传统深度学习,或者说在llm之前的深度学习,现在看来,还是有很多trick以及各种模块”缝合”的内容,这部分有很多提出来的方法其实都有一些共通点的,这里简单回顾总结一下.
Vision Transformer and its variants
AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
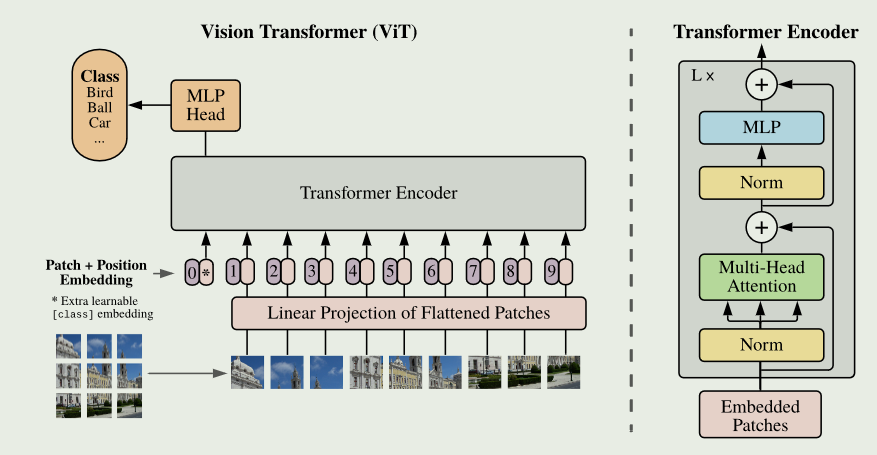
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
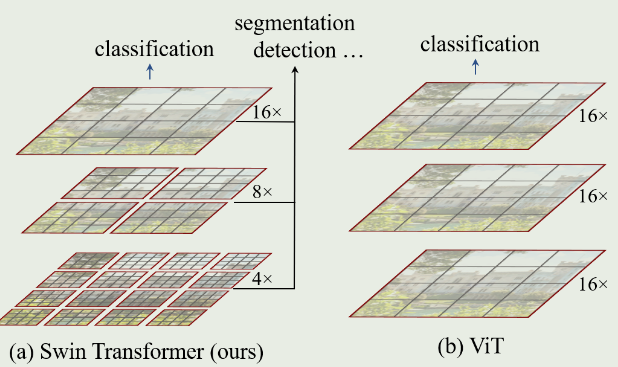
Modernify Conv
A ConvNet for the 2020s
出发点是一个ResNet-50模型.首先使用类似的训练技术来训练vision transformer,并获得了比原始ResNet-50更好的结果
然后我们研究了一系列的设计决策,总结为
1 )marco design,2 ) ResNeXt,3 )inverted- bottleneck,4 )大核尺寸,5 )各种layer-wise的mirco design.
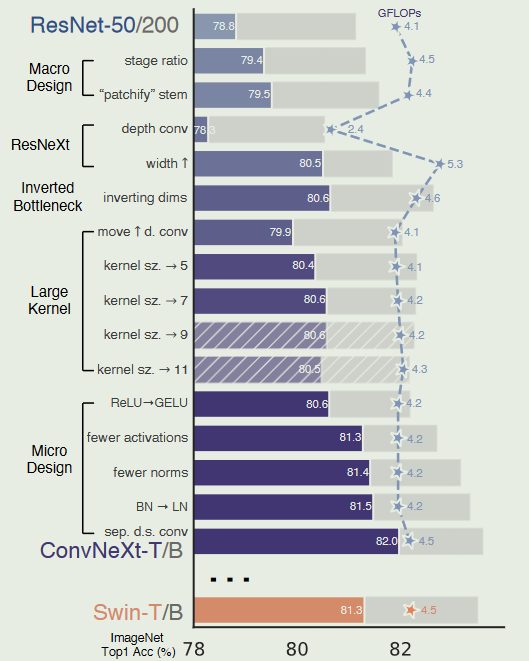
训练技术
最近的研究表明,一套现代的训练技术可以显著提高一个简单的ResNet-50模型的性能.在本研究中,使用了与Dei-T和Swin Transformer相近的训练方法.
对于深度残差网络,训练从原来的90次扩展到300次.
使用Adam W优化器,数据增强技术如Mixup、Cutmix、Rand Augment、Random Erasing,以及正则化方案包括Stochastic Depth和Label Smoothing
Marco Design
修改阶段计算比例
Swin-T阶段计算比例略有不同,为1:1:3:1.对于较大的Swin Transformer,比例为1:1:9:1.
根据设计将每个阶段的块数从ResNet-50中的( 3、4、6、3)调整为( 3、3、9、3),这也将FLOPs与Swin-T对齐
修改stem为patchify
标准ResNet中的stem包含一个7 × 7的步幅为2的卷积层,然后是一个max pooling,这导致对输入图像进行4 ×的下采样.
在Vision Transformers中,使用了patchify策略作为stem,对应于较大的核尺寸(如kernel大小= 14或16)和非重叠卷积.
Swin Transformer使用了类似的” Patchify “层,但是具有更小的Patch size 4以适应架构的多级设计
将ResNet风格的stem替换为使用4 × 4,stride为4的卷积层实现的patchify层.准确率从79.4 %变为79.5 %.这表明ResNet中的stem可能被更简单的” patchify “层ViT替代,这将导致类似的性能
ResNext-ify
核心部件是group normalization,其中卷积滤波器被分成不同的组.在更高的层面上,ResNeXt的指导原则是”利用更多群体,拓展宽度”.更确切地说,ResNeXt对瓶颈块中的3 × 3 conv层使用分组卷积.由于这显著降低了FLOPs,因此扩大了网络宽度以补偿容量损失,
depth-wise卷积类似于自注意力中的加权和操作,它在每个通道的基础上操作,即只在空间维度上混合信息
深度卷积和1 × 1卷积的结合导致了空间和通道混合的分离,这是视觉转换器共有的特性,其中每个操作要么混合了空间或通道维度的信息,但不是两者都混合.
depth-wise卷积的使用有效地降低了网络的FLOPs,但会降低精度
根据ResNeXt提出的策略,将网络宽度增加到与Swin-T的( 64 ~ 96)相同的通道数.随着FLOPs ( 5.3G )的增加,网络性能达到80.5 %.
