这半年要论AI哪些方向最火,那关键词必然包括多模态,AI Agent,RAG等等(事实上已经火了一轮开始冷饭热炒了),一些做之前基础大模型的公司基本开始转向做应用甚至其他方向了. 这里整理一些关于AI Agents的知识和相关基础框架,并结合多智能体协同感知看看有哪些能做的结合.
视觉语言模型
引用lilianweng的博客,视觉语言模型可以粗略分为四类:
1.将图像转换为可以与标记嵌入联合训练的嵌入特征(将图像转为可以与语言编码的特征一起训练的特征)
2.学习作为冻结、预训练语言模型前缀的良好图像嵌入(训练图像特征作为冻结的预训练语言模型的输入前缀)
3.使用专门设计的交叉注意力机制将视觉信息融合到语言模型的层中(使用交叉注意力融合视觉信息到大模型中)
4.无需训练即可结合视觉和语言模型
同时训练图像和文本
VisualBERT将文本输入和图像区域同时输入 BERT,使其能够通过自注意力机制发现图像和文本之间的内部对齐。
在训练时同时输入图像和文本,mask相关文本并加上图像的相关信息,任务是预测遮挡的信息同时提供两个标题区分哪个与图像相关.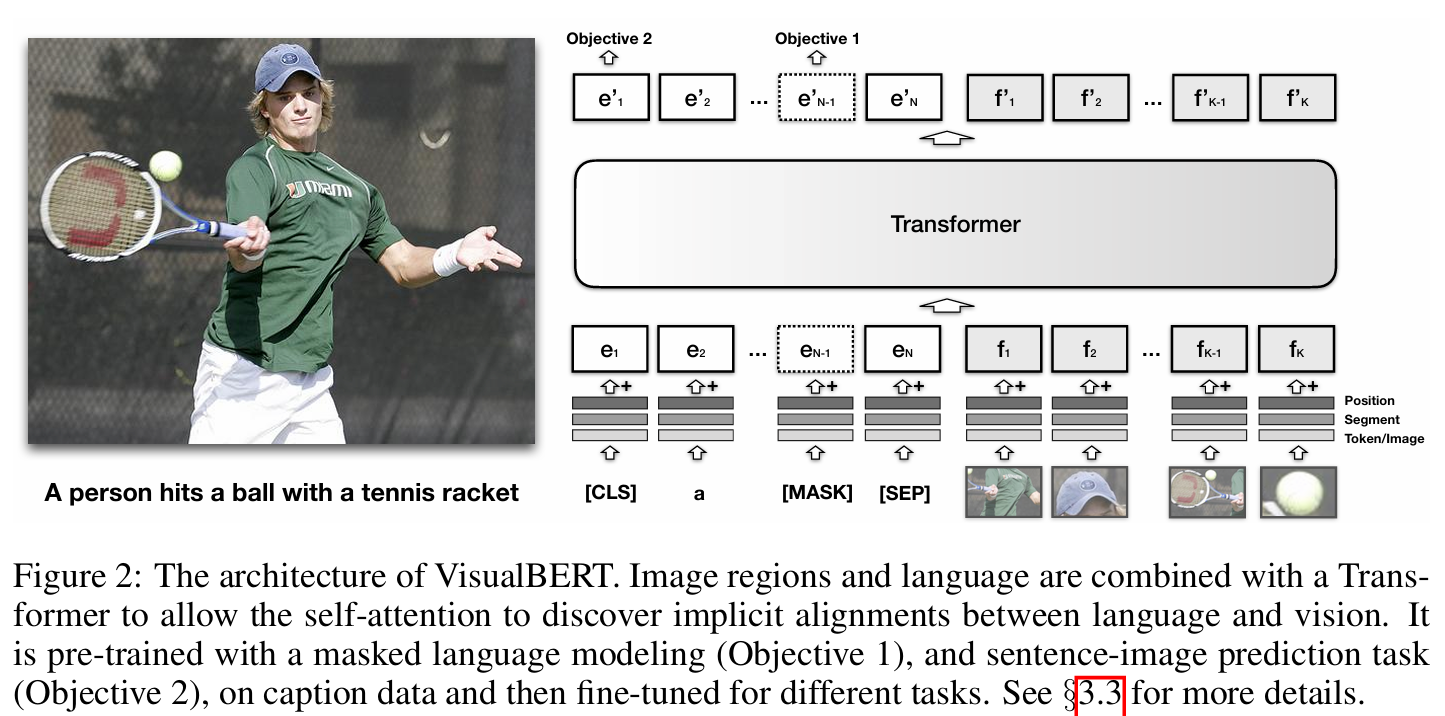
与 BERT 中的文本嵌入类似,VisualBERT 中的每个视觉嵌入也总结了三种类型的嵌入,即分词特征、分割嵌入和位置嵌入,具体来说:
一种通过卷积神经网络计算出的图像边界区域的视觉特征向量
一个表示嵌入是否用于视觉而非文本的段嵌入
一种用于对齐边界区域顺序的位置嵌入
SimVLM是一种简单的前缀语言模型,其中前缀序列的处理方式类似于 BERT 的双向注意力,但主要的文本输入序列只有因果注意力类似于 GPT。图像被编码为前缀标记,以便模型可以完全消耗视觉信息,然后以自回归方式生成相关文本。
SimVLM 将图像分割成更小的块,形成一个平铺的 1D 块序列。他们使用由 ResNet 的前 3 个块组成的卷积阶段来提取上下文化的块,这种设置被发现比简单的线性投影效果更好。
这种方法的学习目标更像是通过视觉信息前缀,通过transformer结构进行自回归学习,这也是它与前者较大的差距. 因此通过图像编码器编码图像特征然后通过掩码语言建模(Masked Language Modeling)(类似完形填空)或自回归学习训练原本的大语言模型使其拥有视觉能力.
学习图像嵌入
