既text2img和大语言模型之后的热点,AI Agent和RAG,简单来说在既有的多模态大模型基础上打造应用,比如利用多个智能体以及外部数据进行搜索. 目前来看还是有一些发展潜力,这方面的资料多见于Hugging Face,LangChain,llama index等等
过去一段时间涌现了一大堆大模型,参数量多达几十B,并且这些模型在许多benchmark上都似乎达到了很高的水平(甚至最近OpenAI的o3达到超越普通人的水平,AGI达没达到不知道,Hype是足够了). 普通人想免费下载的大模型就是贴心的llama了,可以在llama上进行微调等操作. 此外文生图等模型既Stable Diffusion v3.5之后,出走后的人员打造FLUX.
种种迹象表明,Foundation Model的发展已经超出普通人能玩的范围了,因为背后耗费这成千上万张显卡以及大量人员精心修剪后的数据。而如何实现长期盈利才是关键,OpenAI早已打出了名声,作为行业标杆,不少人会去订阅ChatGPT Plus,即使再贵. 但其他公式就会遭殃了,毕竟一个人使用一到两种类似的AI服务已经足够,于是形成了类似冠军争夺,专业做AI的,只有前几家才能生成. 大厂可以背靠大量数据集和人力做模型以及服务,中小公司相对更困难. 而普通人貌似要么花钱使用Open(并不Open)AI更高质量服务,要么用开源的模型,事实上,在这个开源领域正在或者应该,在开发者之间流行,作为辅助工具抑或创造性的图片生成,即使无法盈利,但也逐渐变成计算器一样的工具成为普遍现象. 其中的一些有趣技术就包括T2I文生图以及相关的LoRA,ControlNet. 而多模态大语言模型就是RAG和AI Agent了.
目前国内大中厂以及个人开发者都在这些方向不断努力

For any API provider
因为目前有许多大模型供应商,比如grok,gemini,openai,它们提供不同的大模型和接口. 如果为多个不同供应商分别写然后能够统一进行调用就更好了. HuggingFace提供了相关方法1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25import os
from openai import OpenAI
openai_role_conversions = {
MessageRole.TOOL_RESPONSE: MessageRole.USER,
}
class OpenAIEngine:
def __init__(self, model_name="gpt-4o"):
self.model_name = model_name
self.client = OpenAI(
api_key=os.getenv("OPENAI_API_KEY"),
)
def __call__(self, messages, stop_sequences=[]):
messages = get_clean_message_list(messages, role_conversions=openai_role_conversions)
response = self.client.chat.completions.create(
model=self.model_name,
messages=messages,
stop=stop_sequences,
temperature=0.5,
)
return response.choices[0].message.content
核心是构建一个llm_engine然后通过ReactCodeAgent或者其他Agent调用1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45from anthropic import Anthropic, AnthropicBedrock
# Cf this page for using Anthropic from Bedrock: https://docs.anthropic.com/en/api/claude-on-amazon-bedrock
class AnthropicEngine:
def __init__(self, model_name="claude-3-5-sonnet-20240620", use_bedrock=False):
self.model_name = model_name
if use_bedrock:
self.model_name = "anthropic.claude-3-5-sonnet-20240620-v1:0"
self.client = AnthropicBedrock(
aws_access_key=os.getenv("AWS_BEDROCK_ID"),
aws_secret_key=os.getenv("AWS_BEDROCK_KEY"),
aws_region="us-east-1",
)
else:
self.client = Anthropic(
api_key=os.getenv("ANTHROPIC_API_KEY"),
)
def __call__(self, messages, stop_sequences=[]):
messages = get_clean_message_list(messages, role_conversions=openai_role_conversions)
index_system_message, system_prompt = None, None
for index, message in enumerate(messages):
if message["role"] == MessageRole.SYSTEM:
index_system_message = index
system_prompt = message["content"]
if system_prompt is None:
raise Exception("No system prompt found!")