Inverted Bottleneck
在每个Transformer模块中,一个重要的设计是它创建了一个反向瓶颈,即MLP模块的隐藏维度比输入维度宽4倍
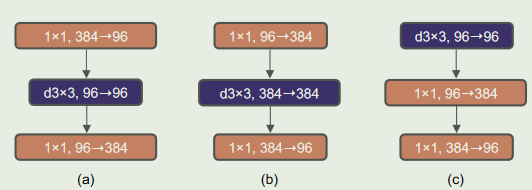
尽管depth-wise卷积层的FLOP值有所增加,但由于下采样残差块的捷径1 × 1 conv层的FLOP值显著降低,该变化使得整个网络的FLOP值降低到4.6 G
更大的尺寸大小
Vision Transformer最具有特色的一个方面是其非局部自注意力,这使得每一层都具有全局的感受野.过去,卷积神经网络使用大的内核尺寸,而(由VGGNet 推广)的金标准是堆叠小的内核尺寸( 3 × 3 )的conv层,它们在现代GPU上具有高效的硬件实现
虽然Swin Transformers将局部窗口重新引入到自注意力块中,但窗口大小至少为7 × 7,明显大于ResNe ( X ) t核大小3 × 3.在这里重新考虑了卷积神经网络中大核卷积的使用.
为了探索大核,一个先决条件是将depth-wise卷积放在前面.这在Transformers中也是显而易见的设计决策:MSA块( 大内核conv)放置在复杂/低效的模块的MLP层之前会有更少的通道,而高效、密集的1 × 1层会做繁重的提升.这一中间步骤将FLOPs降低到4.1 G,导致性能暂时下降到79.9 %.
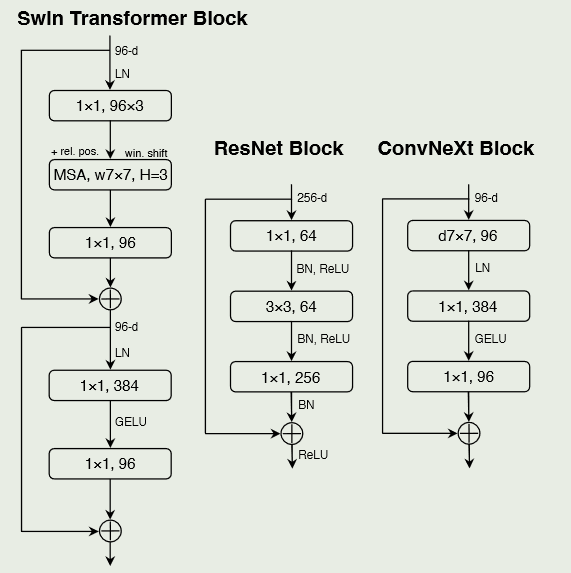
在所有这些准备工作中,采用更大的核卷积的好处是显著的.实验了几种不同的核尺寸,包括3、5、7、9和11.网络的性能从79.9 % ( 3 × 3 )提高到80.6 % ( 7 × 7 ),而网络的FLOPs基本保持不变.此外观察到较大的核尺寸带来的收益在7 × 7处达到饱和点.在大容量模型中也验证了这一行为:将内核大小增加到7 × 7以上时,ResNet - 200机制模型没有表现出进一步的增益
Micro Design
使用GELU替换RELU
NLP和视觉架构的一个不同之处在于使用的激活函数的具体形式.随着时间的推移,许多激活函数已经被开发出来,但ReLU 由于其简单和高效,仍然被广泛用于卷积神经网络中.
在ConvNet中,ReLU也可以用GELU代替,尽管精度保持不变
更少的激活函数
transfomer的激活函数较少.考虑一个具有key / query / value线性嵌入层的Transformer块,一个MLP块中的投影层和两个线性层.MLP块中只有一个激活函数.相比较而言,通常的做法是在每个卷积层中添加一个激活函数,包括1 × 1卷积层.
除了两个1 × 1层之间的GELU层外,从残差块中消除了所有GELU层,复制了Transformer块的风格.该过程使结果提高了0.7 % ~ 81.3 %,与Swin - T的性能基本匹配
更少的normalization层
transformer块通常也具有较少的归一化层数.这里去掉两个Batch Norm ( BN )层,在conv 1 × 1层之前只留下一个BN层.
每个块的归一化层数甚至比Transformers还要少,因为从经验上发现在块的开头增加一个BN层并不能提高性能
替换BN为LN
BatchNorm是卷积神经网络中的一个重要组成部分,它提高了收敛性并减少了过拟合
更简单的层归一化 在Transformer中得到了应用,在不同的应用场景中表现出良好的性能
直接将原始ResNet中的LN替换为BN会导致次优的性能.随着网络结构和训练技术的改变,这里重新使用LN代替BN的影响,观察到ConvNet模型在使用LN进行训练时没有任何困难;事实上,性能略好,获得了81.5 %的准确率
单独的下采样层
在ResNet中,空间下采样是通过每个阶段开始时的残差块来实现的,采用3×3的conv,stride为2 (short connection时使用stride为2的1 × 1 conv).
在Swin Transformers中,不同尺度之间增加了单独的下采样层.这里使用2×2的conv层和stride为2进行空间下采样.
