学习很潮很流行的Java以及相关框架.
Java基础
Java基础
1. java.lang.*
这是默认导入的包,包含基本类和接口。
- Object:所有类的超类。
- String:不可变字符串类,用于文本处理。
- StringBuilder/StringBuffer:可变字符串类,适用于频繁修改字符串的场景。
StringBuffer是线程安全的版本。 - System:提供系统相关的信息和操作,如
System.out.println()打印输出。 - Math:提供数学计算的方法,如三角函数、对数等。
- Integer, Double 等包装类:基本类型的对象表示形式,支持自动装箱/拆箱。
2. java.util.*
包含了集合框架、日期时间工具、随机数生成器等实用工具类。
- Collection 接口及其实现类(如ArrayList, LinkedList, HashSet, TreeSet等):提供了不同类型的集合实现。
- Map 接口及其实现类(如HashMap, TreeMap等):键值对存储结构。
- Iterator:遍历集合的标准方式。
- Date, Calendar, LocalDate, LocalDateTime(Java 8+):处理日期和时间。
- Random:生成伪随机数。
- Arrays:提供操作数组的各种静态方法。
函数式编程(function)包提供了一些功能接口
Function<T, R>:接受一个参数并返回结果。Predicate<T>:接受一个输入参数并返回布尔值。方法签名:`boolean test(T t)```BiFunction<T, U, R>:接受两个输入参数并返回结果。方法签名:R apply(T t, U u)UnaryOperator<T>:接受一个参数并返回相同类型的值,是Function<T, T>的特化形式。 方法签名:T apply(T t)BinaryOperator<T>:接受两个相同类型的参数并返回相同类型的值,是BiFunction<T, T, T>的特化形式。 方法签名:`T apply(T t, T u)```BiPredicate<T, U>:接受两个输入参数并返回布尔值。方法签名:boolean test(T t, U u),用于需要基于两个输入值进行条件判断的场景Supplier<T>:适用于你需要从无到有地“生产”数据的场合。它不接收任何参数,但是可以返回你所需要的类型的实例。这使得它非常适合用于延迟初始化、配置加载等场景。BiConsumer<T, U>:当你需要处理或操作一对相关的值,并且这些操作的结果并不重要(即不需要返回值)时非常有用。比如,你可能想要记录一组键值对的日志,或者将两个值合并在一起而不关心最终结果。
3. java.io.*
提供输入输出流的支持,用于读写文件或进行网络通信。
- InputStream/OutputStream:字节流基类。
- Reader/Writer:字符流基类。
- File:文件或目录路径名的抽象表示形式。
- BufferedReader/BufferedWriter, BufferedInputStream/BufferedOutputStream:提高I/O效率的缓冲类。
4. java.nio.*
新的I/O API,提供了更高效的非阻塞I/O操作。
- Path, Paths:用于处理文件系统路径。
- Files:提供对文件的操作方法。
- ByteBuffer及其他缓冲区类型:用于高效地管理字节序列。
5. java.net.*
网络编程相关的API。
- URL, URI:统一资源定位符/标识符。
- URLConnection:与URL建立连接。
- Socket, ServerSocket:TCP/IP套接字编程的基础类。
- DatagramPacket, DatagramSocket:UDP协议的支持。
6. java.text.*
用于格式化和解析文本。
- NumberFormat, DecimalFormat:数字格式化。
- DateFormat, SimpleDateFormat:日期格式化。
- MessageFormat:根据模式格式化消息。
7. java.time.*
Java 8引入的新日期时间API。
- Instant:表示时间线上的一点。
- LocalDate, LocalTime, LocalDateTime:分别表示不带时区的日期、时间和日期时间。
- ZonedDateTime, OffsetDateTime:带有时区信息的日期时间。
8. 并发相关
- Thread:创建和控制线程。
- Runnable:线程执行的目标接口。
- ExecutorService, Executors:更高级别的线程管理。
- Lock, ReentrantLock:比同步块更灵活的锁定机制。
- ConcurrentHashMap:线程安全的哈希表实现。
9. 其他
- Optional(Java 8+):避免空指针异常的一种设计模式。
- Stream API(Java 8+):提供了一种高效且易于使用的集合元素处理方式。
| 访问修饰符 | 同一类 | 同一包 | 子类(不同包) | 全局 |
|---|---|---|---|---|
public | 是 | 是 | 是 | 是 |
protected | 是 | 是 | 是 | 否 |
| 默认 | 是 | 是 | 否 | 否 |
private | 是 | 否 | 否 | 否 |
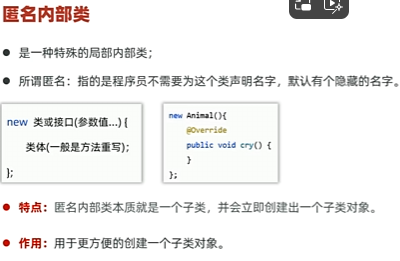
内部类
成员内部类,静态内部类,局部内部类,匿名内部类

1
2
3
4
5
6
7
8
9
10
11
12// 成员内部类
class outerclass {
private String name;
private static String age;
public class innerclass {
void display() {
System.out.println("This is an inner class");
System.out.println(name);
System.out.println(age);
}
}
}

1
2
3
4
5
6
7public static class innercls {
void display() {
System.out.println("This is an inner class");
System.out.println(innercls.this);
System.out.println(age);
}
}

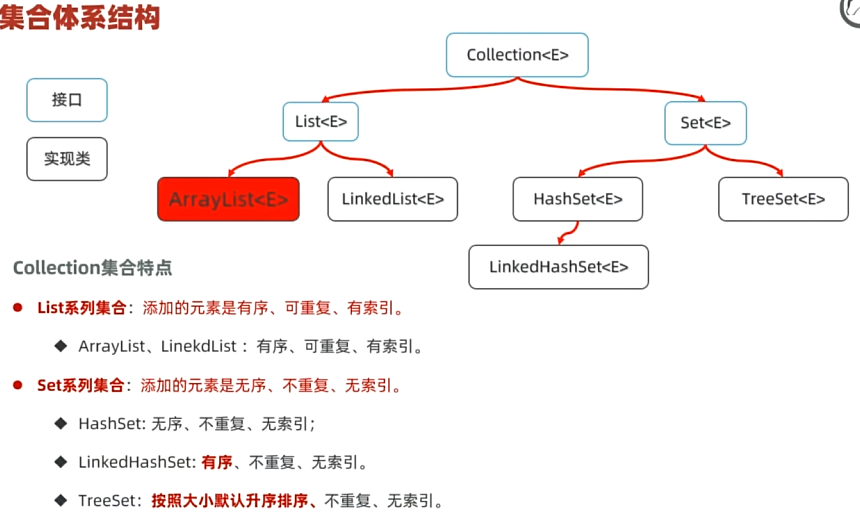
集合Collection与Map
数组和集合的区别:
数组
固定大小:数组一旦创建,其大小是固定的,不能动态增加或减少元素。
类型安全:数组可以是基本数据类型(如
int[],double[])或对象类型(如String[])。对于对象类型的数组,所有元素都必须是该类的实例或者null。内存连续:数组中的元素在内存中是连续存储的,这使得访问速度非常快,因为可以通过计算偏移量直接访问任何元素(时间复杂度为 O(1))。
声明方式
1
2int[] numbers = new int[5]; // 创建一个包含5个整数的数组
String[] names = {"Alice", "Bob"}; // 初始化时赋值
优点
- 访问速度快,支持随机访问。
- 对于小规模、固定数量的数据集非常适合。
List
定义与特性
动态大小:
List接口的主要实现类(如ArrayList,LinkedList)允许动态添加和删除元素,这意味着你可以根据需要扩展或缩小列表的大小。接口与实现:
List是一个接口,常用的实现包括ArrayList和LinkedList。ArrayList底层基于数组实现,而LinkedList则是一个双向链表。类型安全:
List只能存储对象,不能直接存储基本数据类型(但可以使用自动装箱/拆箱功能处理基本数据类型)。声明方式
1
2
3List<String> names = new ArrayList<>();
names.add("Alice");
names.add("Bob");
优点
- 动态大小,方便添加和删除元素。
- 提供了丰富的操作方法,比如
add(),remove(),get(),indexOf()等等。 - 更好的抽象层次,代码更加灵活易读。
缺点
- 相比于数组,某些操作可能效率较低,例如在
ArrayList中插入或删除中间位置的元素会导致其他元素移动;而在LinkedList中查找元素则需要从头或尾遍历整个列表。
ArrayList使用数组实现,查询快,增删慢
LinkedList使用双向链表实现,查询慢,增删快,尤其对于首尾操作
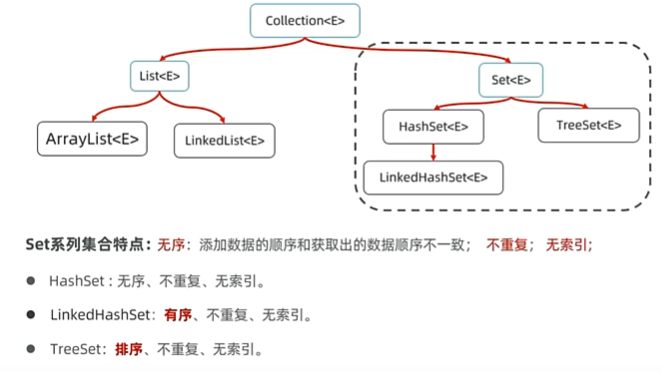
Set

HashSet使用哈希表实现,增删改查性能较好
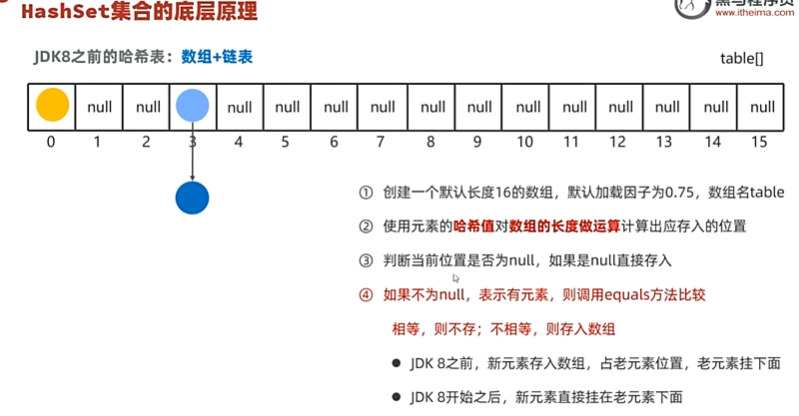
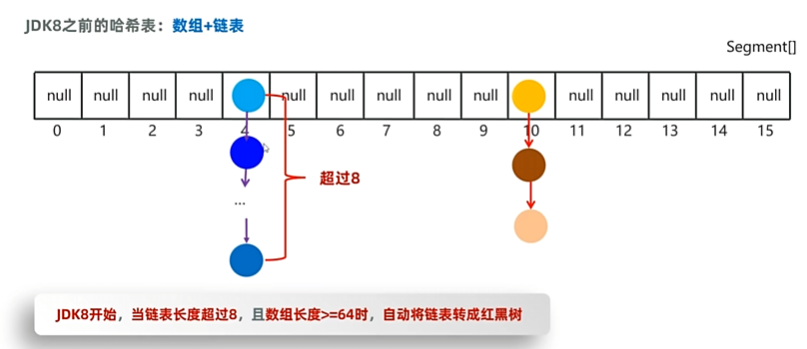
HashSet去重主要依赖于两个关键方法:hashCode() 和 equals()。
- hashCode() 方法:
- 当你尝试将一个对象添加到 HashSet 中时,HashSet 会首先调用这个对象的
hashCode()方法来计算该对象的哈希值。 - 这个哈希值决定了对象在内部哈希表中的存储位置(即所谓的“桶”)。
- 当你尝试将一个对象添加到 HashSet 中时,HashSet 会首先调用这个对象的
- equals() 方法:
- 如果两个对象有相同的哈希值(或者它们被分配到了同一个桶中),HashSet 将使用
equals()方法来进一步检查这两个对象是否真正相等。 - 如果
equals()返回true,则认为这两个对象是重复的,新对象不会被添加到集合中。如果equals()返回false,即使哈希值相同,这两个对象也被认为是不同的,并且都会被添加到集合中。
- 如果两个对象有相同的哈希值(或者它们被分配到了同一个桶中),HashSet 将使用
对于自定义类的对象,如果你希望它们能够正确地在 HashSet 中进行去重,你需要重写 hashCode() 和 equals() 方法,以确保具有相同业务含义的对象返回相同的哈希码并且 equals() 方法也返回 true。
TreeSet底层基于红黑树,可排序,不重复,无索引


Map
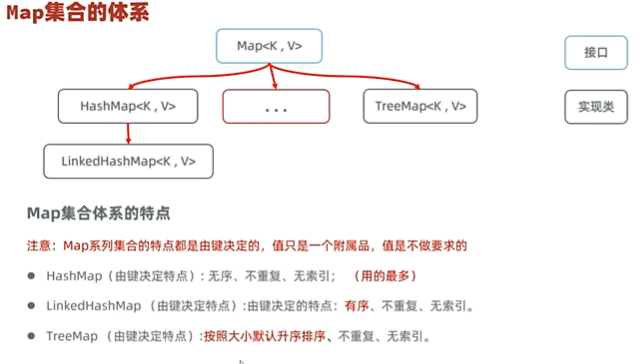

Map的遍历方式

使用 for-each 循环和 entrySet()
这是最常用的遍历方式之一,因为它提供了对键和值的访问。1
2
3for (Map.Entry<String, Integer> entry : map.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
使用迭代器
使用迭代器可以更灵活地控制遍历过程。1
2
3
4
5Iterator<Map.Entry<String, Integer>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<String, Integer> entry = iterator.next();
System.out.println(entry.getKey() + ": " + entry.getValue());
}
使用 Java 8 的 Stream API
通过 stream() 方法可以利用 Stream API 来遍历或进行其他操作。1
2
3map.entrySet().stream().forEach(entry ->
System.out.println(entry.getKey() + ": " + entry.getValue())
);
或者对于某些特定的操作,比如过滤、映射等:1
2
3map.entrySet().stream()
.filter(entry -> entry.getValue() > 1)
.forEach(entry -> System.out.println(entry.getKey()));
Stream流包括中间方法和最终方法,中间方法使用filter,map,调用完成后会返回新的流

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20List<String> alist = new ArrayList<>();
alist.add("a");
alist.add("b");
List<String> list = alist.stream().map((String a) -> a + "a").toList();
List<Double> blist = new ArrayList<>();
list.stream().filter(s-> !s.isEmpty()).forEach(System.out::println);
list.stream().sorted(Comparator.comparingDouble(String::length).reversed()).forEach(System.out::println);
blist.stream().sorted(Double::compare).forEach(System.out::println);
// 去重 limit只需要一个参数 skip跳过前几个
blist.stream().distinct().skip(1).limit(2).forEach(System.out::println);
// 转换成map
list.stream().collect(Collectors.toMap(Function.identity(), String::length)).forEach((k, v) -> System.out.println(k + ":" + v));
Stream<String> a = Stream.of("a", "b", "c");
Stream<Integer> integerStream = Stream.of(1, 2);
// 合并两个流
Stream.concat(a, integerStream).forEach(System.out::println);
异常、泛型与集合框架
Java中异常的类继承体系

运行时异常(extends RuntimeException:数组索引越界
编译异常(extends Exception). 编译时异常需要通过try-catch或throw丢出异常进行处理,
运行时异常不需要特别处理
此外异常可以分为业务类和运行逻辑类,一些代码中的异常应该被catch然后向上抛给业务类或者直接处理.

泛型允许编写可以处理不同类型数据的类、接口和方法,而无需在代码中明确指定具体类型。泛型提供了更强的类型检查,并且消除了对类型转换的需求,从而使得代码更加安全和易于维护。
类型参数:在定义泛型类或方法时使用占位符(通常为大写字母如 T, E, K, V 等),代表实际应用中的类型。
- 类型安全:编译器会在编译期进行类型检查,减少运行时出现的
ClassCastException错误。 - 消除类型转换:由于类型信息在编译时已知,因此不需要显式的类型转换。
使用泛型类
1 | Box<Integer> integerBox = new Box<>(); |
泛型方法
你也可以定义泛型方法,即在方法级别上使用泛型。例如:1
2
3
4
5
6
7
8
9
10
11
12
13public static <T> void printArray(T[] array) {
for (T element : array) {
System.out.println(element);
}
}
public static void main(String[] args) {
Integer[] intArray = {1, 2, 3};
String[] stringArray = {"A", "B", "C"};
printArray(intArray);
printArray(stringArray);
}
在这个例子中,<T> 在方法签名前声明了类型参数,这样这个方法就可以接受任意类型的数组作为参数。
泛型接口
类似地,也可以定义泛型接口:1
2
3
4public interface Container<T> {
void add(T item);
T get(int index);
}
然后实现这个接口:1
2
3
4
5
6
7
8
9
10
11
12
13public class StringContainer implements Container<String> {
private List<String> items = new ArrayList<>();
public void add(String item) {
items.add(item);
}
public String get(int index) {
return items.get(index);
}
}
Java 泛型是在 Java 5 中引入的,而在此之前已经存在了大量的 Java 代码库。如果直接在 JVM 层面实现泛型支持,那么这些现有的代码可能会因为缺乏泛型信息而不兼容。通过类型擦除,Java 编译器能够在编译时移除泛型类型信息,并将泛型代码转换为非泛型代码,这样就可以确保新旧代码可以无缝地一起工作
通配符
有时可能需要编写能够与多种类型工作的代码,但并不需要知道这些类型的具体细节。这时可以使用通配符 ?:
- 无界通配符:
<?>表示可以是任何类型。 - 有界通配符:
<? extends T>和<? super T>分别表示类型必须是T或其子类,以及T或其父类。
泛型的优点
- 类型安全:编译器可以在编译时进行更多的类型检查,减少运行时错误。
- 消除强制类型转换:不再需要手动将对象转换回原始类型。
- 提高代码重用性:通过泛型,相同的逻辑可以应用于不同的数据类型。
Java集合是一种容器,类似于数组但集合的大小可变.