如果不想在适应处理视觉信号时更改语言模型参数,那么可以学习一个与语言模型兼容的图像嵌入空间。
受前缀或提示调整的启发,Frozen和 ClipCap仅在训练期间更新视觉模块的参数,以生成可以与预训练的冻结语言模型一起工作的图像嵌入。两者都使用对齐的图像标题数据集进行训练,以根据图像和先前的文本标记生成下一个文本标记。通过冻结 LM 参数,保留了强大的语言能力。此外,尽管这种设置是在有限的图像标题数据上训练的,但它们在测试时也可以依赖语言模型的知识库。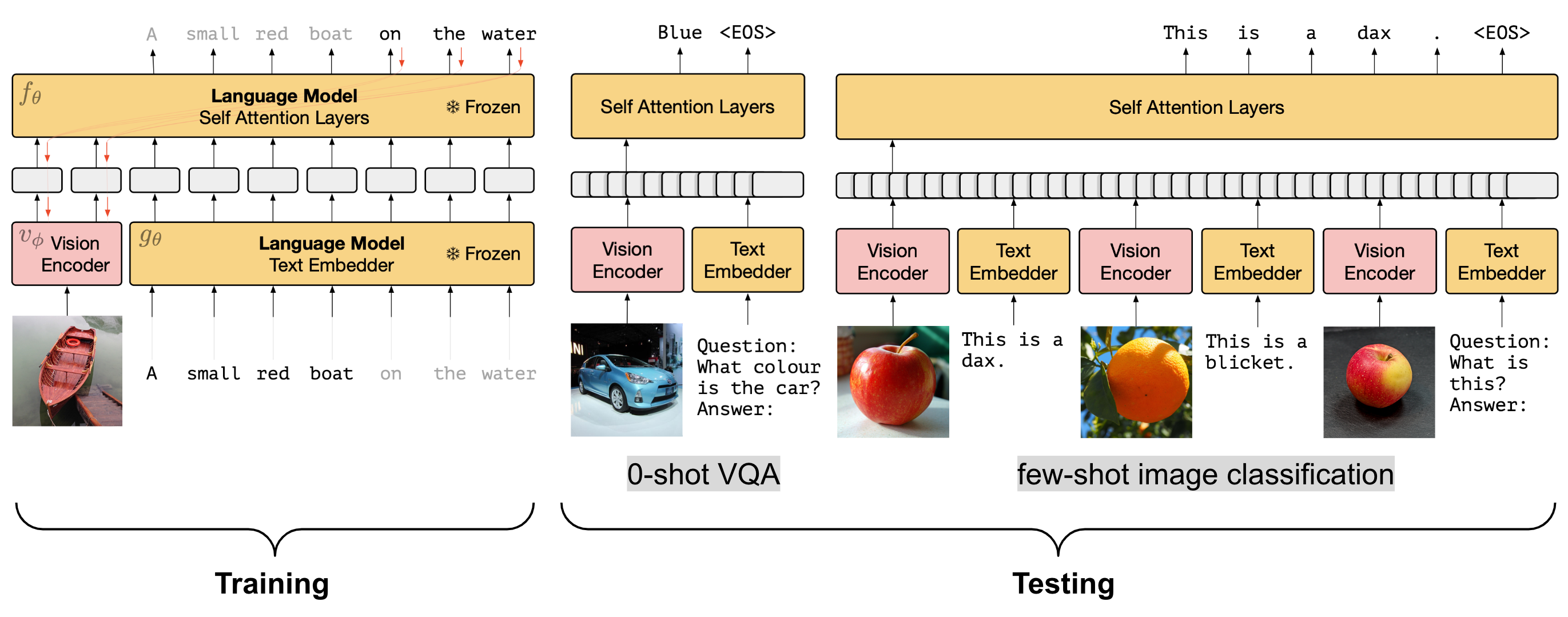
从框架图看来就是只是用了一个视觉编码器将得到的embedding与预训练固定参数的text encoder和大模型同时训练更新视觉编码器
ClipCap 依靠 CLIP 进行视觉编码,但它需要由光映射网络处理,以便将图像嵌入向量转换为与预训练 LM 相同的语义空间。该网络将 CLIP 嵌入向量映射到一系列嵌入向量中,每个向量与 GPT2 中的单词嵌入具有相同的维度。增加前缀大小有助于提高性能。CLIP 视觉编码器和 LM 在训练期间都会被冻结,并且只学习映射网络。
ClipCap学习的是一个映射网络,它同时利用了预训练的CLIP和大模型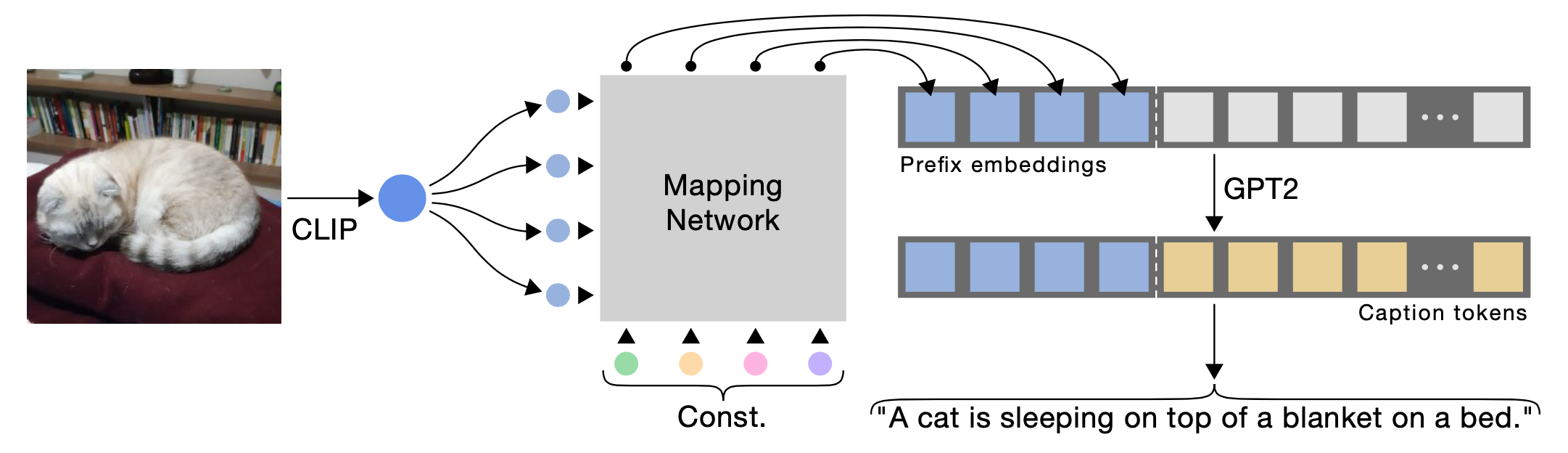
交叉注意力混合视觉和文本信息
VisualGPT采用self-resurrecting的编码器-解码器注意力机制,用少量的域内图像文本数据快速适应预训练的LM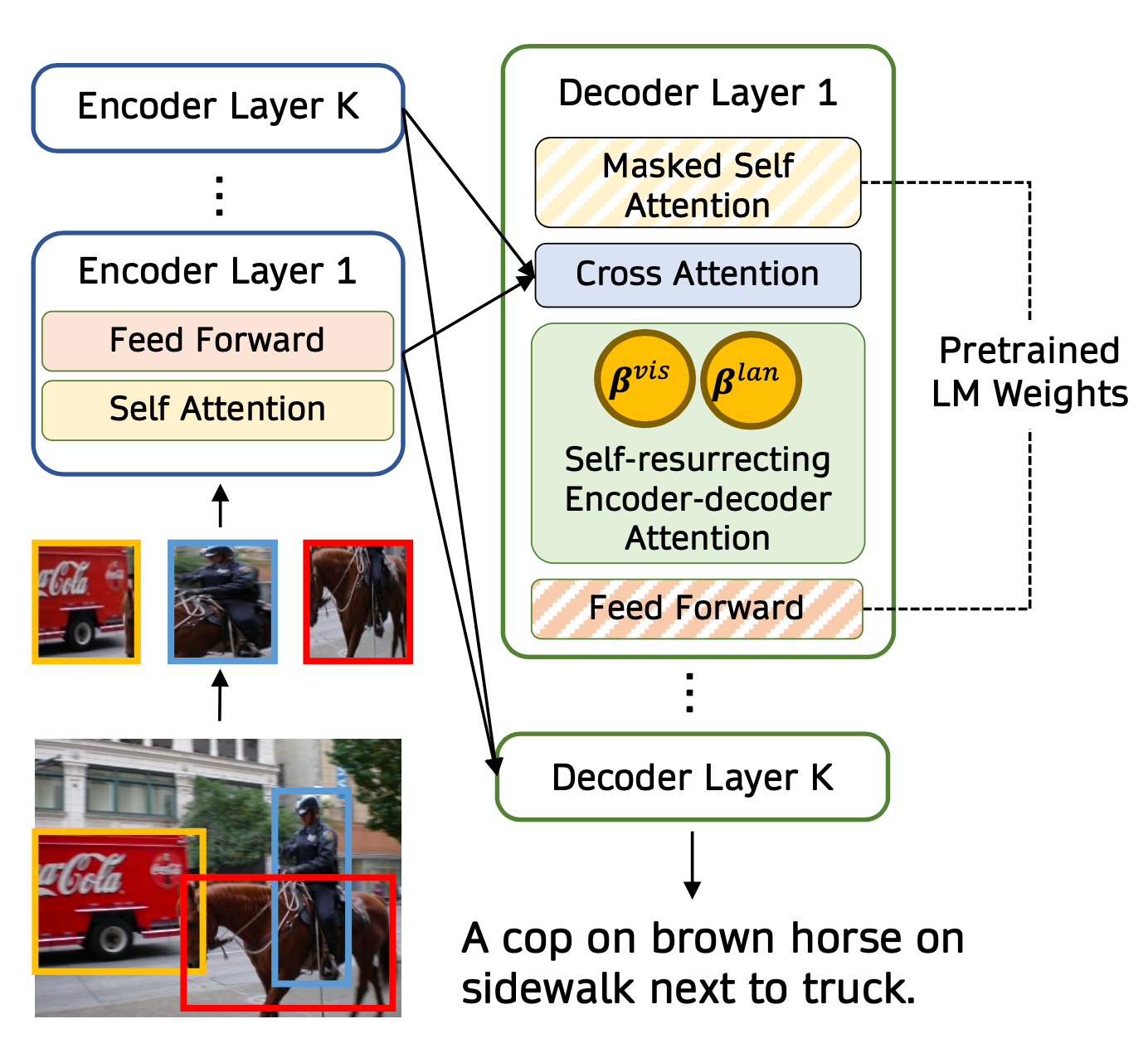
设I为视觉编码器的输入,H为LM解码器的隐藏状态. 引入激活单元通过两个互补门来控制预训练语言信息和视觉组件之间混合.
每层decoder通过门控制单元混合不同的输入.
VC-GPT 将预训练的视觉转换器(CLIP-ViT)作为视觉编码器和预训练的 LM 作为语言解码器相结合。CLIP-ViT 将一系列图像块作为输入和输出,并输出每个块的表示。为避免灾难性的遗忘,VC-GPT 不是将视觉信息直接注入 GPT2,而是在视觉编码器和语言解码器的输出之上引入了额外的交叉注意力层。然后, 一个自集成 模块线性组合单模型语言解码器 logits h^G^和跨模型视觉语言融合模块 logitsh^fuse^ 自集成模块对于性能很重要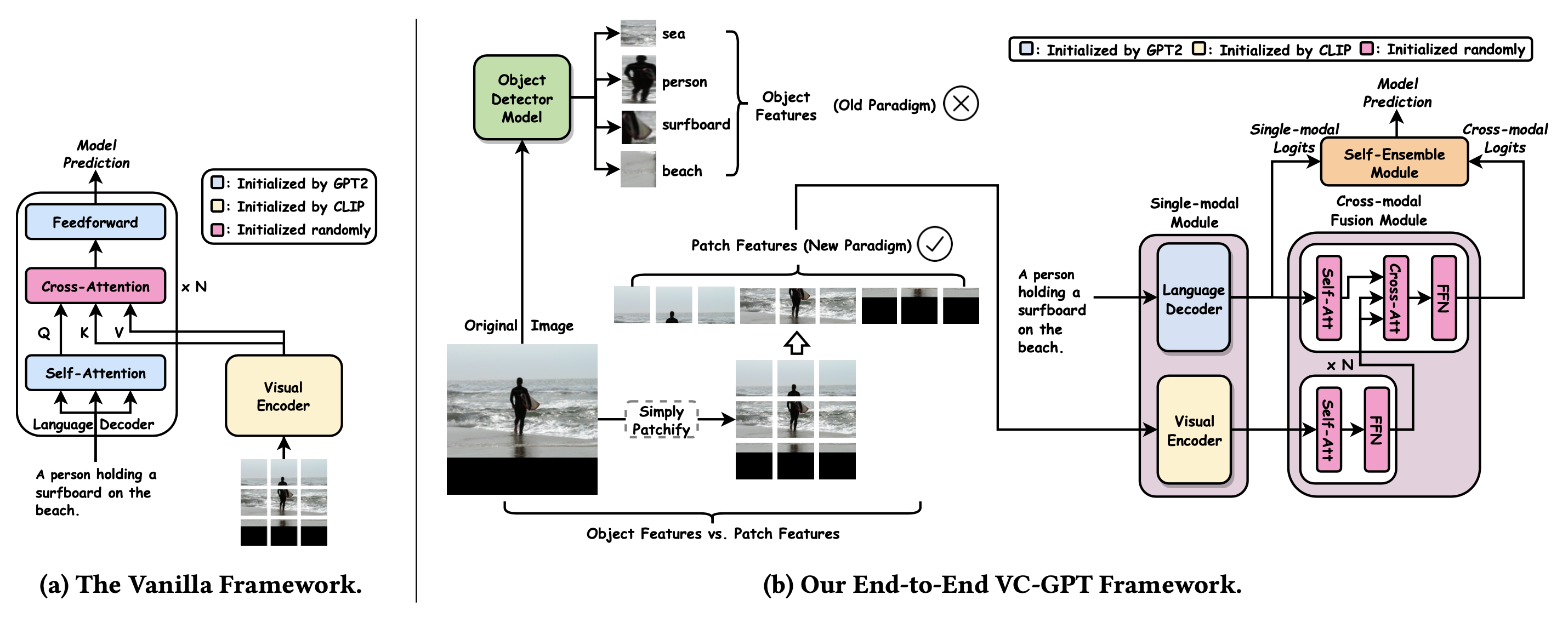