进一步的研究表明,在空间分辨率变化的地方增加归一化层有助于稳定训练.其中包括Swin Transformers中也使用的几个LN层:每个下采样层之前的一个,stem之后的一个,最后全局平均池化之后的一个.可以将准确率提高到82.0%,明显超过Swin-T的81.3%
Early Convolutions Help Transformers See Better
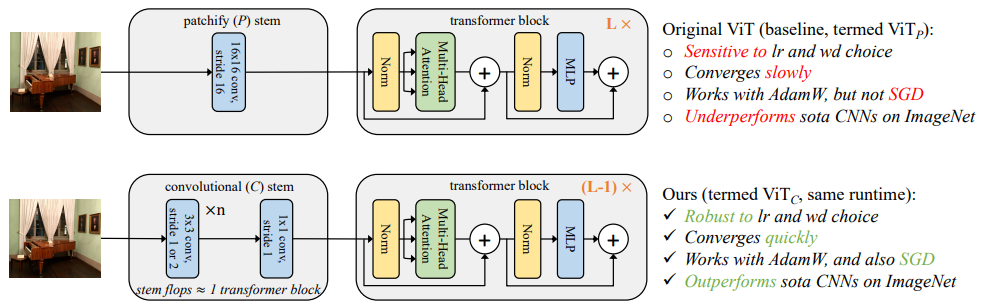
Vision Transformer(ViT)模型表现出不达标的可优化性。特别地,它们对优化器( Adam W vs . SGD)、优化器超参数和训练调度长度的选择非常敏感。相比较而言,现代卷积神经网络更容易优化。为什么会出现这种情况?在这项工作中猜想问题在于ViT模型的patchify stem,它是通过应用于输入图像的stride-p p × p卷积(默认p = 16)来实现的
也就是下采样p倍
这种大核加大步长的卷积与神经网络中卷积层的典型设计选择背道而驰。为了检验这种非典型的设计选择是否会导致问题,分析了ViT模型的优化行为,其原始的Patchify词干与一个简单部分对应,将ViT patchify stem替换为少量堆叠的stride-2 3 × 3卷积。
虽然两种ViT设计的绝大多数计算量是相同的,但发现这种早期视觉处理的微小变化导致训练行为在对优化设置的敏感性以及最终的模型精度方面有明显的不同。在ViT中使用卷积树干显著地增加了优化的稳定性,并提高了峰值性能(在ImageNet - 1k上的top - 1准确率提高了1 - 2 %),同时保持了触发器和运行时间
这种改进可以在模型复杂度(从1G到36G触发器)和数据集规模(从ImageNet - 1k到ImageNet - 21k)的宽光谱范围内观察到。这些发现促使我们推荐在该机制下为ViT模型使用一个标准的、轻量级的卷积主干,作为比原始ViT模型设计更稳健的架构选择。
Vector quantization and Codebook
Neural Discrete Representation Learning
1711.00937] Neural Discrete Representation Learning (arxiv.org)
在没有监督的情况下学习有用的表示(个人认为算是自监督->生成式学习)仍然是机器学习中的一个关键挑战.
VQ-VAE 两个关键方面与VAEs不同:
- encoder输出离散的编码,也就是中间嵌入是离散的
- 先验知识是学到的.
为了学习一个离散的潜在表示,结合了向量量化( VQ )的思想.使用VQ方法可以使模型避免”后验崩溃”问题- -当潜在变量(中间嵌入)与decoder配对时被忽略
离散潜变量(中间嵌入)
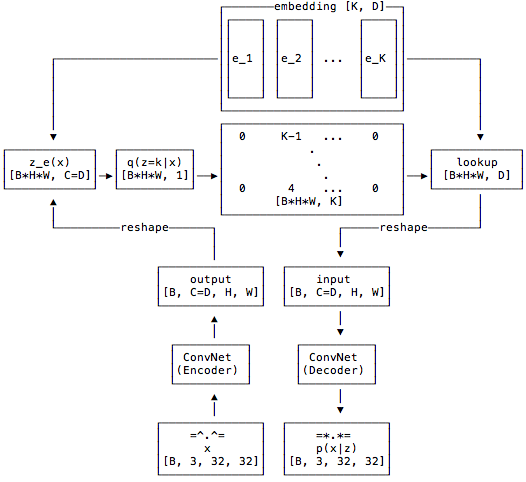
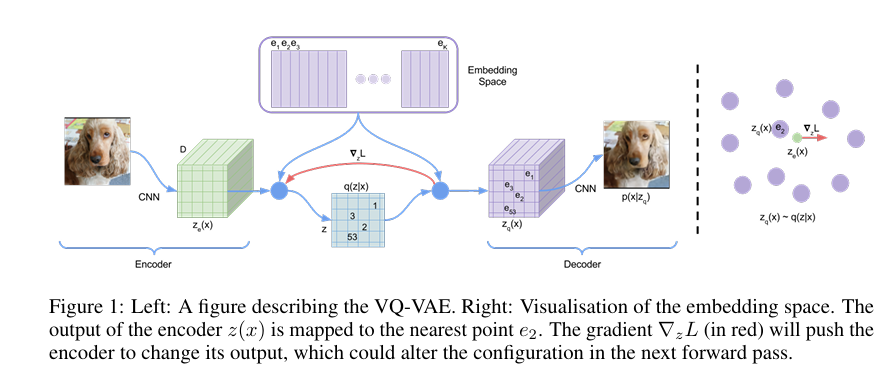
定义一个潜在嵌入空间e∈R^K×D^,其中K为离散潜在空间(即K - way范畴)的大小,D为每个潜在嵌入向量e^i^的维数.注意到存在K个嵌入向量e~i~∈R^D^,i∈1,2,..,K.该模型取一个输入x,通过编码器产生输出z~e~(x)
然后利用共享嵌入空间e通过最近邻查找计算离散潜变量z
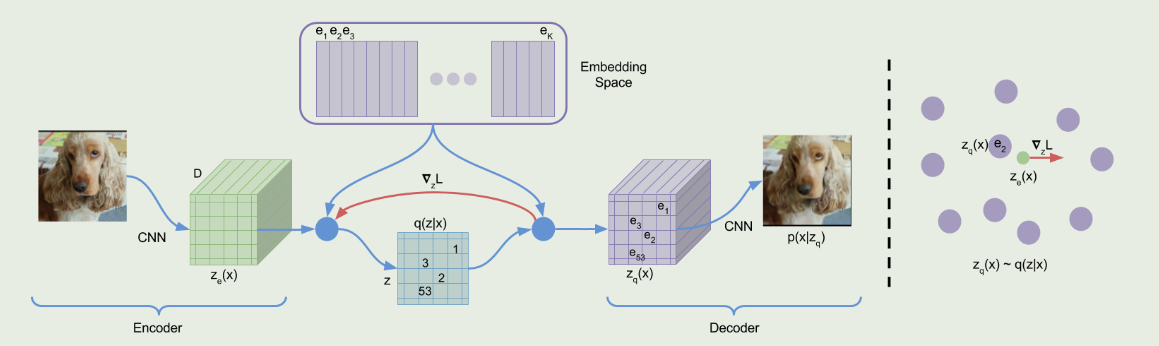
Z~e~(x)是编码器网络的输出,根据这个输出通过找到最近邻映射到给定的潜在空间中,得到z~q~(x)作为decoder的输入.