多线程与线程池

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58package com.sekyoro.tutorThread;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
/**
* @projectName: workspace
* @package: com.sekyoro.tutorThread
* @className: threadDemo
* @author: proanimer
* @description:
* @date: 2025/3/19 16:19
*/
class easyThread extends Thread {
public void run() {
System.out.println("This is a thread");
}
}
class miniThread implements Runnable{
public void run() {
System.out.println("This is a mini thread");
}
}
class miniCallable implements Callable<Integer> {
private int n;
public miniCallable() {
this.n = 0;
}
public miniCallable(int n) {
this.n = n;
}
public Integer call() throws Exception {
System.out.println("Calculating...");
return 10;
}
public int getN() {
return n;
}
}
public class threadDemo {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Thread et = new easyThread();
et.start();
new Thread(new miniThread()).start();
Callable<Integer> mc = new miniCallable();
FutureTask<Integer> ft = new FutureTask<>(mc);
new Thread(ft).start();
Integer i = ft.get();
}
}

线程同步解决线程安全问题
同步代码块1
2
3synchronized() {
}

同步方法

1
2
3synchronized void draw(int m) {
money -= m;
}
Lock锁

1
2
3
4ReentrantLock lock = new ReentrantLock();
lock.lock();
...
lock.unlock();
显式锁(Explicit Lock)
ReentrantLock 类提供了比synchronized更灵活的锁操作,例如可中断的锁等待、尝试非阻塞获取锁、超时获取锁等。
1
2
3
4
5
6
7Lock lock = new ReentrantLock();
lock.lock(); // 获取锁
try {
// 受保护的代码
} finally {
lock.unlock(); // 确保释放锁
}
- 读写锁(ReadWriteLock)
ReadWriteLock 接口 和 ReentrantReadWriteLock 实现类.允许多个读操作同时进行,但在写操作时排斥所有其他读写操作。适用于读多写少的场景。1
2
3
4
5
6
7
8
9
10
11
12
13
14ReadWriteLock rwl = new ReentrantReadWriteLock();
rwl.readLock().lock(); // 获取读锁
try {
// 读取操作
} finally {
rwl.readLock().unlock(); // 释放读锁
}
rwl.writeLock().lock(); // 获取写锁
try {
// 写入操作
} finally {
rwl.writeLock().unlock(); // 释放写锁
}
- 条件变量(Condition)
Condition 接口与显式锁配合使用,提供类似1
2
3
4
5
6
7
8
9
10
11Lock lock = new ReentrantLock();
Condition condition = lock.newCondition();
lock.lock();
try {
condition.await(); // 相当于 wait()
// ...
condition.signal(); // 相当于 notify()
} finally {
lock.unlock();
}
- StampedLock
StampedLock 类是Java 8引入的一种新的锁类型,支持乐观读锁策略,适用于读多写少且大部分读操作不会发生冲突的情况。它提供了三种模式:写锁、悲观读锁和乐观读锁。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21StampedLock stampedLock = new StampedLock();
long stamp = stampedLock.readLock(); // 悲观读锁
try {
// 读取操作
} finally {
stampedLock.unlockRead(stamp);
}
stamp = stampedLock.writeLock(); // 写锁
try {
// 写入操作
} finally {
stampedLock.unlockWrite(stamp);
}
long optimisticStamp = stampedLock.tryOptimisticRead(); // 乐观读锁
// 验证并使用乐观读锁...
if (!stampedLock.validate(optimisticStamp)) {
// 如果验证失败,则需要重新获取悲观读锁或写锁
}
线程池
- ThreadPoolExecutor创建线程池
1 | // 1. 创建线程池 |