MERLOT接受了 600 万个 YouTube 视频的训练,并转录了语音 (YT-Temporal-180M),以学习空间(帧级)和时间(视频级)目标,并在微调时在 VQA 和视觉推理任务上表现出强大的表现。每个视频被拆分为多个片段,每个片段从中间的图像帧和关联的单词。图像由学习的图像编码器编码,单词使用学习的嵌入进行编码。然后,两者在一个联合的vision-language transformer中一起编码。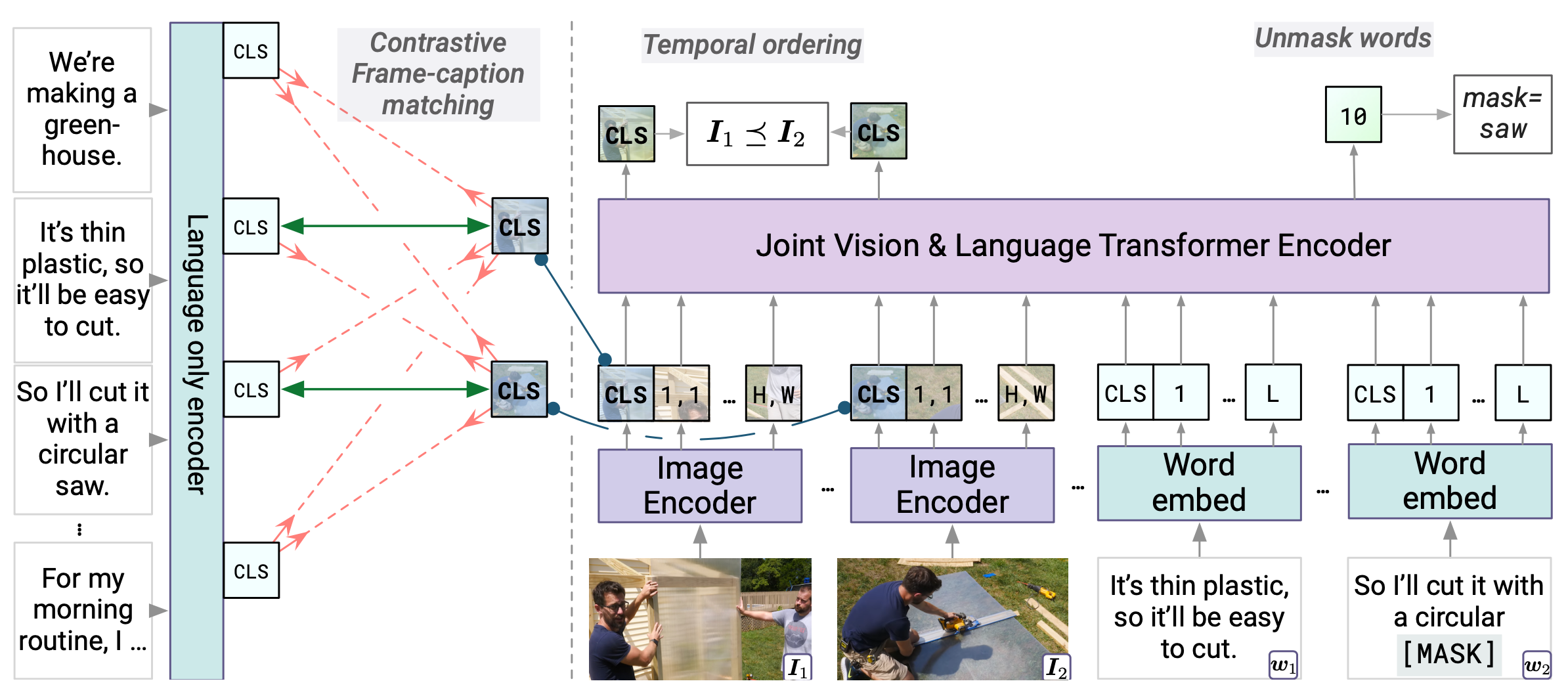
- 遮罩语言建模(MLM),因为在视频中有许多重复的关键字或填充词。
- 对比帧-标题匹配使用联合视觉-语言转换器中的纯语言部分。每个帧 I~t~和 caption w~t~ 的匹配表示形式被视为正面示例,而负面示例来自小批量中的所有其他帧-标题对。
- 时间重新排序学习时间推理:打乱随机i帧,并将段级位置嵌入替换为随机且唯一的位置嵌入。随机位置嵌入被学习,允许模型以正确排序的帧为条件取消这些 “’shuffled’” 帧。
Flamingo ( Alayrac et al. 2022) 是一种视觉语言模型,它接受与图像/视频交错的文本并输出自由格式的文本。Flamingo 通过基于 transformer 的映射器连接预训练的 LM 和预训练的视觉编码器(即 CLIP 图像编码器)。为了更有效地整合视觉信号,Flamingo 采用基于 Perceiver 的架构,从大量视觉输入特征中生成数百个标记,然后使用与 LM 层交错的交叉注意力层将视觉信息融合到语言解码过程中。训练目标是自回归的 NLL 损失。Perceiver 重采样器从图像/视频输入的视觉编码器接收时空特征,以生成固定大小的视觉标记。冻结的 LM 配备了新初始化的交叉注意力层,这些层在预训练的 LM 层之间交错。因此LM 可以生成以上述视觉标记为条件的文本。
与 ClipCap 类似,两个预训练模型在训练期间都会被冻结,因此 Flamingo 仅经过训练才能将现有的强大语言和视觉模型和谐地连接在一起。ClipCap 和 Flamingo 的主要区别在于,前者将图像嵌入视为 LM 的简单前缀,而后者使用门控交叉注意力密集层来融合图像信息。此外,Flamingo 包含的训练数据比 ClipCap 多得多。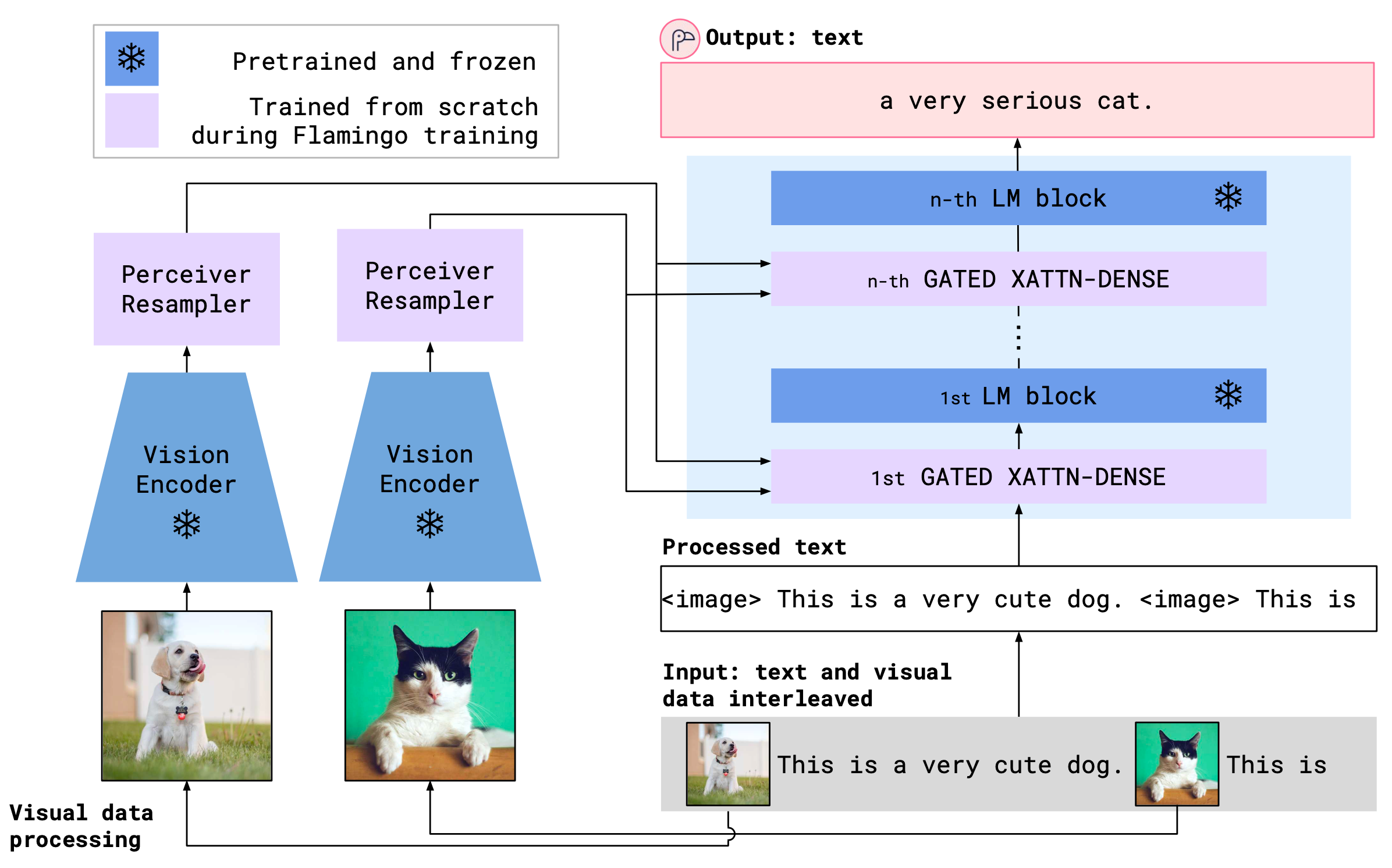