对于梯度,直接将z~q~(x)的梯度copy到z~e~(x)
由于encoder的输出表示和decoder的输入共享相同的D维空间,梯度包含了encoder如何改变其输出以降低重构损失的有用信息
总损失如下,有三个组成部分,分别用于训练VQ-VAE的不同部分.
第一项是重构损失(或数据项),它优化了解码器和编码器
由于z~e~ (x)到z~q~( x)映射的直通梯度估计(梯度直接copy),嵌入e~i~没有从重构损失log~p~ ( z | z~q~ ( x ) )中获得梯度.因此,为了学习嵌入空间,使用最简单的字典学习算法之一,向量量化( VQ ).VQ目标使用l2误差将嵌入向量e~i~移动到编码器输出z~e~ (x).
最后,由于嵌入空间的体积是无量纲的,如果嵌入e~i~的训练速度没有编码器参数那么快,嵌入空间的体积可以任意增长.
Sg表示在前向计算时定义为恒等式且具有零偏导数的停止梯度算子,从而有效地约束其操作数为非更新常数
decoder只优化第一个损失项,encoder优化第一个和最后一个损失项,嵌入由中间损失项优化.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43class VectorQuantizer(nn.Module):
def __init__(self, num_embeddings, embedding_dim, commitment_cost):
super(VectorQuantizer, self).__init__()
self._embedding_dim = embedding_dim
self._num_embeddings = num_embeddings
self._embedding = nn.Embedding(self._num_embeddings, self._embedding_dim)
self._embedding.weight.data.uniform_(-1/self._num_embeddings, 1/self._num_embeddings)
self._commitment_cost = commitment_cost
def forward(self, inputs):
# convert inputs from BCHW -> BHWC
inputs = inputs.permute(0, 2, 3, 1).contiguous()
input_shape = inputs.shape
# Flatten input
flat_input = inputs.view(-1, self._embedding_dim)
# Calculate distances
distances = (torch.sum(flat_input**2, dim=1, keepdim=True)
+ torch.sum(self._embedding.weight**2, dim=1)
- 2 * torch.matmul(flat_input, self._embedding.weight.t()))
# Encoding
encoding_indices = torch.argmin(distances, dim=1).unsqueeze(1)
encodings = torch.zeros(encoding_indices.shape[0], self._num_embeddings, device=inputs.device)
encodings.scatter_(1, encoding_indices, 1)
# Quantize and unflatten
quantized = torch.matmul(encodings, self._embedding.weight).view(input_shape)
# Loss
e_latent_loss = F.mse_loss(quantized.detach(), inputs)
q_latent_loss = F.mse_loss(quantized, inputs.detach())
loss = q_latent_loss + self._commitment_cost * e_latent_loss
quantized = inputs + (quantized - inputs).detach()
avg_probs = torch.mean(encodings, dim=0)
perplexity = torch.exp(-torch.sum(avg_probs * torch.log(avg_probs + 1e-10)))
# convert quantized from BHWC -> BCHW
return loss, quantized.permute(0, 3, 1, 2).contiguous(), perplexity, encodings
- VQVAE PyTorch 实现教程 - 知乎 (zhihu.com)
- Pytorch-VAE-tutorial/02_Vector_Quantized_Variational_AutoEncoder.ipynb at master · Jackson-Kang/Pytorch-VAE-tutorial (github.com)
- pytorch-vq-vae/vq-vae.ipynb at master · zalandoresearch/pytorch-vq-vae (github.com)
Generating Diverse High-Fidelity Images with VQ-VAE-2
Taming Transformers for High-Resolution Image Synthesis

为了学习序列数据上的长程交互,Transformer在各种各样的任务上不断地展示出最先进的结果.与卷积神经网络不同的是,它们不包含优先考虑局部交互的归纳偏差.这使得它们具有表达能力,但对于长序列,如高分辨率图像,在计算上也是不可行的.本文展示了如何将CNN的感应偏置的有效性与transformer的表达能力相结合,使其能够建模,从而合成高分辨率图像
复杂度不是建立在单个像素上,而是需要一种方法,使用学习表示的离散码本,使得任何图像x∈R^H×W×3^都可以由码本项的空间集合z~q~∈R^h×w×nz^表示,其中nz是中间变量的维数
学习高效codebook
首先学习一个由编码器E和解码器G组成的卷积模型,使得它们一起从一个学习的离散codebook $\mathcal{Z}={zk}{k=1}^K\subset\mathbb{R}^{n_z}$中学习用码表示图像,获得
利用编码( z = E(x)∈R^h×w×nz^ )和每个空间码( z~ij~^^^∈R^nz^ )在其最近的codebook项z~k~上的后续逐元素量化q ( · )得到zq
使用Transformer将图像表示为潜在图像成分上的分布
生成视觉丰富的codebook
$\lambda$设置取
∂~GL~ [ · ]表示其梯度也就是在decoder最后一层L的梯度
使用transformers学习图像生成
在E和G可用的情况下可以根据它们编码的codebook索引来表示图像.图像x的量化编码是由z~q~ = q ( E ( x ) )∈R^h×w×nz^给出的,并且等价于一个序列从码本中得到的索引$s\in{0,\ldots,|\mathcal{Z}|-1}^{n\times w}$,它是由码本Z中的索引替换每个码得到的
通过将序列s的索引映射回其对应的码本项,z~q~ = ( z~sij~ )很容易恢复并解码成图像(x = G(z~q~ ) ).