- 利用Executors创建线程池
利用ThreadPoolExecutor设置不同参数调用1
2
3
4
5
6public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
反射、注解与动态代理
反射是指在运行时动态地获取类的信息以及操作对象的能力。通常情况下,Java 编译器会在编译期确定所有类型和成员变量的访问权限及调用方式,而反射则允许你在运行时进行这些操作1
2
3
4
5
6
7
8
9
10
11
12
13// 方式一: 直接通过类名获取
Class<?> clazz = MyClass.class;
// 方式二: 使用对象的 getClass() 方法
MyClass obj = new MyClass();
clazz = obj.getClass();
// 方式三: 通过全限定类名字符串
try {
clazz = Class.forName("com.example.MyClass");
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
得到的class类可以用来创建实例、访问字段、调用方法等
创建实例1
2
3
4
5
6
7
8
9
10
11
12
13
14
15try {
// 假设 MyClass 有一个无参构造函数
Object obj = clazz.getDeclaredConstructor().newInstance();
} catch (Exception e) {
e.printStackTrace();
}
try {
// 获取指定参数类型的构造函数
Constructor<MyClass> constructor = clazz.getConstructor(paramType.class);
// 创建实例
MyClass instance = constructor.newInstance(args);
} catch (Exception e) {
e.printStackTrace();
}
注解(Annotations)是一种元数据形式,它提供了关于程序代码的额外信息,但这些信息并不直接改变程序的运行逻辑。注解自 Java 5 引入以来,已经成为 Java 开发中不可或缺的一部分,用于简化开发流程、提供配置信息、增强代码的功能等
- 定义:注解是接口的一种特殊形式,它通过
@interface关键字来定义,并可以附加到类、方法、变量、参数、包声明等语言元素上。 - 用途:主要用于编译时检查、运行时处理和生成源代码或文档。
- 标记注解:没有成员变量,仅作为标记使用,如
@Override。 - 单值注解:只有一个值,通常省略名称直接指定值,如
@SuppressWarnings("unchecked")。 - 完整注解:包含多个成员变量,需要明确指定每个成员的值。
元注解是指用来注解其他注解的注解,主要包括以下几个:
@Retention:定义了注解的存在阶段(SOURCE, CLASS, RUNTIME)。@Target:指定了注解可以应用的目标元素类型(TYPE, FIELD, METHOD, PARAMETER, CONSTRUCTOR, LOCAL_VARIABLE 等)。@Documented:表明这个注解应该被 javadoc 工具记录。@Inherited:允许子类继承父类中的注解。@Repeatable:从 Java 8 开始支持,表示相同的注解可以在同一地方多次使用。
注解的解析
检查方法和类等是否包含对应注解,若包含则进行相关调用1
2
3
4
5
6
7
8
9
10
11
12
13annotationDemo annotationDemo = new annotationDemo();
Class<?> aClass = annotationDemo.class;
Method[] methods = aClass.getMethods();
for (Method method : methods) {
if (method.isAnnotationPresent( MyTest.class)) {
try {
MyTest declaredAnnotation = method.getDeclaredAnnotation(MyTest.class);
method.invoke(annotationDemo);
} catch (IllegalAccessException | InvocationTargetException e) {
throw new RuntimeException(e);
}
}
}
动态代理
Proxy.newProxyInstance创建代理,参数包括类加载器,需要实现的接口,和代理需要做的事情1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23public class ProxyUtils {
public static StarService createProxy(StarService starService){
StarService o = (StarService)Proxy.newProxyInstance(ProxyUtils.class.getClassLoader(), starService.getClass().getInterfaces(), new InvocationHandler() {
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
String methodName = method.getName();
if("sing".equals(methodName)) {
System.out.println("sing a song: " + args[0]);
}else{
System.out.println("dance a dance");
}
if(method.getReturnType().equals(Void.TYPE)) {
return null;
}else{
return method.invoke(starService,args);
}
}
});
return o;
}
}
ClassLoader
类加载过程主要包括三个阶段:加载、链接和初始化。
- 加载:通过类的全限定名获取定义此类的二进制字节流,并将其转换为方法区中的运行时数据结构,在内存中生成一个代表该类的
java.lang.Class对象。 - 链接:包括验证、准备和解析三个步骤。验证确保被加载类的正确性;准备则为类变量分配内存并设置默认初始值;解析是将类、接口、字段和方法的符号引用转为直接引用的过程。
- 初始化:执行类构造器
<clinit>()方法的过程,对静态变量和静态代码块进行初始化。
Java 类加载器使用双亲委派模型来搜索类或资源。当一个类加载器收到类加载请求时,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器完成,每一层的类加载器都是如此,因此所有的类加载请求最终都会传送到顶层的启动类加载器。只有当父类加载器无法加载该类时,子类加载器才会尝试自己加载
Java 提供了三种内置的类加载器:
- Bootstrap ClassLoader:这是最顶层的类加载器,由本地代码实现,通常用于加载核心 JDK 类库(如
rt.jar)。 无法直接访问,显示为null - Extension ClassLoader:扩展类加载器,用来加载位于
$JAVA_HOME/jre/lib/ext目录下的 JAR 包。 (目前使用PlatformClassLoader,加载 JDK 提供的平台模块中的类,例如java.sql,java.xml,javax.*等模块化的平台类。) - Application ClassLoader:应用程序类加载器,负责加载用户类路径(ClassPath)上指定的类库
Java 提供了一些常用的方法来操作类加载器:
(1) loadClass(String name)
加载指定名称的类或接口。如果已经加载过,则直接返回对应的 Class 对象;如果没有,则按照双亲委派机制尝试加载。1
2
3
4
5try {
Class<?> clazz = ClassLoader.getSystemClassLoader().loadClass("com.example.MyClass");
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
(2) findClass(String name)
查找指定名称的类。默认实现会抛出 ClassNotFoundException 异常,通常需要自定义类加载器覆盖此方法以提供具体的类查找逻辑。
(3) defineClass(byte[] b, int off, int len)
将一个字节数组转换成一个类的 Class 对象。一般不直接调用,主要用于自定义类加载器。
(4) getResource(String name) 和 getResourceAsStream(String name)
用于查找资源文件。前者返回资源的 URL,后者返回资源的输入流。1
2URL resourceUrl = getClass().getClassLoader().getResource("config.properties");
InputStream inputStream = getClass().getClassLoader().getResourceAsStream("config.properties");
(5) getParent()
返回该类加载器的父类加载器。注意,Bootstrap ClassLoader 没有父类加载器,所以对于 Bootstrap ClassLoader 调用 getParent() 将返回 null。
4. 自定义类加载器
有时我们需要根据特定的需求来自定义类加载器。可以通过继承 java.lang.ClassLoader 并重写 findClass 方法来实现。1
2
3
4
5
6
7
8
9
10
11
12
13public class MyClassLoader extends ClassLoader {
protected Class<?> findClass(String name) throws ClassNotFoundException {
byte[] classData = loadClassData(name); // 实现类数据加载逻辑
return defineClass(name, classData, 0, classData.length);
}
private byte[] loadClassData(String className) {
// 加载类数据的逻辑
return new byte[0];
}
}
以下是实现自定义类加载器的基本步骤:
继承
ClassLoader- 创建一个类并继承
ClassLoader。
- 创建一个类并继承
重写
findClass()方法(遵从双亲委派机制)- 实现自定义的类加载逻辑。
调用
defineClass()方法- 将字节码转换为
Class对象。
class对象相同需要classloader相同,相同的classloader进行loadclass相同的类得到的class相同
- 将字节码转换为
1 | import java.io.ByteArrayOutputStream; |
线程上下文加载器
线程上下文类加载器(Thread Context ClassLoader)是 Java 提供的一种机制,允许开发者在线程中设置和获取类加载器。这种机制主要用于解决某些特定场景下类加载的问题,尤其是在复杂的类层次结构或模块化系统中。
线程上下文类加载器的作用
- 解决类加载器隔离问题:
- 在 Java 应用程序中,不同的类加载器可能会形成类加载器树,这导致了类加载器之间的隔离性。
- 例如,在 Web 容器或 OSGi 等环境中,不同应用或模块可能使用不同的类加载器来加载各自的类。在这种情况下,如果一个类需要加载另一个类加载器负责加载的类,则会遇到问题。
- 线程上下文类加载器提供了一种绕过双亲委派模型的方式,允许当前线程使用指定的类加载器来加载类。
- 支持框架和库的开发:
- 许多框架和库(如 JNDI、JDBC 驱动等)依赖于线程上下文类加载器来加载必要的类。
- 这些框架通常不知道具体的类加载器,因此它们可以利用线程上下文类加载器来动态地加载所需的类。
1 | public class ThreadContextClassLoaderExample { |
JVM
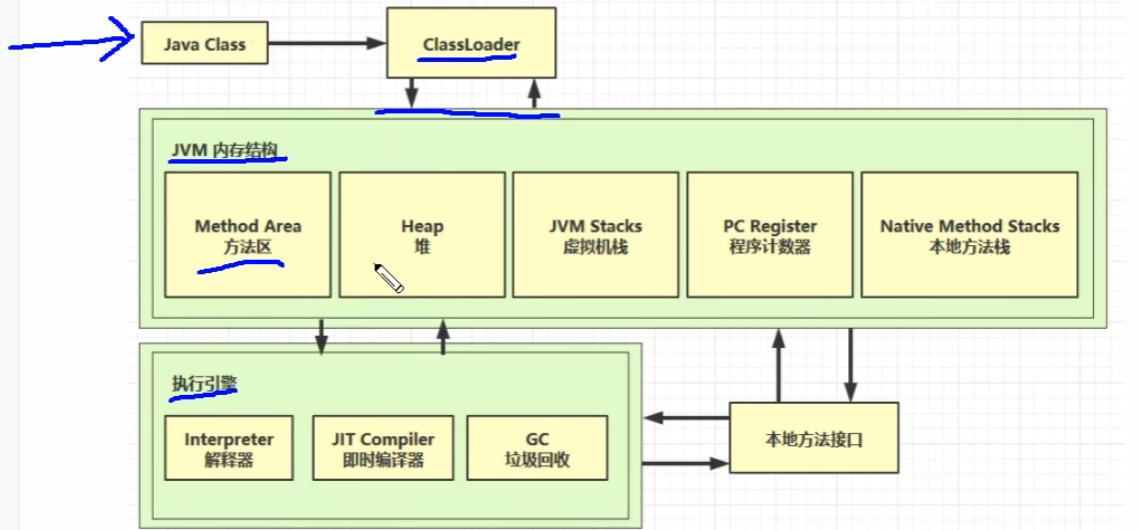
程序计数器: 线程私有
垃圾回收
判断对象可以回收
引用计数法
工作原理
- 初始化:每当创建一个新的对象时,该对象的引用计数器被初始化为1。
- 增加引用:每当有新的引用指向这个对象时(例如,将对象赋值给另一个变量),该对象的引用计数加1。
- 减少引用:每当某个引用不再指向该对象时(例如,变量超出作用域或重新赋值),该对象的引用计数减1。
- 回收内存:当一个对象的引用计数降为0时,表示没有其他引用指向该对象,这时就可以立即回收该对象所占用的内存。
缺点:
无法处理循环引用:如果两个或多个对象相互引用形成环状结构,则即使这些对象实际上已经不可达,它们的引用计数也不会变为0,导致内存泄漏。为了克服这个问题,一些语言引入了弱引用(weak references)或专门的循环检测机制。
多线程环境下的复杂性:在多线程环境下,对引用计数的修改需要同步操作,以防止竞态条件(race condition),这也增加了实现的复杂性和运行时的开销
可达性分析算法
可达性分析的基本思想是从一组被称为“根节点”(root set)的对象开始,遍历所有可以通过这些根节点直接或间接引用到的对象,并将它们标记为存活。未被标记的对象则被认为是不可达的,可以被安全地回收。
在命令行中输入
jps可以列出所有由当前用户启动的 Java 进程的基本信息
-q:仅输出 JVM 的进程 ID,不输出类名、jar 名等信息
-l:输出主类的完整包名;如果进程执行的是 jar 文件,则输出 jar 文件的完整路径
1 | jmap -dump:[live,]format=b,file=<filename>.hprof <pid> |
live:如果指定了这个选项,则只转储存活的对象;如果不指定,则转储所有对象。format=b:表示输出格式为二进制,默认就是二进制格式,所以通常省略不写。<filename>.hprof:指定生成的堆转储文件的名字。<pid>:目标Java进程的进程ID。
引用
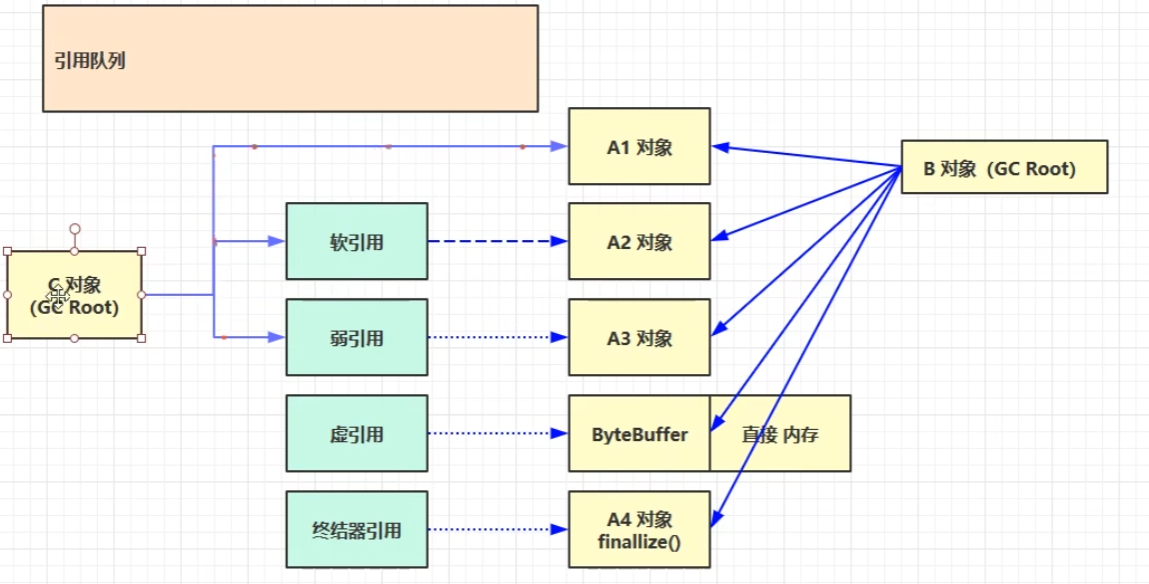
强引用 软引用 弱引用
软引用:垃圾回收时且内存不足时会被回收掉
虚引用 引用队列
终结器引用
- 强引用:日常编程中最常用的引用类型,几乎所有对象都是通过强引用创建的。
- 软引用:适用于缓存场景,当内存不足时,允许GC回收缓存数据。
- 弱引用:适合于需要自动清理的资源管理场景,例如监听器或回调函数列表中的对象。
- 虚引用:主要用于了解对象何时被垃圾回收,常用于做一些清理工作,比如清除本地内存、关闭文件等
回收算法
标记-清除
- 这是最基本的垃圾回收算法,分为两个阶段:标记和清除。在标记阶段,GC从根集合(GC Roots)开始遍历所有可达对象,并标记它们为存活对象;在清除阶段,未被标记的对象即被视为垃圾对象并被回收
- 优点是实现简单,适用于任何对象的内存管理;缺点是会产生内存碎片,因为删除了不可达对象后留下的空闲内存可能是不连续的,这可能导致后续大对象分配失败。
复制(Copying)算法:
- 复制算法将堆内存划分为两部分,每次只使用其中一部分。当这部分内存用完时,GC会暂停应用,将存活对象复制到另一部分内存中,并清空原内存区域
- 此算法避免了内存碎片问题,但代价是只能使用一半的内存空间,且对于存活率较高的对象效率较低。
复制算法将可用内存分为两部分,通常称为From Space和To Space。
程序只使用其中一部分(From Space),当这部分内存满后,GC会遍历From Space中的所有对象,将存活的对象复制到To Space,并且更新这些对象的引用指向新的位置。
清理完From Space后,它变为可用空间,而To Space则成为下次分配新对象的空间
这个过程有效地避免了内存碎片化的问题,因为每次清理后的内存区域都是连续的
标记-整理(Mark-Compact)算法:
- 标记-整理算法结合了标记-清除和复制的优点,在标记阶段与标记-清除类似,但在清除阶段,它会将存活的对象移动到内存的一端,然后清理掉端边界以外的空间
- 它解决了内存碎片问题,但需要移动存活对象,增加了回收的开销。
标记整理算法首先执行标记阶段,这与标记清除算法相同,即通过可达性分析找到所有存活的对象并进行标记。
接下来是整理阶段,在这个阶段,所有的存活对象会被移动到内存的一端,这样可以确保所有的空闲空间都在另一端,形成一个连续的块。
最后一步是对剩余的未被标记的部分进行清理,释放出连续的内存块
分代收集(Generational Collection)算法:
- 分代收集是一种基于对象生命周期特征优化的策略,将堆内存划分为年轻代(Young Generation)和老年代(Old Generation)。年轻代通常采用复制算法,而老年代则采用标记-清除或标记-整理算法
- 这种方法利用了大多数对象“朝生夕死”的特点,提高了垃圾回收的效率。
1. 堆内存分区
在分代垃圾回收中,堆内存通常被划分为三个主要区域:
- 年轻代(Young Generation):
- 主要用于存放新创建的对象。
- 进一步细分为一个 Eden 区和两个 Survivor 区(From 和 To)。
- 老年代(Old Generation):
- 存放的是经过多次垃圾回收后仍然存活的对象,这些对象被认为具有较长的生命期。
- 永久代/元空间(Permanent Generation/Metaspace):
- 在 Java 8 之前称为永久代,之后改为元空间,主要用于存储类的元数据、方法描述等信息,并不属于堆的一部分。
2. 分代垃圾回收过程
年轻代垃圾回收(Minor GC)
- Eden 区与 Survivor 区:当一个新的对象被创建时,它首先被分配到 Eden 区。如果 Eden 区满了,就会触发一次 Minor GC。
- 复制算法:Minor GC 使用这种算法来清理垃圾对象。在这个过程中,存活的对象会被复制到其中一个 Survivor 区(假设为 From),同时清除 Eden 区。
- Survivor 区交换:下一次 Minor GC 发生时,Eden 区和当前的 From Survivor 区中的存活对象会被复制到另一个 Survivor 区(To)。然后这两个角色会互换(即原来的 From 变成 To,反之亦然)。
- 晋升至老年代:当某个对象经历了若干次 Minor GC 后仍然存活(默认情况下是 15 次),它将被移动到老年代。
老年代垃圾回收(Major GC / Full GC)
- Full GC:当老年代也满时,将会触发 Full GC,这会同时清理年轻代和老年代。由于老年代中的对象通常是长期存活的,所以 Full GC 的频率远低于 Minor GC,但其执行成本更高。
- 标记-清除或标记-整理算法:对于老年代,可能会使用这两种算法之一。标记-清除算法简单地标识并删除不再使用的对象,但会导致内存碎片化;标记-整理算法则会在清理的同时压缩内存,减少碎片。
一些常用的 JVM 参数,用于调整分代垃圾回收行为:
- 年轻代相关参数:
-Xmn<size>:设置年轻代大小。-XX:SurvivorRatio=<ratio>:设置 Eden 区与 Survivor 区的比例(默认为 8:1)。-XX:MaxTenuringThreshold=<n>:设置对象晋升到老年代的最大年龄(默认为 15)。
- 老年代相关参数:
-Xms<size>:设置堆内存初始大小。-Xmx<size>:设置堆内存最大大小。
- 垃圾回收器选择:
-XX:+UseSerialGC:启用 Serial 收集器。-XX:+UseParallelGC:启用 Parallel 收集器。-XX:+UseConcMarkSweepGC:启用 CMS 收集器。-XX:+UseG1GC:启用 G1 收集器。-XX:+UseZGC:启用 ZGC 收集器。-XX:+UseShenandoahGC:启用 Shenandoah 收集器
(1) 基本 GC 日志
-XX:+PrintGCDetails:打印详细的垃圾回收日志。-XX:+PrintGC或-verbose:gc:打印简单的垃圾回收日志(仅显示每次 GC 的时间和类型)。
示例:1
java -XX:+PrintGCDetails -XX:+PrintGC MyApplication
输出示例:1
[GC (Allocation Failure) [PSYoungGen: 1024K->512K(2048K)] 1024K->768K(6144K), 0.0023456 secs] [Times: user=0.01 sys=0.00, real=0.00 secs]
(2) 打印时间戳
-XX:+PrintGCTimeStamps:在每条 GC 日志前添加时间戳(从 JVM 启动开始的时间)。-XX:+PrintGCDateStamps:在每条 GC 日志前添加实际日期和时间。
示例:1
java -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps MyApplication
输出示例:1
2023-03-29T12:00:00.000+0000: 1.234:
(3) 将 GC 日志写入文件
-Xloggc:<file>:将 GC 日志写入指定文件。- 结合其他参数可以生成更详细的日志文件。
示例:1
java -XX:+PrintGCDetails -Xloggc:gc.log MyApplication
2. 调整堆内存大小
-Xms<size>:设置 JVM 堆内存的初始大小。例如-Xms512m表示初始堆大小为 512MB。-Xmx<size>:设置 JVM 堆内存的最大大小。例如-Xmx2g表示最大堆大小为 2GB。
1 | java -Xms512m -Xmx2g MyApplication |
3. 调整年轻代和老年代比例
-XX:NewRatio=<ratio>:设置老年代与年轻代的比例。例如-XX:NewRatio=3表示老年代与年轻代的比例为 3:1。-XX:SurvivorRatio=<ratio>:设置 Eden 区与 Survivor 区的比例。例如-XX:SurvivorRatio=8表示 Eden 区与每个 Survivor 区的比例为 8:1。
1 | java -XX:NewRatio=3 -XX:SurvivorRatio=8 MyApplication |
4. 设置元空间大小
-XX:MetaspaceSize=<size>:设置元空间的初始大小。-XX:MaxMetaspaceSize=<size>:设置元空间的最大大小。
示例:1
java -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=256m MyApplication
5. 设置线程栈大小
-Xss<size>:设置每个线程的栈大小。例如-Xss512k表示每个线程的栈大小为 512KB。
1 | java -Xss512k MyApplication |
6. 启用特定垃圾回收器
-XX:+UseSerialGC:启用 Serial 收集器(单线程)。-XX:+UseParallelGC:启用 Parallel 收集器(多线程,关注吞吐量)。-XX:+UseConcMarkSweepGC:启用 CMS 收集器(低延迟,适合 Web 应用)。-XX:+UseG1GC:启用 G1 收集器(适合大内存应用)。-XX:+UseZGC:启用 ZGC 收集器(超低延迟,适合大内存)。-XX:+UseShenandoahGC:启用 Shenandoah 收集器(超低延迟)。
示例:1
java -XX:+UseG1GC MyApplication
7. 设置 GC 暂停时间目标
-XX:MaxGCPauseMillis=<time>:设置 GC 的最大暂停时间目标(单位为毫秒)。只对 G1 和 ZGC 有效。-XX:GCTimeRatio=<ratio>:设置 GC 时间与应用程序运行时间的比例。例如-XX:GCTimeRatio=19表示 GC 时间占总时间的 1/20。
1 | java -XX:+UseG1GC -XX:MaxGCPauseMillis=200 MyApplication |
8. 监控 JVM 性能
-XX:+HeapDumpOnOutOfMemoryError:当发生 OutOfMemoryError 时自动生成堆转储文件。-XX:HeapDumpPath=<path>:指定堆转储文件的路径。-XX:+PrintCommandLineFlags:打印 JVM 启动时的所有命令行参数。-XX:+PrintFlagsFinal:打印所有 JVM 参数及其最终值。
1 | java -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=./heapdump.hprof MyApplication |
9. 其他常用参数
-D<property>=<value>:设置系统属性。例如-Dfile.encoding=UTF-8。-server:启用服务器模式(默认情况下大多数 JVM 都会自动启用此模式)。-XX:+DisableExplicitGC:禁用通过System.gc()显式触发的垃圾回收。
1 | java -Dfile.encoding=UTF-8 -server -XX:+DisableExplicitGC MyApplication |
垃圾回收器
1. Serial 收集器
- 工作模式:单线程运行,适用于单核处理器或客户端应用。
- 应用场景:适合内存较小的应用程序,特别是那些对响应时间要求不高且资源有限的环境。
- 优点:实现简单,对于小型应用程序非常有效。
- 缺点:由于是单线程执行,在进行垃圾回收时会暂停所有其他的工作线程(Stop-The-World, STW),这会导致较长时间的停顿。
启用参数:1
-XX:+UseSerialGC
2. Parallel 收集器(也称为 Throughput Collector)
- 工作模式:多线程并行执行,适用于多核处理器环境下的服务器端应用。
- 关注点:提高吞吐量,即减少垃圾回收时间占总运行时间的比例。
- 年轻代:使用标记-复制算法。
- 老年代:使用标记-整理算法。
- 优点:通过并行处理提高了垃圾回收效率,减少了总的停顿时间。
- 缺点:仍然会有较长的停顿时间,特别是在老年代垃圾回收期间。
启用参数:1
-XX:+UseParallelGC
为了优化老年代的收集性能,可以加上 -XX:+UseParallelOldGC 来启用老年代的并行压缩。
3. CMS(Concurrent Mark Sweep)收集器
工作模式:专注于减少停顿时间,尽可能地与应用程序并发执行大部分垃圾回收工作。
主要阶段
:
- 初始标记(Initial Mark)
- 并发标记(Concurrent Mark)
- 再标记(Remark)
- 并发清除(Concurrent Sweep)
优点:尽量减少了应用程序的停顿时间。
缺点:虽然减少了停顿时间,但增加了总体的CPU占用率;无法压缩内存,可能导致内存碎片化问题;在某些情况下可能会导致“Concurrent Mode Failure”。
启用参数:1
-XX:+UseConcMarkSweepGC
4. G1(Garbage First)收集器
设计理念:旨在提供可预测的停顿时间和高吞吐量。G1 将堆划分为多个区域(Region),优先回收垃圾最多的区域。
主要特性
:
- 可以设置最大停顿时间目标。
- 支持大堆内存管理,并能有效避免内存碎片。
- 在进行垃圾回收时,尝试同时清理年轻代和老年代。
优点:相比 CMS,G1 提供了更好的停顿时间控制,并减少了内存碎片的问题。
缺点:配置相对复杂,可能需要更多的调优才能达到最佳效果。
启用参数:1
-XX:+UseG1GC
CAS与原子类
CAS(Compare-And-Swap,比较并交换)是一种重要的原子操作机制,广泛应用于多线程并发控制中。它允许在不使用锁的情况下实现对共享数据的同步访问,从而避免了传统锁机制可能带来的性能瓶颈和死锁问题。CAS操作包含三个参数:内存位置V、预期原值A和新值B。只有当内存位置V的值等于预期原值A时,才会将内存位置V的值更新为新值B,并返回操作是否成功的布尔值;否则,不做任何操作
在 Java 中,java.util.concurrent.atomic 包提供了基于 CAS 的原子类,例如 AtomicInteger、AtomicLong 等。这些类内部使用了 Unsafe 类提供的底层 CAS 操作1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47import java.util.concurrent.atomic.AtomicInteger;
public class CASCounter {
private AtomicInteger value = new AtomicInteger(0); // 使用 AtomicInteger 实现 CAS
// 增加计数器的值
public void increment() {
int current, next;
do {
current = value.get(); // 获取当前值
next = current + 1; // 计算下一个值
} while (!value.compareAndSet(current, next)); // 尝试 CAS 更新
}
// 获取当前计数器的值
public int getValue() {
return value.get();
}
public static void main(String[] args) throws InterruptedException {
CASCounter counter = new CASCounter();
// 创建多个线程并发增加计数器
Thread t1 = new Thread(() -> {
for (int i = 0; i < 1000; i++) {
counter.increment();
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 1000; i++) {
counter.increment();
}
});
// 启动线程
t1.start();
t2.start();
// 等待线程完成
t1.join();
t2.join();
// 输出最终计数器的值
System.out.println("Final counter value: " + counter.getValue());
}
}
乐观锁和悲观锁
乐观锁(Optimistic Locking)和悲观锁(Pessimistic Locking)是两种处理并发控制的策略,它们在如何管理数据冲突方面采取了不同的方法。
乐观锁则假设不会发生并发冲突,因此不会主动加锁。它允许所有事务同时读取并尝试修改数据,但在提交更改前检查是否有其他事务已经修改了相同的数据。如果有,则拒绝此次修改或根据具体业务逻辑进行重试或其他处理。
悲观锁假设会发生并发冲突,因此在操作数据时会直接加锁,防止其他事务对该数据进行修改直到当前事务完成。
使用悲观锁的方式可能是这样的:在处理订单时首先锁定库存记录,然后检查库存是否足够,若足够则扣减库存并提交事务释放锁;否则回滚事务并告知用户库存不足。
使用乐观锁的方式则是:在开始处理订单时不加锁,而是记录下当前库存记录的版本号或时间戳。在准备扣减库存时再次检查版本号或时间戳是否未变,若未变则扣减库存并更新版本号/时间戳;若有变化则表明期间有其他订单已修改了库存,此时可以选择重试或通知用户稍后再试。
原子操作类
- CAS 操作
CAS(Compare-And-Swap)是实现原子操作的核心机制。它是一个低级别的、硬件提供的原子指令,通常用于无锁算法中。一个典型的 CAS 操作包含三个参数:
- 内存位置 V:要更新的数据在内存中的地址。
- 预期值 A:期望在内存位置 V 处找到的值。
- 新值 B:如果内存位置 V 的当前值等于预期值 A,则将该位置的值更新为新值 B。
CAS 操作会检查内存位置 V 的当前值是否与预期值 A 相等。如果相等,则将内存位置 V 更新为新值 B,并返回成功;如果不相等,则不进行任何修改,并返回失败。这个过程是原子性的,意味着在同一时刻只能有一个线程成功执行 CAS 操作。
传统的
AtomicLong(以及AtomicInteger等)使用 CAS(Compare-And-Swap)操作来保证线程安全,但在高并发情况下,多个线程同时竞争同一个值时,CAS 操作可能会频繁失败并重试,导致性能下降。
LongAdder的设计目标是解决这个问题。它通过分段锁的思想将数据分散到多个变量中,减少了线程间的竞争,从而提高了性能。最终结果可以通过这些变量汇总得到。
- Java 内存模型 (JMM)
Java 内存模型定义了多线程环境下变量的可见性和顺序性规则。为了保证线程间共享变量的一致性,Java 提供了 volatile 关键字和同步块 (synchronized) 来确保变量的可见性。原子类内部使用了类似的技术来确保线程间的可见性,即使它们自身并不总是需要显式的同步块。
- Unsafe 类
Java 的原子类内部通常使用 sun.misc.Unsafe 类提供的本地方法来直接调用底层的 CAS 操作。虽然 Unsafe 类并不是官方推荐的 API,但它被广泛应用于高性能并发库中,如 java.util.concurrent 包内的实现。通过 Unsafe,开发者可以绕过 Java 的安全检查直接与操作系统交互,这使得它可以非常高效地执行 CAS 操作。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16import java.util.concurrent.atomic.AtomicInteger;
public class AtomicIntegerExample {
public static void main(String[] args) {
AtomicInteger atomicInt = new AtomicInteger(0);
// 原子递增
System.out.println("Initial value: " + atomicInt.get());
atomicInt.incrementAndGet(); // 自增1
System.out.println("After increment: " + atomicInt.get());
// 原子更新
atomicInt.updateAndGet(x -> x * 2); // 使用函数式更新
System.out.println("After update: " + atomicInt.get());
}
}
synchronized优化
偏向锁
偏向锁的设计初衷是为了消除无竞争情况下的同步原语,进一步提高程序的运行性能。当一个线程访问同步块并获取锁时,会在对象头中记录当前线程的ID,表示该线程占有了这个对象的锁。
当大多数情况下锁不仅不存在多线程竞争,而且总是由同一线程多次获得时,使用偏向锁可以减少不必要的同步操作。
特性:当没有其他线程尝试获取同一个锁时,持有偏向锁的线程不需要进行同步操作。
如果有其他线程尝试获取偏向锁,则会发生偏向锁撤销,锁可能会升级为轻量级锁。
轻量级锁
Java 轻量级锁是 JVM 提供的一种优化机制,旨在减少多线程环境下获取锁的开销。它主要通过使用 CAS(Compare-And-Swap)操作来避免传统锁带来的性能损耗,适用于线程竞争较少的情况。轻量级锁是 Java 锁机制的一部分,它可以动态升级为重量级锁以应对更高的竞争情况。
- 在线程交替执行同步块且存在轻微的竞争时,轻量级锁能够通过CAS(Compare-and-Swap)操作来避免线程阻塞和上下文切换。
- 特性
- 每个线程都有自己的栈帧,其中包含用于存储锁的记录空间(Lock Record)。当线程试图获取轻量级锁时,会将对象头中的Mark Word复制到该线程的锁记录中,并尝试通过CAS操作将对象头指向该线程的锁记录。
- 若多个线程同时请求轻量级锁且自旋一定次数后仍未成功获取锁,则锁将膨胀为重量级锁。
轻量级锁的工作原理
- 加锁过程
- 当一个线程尝试获取锁时,如果对象没有被锁定(锁标志位为“01”),JVM 会在当前线程的栈帧中创建一个称为 Lock Record 的空间,并将对象头中的 Mark Word 复制到这个 Lock Record 中。
- 然后,线程会尝试用 CAS 操作将对象头中的 Mark Word 更新为指向该线程 Lock Record 的指针。如果成功,则该线程获得了锁。
- 如果 CAS 操作失败,意味着另一个线程已经持有了锁,这时当前线程会自旋(忙等)一段时间,尝试重新获取锁。
- 解锁过程
- 当线程退出同步块时,会使用 CAS 操作尝试将对象头中的 Mark Word 恢复为其原始值(即从 Lock Record 中拷贝回来的 Displaced Mark Word)。
- 如果 CAS 操作成功,则表示没有其他线程尝试获取该锁,锁被成功释放。
- 如果 CAS 操作失败,说明有其他线程尝试获取过该锁,此时轻量级锁将会膨胀为重量级锁。
- 锁的升级
- 轻量级锁在遇到高竞争(即多个线程频繁尝试获取同一把锁)的情况下,可能会膨胀为重量级锁。这是因为持续的自旋等待会消耗大量的 CPU 资源。
- 一旦锁升级为重量级锁,后续试图获取锁的线程将进入阻塞状态,直到锁被释放。
- 适用场景
- 轻量级锁适用于线程竞争不激烈、锁占用时间较短的情况。在这种情况下,轻量级锁能够通过 CAS 操作和自旋来避免线程的阻塞和上下文切换,从而提高程序的并发性能。
- 对于锁竞争较为激烈的场景,建议使用 ReentrantLock 或者其他的高级同步机制,因为这些机制提供了更灵活的锁管理和更好的性能表现。
重量锁
重量级锁通过操作系统提供的互斥量(mutex)来实现线程间的同步,这种锁会让线程调用者进入阻塞状态,并被操作系统挂起。
在高竞争环境下,即多个线程频繁争夺同一资源时,重量级锁能够确保数据的一致性和完整性。
特性
- 锁住的线程会被挂起直到锁被释放,此时其他等待的线程才有可能获取锁。
- 由于涉及用户态到内核态的切换以及线程的挂起和唤醒,重量级锁的开销较大。
锁膨胀
锁膨胀(Lock Escalation)在Java中通常指的是synchronized关键字背后的锁机制随着竞争条件的变化而动态升级的过程。具体来说,在Java虚拟机(JVM)中,锁的状态可以经历从无锁状态到偏向锁、轻量级锁,最后到重量级锁的转变过程。这个过程称为锁膨胀或锁升级,并且它是一个单向的过程,即锁只能从低级别向高级别升级,不能降级。
锁膨胀的具体过程:
- 无锁状态:当对象刚创建时,没有线程尝试获取该对象上的锁,此时处于无锁状态。
- 偏向锁状态:当第一个线程尝试获取对象上的锁时,JVM会将锁设置为偏向锁,并记录下持有偏向锁的线程ID。如果之后还是同一个线程访问,则不需要再次进行加锁操作,直接进入同步块执行代码。偏向锁的目标是减少无实际竞争情况下的锁获取成本。
- 轻量级锁状态:如果有第二个线程尝试获取已经被偏向锁持有的对象的锁时,偏向锁会升级为轻量级锁。轻量级锁使用CAS(Compare and Swap)操作来尝试获取锁,以减少锁的竞争和系统的开销。轻量级锁适用于多个线程交替执行同步块的情况。
- 重量级锁状态:当多个线程长时间竞争同一个对象的锁时,轻量级锁会升级为重量级锁。重量级锁采用操作系统的互斥量(Mutex)来实现,确保线程的安全性。在这种状态下,JVM会创建一个等待队列,将等待获取锁的线程挂起在队列中。重量级锁会导致较大的性能开销,因为它涉及到用户态与内核态之间的切换。
锁膨胀的设计目的是为了优化多线程环境下的性能。通过这种方式,JVM可以根据不同的并发场景自动调整锁的状态,从而减少不必要的性能损耗。例如,在几乎没有竞争的情况下,偏向锁可以提供很好的性能;而在有少量竞争的情况下,轻量级锁可以通过自旋避免阻塞,提高效率;只有在高竞争的情况下,才会升级为重量级锁。这种机制使得synchronized在大多数情况下都能够高效运行。
其他优化
- 减少上锁时间
- 减少锁的颗粒度 使用concurrentHashMap
- 锁粗化 多次循环进入同步块不如在同步块内进行循环
- 锁消除
- 读写分离
JUC
创建线程
1. 继承 Thread 类
(1) 基本原理
通过继承 Thread 类并重写 run() 方法,调用 start() 方法启动线程。
(2) 示例代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16class MyThread extends Thread {
public void run() {
System.out.println("Thread running: " + Thread.currentThread().getName());
}
}
public class Main {
public static void main(String[] args) {
MyThread thread1 = new MyThread();
MyThread thread2 = new MyThread();
thread1.start(); // 启动线程
thread2.start(); // 启动线程
}
}
(3) 优点
- 简单直观,易于理解。
(4) 缺点
Java 不支持多重继承,如果一个类已经继承了其他类,则无法再继承
Thread。2. 实现
Runnable接口
(1) 基本原理
通过实现 Runnable 接口并实现 run() 方法,将 Runnable 对象传递给 Thread 构造器来启动线程。
(2) 示例代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16class MyRunnable implements Runnable {
public void run() {
System.out.println("Runnable running: " + Thread.currentThread().getName());
}
}
public class Main {
public static void main(String[] args) {
Thread thread1 = new Thread(new MyRunnable());
Thread thread2 = new Thread(new MyRunnable());
thread1.start(); // 启动线程
thread2.start(); // 启动线程
}
}
(3) 优点
- 更灵活:可以避免因为继承
Thread而导致的多重继承问题。 - 适合资源共享(多个线程共享同一个
Runnable实例)。
(4) 缺点
- 需要显式地将
Runnable对象传递给Thread。
3. 使用 Callable 和 FutureTask
(1) 基本原理
Callable 接口类似于 Runnable,但它可以返回结果,并且可以抛出异常。FutureTask 是一个包装类,用于管理 Callable 的执行结果。
(2) 示例代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27import java.util.concurrent.Callable;
import java.util.concurrent.FutureTask;
class MyCallable implements Callable<Integer> {
public Integer call() throws Exception {
System.out.println("Callable running: " + Thread.currentThread().getName());
return 42; // 返回计算结果
}
}
public class Main {
public static void main(String[] args) throws Exception {
FutureTask<Integer> futureTask1 = new FutureTask<>(new MyCallable());
FutureTask<Integer> futureTask2 = new FutureTask<>(new MyCallable());
Thread thread1 = new Thread(futureTask1);
Thread thread2 = new Thread(futureTask2);
thread1.start();
thread2.start();
// 获取线程执行结果
System.out.println("Result from thread1: " + futureTask1.get());
System.out.println("Result from thread2: " + futureTask2.get());
}
}
(3) 优点
- 可以返回结果。
- 可以捕获线程中的异常。
- 适合需要获取线程执行结果的场景。
(4) 缺点
- 相比
Runnable,代码稍微复杂一些。
4. 使用线程池(推荐)
(1) 基本原理
Java 提供了 ExecutorService 接口和 Executors 工厂类,用于管理和复用线程,避免频繁创建和销毁线程带来的开销。
(2) 示例代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
class Task implements Runnable {
private String name;
public Task(String name) {
this.name = name;
}
public void run() {
System.out.println("Executing task: " + name + " in thread: " + Thread.currentThread().getName());
}
}
public class Main {
public static void main(String[] args) {
ExecutorService executor = Executors.newFixedThreadPool(3); // 创建固定大小的线程池
for (int i = 0; i < 5; i++) {
executor.submit(new Task("Task-" + i));
}
executor.shutdown(); // 关闭线程池
}
}
(3) 优点
- 高效:线程池可以复用线程,减少线程创建和销毁的开销。
- 灵活:可以设置线程池大小、任务队列等。
- 易于管理:提供更高级的任务调度和生命周期管理功能。
(4) 缺点
- 初学者可能觉得使用线程池的 API 比较复杂。
5. 使用 Lambda 表达式(简化代码)
从 Java 8 开始,可以使用 Lambda 表达式进一步简化线程的创建和使用。
(1) 示例代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17public class Main {
public static void main(String[] args) {
// 使用 Lambda 表达式实现 Runnable
Thread thread1 = new Thread(() ->
System.out.println("Lambda thread running: " + Thread.currentThread().getName())
);
// 使用 Lambda 表达式提交任务到线程池
ExecutorService executor = Executors.newSingleThreadExecutor();
executor.submit(() ->
System.out.println("Lambda task running: " + Thread.currentThread().getName())
);
thread1.start();
executor.shutdown();
}
}
(2) 优点
- 简洁:减少了样板代码。
- 易读:代码更加紧凑。
6. 总结与选择建议
| 方法 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
继承 Thread 类 | 简单任务,快速验证 | 简单直观 | 不能多重继承 |
实现 Runnable 接口 | 多线程共享资源 | 灵活,避免多重继承限制 | 需要显式传递 Runnable |
使用 Callable 和 FutureTask | 需要返回结果或处理异常的任务 | 支持返回值和异常处理 | 代码稍微复杂 |
| 使用线程池 | 长时间运行的任务,或者需要高效管理线程的场景 | 高效,易于管理 | API 较复杂 |
| 使用 Lambda 表达式 | 简化代码,尤其是在线程池中 | 代码简洁 | 依赖 Java 8+ |

