数据填满,超过的数据忽略),否则放在一个map
中,称为substrings,注意这里有多种选择,你可以将其超过first_unassemble_index的段截断,也可以先直接推进去,后面再处理,但为了节省内存,可以直接先截断. 可能到这里有人以为已经结束了,但当推送了某个数据之后,可能后面的substrings就能使用上了,就需要进行处理.如果是next_assembled_idx(其实就是first_unassemble_idx==bytes_pushed),就继续推,因为前面存substrings中的数据时已经考虑到了截断超过first_unassemble_index的数据,数据长度加起来肯定小于容量,这里直接推进去就行了.
Lab2
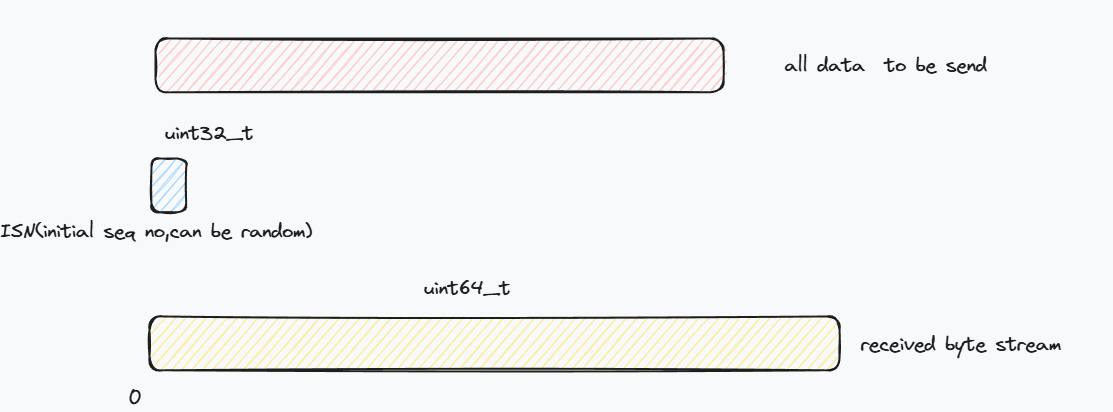
TCP是一种协议,它在不可靠的数据报上可靠地传输一对流控制的字节流(每个方向一个)。双方或“peers”参与TCP连接,每个peers都充当(其自身输出字节流的)“发送者”和“接收者”
首先需要实现一个32-bit的相对索引wrapper与64位绝对索引相互转换.
而注意在接受的数据段(stream index),是直接从0开始,不包括SYN的.
从接收到的absolute seqno->seqno,也就是从64位转为32位,比较简单,可以采取取余或者直接
static_cat<uint32_t>即可,相当于把多出的截断.从seqno->absolute seqno,有非常多可能,比如假设seqno-zero_point的值是144,那么就有可能是144+GAP*k,其中GAP是1UL<<32. 所以需要一个值帮助确定,checkpoint就是这个值,离它最近的就是这个absolute seqno. 需要做的就是求k. k是(checkpoint-absolute seqno)/(1UL<<32)的四舍五入值. 但是要注意,如果checpoint<absolute seqno,上面的公式就会出问题.当checpoint<absolute seqno时,直接返回
seqno-zero_point即可.在此基础上需要实现TCP receiver.
它将(1)从peer的发送方接收消息并使用Reassembler重新组装字节流
(2)将包含确认号(ackno)和窗口大小的消息发送回peer的发送方.
注意SYN和FIN并不包含在数据payload中,但是在计算ackno时需要加上相应的值以确定需要的数据index.
接收到数据时,如果带有SYN则对应的seqno就是zero_point(并不是数据的开始,zero_point+1才是数据),我们本身需要的是发过来的数据在absolute seqno中的索引,但这个值我们无法确定,checkpoint可以设置为bytes_pushed也就是first_unassembled_index,因为这是我们需要的值.在获得absolute seqno后还需要-1除去SYN,然后再insert数据. 如果writer关闭则设置FIN关闭,方便后面send及时关闭.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
{
Wrap32 seqno { 0 };
bool SYN {};
std::string payload {};
bool FIN {};
bool RST {};
// How many sequence numbers does this segment use?
size_t sequence_length() const { return SYN + payload.size() + FIN; }
};
struct TCPReceiverMessage
{
std::optional<Wrap32> ackno {};
uint16_t window_size {};
bool RST {};
};
class TCPReceiver
{
public:
// Construct with given Reassembler
explicit TCPReceiver( Reassembler&& reassembler ) : reassembler_( std::move( reassembler ) ) {}
// The TCPReceiver receives TCPSenderMessages from the peer's TCPSender.
void receive( TCPSenderMessage message );
// The TCPReceiver sends TCPReceiverMessages to the peer's TCPSender.