在s中选择一些指标的排序后图像生成可以表示为自回归下一指标预测:给定指标s < i,转换器学习预测可能的下一指标的分布,即p(s~i~ | s < i)
约束的图像生成
在许多图像合成任务中,用户需要通过提供额外的信息来控制生成过程,从而合成一个示例.这种信息,我们称之为c,可以是描述整体图像类别的单个标签,也可以是另一幅图像本身.然后任务是学习给定这个信息c的序列的似然
生成高分辨率图片
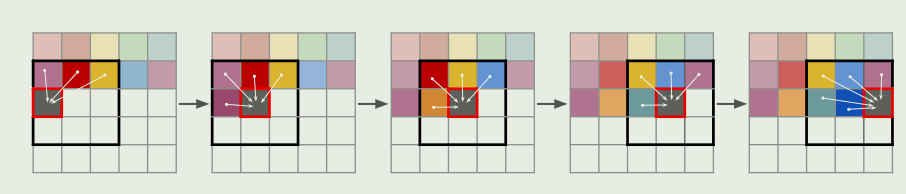
为了生成百万像素级别的图像,我们必须在训练过程中对图像块和裁剪图像进行处理,将s的长度限制在最大可行尺寸.
为了对图像进行采样使用滑动窗口方式的transformers
UDA
Unsupervised Domain Adaptation by Backpropagation
1409.7495] Unsupervised Domain Adaptation by Backpropagation (arxiv.org)
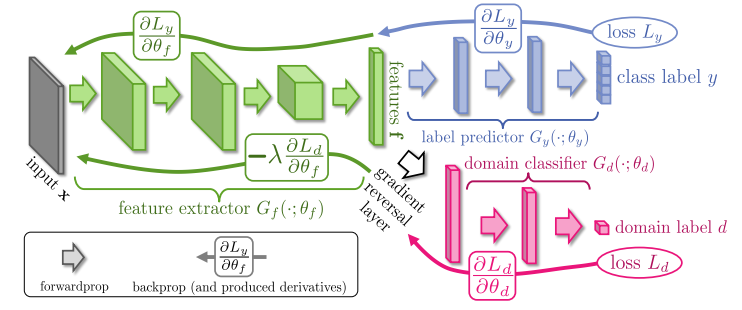
第一篇提出GRL用于域适应的文章
Domain Adaptive Object Detection for Autonomous Driving under Foggy Weather
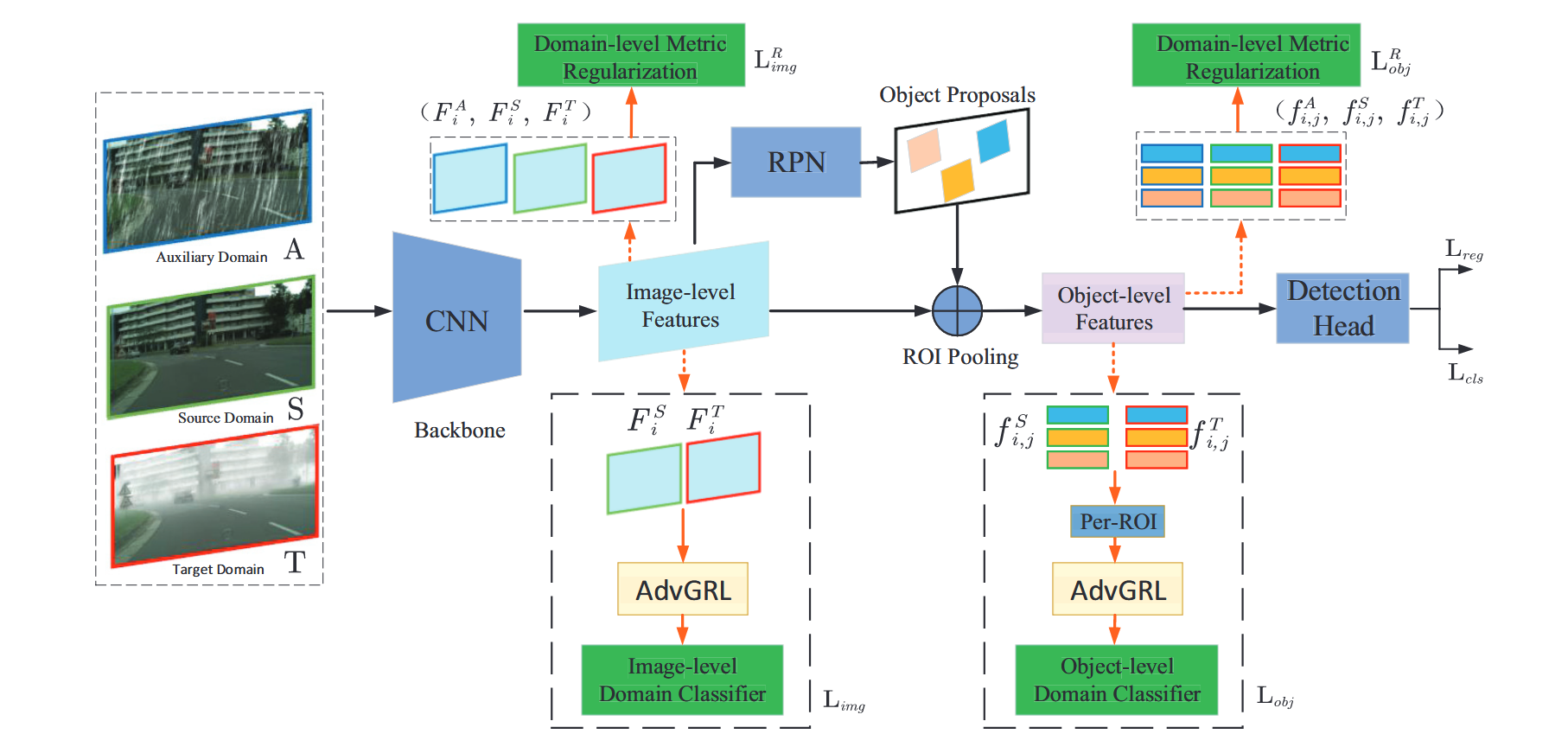
本文提出了一种新颖的雾天环境下面向自动驾驶的域自适应目标检测框架。
我们的方法同时利用图像级和对象级的自适应来减少图像风格和对象外观的领域差异。
为了进一步增强模型在挑战性样本下的能力,我们还提出了一个新的对抗梯度反转层,与领域自适应一起对困难样本进行对抗挖掘。