Syncronized优化原理
synchronized 的底层实现依赖于 JVM 提供的监视器锁(Monitor)\机制,而监视器锁最终映射到操作系统提供的*互斥锁(Mutex Lock)*。具体来说,synchronized 的工作原理分为以下几个阶段:
(1) Monitor(监视器)
- 每个 Java 对象都有一个与之关联的监视器(Monitor),也称为“内置锁”或“监视器锁”。
- 监视器的作用是确保同一时刻只有一个线程能够持有该锁并执行同步代码。
(2) 对象头中的 Mark Word
- 在 HotSpot 虚拟机中,每个 Java 对象都有一个对象头(Object Header),其中包含一个
Mark Word。 Mark Word用来存储对象的元信息,例如哈希码、GC 分代年龄、锁状态等。- 当线程尝试获取锁时,
Mark Word的内容会动态变化,表示锁的状态(无锁、偏向锁、轻量级锁、重量级锁)。
(3) 锁的升级机制
为了优化性能,synchronized 实现了锁的升级机制,从低开销的锁逐步升级到高开销的锁。锁的升级过程如下:
- 无锁状态:
- 初始状态下,对象没有被任何线程锁定。
- 偏向锁(Biased Locking):
- 如果某个线程多次进入同步代码块,JVM 会将锁偏向于该线程。
- 偏向锁通过在
Mark Word中记录线程 ID 来实现,避免每次加锁和解锁都需要 CAS(Compare-And-Swap)操作。 - 偏向锁适用于单线程访问同步代码块的场景。
- 轻量级锁(Lightweight Locking):
- 当有多个线程竞争同一个锁时,偏向锁会升级为轻量级锁。
- 轻量级锁使用自旋的方式尝试获取锁,减少线程上下文切换的开销。
- 如果自旋成功,则直接获取锁;如果自旋失败,则升级为重量级锁。
- 重量级锁(Heavyweight Locking):
- 当竞争激烈时,轻量级锁会升级为重量级锁。
- 重量级锁依赖于操作系统的互斥锁(Mutex Lock),会导致线程阻塞和唤醒,开销较大。
(4) 锁的释放
- 当线程退出同步代码块时,会释放锁。
- JVM 会根据锁的状态(偏向锁、轻量级锁、重量级锁)进行相应的处理,恢复对象头的
Mark Word状态。
| 特性 | synchronized | ReentrantLock |
|---|---|---|
| 实现方式 | JVM 内置关键字 | 显式锁,API 实现 |
| 锁优化 | 支持偏向锁、轻量级锁 | 不支持 |
| 公平性 | 非公平锁 | 支持公平锁 |
| 可中断性 | 不支持 | 支持 |
| 超时机制 | 不支持 | 支持 |
| 条件变量 | 不支持 | 支持(通过 Condition) |
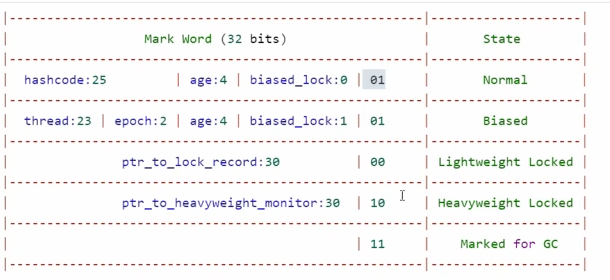
ReentrantLock
ReentrantLock 是 Java 提供的一种可重入的互斥锁,它位于 java.util.concurrent.locks 包中,是 Lock 接口的一个实现类。相比于 synchronized 关键字,ReentrantLock 提供了更灵活、更强大的锁机制,适用于复杂的并发场景。
可重入锁(Reentrant Lock) 指的是一个线程可以多次获取同一个锁而不被自己阻塞。这意味着如果一个线程已经持有了某个锁,并尝试再次获取该锁,则该操作会成功,而不是导致死锁。每次获取锁时,锁内部的计数器会增加;每次释放锁时,计数器会减少;只有当计数器归零时,锁才会真正被释放,允许其他线程获取。
可重入
1 | import java.util.concurrent.locks.ReentrantLock; |
可打断
“可打断”(Interruptible)指的是线程在等待某种资源或处于阻塞状态时,是否能够响应中断请求并进行相应的处理.当一个线程处于不可打断的状态下(如通过某些同步机制等待获取锁),它将不会响应中断信号;而在可打断状态下,线程可以捕获到中断请求,并根据应用逻辑决定如何处理这个中断.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51import java.util.concurrent.locks.ReentrantLock;
public class InterruptibleLockExample {
private final ReentrantLock lock = new ReentrantLock();
public void performTask() throws InterruptedException {
try {
System.out.println(Thread.currentThread().getName() + " is trying to acquire the lock.");
// 尝试获取锁,但是可以响应中断
lock.lockInterruptibly();
try {
System.out.println(Thread.currentThread().getName() + " has acquired the lock.");
// 模拟任务处理
Thread.sleep(5000);
} finally {
lock.unlock();
}
} catch (InterruptedException e) {
System.out.println(Thread.currentThread().getName() + " was interrupted while waiting for the lock.");
// 处理中断,通常这里需要做一些清理工作
Thread.currentThread().interrupt(); // 重新设置中断标志
}
}
public static void main(String[] args) throws InterruptedException {
InterruptibleLockExample example = new InterruptibleLockExample();
Thread t1 = new Thread(() -> {
try {
example.performTask();
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "Worker-1");
Thread t2 = new Thread(() -> {
try {
Thread.sleep(1000); // 让 t1 先开始尝试获取锁
example.performTask();
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "Worker-2");
t1.start();
t2.start();
Thread.sleep(2000); // 主线程等待一段时间后中断 t2
t2.interrupt();
}
}
尝试获取锁
boolean tryLock()- 尝试获取锁。如果锁可用,则立即获取并返回
true;否则返回false。
- 尝试获取锁。如果锁可用,则立即获取并返回
boolean tryLock(long timeout, TimeUnit unit)- 尝试在指定时间内获取锁。如果在超时前获取到锁,则返回
true;否则返回false。
- 尝试在指定时间内获取锁。如果在超时前获取到锁,则返回
公平锁
ReentrantLock 默认是非公平锁。也就是说,当多个线程竞争锁时,默认情况下新来的线程可能会直接插队获取锁,而不需要严格按照线程等待的顺序(FIFO 队列)来分配锁。
公平锁与非公平锁的区别
- 公平锁(Fair Lock)
- 公平锁会按照线程请求锁的顺序(即 FIFO 队列)来分配锁。
- 这种方式可以避免线程饥饿问题,但可能会导致性能下降,因为线程切换的开销较高。
- 非公平锁(Non-Fair Lock)
- 非公平锁允许插队,即新来的线程可以直接尝试获取锁,而不需要排队。
- 这种方式减少了线程上下文切换的开销,提高了吞吐量,但在高并发场景下可能导致某些线程长时间无法获取锁(饥饿问题)。
与条件变量
在并发编程中,条件变量是一种用于线程间协调的机制。它允许一个或多个线程等待某个条件变为真,而不是忙等(busy-waiting)。在Java中,Condition 接口由 ReentrantLock 类提供支持,每个 ReentrantLock 可以创建多个 Condition 实例,从而实现更加灵活的线程控制。
Condition 接口的主要方法
- await():使当前线程等待,并释放锁。直到其他线程调用
signal()或signalAll()方法唤醒它。 - signal():唤醒一个等待该条件的线程。如果有多个线程在等待,则选择其中的一个。
- signalAll():唤醒所有等待该条件的线程。
- awaitUninterruptibly():类似于
await(),但是不会响应中断。 - awaitNanos(long nanosTimeout)、awaitUntil(Date deadline):带超时的等待方法。
1 | import java.util.concurrent.locks.Condition; |
volatile原理
volatile 是 Java 中的一个关键字,用于修饰变量,它提供了一种比锁更轻量级的同步机制。尽管 volatile 并不能替代 synchronized 关键字所提供的所有功能,但在某些特定场景下,它可以有效地保证线程间的可见性和有序性。
工作原理
- 可见性:当一个线程对一个
volatile变量进行写操作时,会将该变量立即刷新到主内存中。而当其他线程读取这个volatile变量时,它们会被强制从主内存中重新读取这个变量的最新值,而不是使用自己工作内存中的缓存副本。这就确保了所有线程都能看到最新的变量值。 - 禁止指令重排序优化:Java 编译器和处理器可以对指令进行重排序以提高执行效率。然而,这种重排序可能会导致多线程环境下的程序出现意料之外的行为。
volatile变量可以防止编译器对涉及该变量的操作进行指令重排序,从而保持代码的预期执行顺序。
虽然 volatile 和原子类(如 AtomicInteger)都提供了线程安全的操作,但它们之间存在一些关键差异:
- 原子性:
volatile只能保证变量的可见性和有序性,不能保证复合操作(比如增加、减少)的原子性。而原子类通过使用 CAS(比较并交换)等硬件级别的原子操作来保证操作的原子性。 - 性能:由于
volatile不需要像锁那样复杂的开销,因此在只涉及简单状态更新的情况下,它的性能通常优于基于锁的解决方案。但是,在需要进行复杂的状态转换或需要保证原子性的场景下,原子类可能是更好的选择。
1 | public class FlagExample { |
volatile 适用于以下场景:
- 变量的写入不依赖于其当前值。
- 变量不需要与其他状态变量共同参与不变约束。
- 对变量的访问都是原子操作(例如,简单的布尔标志)。
自定义线程池
1 | class ThreadPool { |
使用JDK提供的方法1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47import java.util.concurrent.*;
public class ThreadPoolExample {
public static void main(String[] args) {
// 核心线程数
int corePoolSize = 2;
// 最大线程数
int maximumPoolSize = 4;
// 空闲线程存活时间
long keepAliveTime = 10;
// 时间单位
TimeUnit unit = TimeUnit.SECONDS;
// 任务队列
BlockingQueue<Runnable> workQueue = new LinkedBlockingQueue<>(2);
// 线程工厂
ThreadFactory threadFactory = Executors.defaultThreadFactory();
// 拒绝策略
RejectedExecutionHandler handler = new ThreadPoolExecutor.AbortPolicy();
// 创建线程池
ThreadPoolExecutor executor = new ThreadPoolExecutor(
corePoolSize,
maximumPoolSize,
keepAliveTime,
unit,
workQueue,
threadFactory,
handler
);
// 提交任务
for (int i = 0; i < 10; i++) {
final int taskId = i;
executor.submit(() -> {
System.out.println("Task " + taskId + " is running on thread " + Thread.currentThread().getName());
try {
Thread.sleep(2000); // 模拟任务执行
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
}
// 关闭线程池
executor.shutdown();
}
}1
2
3
4
5
6
7
8
9
10
11
12ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(), new ThreadPoolExecutor.DiscardPolicy());
for (int i = 0; i < 10; i++) {
Future<Integer> submit = threadPoolExecutor.submit(new MyCallable());
try {
System.out.println(submit.get());
} catch (InterruptedException e) {
throw new RuntimeException(e);
} catch (ExecutionException e) {
throw new RuntimeException(e);
}
}