为了轻松处理带有交错图像的文本,Flamingo 中的遮罩设计为文本标记仅交叉关注与最后一个前图像对应的视觉标记,从而大大减少了某个文本标记可以看到的视觉标记的数量。他们发现这比允许文本标记直接处理所有前面的图像效果更好。文本仍然可以处理所有以前的图像,因为文本编码器中存在因果自我注意依赖关系。此设计可以处理上下文中任意数量的图像。从互联网上抓取了 4300 万个网页,名为 MultiModal MassiveWeb (M3W) 数据集,其中包含带有交错图像的文本。此外,Flamingo 还在配对的图像/文本和视频/文本数据集上进行了训练,包括 ALIGN、LTIP 和 VTP。
CoCa捕捉到了对比学习和图像到标题生成的优点。它是一个联合训练的模型,在 CLIP 风格的表示上具有对比损失,在图像描述上具有生成损失,在各种多模态评估任务上实现了 SoTA 零样本转移。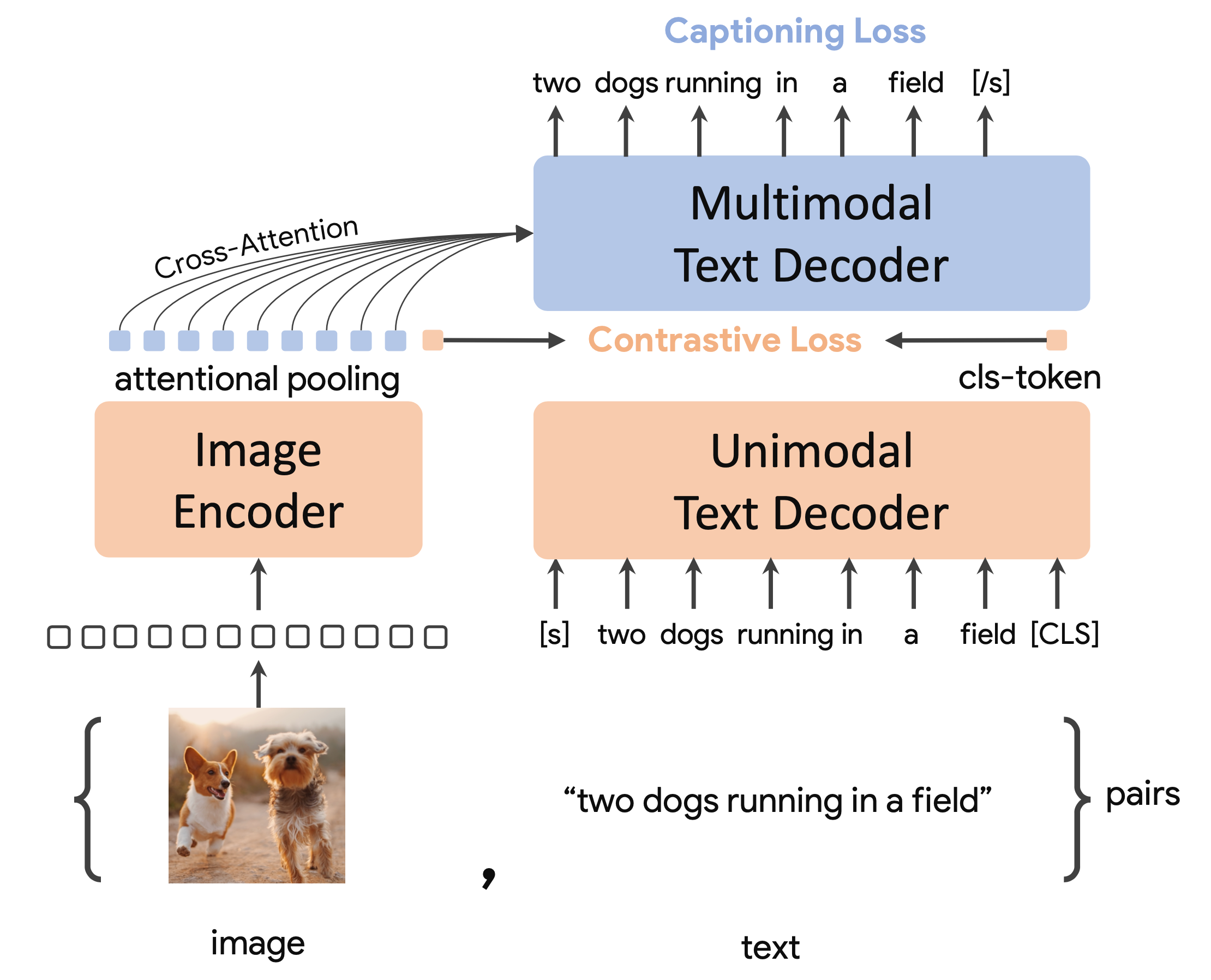
CoCa 是从头开始预训练的,使用 Web 规模的替代文本数据 ALIGN 和注释图像,将所有标签视为 JTB-3B 中的文本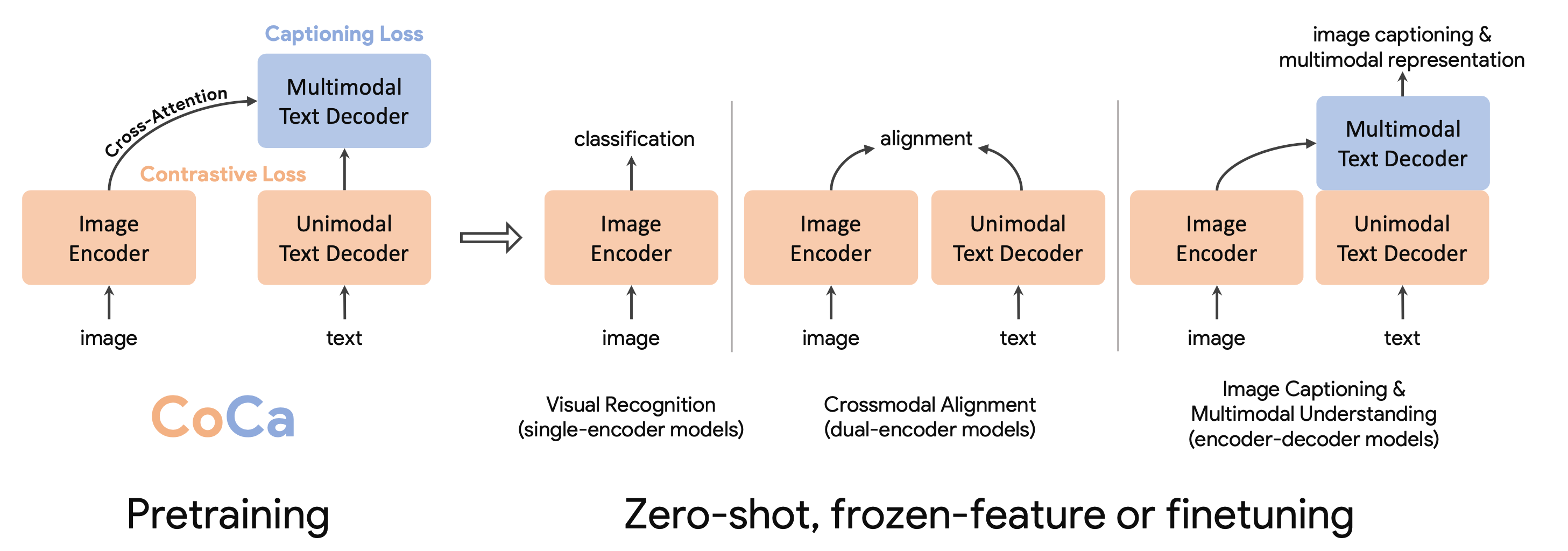
无训练方法
可以通过将预训练的语言和视觉模型拼接在一起来解决视觉语言任务,而无需训练任何其他参数。
MAGiC 根据名为 magic score 的基于 CLIP 的分数进行引导解码,以对下一个标记进行采样,而无需微调。鼓励生成的文本与给定图像相关,同时仍与先前生成的文本保持一致.与其他无监督方法相比,MAGiC 具有不错的性能,但与有监督方法仍然存在很大差距. MAGiC核心就是更改了采样方式,第t步采样的token会通过基于CLIP的分数计算与图像编码相似的值.
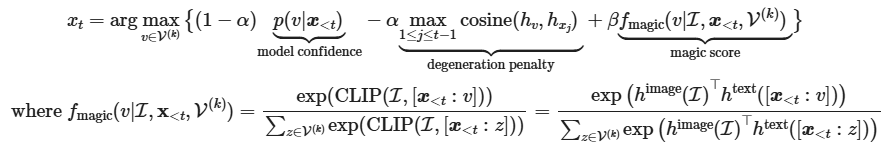
对于基于知识的 VQA 任务,PICa首先将图像转换为标题或标签,然后使用少数镜头示例提示 GPT3 提供答案。图像标题或标记由某些现有模型(例如 VinVL)或 Azure 标记 API 提取。GPT3 被认为是一个非结构化的隐式知识库.