此外,我们提出通过数据增强生成一个辅助域,以执行一个新的域级度量正则化。在公开数据集上的实验结果表明了所提方法的有效性和准确性。
Image-level adaptation
域分类器只是一个具有两个卷积层的简单CNN,它将输出一个预测来识别特征域
Object-level Adaptation
除了不同领域的图像级全局差异外,不同领域的物体在外观、大小、颜色等方面也可能存在差异。将Faster R - CNN中ROI Pooling层之后的每个候选区域定义为一个潜在的对象。与图像级自适应模块类似,通过ROI池化获得目标级域表示后,我们实现了一个目标级域分类器来识别局部信息中的特征衍生。一个训练有素的对象级分类器,一个具有3个全连接层的神经网络,将有助于对齐对象级特征分布。
Multi-adversarial Faster-RCNN for Unrestricted Object Detection
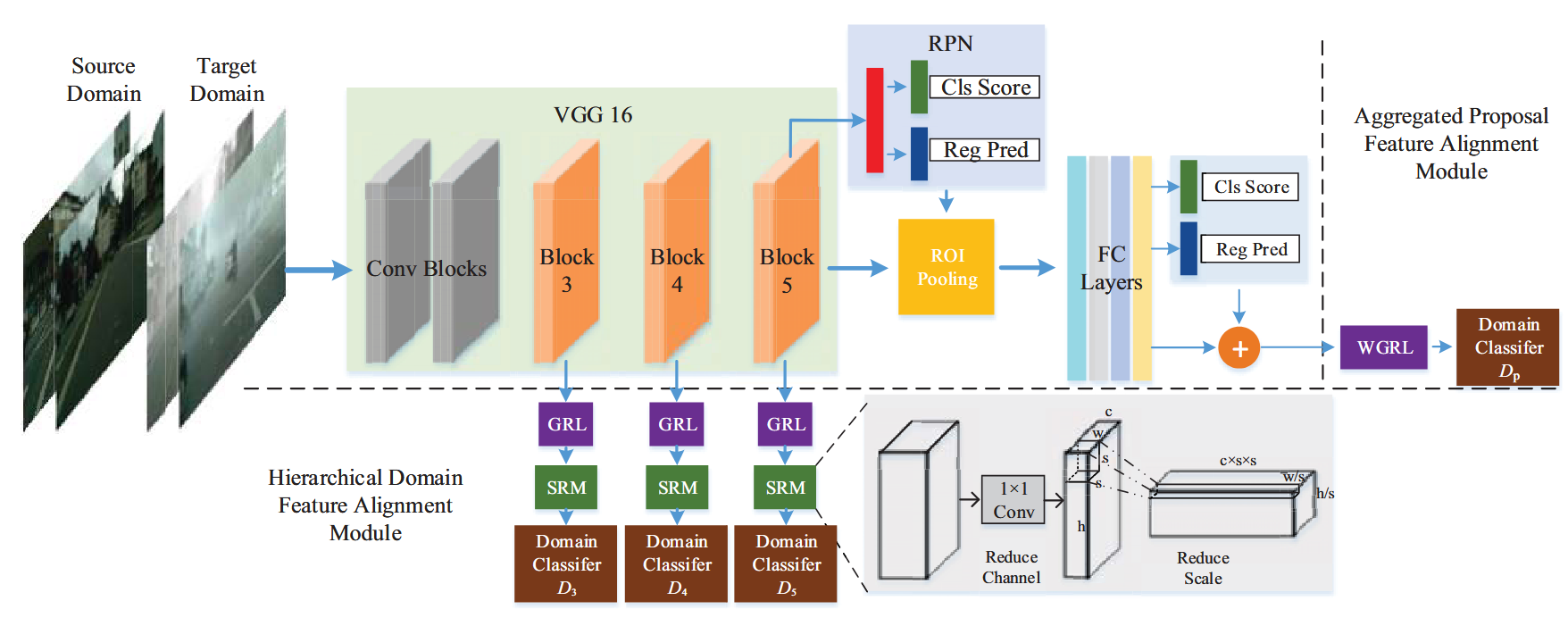
在多个模块上使用GRL与域判别器,相当于有个多尺度.
CDTrans: Cross-domain Transformer for Unsupervised Domain Adaptation
2109.06165] CDTrans: Cross-domain Transformer for Unsupervised Domain Adaptation (arxiv.org)
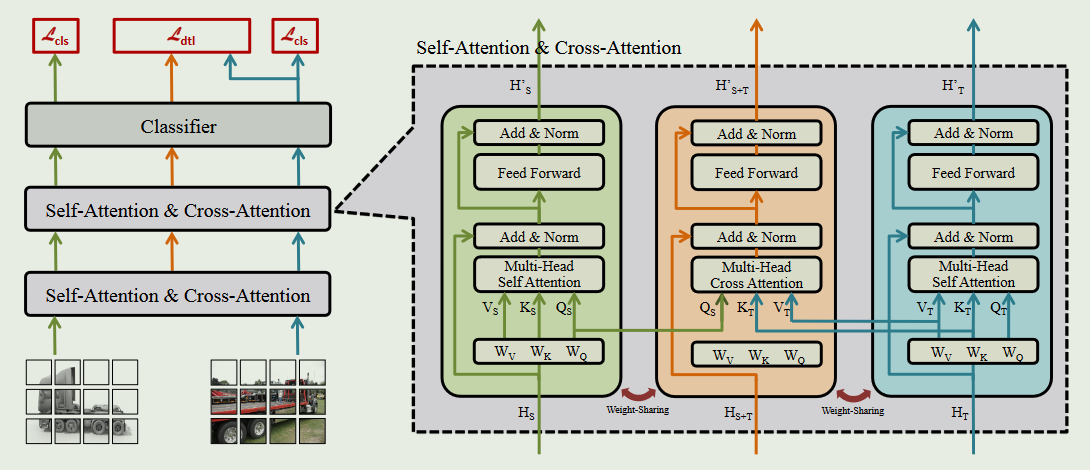
它由3个权重共享的transformer组成,通过使用two-way center-aware labeling method方法选择成对输入.