- corePoolSize:
- 核心线程数,即线程池中始终保持的最小线程数量。
- 即使这些线程处于空闲状态,也不会被销毁(除非设置了
allowCoreThreadTimeOut)。
- maximumPoolSize:
- 线程池允许的最大线程数。
- 当任务队列已满且当前线程数小于
maximumPoolSize时,线程池会创建新线程来处理任务。
- keepAliveTime:
- 空闲线程的存活时间。
- 如果线程数超过
corePoolSize,多余的空闲线程会在空闲一段时间后被回收。
- unit:
keepAliveTime的时间单位,例如TimeUnit.SECONDS。
- workQueue:
- 任务队列,用于保存等待执行的任务。
- 常见实现包括:
ArrayBlockingQueue:有界队列。LinkedBlockingQueue:无界队列。SynchronousQueue:不存储任务,直接交给线程执行。
- threadFactory:
- 创建线程的工厂,用于自定义线程的名称、优先级等属性。
- 默认使用
Executors.defaultThreadFactory()。
- handler:
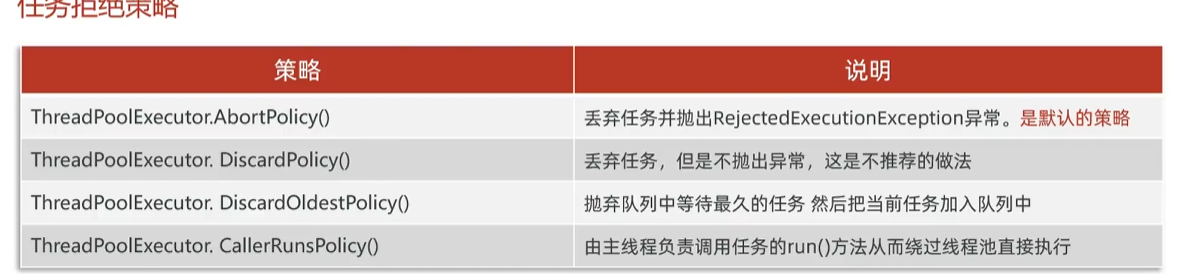
- 拒绝策略,当线程池无法处理新任务时(例如线程池已满且任务队列已满),会调用此策略。
- 常见实现包括:
AbortPolicy:抛出RejectedExecutionException异常。CallerRunsPolicy:由调用线程(提交任务的线程)执行该任务。DiscardPolicy:直接丢弃任务。DiscardOldestPolicy:丢弃队列中最旧的任务,然后尝试重新提交新任务。
3. 线程池的工作原理
- 任务提交:
- 当一个任务被提交到线程池时,线程池会根据当前线程数和任务队列的状态决定如何处理任务。
- 任务分配逻辑:
- 如果当前线程数小于
corePoolSize,即使有空闲线程,也会创建新线程来执行任务。 - 如果当前线程数等于或大于
corePoolSize,任务会被放入任务队列中等待。 - 如果任务队列已满且当前线程数小于
maximumPoolSize,线程池会创建新线程来执行任务。 - 如果任务队列已满且当前线程数等于
maximumPoolSize,则触发拒绝策略。
- 如果当前线程数小于
- 线程回收:
- 如果线程数超过
corePoolSize,多余的空闲线程会在空闲一段时间(keepAliveTime)后被回收
- 如果线程数超过
Executors
- 创建固定大小的线程池 -
newFixedThreadPool
该方法返回一个固定大小的线程池,适用于需要限制并发线程数的场景。
示例代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class FixedThreadPoolExample {
public static void main(String[] args) {
// 创建一个固定大小为3的线程池
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(3);
for (int i = 0; i < 5; i++) {
int taskId = i;
fixedThreadPool.submit(() -> {
System.out.println("Task " + taskId + " is running on thread " + Thread.currentThread().getName());
try {
Thread.sleep(2000); // 模拟任务执行时间
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
}
// 关闭线程池
fixedThreadPool.shutdown();
}
}
- 线程池中的线程数量是固定的。
- 如果所有线程都在忙,新的任务将等待直到有空闲线程可用。
- 创建单线程化的线程池 -
newSingleThreadExecutor
该方法返回一个只有一个工作线程的线程池,适用于需要保证顺序执行任务的场景。
示例代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class SingleThreadExecutorExample {
public static void main(String[] args) {
// 创建一个单线程化的线程池
ExecutorService singleThreadExecutor = Executors.newSingleThreadExecutor();
for (int i = 0; i < 5; i++) {
int taskId = i;
singleThreadExecutor.submit(() -> {
System.out.println("Task " + taskId + " is running on thread " + Thread.currentThread().getName());
try {
Thread.sleep(2000); // 模拟任务执行时间
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
}
// 关闭线程池
singleThreadExecutor.shutdown();
}
}
- 所有提交的任务按照提交顺序依次执行。
- 即使发生故障,也会重新创建一个线程来替代原来的线程继续处理后续任务。
- 创建一个会根据需要创建新线程的线程池 -
newCachedThreadPool
该方法返回一个可根据需要创建新线程的线程池,适用于执行大量短期异步任务的场景。
示例代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class CachedThreadPoolExample {
public static void main(String[] args) {
// 创建一个缓存线程池
ExecutorService cachedThreadPool = Executors.newCachedThreadPool();
for (int i = 0; i < 5; i++) {
final int taskId = i;
cachedThreadPool.submit(() -> {
System.out.println("Task " + taskId + " is running on thread " + Thread.currentThread().getName());
try {
Thread.sleep(2000); // 模拟任务执行时间
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
}
// 关闭线程池
cachedThreadPool.shutdown();
}
}
- 线程池可以根据需要创建新线程,并在空闲60秒后回收未使用的线程。
- 适合执行大量短期异步任务的应用程序。
- 创建支持定时及周期性任务执行的线程池 -
newScheduledThreadPool
该方法返回一个支持定时和周期性任务执行的线程池。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
public class ScheduledThreadPoolExample {
public static void main(String[] args) {
// 创建一个支持定时及周期性任务执行的线程池
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(3);
// 定时执行任务,延迟2秒后执行
scheduledThreadPool.schedule(() -> {
System.out.println("This task is run after a delay of 2 seconds");
}, 2, TimeUnit.SECONDS);
// 周期性执行任务,初始延迟2秒后开始执行,之后每隔3秒执行一次
scheduledThreadPool.scheduleAtFixedRate(() -> {
System.out.println("This task is run periodically every 3 seconds");
}, 2, 3, TimeUnit.SECONDS);
// 记得关闭线程池
// scheduledThreadPool.shutdown(); 在实际应用中,可能需要在适当的时候调用shutdown()来关闭线程池
}
}
- 支持延迟执行任务或周期性执行任务。
schedule()方法用于一次性延迟执行任务。scheduleAtFixedRate()方法用于周期性执行任务。
- 使用自定义线程工厂
你可以通过提供自定义的 ThreadFactory 来定制线程的创建过程,比如设置线程名称、优先级等。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28import java.util.concurrent.*;
public class CustomThreadFactoryExample {
public static void main(String[] args) {
ThreadFactory customThreadFactory = new ThreadFactory() {
public Thread newThread(Runnable r) {
return new Thread(r, "CustomThread-" + System.currentTimeMillis());
}
};
ExecutorService executorService = Executors.newFixedThreadPool(2, customThreadFactory);
for (int i = 0; i < 5; i++) {
int taskId = i;
executorService.submit(() -> {
System.out.println("Task " + taskId + " is running on thread " + Thread.currentThread().getName());
try {
Thread.sleep(2000); // 模拟任务执行时间
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
}
executorService.shutdown();
}
}
自定义线程工厂允许更灵活地控制线程的创建过程。

线程池关闭方法
shutdown()
- 描述:该方法不会立即强制关闭线程池,而是首先停止接收新的任务,并尝试完成已经提交的任务。
- 行为
- 已经提交到线程池中的任务将继续执行直至完成。
- 此方法调用后,如果尝试向线程池提交新任务,则会根据线程池的拒绝策略处理(通常是抛出
RejectedExecutionException)。
示例代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class ShutdownExample {
public static void main(String[] args) throws InterruptedException {
ExecutorService executor = Executors.newFixedThreadPool(2);
for (int i = 0; i < 5; i++) {
int taskId = i;
executor.submit(() -> {
System.out.println("Task " + taskId + " is running on thread " + Thread.currentThread().getName());
try {
Thread.sleep(2000); // 模拟任务执行时间
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
}
System.out.println("Shutting down the executor...");
executor.shutdown(); // 发出关闭信号
// 等待所有任务完成
if (!executor.awaitTermination(60, TimeUnit.SECONDS)) {
System.out.println("Some tasks are still running");
} else {
System.out.println("All tasks finished.");
}
}
}
shutdownNow()
- 描述:尝试立即停止所有正在执行的任务,并暂停处理等待的任务。
- 行为
- 它试图终止所有正在执行的任务,并返回一个等待执行的任务列表。
- 并不能保证能够立即停止正在执行的任务,因为任务可能无法响应中断。
示例代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27import java.util.List;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class ShutdownNowExample {
public static void main(String[] args) throws InterruptedException {
ExecutorService executor = Executors.newFixedThreadPool(2);
for (int i = 0; i < 5; i++) {
int taskId = i;
executor.submit(() -> {
try {
System.out.println("Task " + taskId + " is running on thread " + Thread.currentThread().getName());
Thread.sleep(2000); // 模拟任务执行时间
} catch (InterruptedException e) {
System.out.println("Task " + taskId + " was interrupted.");
Thread.currentThread().interrupt(); // 重新设置中断状态
}
});
}
System.out.println("Attempting to shutdown the executor now...");
List<Runnable> notExecutedTasks = executor.shutdownNow(); // 尝试立即关闭
System.out.println("Number of tasks that will not be executed: " + notExecutedTasks.size());
}
}
awaitTermination(long timeout, TimeUnit unit)
- 描述:阻塞当前线程直到线程池中的所有任务都已完成执行,或者超时发生,或者当前线程被中断。
- 行为
- 通常与
shutdown()方法一起使用,以确保所有任务都在程序退出之前完成。 - 返回值为
true表示所有任务都已经完成;返回false则表示由于超时而未完成。
- 通常与
可以通过调用 isShutdown() 方法来检查线程池是否已经被标记为关闭。此外,isTerminated() 可用于判断线程池是否已经完全终止(即所有任务都已完成)
线程安全集合类
线程安全的集合类是用于在多线程环境中安全地存储和操作数据的工具。这些集合类通过内部的同步机制或无锁算法(如 CAS)来保证线程安全。