TCPReceiverMessage send() const;
// Access the output (only Reader is accessible non-const)
const Reassembler& reassembler() const { return reassembler_; }
Reader& reader() { return reassembler_.reader(); }
const Reader& reader() const { return reassembler_.reader(); }
const Writer& writer() const { return reassembler_.writer(); }
private:
Reassembler reassembler_;
};在send中,需要返回ackno和window_size,后者就是writer().available_capacity(),但注意如果初始化时超过了就设置MAX.
前者就是目前接收到的数据加上标志位.
发送数据时首先初始化SYN作为开始位置,开始位置之后的一个位置是数据位置.发送数据时携带这个标志和数据payload,同时每次只允许最多发送uint_32_t数据,所以发送数据时需要将原本64位的索引转成32位
在TCP报头中,空间是宝贵的,流中的每个字节的索引不是用64位索引表示,而是用32位的“序列号”或“seqno”表示。这增加了复杂性
当接收者拿到32位的相对索引时如何知道在绝对位置上的索引呢
关键是确定checkpoint,因为absolute seqno可能是k*GAP+offset,offset是小于GAP的.
假设如下图,如果此时发送一个之前的重复段,实际的absolute seqno比较小,如果使用bytes_pushed,那么可能会导致得到的first_index比较大. 出现这种情况的前提是,bytes_pushed>uint32_t,因为此时会有多个可能的绝对位置,如果再发送之前的数据,那么absolute seqno的first_index就会选择错误.
当我尝试这么测试时,要么报错oom要么timeout.
Lab3
实现TcpSender.在文档中需要要点都说了.但是有些细节还是容易忘.
首先在push方法中,什么时候发送数据?
只要有可读数据并且空余的window_size就能使用transmit读取数据.什么叫做空余的window_size,只要window_size大于0就能发送数据吗,事实上并不是,比如如果我连续发送了很多数据,但是window_size一直为0,我还需要不断发送直到读完所有数据吗,貌似也是可行的. 更好的方式是window_size如果小于outstanding_bytes的数量,那就先等着,直到接收到peer发来的ackno更新window_size. 每次发送的数据就是window_size-outstanding_bytes,但是有个MAX_PAYLOAD_SIZE的限制,另外注意发送的数据大小是包含SYN的,也就是说如果是开始的数据,window_size =100,那么只能发送99个数据.payload大小是99.
如何确定sender需要发送FIN?
首先reader需要结束,也就是reader().is_finished() (注意不是bytes_bufferd==0,还需要reader关闭,因为还没有关闭时也有可能存在buffer为空的情况).此外剩余的数据已经小于window_size-outstanding_bytes(相当于peer还剩的空间).
然后发送数据,开启计时同时增加发送的index和outstanding_bytes,保存发送的信息. 当接收到ackno和window_size时进行更新窗口大小,并根据ackno删除数据,如果确实超过了保留数据的ackno+seq_len,那就更新ack_abs_seqno,此外重新设置timer,如果清空了outstanding_byte_stream,那就关闭定时器,否则还是打开但需要重置时间.tick方法计时器超时并且还有重传数据时,发送最早的重传数据,重置timer,如果window_size不为0,double重传时间,重传次数+1,背后的逻辑可能是,如果window_size为0,表示peer没有什么要接受的,没有那么急
注意,当window_size为0时,说明peer没有需要的数据了,但如果依然能发送(>outstanding_bytes),就需要多发送1byte数据来查看peer还能否扩展空间.如果没有数据了就不发了.
想象一下,如果peer依然发送window_size=0,在tick中我们就会不断重试,直到超过次数然后退出.
Lab4
使用之前的工具进行数据分析.无代码
Lab5
在有了TCP实现之后,还需要怎么封装才能传输信息?