源分支( HS )和目标分支( HT )采用交叉熵,源-目标分支( HS + T )和HT之间采用蒸馏损失$L_{dtl}=\sum_kq_k\log p_k$
针对来自不同域的特征使用权重相同的网络,将得到的结果使用交叉熵作为损失,相比于之前使用GRL的方法,这里更偏向使用一种指标作为损失优化网络
TVT: Transferable Vision Transformer for Unsupervised Domain Adaptation
TVT: Transferable Vision Transformer for Unsupervised Domain Adaptation (thecvf.com)
随着近年来Vision Transformer在视觉任务中的应用呈指数增长,然而,ViT在适应跨领域知识方面的能力在文献中仍未被探索.为了填补这一空白,本文首先全面考察了ViT在多种域适应任务上的表现.令人惊讶的是,ViT表现出优越的泛化能力,而通过结合对抗自适应可以进一步提高性能
尽管如此,直接使用基于CNNs的适应策略并没有利用ViT在知识转移中发挥重要作用的内在优势(例如,注意力机制和序列图像表示).为了弥补这一缺陷,我们提出了一个统一的框架,即可迁移视觉转换器( Transferable Vision Transformer,TVT ),以充分利用视觉里程计的可迁移性进行领域自适应.
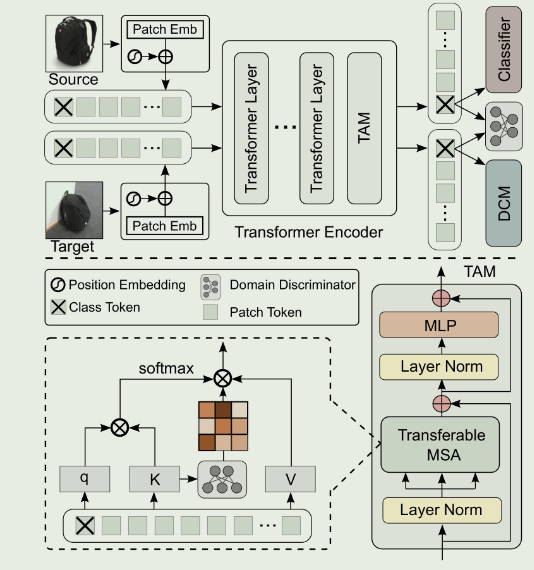
与ViT一样,源图像和目标图像都被分割成固定大小的图像块,然后线性映射并嵌入位置信息.生成的补丁送入变压器编码器,最后一层由可转让性适配模块( TAM )替换.特征学习、对抗域适应和分类由ViT-akin骨干、两个域判别器(在path-level和global-level上)、判别聚类模块( Discriminative Clustering Module,DCM )和基于MLP的分类器完成
在transformer模型中插入了一个Transferable MSA模块(TMA)用于增强
在使用transformer时,考虑patch-level,global-level,spatial-level等等不同尺度上使用domain discriminator
除了进行域适应之外,还需要考虑本身特征对于检测的重要性
针对利用无标签目标数据学习概率判别分类器的挑战性问题,需要最小化目标域上的期望分类误差。然而,如果不引入目标域的语义约束,通过TAM强迫两个域相似的跨域特征对齐可能会破坏学习到的表示的判别信息。