Vector 和 Hashtable
这两个类是早期 Java 提供的线程安全集合类,但现在已被更高效的替代品取代。
Vector
- 线程安全的动态数组,类似于
ArrayList,但所有操作都通过synchronized加锁。 - 性能较低,推荐使用
CopyOnWriteArrayList或Collections.synchronizedList()替代。
Hashtable
- 线程安全的哈希表,类似于
HashMap,但所有操作都通过synchronized加锁。 - 推荐使用
ConcurrentHashMap替代。
同步包装类(Collections.synchronizedXxx() 方法)
Java 的 Collections 类提供了一组静态方法,可以将普通的非线程安全集合包装成线程安全的集合。
示例代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18import java.util.*;
public class SynchronizedCollectionsExample {
public static void main(String[] args) {
// 创建一个线程安全的 ArrayList
List<String> synchronizedList = Collections.synchronizedList(new ArrayList<>());
// 创建一个线程安全的 HashMap
Map<String, String> synchronizedMap = Collections.synchronizedMap(new HashMap<>());
// 使用时仍需手动加锁以保证复合操作的线程安全
synchronized (synchronizedList) {
if (!synchronizedList.isEmpty()) {
synchronizedList.remove(0);
}
}
}
}
特点
- 内部通过
synchronized关键字实现同步。 - 简单易用,但性能较差,因为所有操作都需要竞争同一把锁。
- 复合操作(如迭代、条件检查等)需要外部手动加锁。
Concurrent 系列集合
java.util.concurrent 包中提供了多个高性能的线程安全集合类,它们基于分段锁(Segment Lock)或其他无锁算法(如 CAS),性能优于传统的同步集合。
常用类
ConcurrentHashMap:- 线程安全的
Map实现。 - 支持高并发访问,性能优于
Hashtable。 - 内部通过分段锁或 CAS 操作实现线程安全。
- 线程安全的
ConcurrentSkipListMap:- 线程安全的有序
Map实现。 - 基于跳表(Skip List)实现。
- 线程安全的有序
ConcurrentSkipListSet:- 线程安全的有序
Set实现。
- 线程安全的有序
ConcurrentLinkedQueue:- 线程安全的无界非阻塞队列。
- 基于链表实现,支持高并发。
ConcurrentLinkedDeque:- 线程安全的双端队列。
1 | import java.util.concurrent.ConcurrentHashMap; |
特点
- 高性能,支持高并发。
- 提供了丰富的原子操作(如
computeIfAbsent、merge等)。 - 适用于高并发场景。
阻塞队列(Blocking Queue)
阻塞队列是线程安全的队列,当队列为空或满时,会阻塞线程直到满足条件。
常用类
ArrayBlockingQueue:- 有界阻塞队列,基于数组实现。
- 需要指定容量。
LinkedBlockingQueue:- 无界或有界阻塞队列,基于链表实现。
- 默认情况下是无界的(容量为
Integer.MAX_VALUE)。
PriorityBlockingQueue:- 线程安全的优先级队列。
- 元素按优先级排序。
SynchronousQueue:- 不存储元素的阻塞队列。
- 每次插入操作必须等待一个对应的移除操作。
DelayQueue:- 用于延迟处理元素的阻塞队列。
- 元素只有在延迟时间到期后才能被取出。
示例代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
public class BlockingQueueExample {
public static void main(String[] args) throws InterruptedException {
BlockingQueue<String> queue = new ArrayBlockingQueue<>(2);
// 生产者线程
Thread producer = new Thread(() -> {
try {
queue.put("A");
queue.put("B");
queue.put("C"); // 队列满时阻塞
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
// 消费者线程
Thread consumer = new Thread(() -> {
try {
System.out.println(queue.take());
System.out.println(queue.take());
System.out.println(queue.take()); // 队列空时阻塞
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
producer.start();
consumer.start();
producer.join();
consumer.join();
}
}
特点
- 适用于生产者-消费者模型。
- 提供了阻塞操作(如
put和take)。 - 可以控制队列的容量。
CopyOnWrite 系列集合
CopyOnWrite 系列集合适用于读多写少的场景,其核心思想是:每次修改时复制一份新的数据副本,从而避免读写冲突。
常用类
CopyOnWriteArrayList:- 线程安全的
List实现。 - 适用于读操作远多于写操作的场景。
- 线程安全的
CopyOnWriteArraySet:- 基于
CopyOnWriteArrayList实现的线程安全Set。
- 基于
示例代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17import java.util.List;
import java.util.concurrent.CopyOnWriteArrayList;
public class CopyOnWriteArrayListExample {
public static void main(String[] args) {
List<String> list = new CopyOnWriteArrayList<>();
// 添加元素
list.add("A");
list.add("B");
// 遍历(无需额外加锁)
for (String item : list) {
System.out.println(item);
}
}
}
特点
- 修改操作(如
add、remove)会创建数据副本,因此写操作成本较高。 - 读操作不需要加锁,性能高。
- 不适合频繁写入的场景。
| 集合类型 | 场景 | 特点 |
|---|---|---|
Collections.synchronizedXxx() | 简单线程安全需求 | 所有操作加锁,性能较低 |
Vector / Hashtable | 兼容旧代码 | 过时,不推荐 |
CopyOnWriteArrayList | 读多写少 | 写操作成本高,读操作无需加锁 |
ConcurrentHashMap | 高并发场景 | 高性能,支持原子操作 |
阻塞队列(如 ArrayBlockingQueue) | 生产者-消费者模型 | 提供阻塞操作,支持容量控制 |
FAQ
HashMap并发死链问题
HashMap 的底层实现是一个数组(桶)和链表/红黑树的结合。当发生哈希冲突时,多个键值对会被存储在同一个桶中,形成链表或红黑树。在多线程环境下,如果多个线程同时对 HashMap 进行写操作(如扩容或插入),可能会破坏链表的结构,导致链表形成环状结构(即死链)。
具体原因:
- 扩容时的并发问题
- 当
HashMap的容量不足时,会触发扩容操作(resize()方法),将旧数组中的元素重新分配到新数组中。 - 在多线程环境下,多个线程可能同时执行扩容操作,导致链表节点被错误地连接,形成环形链表。
- 当
- 链表插入时的并发问题
- 多个线程同时插入元素时,可能会导致链表节点的指针被错误地修改,从而形成环形链表。
一旦链表形成了环形结构,后续的读操作(如 get())会在遍历链表时陷入无限循环。
为了避免 HashMap 的并发死链问题,可以采取以下几种解决方案:
(1) 使用线程安全的集合类
- 使用ConcurrentHashMap替代HashMap
ConcurrentHashMap是专门为多线程环境设计的线程安全集合类。- 它通过分段锁(Segment Lock)或 CAS 操作来保证线程安全,避免了死链问题。
(2) 手动加锁
- 如果必须使用
HashMap,可以通过synchronized或显式锁(如ReentrantLock)来保护对其的修改操作。
(3) 使用 Collections.synchronizedMap() 包装
- 将
HashMap包装成线程安全的集合。
项目管理
Maven✨
Maven Getting Started Guide – Maven
黑马程序员Maven全套教程,maven项目管理从基础到高级,Java项目开发必会管理工具maven_哔哩哔哩_bilibili
项目中源码目录,资源文件夹目录等都是maven设置的
Maven 提倡使用一个共同的标准目录结构,Maven 使用约定优于配置的原则,大家尽可能的遵守这样的目录结构。如下所示:
| 目录 | 目的 |
|---|---|
| ${basedir} | 存放pom.xml和所有的子目录 |
| ${basedir}/src/main/java | 项目的java源代码 |
| ${basedir}/src/main/resources | 项目的资源,比如说property文件,springmvc.xml |
| ${basedir}/src/test/java | 项目的测试类,比如说Junit代码 |
| ${basedir}/src/test/resources | 测试用的资源 |
| ${basedir}/src/main/webapp/WEB-INF | web应用文件目录,web项目的信息,比如存放web.xml、本地图片、jsp视图页面 |
| ${basedir}/target | 打包输出目录 |
| ${basedir}/target/classes | 编译输出目录 |
| ${basedir}/target/test-classes | 测试编译输出目录 |
| Test.java | Maven只会自动运行符合该命名规则的测试类 |
| ~/.m2/repository | Maven默认的本地仓库目录位置 |
POM( Project Object Model,项目对象模型 ) 是 Maven 工程的基本工作单元,是一个XML文件,包含了项目的基本信息,用于描述项目如何构建,声明项目依赖,等等。
执行任务或目标时,Maven 会在当前目录中查找 POM。它读取 POM,获取所需的配置信息,然后执行目标。
POM 中可以指定以下配置:
- 项目依赖
- 插件
- 执行目标
- 项目构建 profile
- 项目版本
- 项目开发者列表
- 相关邮件列表信息
1 | <project xmlns = "http://maven.apache.org/POM/4.0.0" |
所有 POM 文件都需要 project 元素和三个必需字段:groupId,artifactId,version。
| 节点 | 描述 |
|---|---|
| project | 工程的根标签。 |
| modelVersion | 模型版本需要设置为 4.0。 |
| groupId | 这是工程组的标识。它在一个组织或者项目中通常是唯一的。例如,一个银行组织 com.companyname.project-group 拥有所有的和银行相关的项目。 |
| artifactId | 这是工程的标识。它通常是工程的名称。例如,消费者银行。groupId 和 artifactId 一起定义了 artifact 在仓库中的位置。 |
| version | 这是工程的版本号。在 artifact 的仓库中,它用来区分不同的版本。例如:com.company.bank:consumer-banking:1.0 com.company.bank:consumer-banking:1.1 |
依赖管理
1 | <dependencies> |
插件管理
1 | <build> |
其他常用元素
properties: 定义项目中的一些属性变量:1
2
3
4<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
repositories: 定义项目的依赖库:1
2
3
4
5
6<repositories>
<repository>
<id>central</id>
<url>https://repo.maven.apache.org/maven2</url>
</repository>
</repositories>
dependencyManagement: 用于管理依赖的版本,特别是在多模块项目中:1
2
3
4
5
6
7
8
9<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-core</artifactId>
<version>5.3.9</version>
</dependency>
</dependencies>
</dependencyManagement>
profiles: 用于定义不同的构建配置,可以根据不同的环境进行构建:1
2
3
4
5
6
7
8
9
10
11
12
13
14<profiles>
<profile>
<id>development</id>
<properties>
<environment>dev</environment>
</properties>
</profile>
<profile>
<id>production</id>
<properties>
<environment>prod</environment>
</properties>
</profile>
</profiles>
继承: 通过parent元素,一个POM文件可以继承另一个POM文件的配置:1
2
3
4
5<parent>
<groupId>com.example</groupId>
<artifactId>parent-project</artifactId>
<version>1.0-SNAPSHOT</version>
</parent>
聚合: 通过modules元素,一个POM文件可以管理多个子模块:1
2
3
4<modules>
<module>module1</module>
<module>module2</module>
</modules>
生命周期
个典型的 Maven 构建(build)生命周期是由以下几个阶段的序列组成的:
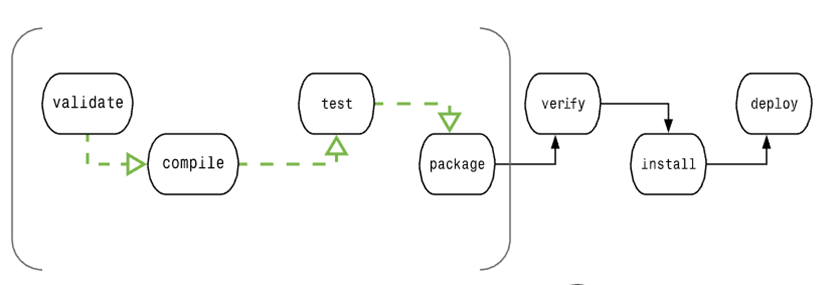
| 阶段 | 处理 | 描述 |
|---|---|---|
| 验证 validate | 验证项目 | 验证项目是否正确且所有必须信息是可用的 |
| 编译 compile | 执行编译 | 源代码编译在此阶段完成 |
| 测试 Test | 测试 | 使用适当的单元测试框架(例如JUnit)运行测试。 |
| 包装 package | 打包 | 将编译后的代码打包成可分发的格式,例如 JAR 或 WAR |
| 检查 verify | 检查 | 对集成测试的结果进行检查,以保证质量达标 |
| 安装 install | 安装 | 安装打包的项目到本地仓库,以供其他项目使用 |
| 部署 deploy | 部署 | 拷贝最终的工程包到远程仓库中,以共享给其他开发人员和工程 |
为了完成 default 生命周期,这些阶段(包括其他未在上面罗列的生命周期阶段)将被按顺序地执行。
Maven 有以下三个标准的生命周期:
1、Clean 生命周期:
- clean:删除目标目录中的编译输出文件。这通常是在构建之前执行的,以确保项目从一个干净的状态开始。
2、Default 生命周期(也称为 Build 生命周期):
- validate:验证项目的正确性,例如检查项目的版本是否正确。
- compile:编译项目的源代码。
- test:运行项目的单元测试。
- package:将编译后的代码打包成可分发的格式,例如 JAR 或 WAR。
- verify:对项目进行额外的检查以确保质量。
- install:将项目的构建结果安装到本地 Maven 仓库中,以供其他项目使用。
- deploy:将项目的构建结果复制到远程仓库,以供其他开发人员或团队使用。
3、Site 生命周期:
- site:生成项目文档和站点信息。
- deploy-site:将生成的站点信息发布到远程服务器,以便共享项目文档。
仓库
在 Maven 的术语中,仓库是一个位置(place)。
Maven 仓库是项目中依赖的第三方库,这个库所在的位置叫做仓库。
在 Maven 中,任何一个依赖、插件或者项目构建的输出,都可以称之为构件。
Maven 仓库能帮助我们管理构件(主要是JAR),它就是放置所有JAR文件(WAR,ZIP,POM等等)的地方。
Maven 仓库有三种类型:
- 本地(local)
- 中央(central)
- 远程(remote)
Maven 的本地仓库,在安装 Maven 后并不会创建,它是在第一次执行 maven 命令的时候才被创建。
运行 Maven 的时候,Maven 所需要的任何构件都是直接从本地仓库获取的。如果本地仓库没有,它会首先尝试从远程仓库下载构件至本地仓库,然后再使用本地仓库的构件。
默认情况下,不管Linux还是 Windows,每个用户在自己的用户目录下都有一个路径名为 .m2/repository/ 的仓库目录。
Maven 本地仓库默认被创建在 %USER_HOME% 目录下。要修改默认位置,在 %M2_HOME%\conf 目录中的 Maven 的 settings.xml 文件中定义另一个路径。1
<settings xmlns="http://maven.apache.org/SETTINGS/1.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0 http://maven.apache.org/xsd/settings-1.0.0.xsd"> <localRepository>C:/MyLocalRepository</localRepository> </settings>
当运行 Maven 命令,Maven 将下载依赖的文件到你指定的路径中。
Maven 中央仓库是由 Maven 社区提供的仓库,其中包含了大量常用的库。
中央仓库包含了绝大多数流行的开源Java构件,以及源码、作者信息、SCM、信息、许可证信息等。一般来说,简单的Java项目依赖的构件都可以在这里下载到。
中央仓库的关键概念:
- 这个仓库由 Maven 社区管理。
- 不需要配置。
- 需要通过网络才能访问。
如果 Maven 在中央仓库中也找不到依赖的文件,它会停止构建过程并输出错误信息到控制台。为避免这种情况,Maven 提供了远程仓库的概念,它是开发人员自己定制仓库,包含了所需要的代码库或者其他工程中用到的 jar 文件。
举例说明,使用下面的 pom.xml,Maven 将从远程仓库中下载该 pom.xml 中声明的所依赖的(在中央仓库中获取不到的)文件。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.companyname.projectgroup</groupId>
<artifactId>project</artifactId>
<version>1.0</version>
<dependencies>
<dependency>
<groupId>com.companyname.common-lib</groupId>
<artifactId>common-lib</artifactId>
<version>1.0.0</version>
</dependency>
<dependencies>
<repositories>
<repository>
<!--自定义远程仓库-->
<id>companyname.lib1</id>
<url>http://download.companyname.org/maven2/lib1</url>
</repository>
<repository>
<id>companyname.lib2</id>
<url>http://download.companyname.org/maven2/lib2</url>
</repository>
</repositories>
</project>
当执行 Maven 构建命令时,Maven 开始按照以下顺序查找依赖的库:
- 步骤 1 - 在本地仓库中搜索,如果找不到,执行步骤 2,如果找到了则执行其他操作。
- 步骤 2 - 在中央仓库中搜索,如果找不到,并且有一个或多个远程仓库已经设置,则执行步骤 4,如果找到了则下载到本地仓库中以备将来引用。
- 步骤 3 - 如果远程仓库没有被设置,Maven 将简单的停滞处理并抛出错误(无法找到依赖的文件)。
- 步骤 4 - 在一个或多个远程仓库中搜索依赖的文件,如果找到则下载到本地仓库以备将来引用,否则 Maven 将停止处理并抛出错误(无法找到依赖的文件)。
Maven 仓库默认在国外, 国内使用难免很慢,我们可以更换为阿里云的仓库。
修改 maven 根目录下的 conf 文件夹中的 settings.xml 文件,在 mirrors 节点上,添加内容如下:1
2
3
4
5
6<mirror>
<id>aliyunmaven</id>
<mirrorOf>*</mirrorOf>
<name>阿里云公共仓库</name>
<url>https://maven.aliyun.com/repository/public</url>
</mirror>
如果想使用其它代理仓库,可在 1
2
3
4
5
6
7
8
9
10<repository>
<id>spring</id>
<url>https://maven.aliyun.com/repository/spring</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
在你的 pom.xml 文件 1
2
3
4
5<dependency>
<groupId>[GROUP_ID]</groupId>
<artifactId>[ARTIFACT_ID]</artifactId>
<version>[VERSION]</version>
</dependency>
常用命令
mvn clean- 清理项目,删除
target目录(该目录包含了编译和打包过程中生成的所有文件)。
- 清理项目,删除
mvn compile- 编译项目的源代码。默认情况下,会查找
src/main/java目录下的所有.java文件,并将编译后的.class文件输出到target/classes目录中。
- 编译项目的源代码。默认情况下,会查找
mvn test- 使用合适的单元测试框架(如 JUnit 或 TestNG)运行项目的测试代码。默认情况下,测试代码位于
src/test/java目录下。
- 使用合适的单元测试框架(如 JUnit 或 TestNG)运行项目的测试代码。默认情况下,测试代码位于
mvn package- 将编译好的字节码打包成可分发的格式,例如 JAR 或 WAR 文件。这个命令首先执行
compile和test,然后将项目打包并存放在target目录中。
- 将编译好的字节码打包成可分发的格式,例如 JAR 或 WAR 文件。这个命令首先执行
mvn install- 安装打包好的构件到本地仓库(通常是用户主目录下的
.m2/repository),以便它可以被其他项目作为依赖使用。此命令还会执行package的所有步骤。
- 安装打包好的构件到本地仓库(通常是用户主目录下的
mvn deploy- 在集成或发布阶段使用,用于将最终包复制到远程仓库,使得其他开发者或项目可以共享这个构件。
mvn site- 生成关于项目的站点文档,包括测试覆盖率报告、依赖列表等信息。
mvn clean install- 组合命令,先清理项目 (
clean) 然后安装 (install) 到本地仓库。这是非常常见的组合,用于确保在干净环境下重新构建整个项目。
- 组合命令,先清理项目 (
mvn dependency:tree- 显示项目依赖树,有助于分析依赖冲突或了解项目依赖关系。
mvn archetype:generate- 生成一个新的 Maven 项目结构,通过交互式的方式选择项目模板
数据库
MySQL✨
事务
一组操作的集合,不可分割的一个工作单位. 事务会把所有操作作为一个整体向系统提交或撤销操作,即这些操作要么同时成功,要么同时失败.
事务四大特性
- 原子性(Atomicity):事务中的所有操作要么全部完成,要么全部不执行。
- 一致性(Consistency):事务应该将数据库从一种一致状态转换为另一种一致状态。
- 隔离性(Isolation):并发事务之间相互隔离,不会互相干扰。
- 持久性(Durability):一旦事务提交,所做的更改将是永久性的,即使系统发生故障也不会丢失。