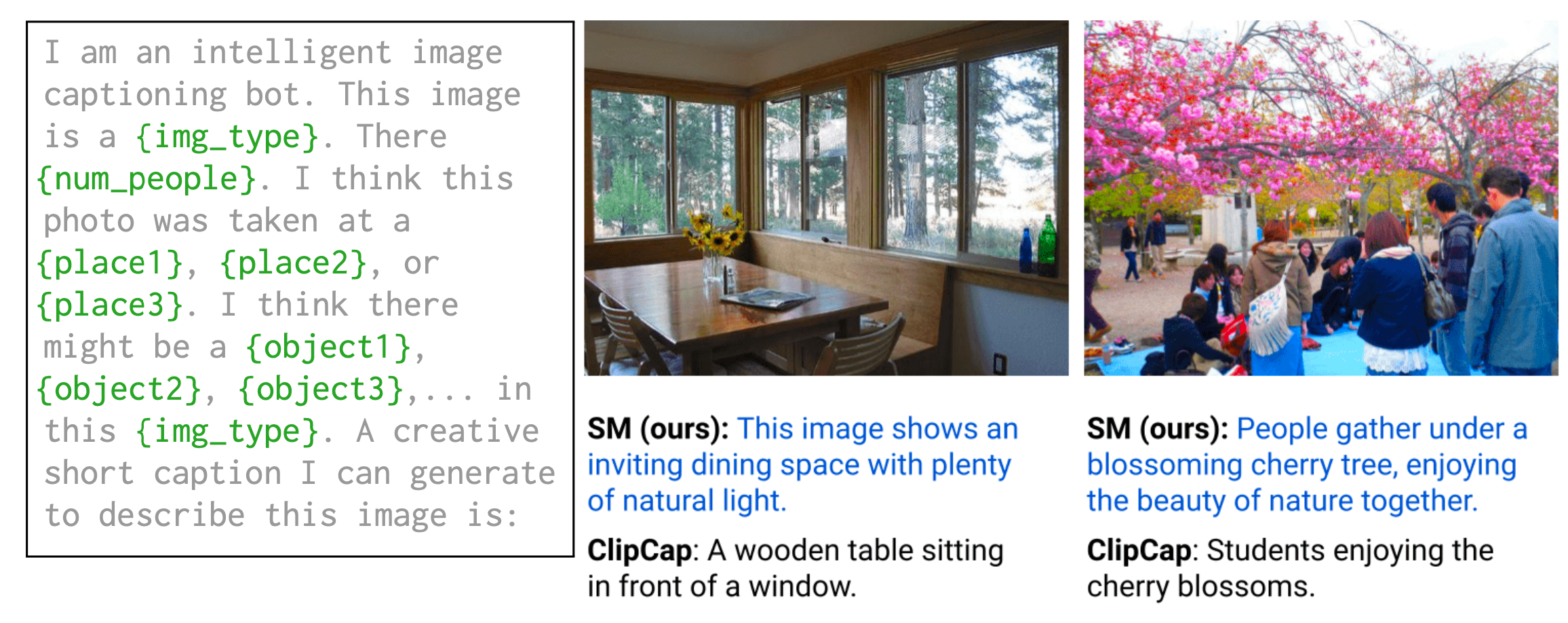
苏格拉底模型是一个框架,通过语言(提示)将不同模态的多个预训练模型组合成一个模型,而无需进一步训练。在这里,语言被认为是不同模型可以交换信息的中间表示。关键思想是使用多模型多模态提示,其中非语言模型的输出入到语言提示中,然后用于 LM 进行推理. SM 可以生成图像字幕,首先使用 VLM 对不同的地点类别、对象类别、图像类型和人数进行零拍摄预测;然后将 VLM 填充的语言提示输入到因果 LM 中以生成候选字幕。Socratic 方法在图像字幕方面与 ClipCap 的性能仍然存在差距,但考虑到它不涉及任何培训,因此相当不错。 简单来说就是将不同模态模型,比如vision-language model,language model,audio-language model结合在一起,通过一种相对固定的prompt template通信,SM 可以生成图像字幕,首先使用 VLM 对不同的地点类别、对象类别、图像类型和人数进行零拍摄预测;然后将 VLM 填充的语言提示输入到因果 LM 中以生成候选字幕
大模型驱动的Agents
多个大模型之间协作增强输出并设计一些类似模仿一个系统中负责不同功能的组件组成Agent. 目前许多大模型公司在做应用时都是往这个方向发展.在 LLM 驱动的自主代理系统中,LLM 充当代理的大脑,并辅以几个关键组件:
规划:子目标和分解:智能体将大型任务分解为较小的、可管理的子目标,从而能够高效处理复杂任务。反思和完善:智能体可以对过去的行为进行自我批评和自我反省,从错误中吸取教训并为未来的步骤进行改进,从而提高最终结果的质量。(任务分解和完善行为)
记忆: 短期记忆:所有的上下文学习(参见提示工程)都是利用模型的短期记忆来学习的。长期记忆:这为代理提供了在较长时间内保留和调用(无限)信息的能力,通常是通过利用外部向量存储和快速检索。
工具使用:智能体学习调用外部 API 以获取模型权重中缺少的额外信息(通常在预训练后很难更改),包括当前信息、代码执行能力、对专有信息源的访问等

规划
任务分解
Chain of Thoughts已成为提高模型在复杂任务上性能的标准提示技术。该模型被指示 “逐步思考”,以利用更多的测试时计算将困难的任务分解为更小、更简单的步骤。CoT 将大任务转化为多个可管理的任务,并阐明对模型思维过程的解释
Tree of Thoughts通过在每一步探索多种推理可能性来扩展 CoT。它首先将问题分解为多个思考步骤,每个步骤生成多个思考,从而创建一个树状结构。搜索过程可以是 BFS(广度优先搜索)或 DFS(深度优先搜索),每个状态都由分类器(通过提示)或多数投票进行评估。
任务分解可以通过以下方式完成:(1) 由 LLM 使用简单的提示,如 "Steps for XYZ.\n1." , "What are the subgoals for achieving XYZ?" , (2) 通过使用特定于任务的指令;例如 "Write a story outline." 用于写小说,或 (3)人工输入
另一种非常不同的方法 LLM+P ( Liu et al. 2023) 涉及依靠外部经典规划师进行长期规划。这种方法利用规划域定义语言 (PDDL) 作为中间接口来描述规划问题。在这个过程中, LLM (1) 将问题翻译成 “问题 PDDL”,然后 (2) 请求经典规划师基于现有的 “领域 PDDL” 生成 PDDL 计划,最后 (3) 将 PDDL 计划翻译回自然语言。从本质上讲,规划步骤外包给外部工具,假设特定领域的 PDDL 和合适的规划器可用,这在某些机器人设置中很常见,但在许多其他领域中并不常见
自我反思
自我反省允许自主智能体通过改进过去的行动决策和纠正以前的错误来迭代改进。它在不可避免地需要试错的实际任务中起着至关重要的作用。
ReAct通过将动作空间扩展为特定于任务的离散动作和语言空间的组合,将推理和行动整合到 LLM 中。前者使 LLM 能够与环境交互(例如使用维基百科搜索 API),而后者则提示 LLM 以自然语言生成推理轨迹。
Reflexion 是一个框架,用于为智能体提供动态记忆和自我反思能力,以提高推理技能。Reflexion具有标准的 RL 设置,其中奖励模型提供简单的二进制奖励,操作空间遵循ReAct中的设置,其中特定于任务的操作空间通过语言进行扩充,以支持复杂的推理步骤。在每个操作a~t~之后,智能体会计算启发式 h~t~,并且可以根据自我反思结果选择性地决定重置环境以开始新的试用。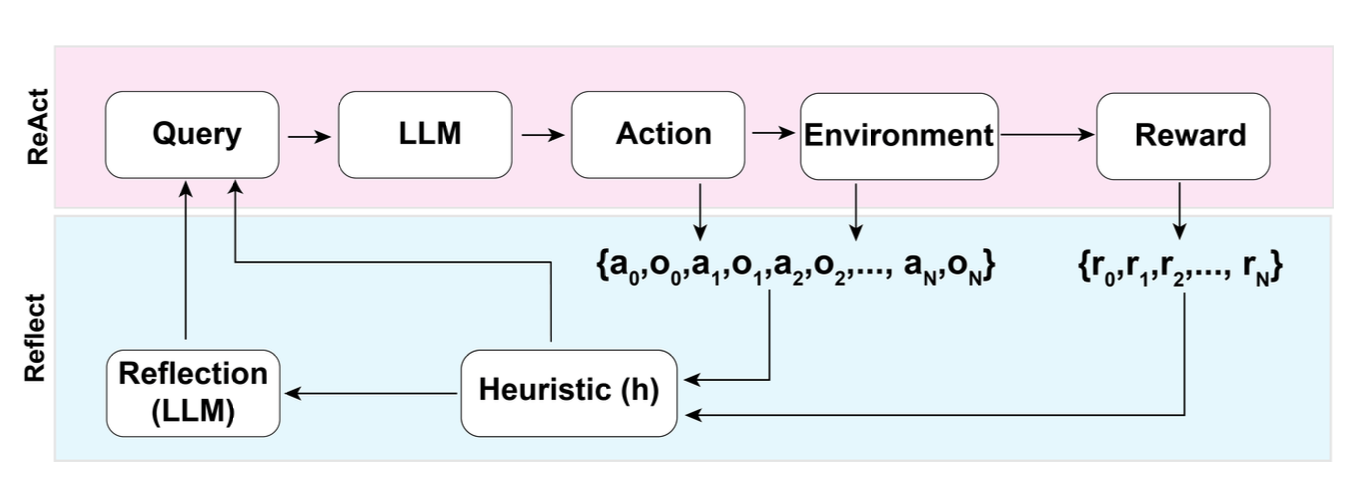
启发式函数确定轨迹何时效率低下或包含幻觉,何时应停止。低效的规划是指花费太长时间而没有成功的轨迹。幻觉被定义为遇到一系列连续的相同动作,这些动作导致在环境中进行相同的观察。
自我反思是通过向 LLM 展示两张照片的例子来创建的,每个例子都是一对(失败的轨迹,指导计划中未来变化的理想反思)。然后将反射添加到 agent 的工作内存中,最多三个,用作查询 LLM 的上下文。
Chain of Hindsight鼓励模型通过明确呈现一系列过去的输出来改进自己的输出,每个输出都带有反馈注释.CoH 的理念是在上下文中呈现连续改进的产出的历史,并训练模型顺应趋势以产生更好的产出。算法蒸馏将相同的想法应用于强化学习任务中的跨集轨迹,其中算法被封装在一个长期受历史条件限制的策略中。考虑到代理与环境交互多次,并且每次代理都会变得更好,AD 会将此学习历史记录连接起来,并将其馈送到模型中。
记忆模块
三种类型的记忆
- 感官记忆:这是记忆的最早阶段,提供在原始刺激结束后保留感官信息(视觉、听觉等)印象的能力。感官记忆通常最多只持续几秒钟。子类别包括图标记忆(视觉)、回声记忆(听觉)和触觉记忆(触觉
- 短期记忆 (STM) 或工作记忆:它存储我们目前知道的和执行复杂认知任务(如学习和推理)所需的信息。短期记忆被认为具有大约 7 项的容量 (Miller 1956) 并持续 20-30 秒。
- 长期记忆 (LTM):长期记忆可以存储信息非常长的时间,从几天到几十年不等,具有基本上无限的存储容量。LTM 有两种亚型:
显性 / 陈述性记忆:这是对事实和事件的记忆,指的是那些可以被有意识地回忆起来的记忆,包括情景记忆(事件和经历)和语义记忆(事实和概念)
内隐/程序记忆:这种类型的记忆是无意识的,涉及自动执行的技能和例程,例如骑自行车或在键盘上打字。
感官记忆作为原始输入(包括文本、图像或其他模态)的学习嵌入表示;
短期记忆作为上下文学习。它简短而有限,因为它受 Transformer 的有限上下文窗口长度的限制。
长期内存作为代理在查询时可以处理的外部向量存储,可通过快速检索访问。最大内积搜索