filtered_messages = [message for i, message in enumerate(messages) if i != index_system_message]
if len(filtered_messages) == 0:
print("Error, no user message:", messages)
assert False
response = self.client.messages.create(
model=self.model_name,
system=system_prompt,
messages=filtered_messages,
stop_sequences=stop_sequences,
temperature=0.5,
max_tokens=2000,
)
full_response_text = ""
for content_block in response.content:
if content_block.type == "text":
full_response_text += content_block.text
return full_response_text1
agent = ReactCodeAgent(tools=[], llm_engine=llm_engine)
Intro to RAG
RAG是一种流行的方法,用于解决LLM由于所述内容不在其训练数据中而无法意识到特定内容的问题,或者即使以前看到过该内容也会产生幻觉。这些特定内容可能是专有的、敏感的,或者是最近的和经常更新的。
如果数据是静态的,并且不定期更改,则可以考虑对大型模型进行微调。然而,在许多情况下,微调可能是昂贵的,并且,当重复进行时(例如,为了解决数据漂移),会导致“模型转移”。这是指模型的行为以一种没有改变的方式发生变化
RAG(检索增强生成)不需要模型微调。相反,RAG通过向LLM提供从相关数据中检索的附加上下文来工作,以便它可以生成更明智的响应。

这类应用可以非常方便写文档、报告的人,因为时常会有比较新的消息而大模型训练资料中没有,这个时候可以让大模型主动调用外部工具(比如搜索引擎),或者主动给它额外的工具从而补充大模型的能力.
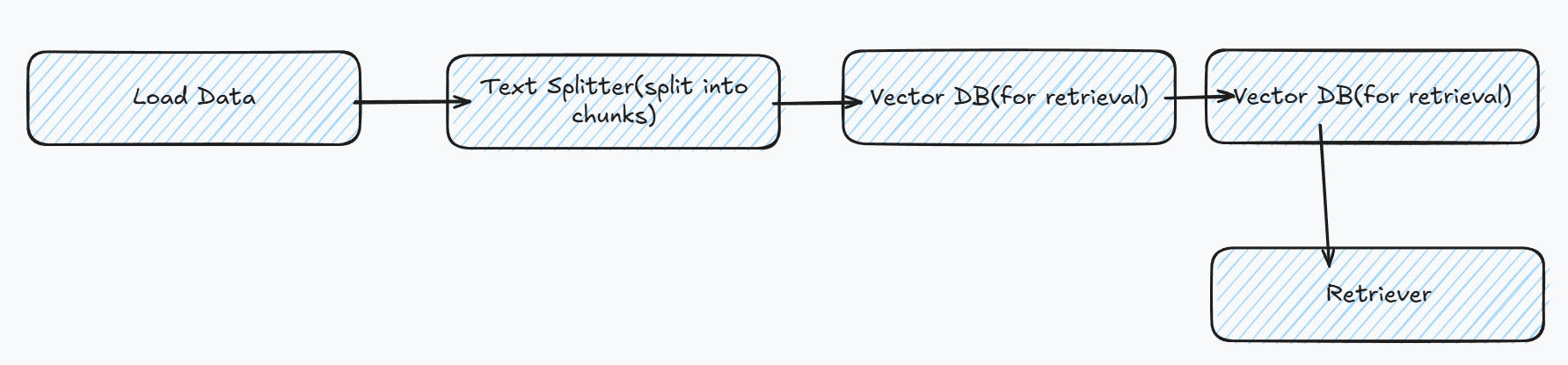
简易的RAG工作流
加载数据
1 | from getpass import getpass |
使用github加载数据,将数据分块加载,最常见和直接的分块方法是定义一个固定大小的块,以及它们之间是否应该有任何重叠。在块之间保持一些重叠可以让我们在块之间保留一些语义上下文。一般文本的推荐拆分器是RecursiveCharacterTextSplitter1
2
3from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(chunk_size=512, chunk_overlap=30)
chunked_docs = splitter.split_documents(docs)
创建embedding和retriever
需要将文件转为特征,为了创建文档块嵌入,这里使用HuggingFaceEmbeddings和BAAI/ big -base-en-v1.5嵌入模型。Hub上还有许多其他的嵌入模型MTEB Leaderboard - a Hugging Face Space by mteb,使用FAISS作为嵌入特征搜索库,相当于创建一个数据库,其中数据就是嵌入后的特征1
2
3
4from langchain.vectorstores import FAISS
from langchain.embeddings import HuggingFaceEmbeddings
db = FAISS.from_documents(chunked_docs, HuggingFaceEmbeddings(model_name="BAAI/bge-base-en-v1.5"))
设置检索方式,近邻搜索,返回最高的4个结果.1
retriever = db.as_retriever(search_type="similarity", search_kwargs={"k": 4})
LLM
刚才使用了嵌入模型,现在使用对输入prompt以及回复的llm,相关榜单Open LLM Leaderboard - a Hugging Face Space by open-llm-leaderboard.1
2
3
4
5
6
7
8
9
10
11import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
model_name = "HuggingFaceH4/zephyr-7b-beta"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True, bnb_4bit_use_double_quant=True, bnb_4bit_quant_type="nf4", bnb_4bit_compute_dtype=torch.bfloat16
)
model = AutoModelForCausalLM.from_pretrained(model_name, quantization_config=bnb_config)
tokenizer = AutoTokenizer.from_pretrained(model_name)
此外对模型做了量化减小体积
搭建LLM链
设置pipeline,1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38from langchain.llms import HuggingFacePipeline
from langchain.prompts import PromptTemplate
from transformers import pipeline
from langchain_core.output_parsers import StrOutputParser
text_generation_pipeline = pipeline(
model=model,
tokenizer=tokenizer,
task="text-generation",
temperature=0.2,
do_sample=True,
repetition_penalty=1.1,
return_full_text=True,
max_new_tokens=400,
)
llm = HuggingFacePipeline(pipeline=text_generation_pipeline)
prompt_template = """
<|system|>
Answer the question based on your knowledge. Use the following context to help:
{context}
</s>
<|user|>
{question}
</s>
<|assistant|>
"""
prompt = PromptTemplate(
input_variables=["context", "question"],
template=prompt_template,
)
llm_chain = prompt | llm | StrOutputParser()
结合llm_chain搭配retriver1
2
3
4
5from langchain_core.runnables import RunnablePassthrough
retriever = db.as_retriever()