Safe Self-Refinement for Transformer-based Domain Adaptation
VQ-VAE
lucidrains/vector-quantize-pytorch: Vector (and Scalar) Quantization, in Pytorch非常不错,此外这个作者还有一个实现各种vit的仓库lucidrains/vit-pytorch
Neural Discrete Representation Learning
Generating Diverse High-Fidelity Images with VQ-VAE-2

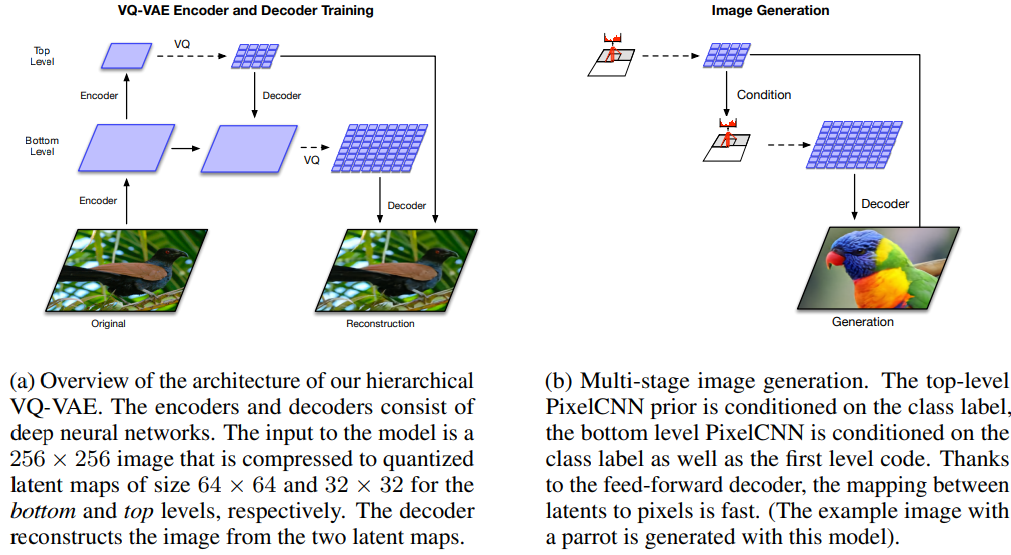
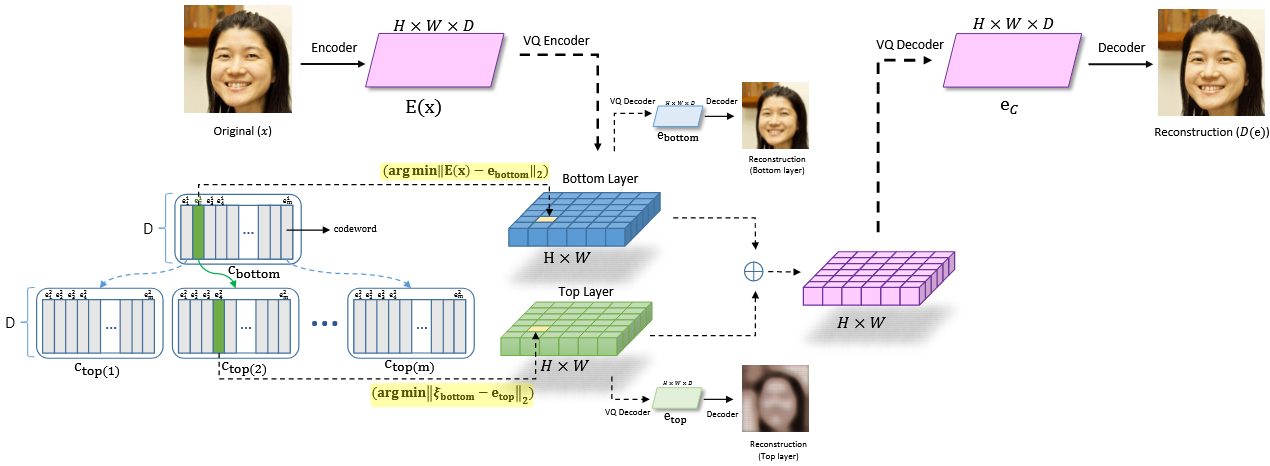
底层和顶层分别被压缩为大小为64 × 64和32 × 32的quantized latent图,相当于使用了不同尺度、多尺度的codelayer/codebook,再将不同尺度的codelayer通过多个decoder. 令分辨率最大的为bottom layer,不断降低分辨率并设置与encoder-decoder对数目对应的codelayer,得到多个H*W*1的量化结果,将上一层得到的量化结果通过decoder解码后的结果并上采样(增加特征图大小)与当前层量化的结果concat通过当前的decoder得到结果. 最后结果取bottom layer也就是分辨率最高那一层的解码结果,相当于实现了pyramid的多尺度,更新codelayer权重有两种方式,一种是使用stop gradient,在代码层面上使用.detach(),另一种通过ema.
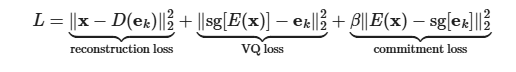
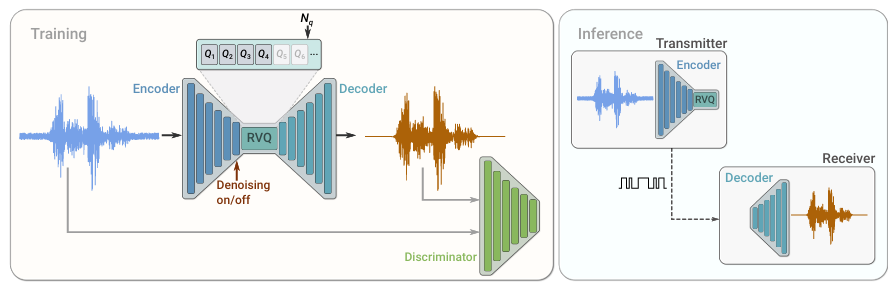
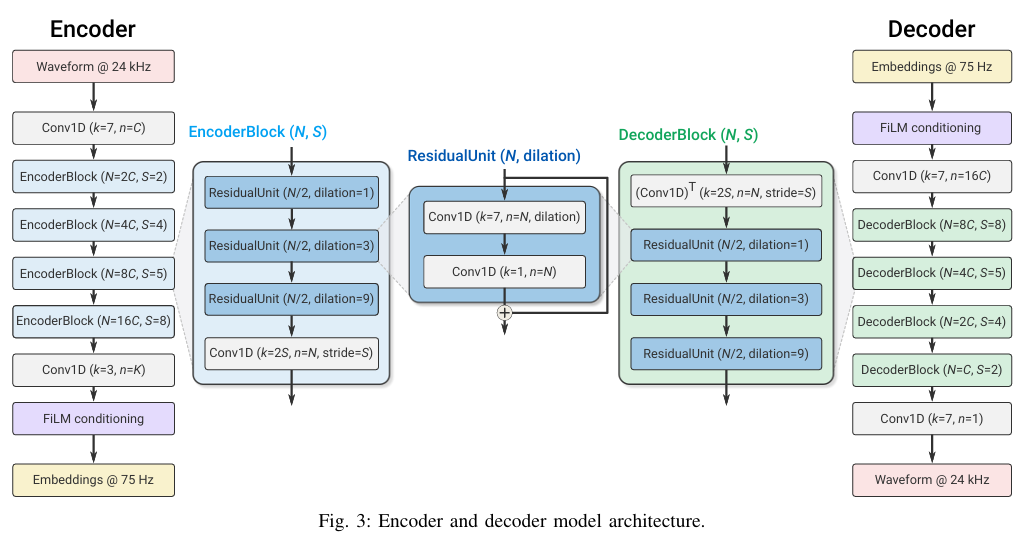
SoundStream: An End-to-End Neural Audio Codec
Hierarchical Residual Learning Based Vector Quantized Variational Autoencoder for Image Reconstruction and Generation
Addressing Representation Collapse in Vector Quantized Models with One Linear Layer