事务并发问题
多个事务并发进行的问题
脏读
一个事务读到另外一个事务还没有提交的数据
不可重复读
一个事务先后读取同一条记录,但两次读取的数据不同,称之为不可重复读
幻读
一个事务按照条件查询数据时,没有对应的数据行,但是在插入数据时,又发现这行数据已经存在
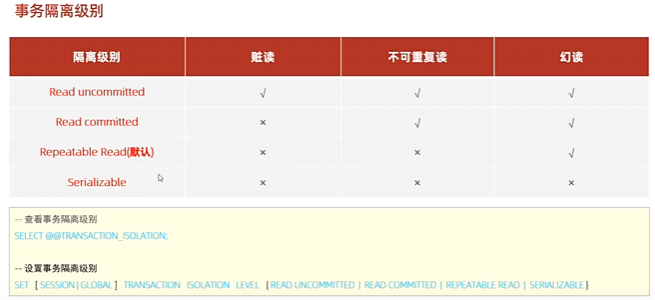
事务隔离级别
MySQL 支持四种标准的事务隔离级别:
- 读未提交(Read Uncommitted):最低级别的隔离,允许脏读、不可重复读和幻读。
- 读已提交(Read Committed):防止脏读,但允许不可重复读和幻读。
- 可重复读(Repeatable Read):默认级别,防止脏读和不可重复读,但允许幻读。
- 串行化(Serializable):最高级别的隔离,完全防止脏读、不可重复读和幻读,但会降低并发性能。
1 | SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ; |
1. 默认情况下:事务需要显式提交
- 在
START TRANSACTION开始一个事务后,所有对数据库的修改操作(如UPDATE、INSERT等)都只会暂时存在于事务的上下文中,而不会直接写入数据库。 - 这些更改对其他事务是不可见的(根据隔离级别),直到你显式调用
COMMIT提交事务。 - 如果你调用
ROLLBACK,则所有的更改会被撤销,数据库恢复到事务开始前的状态。
2. 如果未提交且会话结束
如果你在事务中执行了更新语句,但没有显式调用COMMITROLLBACK
,然后会话意外终止(例如客户端断开连接),MySQL 的行为如下:
- InnoDB 存储引擎(支持事务):事务会被自动回滚,所有未提交的更改都会被撤销。
- MyISAM 存储引擎(不支持事务):由于 MyISAM 不支持事务,所有操作会立即生效,无法回滚。
3. autocommit 模式的影响
- MySQL 默认开启了 autocommit 模式(
autocommit=1)。在这种模式下,每条单独的 SQL 语句都会被视为一个独立的事务,并在执行后自动提交。 - 当你使用
START TRANSACTION或BEGIN时,会临时禁用 autocommit 模式,直到事务结束(通过COMMIT或ROLLBACK)。 - 如果你没有显式提交事务,而会话结束时 autocommit 模式重新启用,InnoDB 会自动回滚未提交的事务。
存储引擎
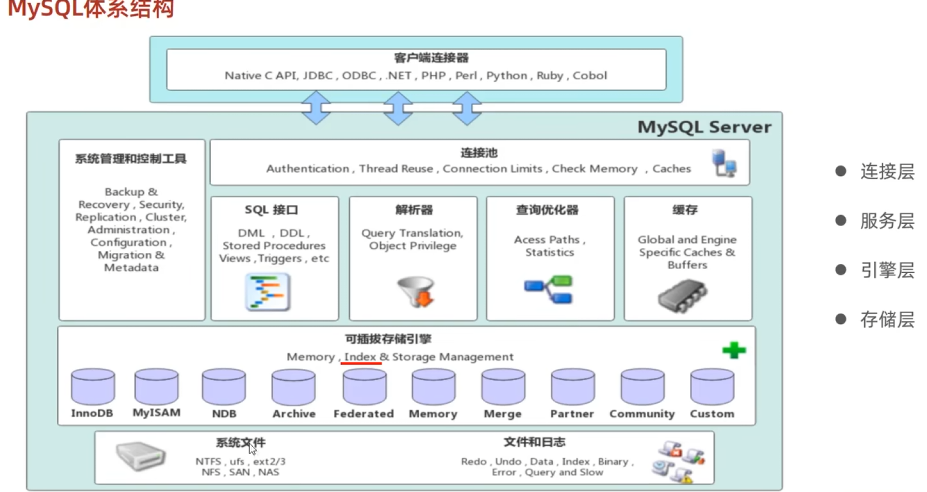
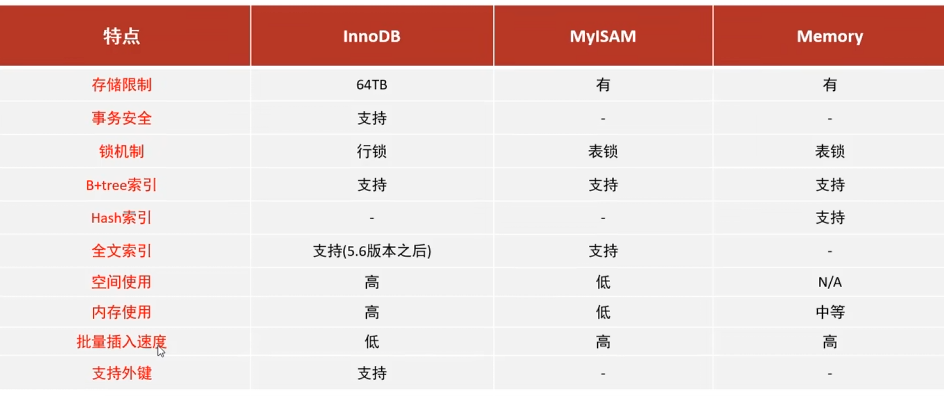
1. InnoDB
默认存储引擎:从 MySQL 5.5 开始成为默认存储引擎。
特性
- 事务支持:完全支持 ACID(原子性、一致性、隔离性、持久性)属性,适合需要高可靠性和数据一致性的应用。
- 行级锁定:提供高效的并发处理能力,减少了锁冲突的可能性。
行级锁定是指在对数据进行操作时,只锁定受影响的具体行而不是整个表。这意味着在同一张表中,不同事务可以同时对不同的行进行读写操作。
- 外键支持:唯一支持外键约束的存储引擎,有助于维护数据完整性和引用完整性。
- 崩溃恢复:通过 redo 和 undo 日志实现快速崩溃恢复。
- 聚簇索引:每个表都使用主键作为聚簇索引,提高了查询效率。
2. MyISAM
- 早期默认存储引擎:在 MySQL 5.5 之前是默认的存储引擎。
- 特性
- 不支持事务:适用于对事务要求不高、以读操作为主的场景。
- 表级锁定:整个表被锁定进行写入操作,可能导致高并发下的性能瓶颈。
- 全文索引:MyISAM 支持全文搜索,这在某些文本检索应用中非常有用。
- 压缩表:可以创建只读压缩表,节省存储空间。
- 简单高效:对于简单的查询操作,MyISAM 提供了较高的性能。
3. Memory (Heap)
- 内存中的表:数据存放在内存中,因此访问速度非常快。
- 特性
- 临时性:重启服务器后数据丢失,适用于缓存数据或临时计算。
- 表级锁定:由于是内存操作,锁定粒度较粗并不会显著影响性能。
- 哈希索引:默认使用哈希索引,对于精确匹配查询特别有效。
- 不支持事务:与 MyISAM 类似,Memory 引擎也不支持事务。

索引

- 定义:索引是一种特殊的数据结构,用于加速数据库表中数据的检索速度。
- 目的:减少查询时需要扫描的数据量,从而提高查询性能。
代价:虽然索引可以加快查询速度,但它们也会占用额外的存储空间,并且在进行插入、更新和删除操作时会增加一些开销。
B-Tree 索引
适用范围:这是 MySQL 中最常用的索引类型,默认情况下,
CREATE INDEX创建的就是 B-Tree 索引。特点
- 支持全键值、键值范围和键前缀查找(如
LIKE 'abc%')。 - 能够有效地支持等值查询和范围查询(例如
>、<、BETWEEN、IN等)。 - 适用于大多数类型的比较操作(包括
=、<>、>、>=、<、<=)。
- 支持全键值、键值范围和键前缀查找(如
(1) 阶数(Order)
- B 树的阶数 t是一个定义其结构的重要参数。每个节点最多可以有 2t−1个键值,并且至少包含 t−1个键值(除了根节点外)。每个内部节点最多有 2t个子节点。
这种设计确保了树的高度保持较低,从而减少了查找所需的时间。(2) 节点类型
内部节点:除了叶子节点之外的所有节点。它们存储键值和指向子节点的指针。
- 叶子节点:位于树的最底层,直接存储数据或指向数据的指针。
2. B+ 树(B+Tree)
定义
- B+ 树是 B 树的一种变体,特别优化了范围查询性能。与 B 树不同的是,B+ 树的所有数据都存储在叶子节点中,而内部节点仅用于导航目的。
特点
- 所有数据都在叶子节点:这意味着所有的实际数据记录都存储在叶子节点上,而不是分散在整棵树中。这样做的好处是可以将更多的键值放入内部节点,从而进一步降低树的高度。
- 叶子节点链表:B+ 树的叶子节点通过双向链表连接在一起,这极大地提高了范围查询的效率,因为一旦定位到起始位置,就可以沿着链表顺序访问后续的数据。
- 更高的分支因子:由于内部节点不存储数据,因此可以容纳更多的子节点指针,这有助于进一步减少树的高度,提高查找效率。
3. B 树 vs. B+ 树
| 特性 | B 树 | B+ 树 |
|---|---|---|
| 数据存储位置 | 内部节点和叶子节点都可以存储数据 | 仅叶子节点存储数据,内部节点仅用于导航 |
| 叶子节点连接 | 不具备叶子节点间的直接连接 | 叶子节点之间通过链表相连,便于范围查询 |
| 树的高度 | 较高,因为内部节点也需要存储数据 | 更低,因为内部节点可以存储更多键值,减少了树的高度 |
| 适用场景 | 适合于大多数基本查询操作 | 特别适合于范围查询和排序操作 |

| 特性 | B树 | B+树 |
|---|---|---|
| 数据存储 | 数据(key-value)存储在所有节点(叶子+内部) | 数据仅存储在叶子节点,内部节点只存 key |
| 指针 | 内部节点的指针指向子节点 | 叶子节点间有额外的顺序指针(双向链表) |
| 搜索 | 可以在非叶子节点找到数据,搜索可能提前结束 | 必须走到叶子节点才能找到数据,查询路径固定 |
| 范围查询 | 范围查询效率较低,需回溯 | 范围查询效率高(叶子节点是链表,顺序扫描快) |
| 磁盘I/O | 较多随机I/O | 较少随机I/O,访问更快 |
| 树的高度 | 相对较高 | 相对较低(因为内部节点更小,能容纳更多 key) |

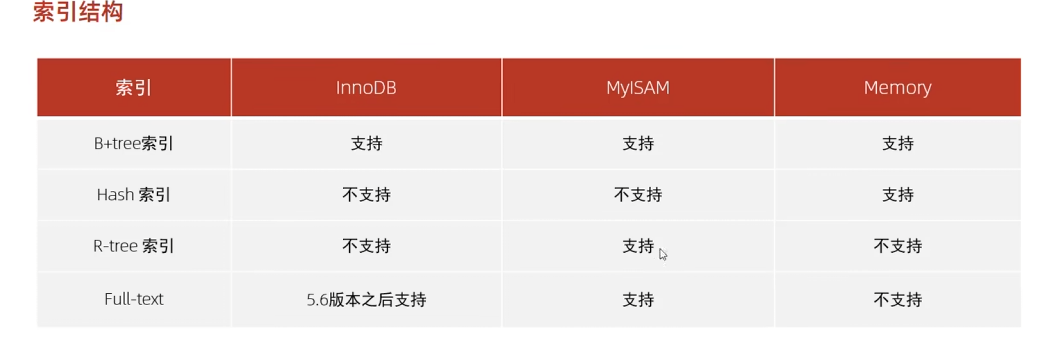

| 特性 | 聚集索引 | 二级索引 |
|---|---|---|
| 物理存储 | 数据按索引键顺序存储 | 数据存储位置与索引无关,索引中包含指向数据行的指针 |
| 数量限制 | 每个表只能有一个 | 可以有多个 |
| 查询效率 | 对于按索引键排序的查询非常高效 | 需要两次查找(先找索引,再找数据行),但适用于多种查询条件 |
| 更新开销 | 更新可能导致大量数据重排,开销较大 | 更新仅需修改索引结构,开销相对较小 |
SQL优化
1. 使用 EXPLAIN 分析查询性能
🔹 EXPLAIN 可以 分析 SQL 查询的执行计划,查看 索引使用情况、扫描方式 和 查询优化器的决策。1
EXPLAIN SELECT * FROM users WHERE name = 'Alice';
🚀 关键字段解读:
| 字段 | 作用 | 优化建议 |
|---|---|---|
id | 查询的执行顺序 | ID 越大,优先执行 |
select_type | 查询类型 | SIMPLE 是最优 |
table | 查询的表 | 确保表索引优化 |
type | 访问类型 | ALL(全表扫描) 最差,index、ref、range、const 最优 |
possible_keys | 可能使用的索引 | 如果 NULL,说明没有合适的索引 |
key | 实际使用的索引 | 确保索引合理 |
rows | 需要扫描的行数 | 越少越好 |
Extra | 额外信息 | 避免 Using filesort 和 Using temporary |
🔹 优化示例1
EXPLAIN SELECT * FROM users WHERE email = 'test@example.com';