rag_chain = {"context": retriever, "question": RunnablePassthrough()} | llm_chain
比较结果
在没有rag下1
2question = "How do you combine multiple adapters?"
llm_chain.invoke({"context": "", "question": question})
在有rag下1
rag_chain.invoke(question)
Agent with tool-calling
大模型搭配tool calling(比如调用计算器,编程语言解析器,浏览器搜索等)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19from transformers import load_tool, ReactCodeAgent, HfApiEngine
# Import tool from Hub
image_generation_tool = load_tool("m-ric/text-to-image", cache=False)
# Import tool from LangChain
from transformers.agents.search import DuckDuckGoSearchTool
search_tool = DuckDuckGoSearchTool()
llm_engine = HfApiEngine("Qwen/Qwen2.5-72B-Instruct")
# Initialize the agent with both tools
agent = ReactCodeAgent(tools=[image_generation_tool, search_tool], llm_engine=llm_engine)
# Run it!
result = agent.run(
"Generate me a photo of the car that James bond drove in the latest movie.",
)
result
使用Qwen-2.5大模型,搭配文生图和搜索工具,相当于结合了多个模型和外部工具,让原本单一的模型具备多种功能.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77import datasets
from langchain.docstore.document import Document
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain_community.embeddings import HuggingFaceEmbeddings
knowledge_base = datasets.load_dataset("m-ric/huggingface_doc", split="train")
source_docs = [
Document(page_content=doc["text"], metadata={"source": doc["source"].split("/")[1]}) for doc in knowledge_base
]
docs_processed = RecursiveCharacterTextSplitter(chunk_size=500).split_documents(source_docs)[:1000]
embedding_model = HuggingFaceEmbeddings(model_name="thenlper/gte-small")
vectordb = FAISS.from_documents(documents=docs_processed, embedding=embedding_model)
import json
from transformers.agents import Tool
from langchain_core.vectorstores import VectorStore
class RetrieverTool(Tool):
name = "retriever"
description = (
"Retrieves some documents from the knowledge base that have the closest embeddings to the input query."
)
inputs = {
"query": {
"type": "string",
"description": "The query to perform. This should be semantically close to your target documents. Use the affirmative form rather than a question.",
},
"source": {"type": "string", "description": ""},
"number_of_documents": {
"type": "string",
"description": "the number of documents to retrieve. Stay under 10 to avoid drowning in docs",
},
}
output_type = "string"
def __init__(self, vectordb: VectorStore, all_sources: str, **kwargs):
super().__init__(**kwargs)
self.vectordb = vectordb
self.inputs["source"]["description"] = (
f"The source of the documents to search, as a str representation of a list. Possible values in the list are: {all_sources}. If this argument is not provided, all sources will be searched.".replace(
"'", "`"
)
)
def forward(self, query: str, source: str = None, number_of_documents=7) -> str:
assert isinstance(query, str), "Your search query must be a string"
number_of_documents = int(number_of_documents)
if source:
if isinstance(source, str) and "[" not in str(source): # if the source is not representing a list
source = [source]
source = json.loads(str(source).replace("'", '"'))
docs = self.vectordb.similarity_search(
query,
filter=({"source": source} if source else None),
k=number_of_documents,
)
if len(docs) == 0:
return "No documents found with this filtering. Try removing the source filter."