外部存储器可以缓解有限注意力持续时间的限制。标准做法是将信息的嵌入表示保存到可以支持快速最大内积搜索 (MIPS) 的向量存储数据库中。为了优化检索速度,常见的选择是近似最近邻 (ANN) 算法,以返回大约 k 个前 k 个最近邻,以牺牲一点准确性损失来换取巨大的加速
LSH(Locality-Sensitive Hashing):它引入了一个哈希函数,以便将相似的输入项以高概率映射到相同的存储桶,其中存储桶的数量远小于输入的数量
ANNOY (Approximate Nearest Neighbors Oh Yeah):核心数据结构是随机投影树,这是一组二叉树,其中每个非叶节点代表一个将输入空间分成两半的超平面,每个叶子存储一个数据点。树是独立且随机构建的,因此在某种程度上,它模仿了哈希函数。ANNOY 搜索发生在所有树中,以迭代搜索最接近查询的一半,然后聚合结果。这个想法与 KD 树非常相关,但更具可扩展性。
HNSW(分层可导航小世界):它的灵感来自小世界网络的思想,其中大多数节点可以在少量步骤内被任何其他节点到达;例如社交网络的“六度分离”功能。HNSW 构建了这些小世界图的分层,其中底层包含实际数据点。中间的图层创建快捷方式以加快搜索速度。在执行搜索时,HNSW 从顶层的随机节点开始,并导航到目标。当它无法更靠近时,它会向下移动到下一层,直到到达底层。上层的每次移动都可能覆盖数据空间中的很长一段距离,而下层的每一次移动都会提高搜索质量。
FAISS(meta相似性搜索):它的运行基于以下假设:在高维空间中,节点之间的距离遵循高斯分布,因此应该存在数据点的聚类。FAISS 通过将向量空间划分为多个聚类,然后在聚类内优化量化来应用向量量化。Search 首先查找具有粗略量化的候选集群,然后进一步查找具有更精细量化的每个集群。
工具使用
工具的使用是人类的一个显著特征。我们创造、修改和利用外部物体来做超出我们身体和认知极限的事情。为 LLMs 配备外部工具可以显着扩展模型功能。
HuggingGPT 是一个以 ChatGPT 作为任务规划器的框架,根据模型描述选择 HuggingFace 平台中可用的模型,并根据执行结果总结响应. 系统调用包括任务规划,模型选择,任务执行,生成响应.
API-Bank 是评估工具增强 LLMs 性能的基准。它包含 53 个常用的 API 工具、一个完整的工具增强 LLM 工作流程,以及 264 个带注释的对话,涉及 568 个 API 调用。API 的选择非常多样化,包括搜索引擎、计算器、日历查询、智能家居控制、日程管理、健康数据管理、帐户身份验证工作流程等。因为 API 数量众多,所以 LLM 首先要有 API 搜索引擎,找到合适的 API 进行调用,然后用相应的文档进行调用。
协同感知中的LLM
最近有一系列的工作使用LLM与协同感知、自动驾驶结合(也有使用VLM的,方法类似).这里简单介绍一些相关工作.
V2V-LLM: Vehicle-to-Vehicle Cooperative Autonomous Driving with Multi-Modal Large Language Models
当前的自动驾驶车辆主要依靠其单独的传感器来了解周围的场景并规划未来的轨迹,当传感器发生故障或被遮挡时可能是不可靠的。为了解决这个问题,通过车辆到车辆( Vehicle-to-Vehicle,V2V )通信的协作感知方法已经被提出,但它们往往侧重于检测和跟踪。这些方法如何有助于整体的协作规划性能仍未得到充分的研究。
受最近使用大语言模型( Large Language Models,LLMs )构建自动驾驶系统的进展的启发,提出了一种新的问题设置,将LLM集成到协作自动驾驶中,并提出了车对车问答( Vehicle-to- Vehicle Question-Answering,V2V-QA )数据集和基准测试集.
还提出了基线方法Vehicle-to-Vehicle Large Language Model ( V2V-LLM ),它使用一个LLM来融合来自多个连接的自动驾驶车辆( CAV )的感知信息,并回答与驾驶相关的问题:grounding,notable objected identification, and planning.
实验结果表明,提出的V2VLLM可以作为一个有前途的统一模型架构来执行协作自动驾驶中的各种任务,并且优于使用不同融合方法的其他基线方法。工作也开创了一个新的研究方向,可以提高未来自动驾驶系统的安全性。
无人驾驶车辆在日常运行中的感知和规划系统严格依赖于其本地的LiDAR传感器和相机来探测附近的显著目标并进行规划.当传感器被附近的大型物体遮挡时,这种方法可能会遇到安全问题。在这种情况下,自动驾驶车辆无法准确地检测到所有附近的显著目标,使得后续的轨迹规划结果不可靠。
为了解决这个安全问题,最近的研究提出了通过车车通信( V2V )通信的协作感知算法。在协同驾驶场景中,多个邻近行驶的智能网联汽车( Connected Autonomous Vehicles,CAVs )通过V2V通信共享彼此的感知信息。然后将接收到的来自多个CAV的感知数据进行融合,以产生更好的整体检测结果。
所有CAV与LLM共享各自的感知信息。任何CAV都可以以自然语言的形式向LLM提问,以获取对驾驶安全有用的信息。
为了研究这个问题,首先创建了车辆到车辆问答( V2V-QA )数据集,该数据集基于V2V4Real的自动驾驶协作感知数据集。
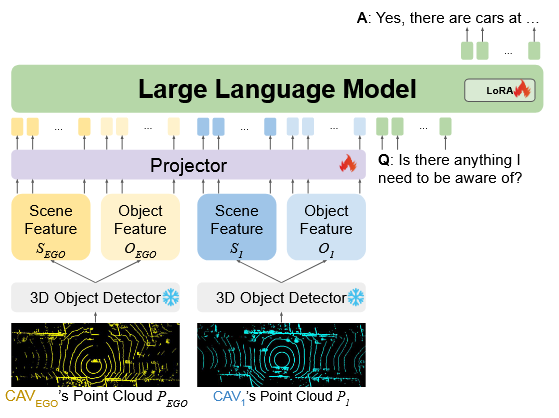
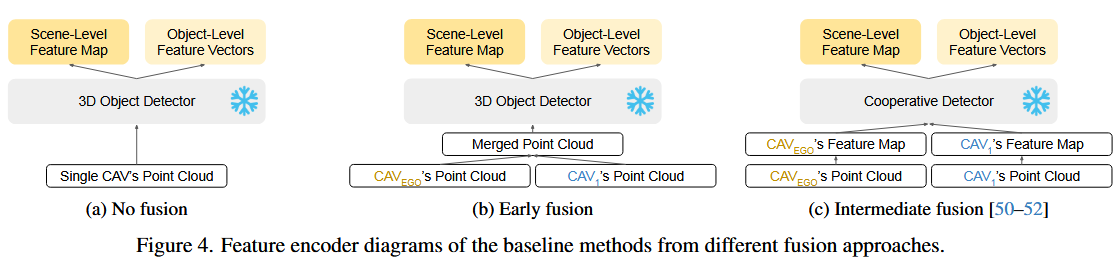
车-车大语言模型( V2V-LLM )用于协同自动驾驶.每个CAV提取自己的感知特征,并与V2V-LLM共享。V2V-LLM融合场景级特征图和对象级特征向量,然后进行视觉和语言理解,为V2V-QA中输入的驾驶相关问题提供答案。
还将V2V - LLM与其他基线方法对应的不同特征融合方法:不融合、早期融合和中间融合进行了比较。结果表明,V2V - LLM在较重要的目标识别和规划任务中取得了最好的性能,在grounding任务中取得了次优的性能,
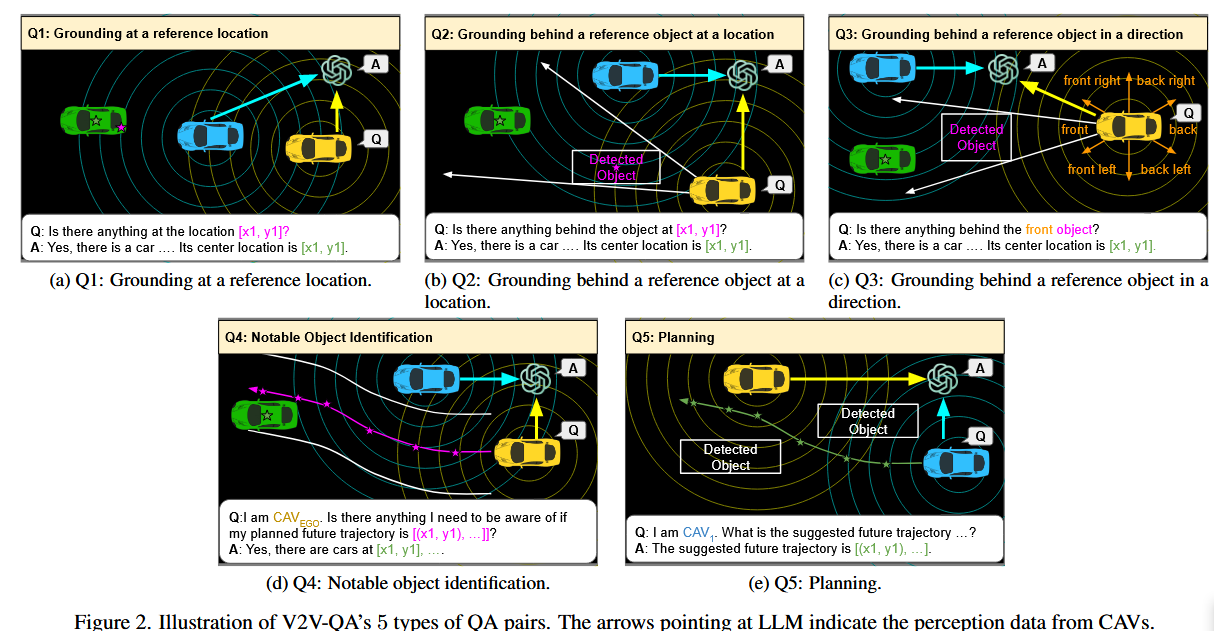
对于V2V4Real数据集的每一帧,创建了5种不同类型的问答对,包括3种类型的背景问题,1种类型的显著对象识别问题和1种类型的规划问题。这些QAs是针对协同驾驶场景设计的。为了生成这些问答对的实例,使用V2V4Real 的ground-truth边界框注释、每个CAV的ground - truth轨迹和个体检测结果作为源信息。然后根据前述实体和文本模板之间的几何关系使用不同的手动设计的规则来生成的问答对
作者设计了几种不同类型的问答对作为数据集,这个数据集也是多模态数据集.