- TCP-in-UDP-in-IP:TCP段可以在用户数据报的有效载荷中携带。在正常(用户空间)设置中工作时,这是最容易实现的:Linux提供了一个接口(“数据报套接字”,UDPSocket),它允许应用程序只提供用户数据报的有效载荷和目标地址,内核负责构造UDP报头、IP报头和以太网报头,然后将数据包发送到适当的下一跳
- 内核确保每个套接字具有本地和远程地址和端口号的独占组合,并且由于内核负责将这些写入UDP和IP头,因此它可以保证不同应用程序之间的隔离
- TCP-in-IP:在通常的用法中,TCP段几乎总是直接放在互联网数据报中,在IP和TCP头之间没有UDP头。这就是人们所说的“TCP/IP”.“这有点难以实施。Linux提供了一个称为TUN设备的接口,它允许应用程序提供一个完整的Internet数据报,内核负责其余的工作(写入以太网头,并实际通过物理以太网卡发送,等等)。但是应用程序必须自己构造完整的IP报头,而不仅仅是有效负载
- TCP-in-IP-in-Ethernet: 在上述方法中仍然依赖Linux内核来实现部分网络堆栈。每次代码向TUN设备写入IP数据报时,Linux都必须用IP数据报作为有效负载构建一个适当的链路层(以太网)帧。这意味着Linux必须找出下一跳以太网目的地址,给定下一跳的IP地址。如果不知道,Linux广播一个查询:“谁声明了以下内容?IP地址?以太网地址是什么?,然后等待回复。这些功能由网络接口执行:一个将出站IP数据报转换为链路层(例如,以太网)帧的组件,反之亦然。(在实际系统中,网络接口通常有eth0、eth1、wlan0等名称)
这一节说白了就是实现简单的ARP,保存IP地址与MAC(以太网)地址映射.
关键是两个方法,接受数据和发送数据.对于发送数据,如果在映射表中,那就直接发送,如果不在,那就需要发送arp消息,但前提是之前没有发送过或者发送后超过了一定时间,发送arp消息后timer置0.注意发送的arp请求消息中,目标以太网地址为0,广播地址在以太网地址字段中而不是arp中.arp消息是payload,以太网头是header.然后将要发送的消息和next_hop保存,等接受到相应的地址后再发送.对于接受消息,如果数据是ip数据报并且目标ip是自己,就接受消息并且更新映射表,如果是新的映射设置timer,否则不管.然后看新的映射是否跟保存的消息的目标ip相同,相同则发送.如果是arp消息,也更新映射与timer,如果是请求就发送自己的ip.否则根据更新的映射发送消息. 在tick中更新timer,并且如果超时就删除对应映射. 需要注意的是,什么时候需要开启timer,什么时候删除.
发送了arp消息时需要设置为0,接收到arp回应时删除对应arp请求的ip记录. 接收到新的映射时开启timer,超过30s后删除映射表和timer.
Lab6
一个router有几个网络接口,可以在其中任何一个接口上接收Internet数据报.
router的工作是根据路由表转发它收到的数据报:路由表是一个规则列表,它告诉router,对于任何给定的数据报,
•发送哪个接口
•下一跳IP地址
实现一个路由器,它可以为给定的数据报得到这两个东西。
这里本身逻辑并不复杂,写一个路由表记录ip掩码和掩码后的地址,对应下一跳地址和interface. 首先遍历interface,拿到消息队列,对于每个消息ttl的ttl如果小于等于1,直接丢掉,否则拿去匹配路由表中,找到最长匹配的ip地址.
我一开始使用的路由表结构是map,但是发现一直过不了,改成multimap就过了,说明有重复的key,我的结构体如下,如果有重复key,表明掩码长度.
2
3
4
5
6
7
uint32_t masked_ipaddr{}; #掩码后的地址
uint8_t prefix_length{}; # 前缀长度
constexpr bool operator<(const ip_addr& ip_) const {
return prefix_length < ip_.prefix_length;
};
};由两种解决方法,要么使用multimap允许重复key,要么将<比较操作为修改
2
3
4
5
6
7
8
9
10
uint32_t masked_ipaddr{};
uint8_t prefix_length{};
constexpr bool operator<(const ip_addr& ip_) const {
if(prefix_length != ip_.prefix_length) {
return prefix_length<ip_.prefix_length;
}
return masked_ipaddr<ip_.masked_ipaddr;
};
};c++20增加了
<=>操作符和 std::strong_ordering,std::weak_ordering
,std::partial_ordering. 定义一个默认的<=>操作符基本就能允许所有比较,实在是太酷啦! 比较顺序与类中声明成员的顺序一致.
2
3
4
5
6
7
8
9
10
11
std::string name{};
double value{};
constexpr auto operator<=>(const Person &) const = default;
};
int main() {
Person p1{.name = "张三", .value = 12.}, p2{.name = "李四", .value = 13.};
if (p1 == p2) {
puts("我们都一样");
}
}Lab7
lab7也是测试
总结
本次计算机网络实验,从一开始的bytestream,到reassember,再到tcpsender,reader,最后写路由分配ip数据报.
参考资料
- Kiprey/sponge: CS144 Lab Assignments (github.com)
- Kenshin2438/CS144: CS 144: Introduction to Computer Networking, Winter 2024 (github.com)
- CS 144: Introduction to Computer Networking
-------------本文结束感谢您的阅读-------------感谢阅读.
- 本文链接: https://www.sekyoro.top/2024/09/01/cs144-intro-to-computer-network/
- 版权声明: 本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
欢迎关注我的其它发布渠道