return "Retrieved documents:\n\n" + "\n===Document===\n".join([doc.page_content for doc in docs])
from transformers.agents import HfApiEngine, ReactJsonAgent
llm_engine = HfApiEngine("Qwen/Qwen2.5-72B-Instruct")
retriever_tool = RetrieverTool(vectordb=vectordb, all_sources=all_sources)
agent = ReactJsonAgent(tools=[retriever_tool], llm_engine=llm_engine, verbose=0)
agent_output = agent.run("Please show me a LORA finetuning script")
print("Final output:")
print(agent_output)
通过RAG以及迭代的询问提升回答质量,首先还是加载数据,分块,编码为向量加载到一个向量数据库.
huggingface的transformers库自带调用解释器1
2
3
4
5
6
7
8
9
10
11
12
13
14
15from transformers import ReactCodeAgent
agent = ReactCodeAgent(tools=[], llm_engine=HfApiEngine("Qwen/Qwen2.5-72B-Instruct"))
code = """
list=[0, 1, 2]
for i in range(4):
print(list(i))
"""
final_answer = agent.run(
"I have some code that creates a bug: please debug it, then run it to make sure it works and return the final code",
code=code,
)
结合OpenAI的接口制作agent.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43import os
from openai import OpenAI
from transformers.agents.llm_engine import MessageRole, get_clean_message_list
openai_role_conversions = {
MessageRole.TOOL_RESPONSE: "user",
}
class OpenAIEngine:
def __init__(self, model_name="gpt-4o-2024-05-13"):
self.model_name = model_name
self.client = OpenAI(
api_key=os.getenv("OPENAI_API_KEY"),
)
def __call__(self, messages, stop_sequences=[]):
# Get clean message list
messages = get_clean_message_list(messages, role_conversions=openai_role_conversions)
# Get LLM output
response = self.client.chat.completions.create(
model=self.model_name,
messages=messages,
stop=stop_sequences,
)
return response.choices[0].message.content
openai_engine = OpenAIEngine()
agent = ReactCodeAgent(llm_engine=openai_engine, tools=[])
code = """
list=[0, 1, 2]
for i in range(4):
print(list(i))
"""
final_answer = agent.run(
"I have some code that creates a bug: please debug it and return the final code",
code=code,
)
Agentic RAG
单纯的RAG也有局限性,最重要的是以下两点:
- 它只执行一个检索步骤:如果结果不好,那么生成的结果也会不好。
- 语义相似度是以用户查询作为参考来计算的,这可能是次优的:例如,用户查询通常是一个问题,而包含真实答案的文档就是确定句式,因此与疑问形式的其他源文档相比,其相似度得分将被降低,从而导致丢失相关信息的风险。
但是可以通过创建一个RAG代理来缓解这些问题:
- 不直接使用用户的问题作为查询,agent将结合用户输入
- agent可以生成片段以便重新检索
1 | import datasets |

Use local data
Building RAG with Custom Unstructured Data
许多重要的知识都以各种格式存储,如pdf、电子邮件、Markdown文件、PowerPoint演示文稿、HTML页面、Word文档等。
如何预处理所有这些数据,因为这些文件的格式各不相同,要么搭配langchain等工具分别进行解析,要么直接使用现有工具库Introduction | 🦜️🔗 LangChain,Unstructured - Unstructured
本地推理应用与库
目前有许多大模型本地推理应用,比如Ollama,LMStudio,GPT4All等等,而它们背后的推理库也有很多,比如llama.cpp,ggml. 通过利用Ollama等工具搭配LangChain可以更高效及其定制化属于自己的LLM应用.
Ollama本身提供了API服务,通过这个服务与用户本地文件和prompt,可以搭建一个小应用1
2
3
4
5
6curl http://localhost:11434/api/chat -d '{
"model": "llama3.2",
"messages": [
{ "role": "user", "content": "why is the sky blue?" }
]
}'
注意这个返回值会是一个JSON流.具体来说, 通过ChatOllama | 🦜️🔗 LangChain获得更好的处理,再利用FastAPI或Sanic搭建web用户界面,结合上传用户文件等搭建一个应用.1
2
3
4from langchain_ollama import OllamaLLM
model = OllamaLLM(model="llama3")
model.invoke("Come up with 10 names for a song about parrots")