Q1 Grounding at a reference location
在这种类型的问题中,要求LLM来识别是否存在一个对象占据了特定的查询2D位置。如果是,则期望LLM提供物体的中心位置。否则,LLM应该表示在参考位置处没有任何信息。为了生成这类问答对的实例,我们使用背景-真值框的中心位置和每个CAV的单个检测结果框作为问题中的查询位置。这样,我们可以更专注于评估各个模型对潜在的假阳性和假阴性检测结果的协同接地能力。
Q2 Grounding behind a reference object at a location
当一个CAV的视场被一个邻近的大物体遮挡时,该CAV可能希望根据所有CAV的融合感知信息,请求中心化的LLM来判断遮挡大物体后面是否存在物体。如果是这样的话,LLM预计将返回对象的位置,询问CAV可能需要更多的防御性驾驶或调整其规划。否则,LLM应该表明参照对象背后没有任何东西。为了生成这类问答对的实例,使用每个检测结果框的中心位置作为这些问题中的查询位置。根据询问的CAV与参考物体的相对位姿画出一个扇形区域,并在该区域中选择距离最近的真实物体作为答案。
Q3 Grounding behind a reference object in a direction
进一步在语言和空间理解能力上对LLM提出了挑战,将Q2的参考2D位置替换为参考方向关键字。为了生成这类QA对的实例,首先在一个CAV的6个方向中各得到一个最接近的检测结果框作为参考对象。然后在Q2中遵循相同的数据生成方法,在相应的扇形区域中得到最接近的ground-truth box作为答案。
Q4 Notable object identification
前述的真值任务可以看作自动驾驶管道中的中间任务。自动驾驶车辆更关键的能力包括识别规划的未来轨迹附近的显著目标和调整未来规划以避免潜在的碰撞。在显著性物体识别问题中,从地面-真值轨迹中提取了6个未来3秒的路标点作为问题中的参考未来路标点。然后,在参考未来轨迹的10米范围内最多得到3个最近的地面真实物体作为答案。
Q5 规划
与上述QA类型相比,规划是自动驾驶系统最重要的输出,因为自动驾驶汽车的最终目标是安全地通过复杂的环境,避免未来的任何潜在碰撞。为了生成规划QAs,我们从每个CAV的真实未来轨迹中提取6个均匀分布在未来3秒内的未来航路点作为答案。由于一些原因,V2V - QA的规划任务也比其他基于NuScenes的LLM驱动的相关工作更具有挑战性。首先,我们在协同驾驶场景中支持多辆CAV。LLM模型需要提供不同的答案,这取决于哪个CAV要求其建议的未来轨迹,而先前的工作只需要生成单个自动驾驶车辆的规划结果。其次,V2V-QA是基于V2V4Real的,它包括城市和高速公路两种驾驶场景。在这两种不同的环境中,车辆的运动模式有很大的不同。相反,基于Nu Scenes的LLM驾驶研究只需要考虑城市驾驶场景。
AGENTSCODRIVER: Large Language Model Empowered Collaborative Driving with Lifelong Learning
智能网联汽车和无人驾驶近来发展迅速。然而,目前的自动驾驶系统主要基于数据驱动的方法,在可解释性、泛化性和持续学习能力方面表现出明显的不足。此外,单车自动驾驶系统缺乏与其他车辆协作和协商的能力,这对驾驶安全和效率至关重要。为了有效地解决这些问题,利用大型语言模型( LLMs )开发了一个新的框架,称为AGENTSCODRIVER,以使多车辆能够进行协同驾驶。
AGENTSCODRIVER由5个模块组成:观察模块、推理引擎、认知记忆模块、强化反射模块和通信模块。它可以通过与驾驶环境的不断交互,随时间推移积累知识、教训和经验,从而使实现终身学习成为可能。此外,通过利用通信模块,不同智能体可以交换信息,实现复杂驾驶环境下的协商与协作。进行了大量的实验,并显示了AGENTSCODRIVER相对于现有方法的优越性。
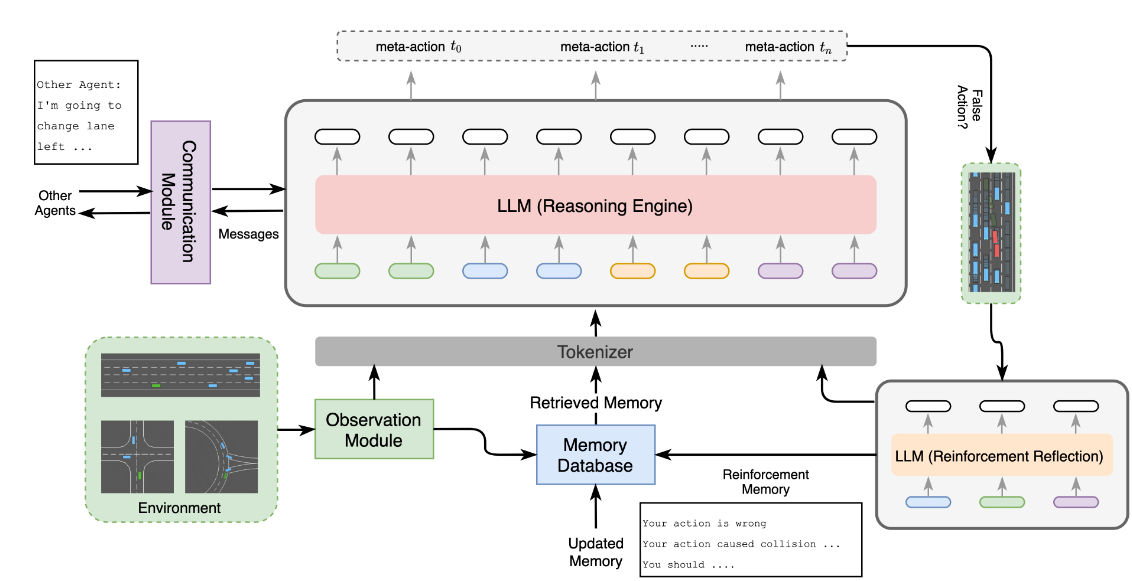
AGENTSCODRIVER的体系结构由5个模块组成:观测模块、推理引擎、存储模块、增强反射模块和通信模块。推理引擎、通信模块和增强反射模块利用LLMs生成消息和最终决策
Observation Module
为了使智能体能够进行协作,CAV感知其周围环境并提取必要的信息用于下游的高阶任务推理是很重要的,因此为智能体开发了一个观测模块来编码其周围的场景,并提取其有用的高层信息,如车道数和周围车辆的位置和速度。然后将这些观察结果输入到智能体的推理引擎中进行分析并做出决策。它们也被用来从记忆模块中回忆相关的记忆
Reasoning Engine
推理是人类最基本、最重要的能力之一,对于人类做出日常的、复杂的决策具有重要的意义。传统的数据驱动方法直接利用感知信息(例如,目标检测结果和语义分割结果)进行最终的驾驶决策(例如,左转或右转,加速和减速),缺乏可解释性,无法处理复杂场景和长尾情况。受人类推理能力的启发,我们提出了一个CAV智能体的推理引擎,它由三个步骤组成:1 )提示生成,2 )推理过程,3 )运动规划。
Memory Module
记忆对于一个人来说是非常重要的。当一个人驾驶汽车时,他或她会使用常识,例如遵守交通规则和回忆过去的经验来做出决定。为了将这种能力灌输给智能体,我们提出了智能体的记忆模块,该模块由三部分组成:常识记忆、经验记忆和结构化文本存储的反思记忆。常识性记忆包含了驾驶的常识性知识,如交通规则等。经验记忆包含过去的驾驶场景和相应的决策。反射记忆包含反射模块的反馈。智能体可以从存储模块中检索相关的内存,使其可用于决策。
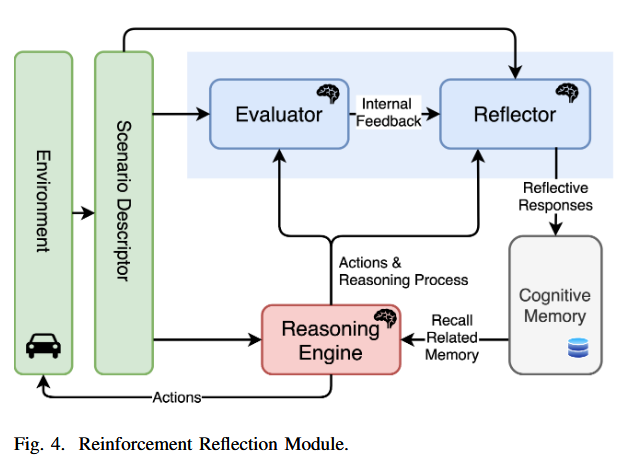
Reinforcement Reflection
一个人要想成为某一领域的专家,就必须从过去的经历中学习,这意味着他必须有能力反思自己过去的错误,并分析其背后的原因。对于智能体来说,拥有这样的反思能力对于保持正确的操作和安全驾驶也是至关重要的。基于这些观察,提出了强化反射,它有两个模块:一个评估器和一个反射器。评价者(记为E )像评判者一样对agent的输出进行打分,反射者(记为R )可以对agent的行为进行反思,并生成分析结果来改进agent的行为。
Communication Module
协作Agent之间的有效通信是至关重要的。通过相互之间的通信,将扩大智能体的观测范围。分别考虑两个智能体的观测值o1和o2,如果两个智能体相互交换观测信息,则两个智能体的观测值将扩展到o1∪o2。此外,沟通对于代理人之间相互协商并做出更好的决策也是至关重要的。例如,考虑一个智能体正在驾驶一辆汽车,并且想要超越前车。如果智能体与前车进行通信,则前车的智能体学习到后方车辆的意图,进而可以做出更好的决策,避免潜在的碰撞。
Towards Interactive and Learnable Cooperative Driving Automation: a Large Language Model-Driven Decision-Making Framework
目前,智能网联汽车( Connected Autonomous Vehicles,CAVs )已经开始在世界各地进行开放道路测试,但其在复杂场景下的安全和效率表现仍不尽如人意。协同驾驶利用CAV的连通能力实现大于其部分之和的协同作用,使其成为提高复杂场景下CAV性能的一种有前途的方法。然而,缺乏交互和持续学习能力限制了当前的协同驾驶到单场景应用和特定的协同驾驶自动化( Cooperative Driving Automation,CDA )。
为了应对这些挑战,本文提出了一种可交互和学习的LLM驱动的协同驾驶框架CoDrivingLLM,以实现全场景和全CDA。
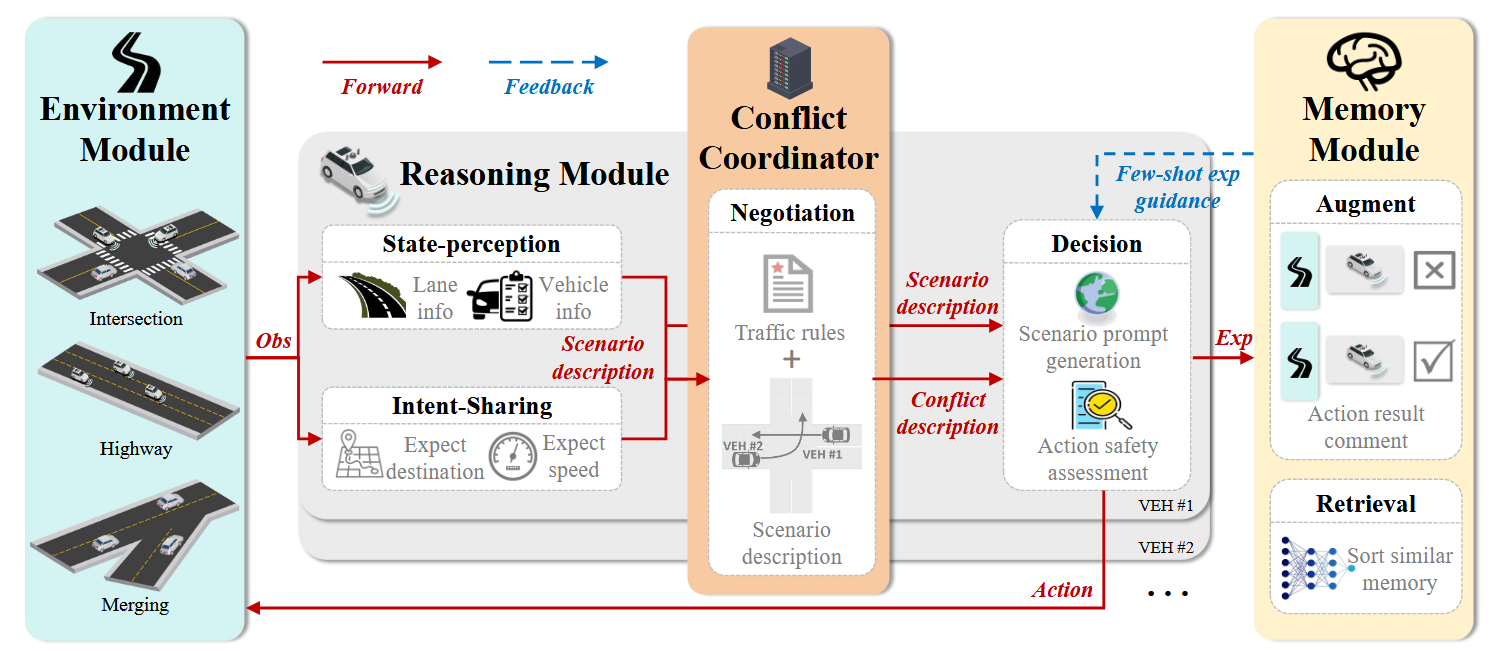
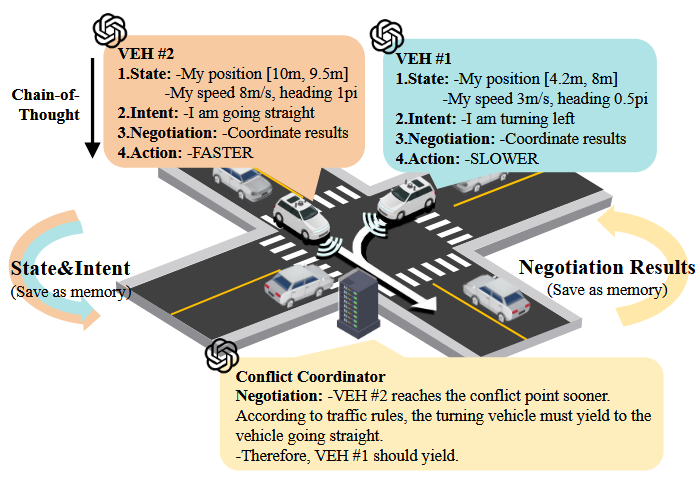
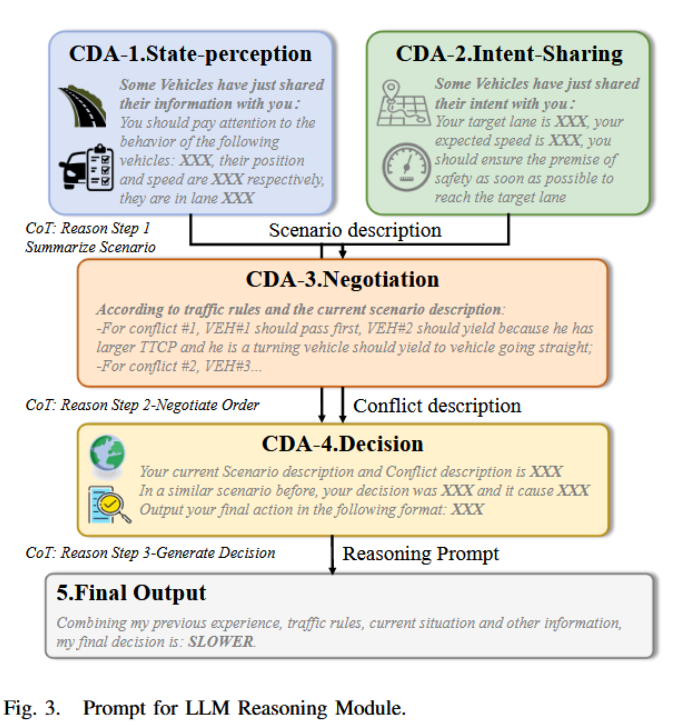
首先,由于大语言模型( Large Language Models,LLMs )不擅长处理数学计算,引入环境模块,基于语义决策更新车辆位置,从而避免直接LLM控制车辆位置可能带来的误差。其次,基于SAE J3216标准定义的CDA的四个层次,提出了基于思维链( Chain-of- Thought,COT )的推理模块,包括状态感知、意图共享、协商和决策,增强了LLMs在多步推理任务中的稳定性。
然后,在推理过程中,通过冲突协调者来管理集中的冲突解决。最后,通过引入记忆模块和使用提取增强生成,赋予CAVs从过去经验中学习的能力。