2. 使用 SHOW PROFILE 进行 SQL 运行时间分析
🔹 SHOW PROFILE 详细分析 SQL 在各个阶段的执行时间,如 解析、优化、执行、发送数据。1
2
3sqlCopyEditSET profiling = 1;
SELECT * FROM users WHERE email = 'test@example.com';
SHOW PROFILES;
🔹 查看 SQL 具体耗时1
SHOW PROFILE FOR QUERY 1;
🚀 优化方向
- 如果
sending data耗时长 ➝ 可能需要优化索引或减少返回数据量。 - 如果
query optimization耗时长 ➝ SQL 逻辑复杂,可以考虑优化子查询或 JOIN。
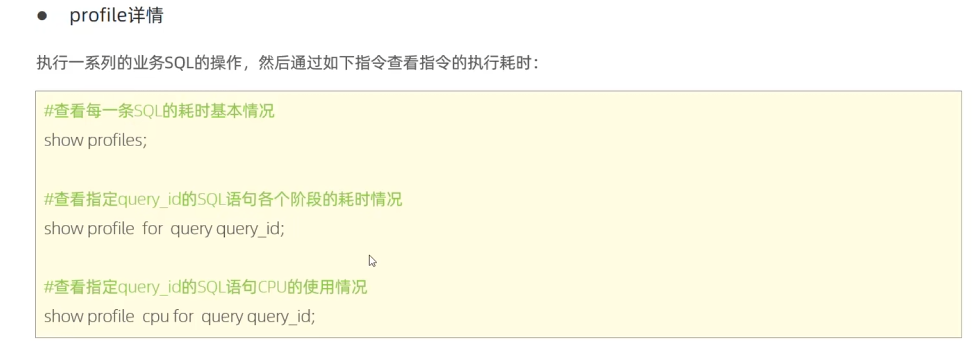
3. 使用 SHOW STATUS 获取数据库运行状态1
2SHOW STATUS LIKE 'Threads%';
SHOW GLOBAL STATUS LIKE 'Com_______';
🚀 关键指标
| 指标 | 作用 | 优化建议 |
|---|---|---|
Threads_running | 当前正在执行的查询数 | 避免长时间运行的查询 |
Threads_connected | 当前连接数 | 优化连接池配置 |
Slow_queries | 慢查询数量 | 检查慢查询日志 |
Handler_read_rnd_next | 全表扫描次数 | 应减少(索引优化) |
4. 慢查询日志分析
🔹 开启慢查询日志1
2SET GLOBAL slow_query_log = 1;
SET GLOBAL long_query_time = 1; -- 记录执行时间 >1秒的查询
🔹 查看慢查询1
SELECT * FROM mysql.slow_log ORDER BY start_time DESC;
🚀 优化方法
- 使用索引,减少
ALL扫描 - 优化
JOIN,避免Using temporary - 避免
ORDER BY+LIMIT造成的filesort
5. 索引优化
(1)使用合适的索引1
CREATE INDEX idx_users_name ON users(name);
单列索引:适用于单个查询字段
复合索引:适用于
WHERE col1 AND col2前缀索引:适用于长字符串字段
1
CREATE INDEX idx_users_email ON users(email(10));
(2)避免索引失效
🔹 索引会失效的情况
| 错误写法 | 原因 |
|---|---|
WHERE name LIKE '%abc' | % 开头索引失效 |
WHERE DATE(create_time) = '2024-03-30' | 函数 使索引失效 |
WHERE id + 1 = 10 | 计算操作 使索引失效 |
🔹 优化索引查询1
2
3
4
5-- 方式 1:避免前导 %
SELECT * FROM users WHERE name LIKE 'abc%';
-- 方式 2:索引时间范围查询
SELECT * FROM orders WHERE create_time BETWEEN '2024-03-30' AND '2024-03-31';
6. SQL 语句优化
(1)避免 SELECT \*1
SELECT id, name FROM users WHERE id = 10;
🔹 减少不必要的数据传输,提高查询效率
(2)避免 OR,改为 UNION ALL1
2
3
4
5
6
7sqlCopyEdit-- ❌ 索引失效
SELECT * FROM users WHERE name = 'Alice' OR age = 25;
-- ✅ 改成 UNION ALL
SELECT * FROM users WHERE name = 'Alice'
UNION ALL
SELECT * FROM users WHERE age = 25;
🔹 OR 可能导致索引失效,而 UNION ALL 可提高性能
(3)避免 NOT IN,改用 NOT EXISTS1
2
3
4
5
6
7sqlCopyEdit-- ❌ NOT IN 可能导致全表扫描
SELECT * FROM users WHERE id NOT IN (SELECT user_id FROM orders);
-- ✅ 使用 NOT EXISTS
SELECT * FROM users u WHERE NOT EXISTS (
SELECT 1 FROM orders o WHERE u.id = o.user_id
);
🔹 NOT EXISTS 在大数据量下查询效率更高
| 优化点 | 方法 |
|---|---|
| SQL 分析 | EXPLAIN、SHOW PROFILE |
| 索引优化 | CREATE INDEX,避免索引失效 |
| 慢查询优化 | SHOW SLOW LOGS,减少 SELECT * |
| SQL 语句优化 | 避免 OR,使用 EXISTS |
| 缓存优化 | 使用 Redis,调整 query_cache_size |
| 服务器配置优化 | 优化 innodb_buffer_pool_size、max_connections |
1. 最左前缀法则
定义
最左前缀法则指的是,在使用组合索引时,查询条件必须从索引的最左边开始匹配。只有满足这个规则,MySQL 才能利用该索引来加速查询。
例如,如果你在一个表上创建了一个组合索引
1 | (col1, col2, col3) |
,那么以下查询可以有效利用该索引:
sql
深色版本1
2
3SELECT * FROM table WHERE col1 = 'value';
SELECT * FROM table WHERE col1 = 'value' AND col2 = 'value';
SELECT * FROM table WHERE col1 = 'value' AND col2 = 'value' AND col3 = 'value';
但是,如果查询条件不包含col1或者跳过了col1,则无法完全利用该索引:1
2
3-- 不能利用索引
SELECT * FROM table WHERE col2 = 'value';
SELECT * FROM table WHERE col3 = 'value';
原理
- 组合索引实际上是对多个列进行排序后构建的索引结构。MySQL 在查找数据时,会首先根据索引中最左边的列进行过滤,然后再依次考虑后面的列。
- 因此,为了最大化索引的利用率,查询条件应该尽可能地从最左边的列开始,并且保持连续
模糊查询,如果是头部进行模糊,索引不会失效.
在索引上进行运算,索引会失效.
1. LIKE 以 % 开头
❌ 错误示例(索引失效,全表扫描):1
SELECT * FROM users WHERE name LIKE '%Alice';
📌 原因:
LIKE '%XXX'前面有通配符,MySQL 无法利用 B+ 树索引,只能全表扫描。
✅ 正确优化1
SELECT * FROM users WHERE name LIKE 'Alice%';
📌 优化点:
Alice%结尾带%,索引仍然有效。若要支持前缀匹配,可 使用全文索引(FULLTEXT):
1
2sqlCopyEditALTER TABLE users ADD FULLTEXT(name);
SELECT * FROM users WHERE MATCH(name) AGAINST('Alice');
2. OR 可能导致索引失效
❌ 错误示例(索引失效):1
SELECT * FROM users WHERE name = 'Alice' OR age = 25;
📌 原因:
name和age上都有索引,但OR让 MySQL 无法同时使用多个索引,会导致全表扫描。
✅ 正确优化1
2
3
4-- 方式 1:使用 UNION(若 name 和 age 都有索引)
SELECT * FROM users WHERE name = 'Alice'
UNION ALL
SELECT * FROM users WHERE age = 25;
📌 优化点:
UNION ALL分两次查询,分别使用索引,避免全表扫描。
3. NOT IN 可能导致索引失效
❌ 错误示例(索引失效):1
SELECT * FROM users WHERE id NOT IN (1, 2, 3);
📌 原因:
NOT IN可能触发全表扫描,因为 MySQL 需要 检查每一行是否符合条件。
✅ 正确优化1
2
3
4-- 方式 1:改用 NOT EXISTS
SELECT * FROM users u WHERE NOT EXISTS (
SELECT 1 FROM orders o WHERE u.id = o.user_id
);
📌 优化点:
NOT EXISTS性能更优,可有效利用索引。
4. 对索引列进行计算
❌ 错误示例(索引失效):1
SELECT * FROM users WHERE id + 1 = 10;
📌 原因:
id + 1 = 10对索引字段进行了计算,导致 MySQL 无法使用索引。
✅ 正确优化1
SELECT * FROM users WHERE id = 9;
📌 优化点:
- 尽量避免索引列上的计算。
5. 对索引列使用函数
❌ 错误示例(索引失效):1
SELECT * FROM users WHERE LEFT(phone, 3) = '138';
📌 原因:
LEFT(phone, 3)对phone列进行了函数操作,导致索引失效。
✅ 正确优化1
SELECT * FROM users WHERE phone LIKE '138%';
📌 优化点:
- 避免对索引列使用函数,可以使用
LIKE 'XXX%'。
6. 数据类型不匹配
❌ 错误示例(索引失效):1
SELECT * FROM users WHERE phone = 13812345678;
📌 原因:
phone列是VARCHAR(11)类型,但查询时传入的是 数值(INT)。- MySQL 会进行隐式类型转换,导致索引失效。
✅ 正确优化1
SELECT * FROM users WHERE phone = '13812345678';
📌 优化点:
- 保证查询参数类型与索引列类型一致。
7. 范围查询 (>、<、BETWEEN) 导致索引失效
❌ 错误示例(索引失效部分字段):1
SELECT * FROM users WHERE age > 30 AND name = 'Alice';
📌 原因:
age > 30是范围查询,索引可能只用到age,导致name不能被索引优化。
✅ 正确优化1
SELECT * FROM users WHERE name = 'Alice' AND age > 30;
📌 优化点:
- 调整查询字段顺序,让等值查询 (
=) 在前,让 MySQL 更容易使用索引。
8. ORDER BY + LIMIT 可能导致索引失效
❌ 错误示例:1
SELECT * FROM users ORDER BY age LIMIT 10000, 10;
📌 原因:
- 当
LIMIT偏移量过大时,MySQL 仍然会扫描大量数据,导致性能下降。
✅ 正确优化1
2
3
4
5
6
7-- 方式 1:使用覆盖索引
SELECT id, name FROM users ORDER BY age LIMIT 10000, 10;
-- 方式 2:使用子查询优化
SELECT * FROM users
WHERE id >= (SELECT id FROM users ORDER BY age LIMIT 10000, 1)
ORDER BY age LIMIT 10;
📌 优化点:
- 尽量减少
LIMIT偏移量,可用 子查询 或 覆盖索引 提高效率。
索引失效的常见原因总结
| 失效原因 | 解决方案 |
|---|---|
LIKE '%XXX' | 改为 LIKE 'XXX%',或使用 FULLTEXT 索引 |
OR | 使用 UNION ALL |
NOT IN | 使用 NOT EXISTS |
| 索引列计算 | 直接在 WHERE 子句中使用索引列 |
| 索引列使用函数 | 避免 LEFT(phone, 3),改用 LIKE 'XXX%' |
| 数据类型不匹配 | 查询参数类型与索引列类型一致 |
范围查询 (>, <, BETWEEN) | 让等值查询 (=) 在前 |
ORDER BY + LIMIT | 使用覆盖索引或子查询优化 |
在某些情况下,可以通过 FORCE INDEX 强制 MySQL 使用特定的索引,避免优化器选择全表扫描。
示例
1 | SELECT * FROM employees FORCE INDEX (idx_department) |
- 注意:强制使用索引需要谨慎,因为优化器通常会选择最优的执行计划。如果强制使用不合适的索引,可能会适得其反
覆盖索引
如果查询的所有列都包含在一个索引中,可以通过创建覆盖索引来避免回表操作,从而提高查询效率。
示例
假设查询如下:1
SELECT department, salary FROM employees WHERE department = 'Sales' OR salary > 5000;
可以创建以下覆盖索引:1
CREATE INDEX idx_dept_salary ON employees(department, salary);
由于查询所需的所有列都在索引中,MySQL 可以直接通过索引返回结果,无需访问数据表(不需要回标)。
前缀索引
- 前缀索引是指对列中值的前 N 个字符或字节创建索引,而不是对整个列值进行索引。
- 这种方法特别适用于
VARCHAR、TEXT和BLOB类型的列,这些列通常包含较长的数据。
前缀索引(Prefix Index)是 MySQL 中一种特殊的索引类型,它允许你为列的值的前缀创建索引,而不是整个列的值。这种索引对于那些存储较长字符串的列特别有用,因为它可以显著减少索引的大小,同时仍然提供良好的查询性能
假设有一个博客系统,其中的文章标题可能很长,并且我们希望根据标题的部分内容进行搜索:1
2
3
4
5
6CREATE TABLE articles (
id INT PRIMARY KEY,
title VARCHAR(255),
content TEXT,
INDEX idx_title (title(50)) -- 对标题的前50个字符创建索引
);
对于存储长文本数据的列,除了前缀索引外,还可以考虑使用全文索引(Full-Text Index)。全文索引专门用于支持复杂的文本搜索功能,如自然语言查询和布尔查询。
(1) 适用场景
- 前缀索引:适合于简单的前缀匹配查询(如
LIKE 'prefix%')。 - 全文索引:适合于复杂的文本搜索需求(如
MATCH ... AGAINST)。
(2) 性能对比
- 前缀索引更适合于快速定位具有特定前缀的记录,但在处理复杂的文本搜索时不如全文索引高效。
- 全文索引虽然功能强大,但构建和维护成本较高,尤其是在数据量较大的情况下。



视图/存储过程/触发器
视图 (Views)
视图是基于SQL语句的结果集的可视化的表。视图包含行和列,就像一个真实的表。视图中的字段就是来自一个或多个数据库中的真实表中的字段
- 虚拟表:视图并不在数据库中以存储的数据值集形式存在;行和列数据来自于定义视图的查询所引用的基本表,并且是在访问视图时动态生成的。
- 简化复杂查询:可以将复杂的查询封装进视图中,使用户可以通过简单的查询来访问这些数据。
- 安全性:通过视图限制对基础表的访问,从而提高安全性。例如,只允许用户通过视图查看特定的列或行。
- 更新限制:并非所有视图都可以被更新。对于包含聚合函数、DISTINCT关键字、GROUP BY、HAVING等的视图,通常不能直接进行更新操作。
1 | CREATE VIEW view_name AS |
存储过程 (Stored Procedures)
定义
- 存储过程是一组为了完成特定功能的SQL语句集,经过编译后存储在数据库中,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。
特点与重点
- 性能优化:由于存储过程在创建时就已经进行了编译,因此在执行时速度更快。
- 模块化编程:可以将复杂的业务逻辑封装到存储过程中,提高代码的重用性和可维护性。
- 减少网络流量:通过将一系列操作封装在一个存储过程中,可以减少客户端与服务器之间的通信量。
- 安全控制:可以为存储过程设置权限,从而控制谁可以执行哪些操作。
创建示例1
2
3
4
5
6DELIMITER //
CREATE PROCEDURE procedure_name()
BEGIN
-- SQL statements here
END //
DELIMITER ;
触发器 (Triggers)
定义
- 触发器是一种特殊的存储过程,它不能被显式地调用,而是当一个与其关联的操作发生的时候自动触发执行。这些操作包括
INSERT、UPDATE、DELETE等。
特点与重点
- 自动执行:无需人工干预即可自动执行,用于确保某些规则或流程的一致性。
- 事务支持:触发器会参与到同一个事务中,这意味着如果触发器中的操作失败,则整个事务都会回滚。
- 事件驱动:可以根据表上的插入、更新或删除操作来触发相应的逻辑。
- 注意性能影响:虽然触发器提供了强大的功能,但不恰当地使用可能会导致性能问题,尤其是在高并发环境下。
创建示例1
2
3
4
5
6CREATE TRIGGER trigger_name
BEFORE/AFTER INSERT/UPDATE/DELETE ON table_name
FOR EACH ROW
BEGIN
-- Trigger logic here
END;
- 视图主要用于简化查询、增强安全性和提供抽象层。
- 存储过程则侧重于执行效率、模块化编程和减少网络负载。
- 触发器适用于需要在数据库层面自动响应特定事件的情况,如保持数据一致性或记录审计信息。
锁
锁(Locking)是确保数据一致性和事务隔离级别的核心机制。通过锁定数据库中的资源,可以防止多个用户或进程同时对相同的数据进行修改而导致的数据不一致性问题。
全局锁
全局读锁允许在锁定期间进行读操作,但阻止写操作。全局读锁通常用于备份操作或其他需要读取整个数据库的场景。通常使用 FLUSH TABLES WITH READ LOCK 语句来获取全局读锁。1
2
3flush tables with read lock;
mysqldump db > xx.sql;
unlock tables;
表级锁:锁定整个表,适用于高并发写入较少的场景。
表锁
LOCK TABLES 语句用于在事务或会话中显式地锁定一张或多张表。锁定的表会根据需要加共享锁或排它锁,直到 UNLOCK TABLES 被调用。
示例:1
2LOCK TABLES table_name READ; -- 给表加共享锁
LOCK TABLES table_name WRITE; -- 给表加排它锁
UNLOCK TABLES 用于释放之前使用 LOCK TABLES 锁定的所有表。此命令会解除锁定,允许其他事务访问这些表。
示例:1
UNLOCK TABLES;
共享锁(S Lock 读锁)
共享锁允许多个事务同时读取表中的数据,但阻止写操作。也就是说,多个事务可以同时持有共享锁并执行读取操作,但不能修改表中的数据。
- 共享锁的特点:
- 允许多个事务并发读取同一个表的数据。
- 其他事务无法修改表中的数据,但可以进行读取操作。
排它锁(X Lock 写锁)
排它锁是一种更强的锁类型,当一个事务对某一表加了排它锁时,其他事务既不能读取也不能修改这个表中的数据。
- 排它锁的特点:
- 只有持有排它锁的事务可以对表进行修改。
- 其他事务无法读取或修改这个表。
元数据锁
用于保护数据库元数据的一种锁机制。元数据指的是描述数据库结构的信息,比如表、索引、列、外键等数据库对象的定义。元数据锁的主要作用是防止在某些操作(如修改表结构)期间,其他操作对相同数据库对象的访问或修改,以保证元数据的一致性和完整性。

意向锁
意向锁是一种表级锁,它的作用并不是直接控制对数据的访问,而是表明某个事务希望对表中的某些行加锁,从而避免在加行级锁时与其他事务产生冲突。
当一个事务打算在某个表中对某些行加行级锁时,必须首先获取意向锁(IS 或 IX)来表明它的意图。这些意向锁会被 自动加上,因此,事务无需手动显式地设置意向锁。
- 意向共享锁(Intention Shared Lock, IS 锁):
- 表示事务打算在某些行上加共享锁(S 锁)。
- 其他事务仍然可以对该表加意向共享锁或意向排他锁,但不能加排他锁(X 锁)。
- 意向排他锁(Intention Exclusive Lock, IX 锁):
- 表示事务打算在某些行上加排他锁(X 锁)。
- 其他事务不能对该表加任何类型的锁(包括共享锁和排他锁),但可以加意向排他锁。
| 当前锁 \ 请求锁 | IS 锁 | IX 锁 | S 锁 | X 锁 |
|---|---|---|---|---|
| IS 锁 | 兼容 | 兼容 | 兼容 | 不兼容 |
| IX 锁 | 兼容 | 兼容 | 不兼容 | 不兼容 |
| S 锁 | 兼容 | 不兼容 | 兼容 | 不兼容 |
| X 锁 | 不兼容 | 不兼容 | 不兼容 | 不兼容 |
1. 使用 SELECT ... FOR UPDATE 触发意向排它锁(IX)
SELECT ... FOR UPDATE 语句会在查询的行上加上 排它锁(X),同时在表级别加上 意向排它锁(IX),表示这个事务打算对该表中的一些行加排它锁。这样做是为了避免多个事务在同一表上进行行级锁时产生冲突。1
2
3
4
5-- 开始一个事务
START TRANSACTION;
-- 对表中的某行数据加排它锁,并在表上加意向排它锁(IX)
SELECT * FROM your_table WHERE id = 1 FOR UPDATE;
2. 使用 SELECT ... LOCK IN SHARE MODE 触发意向共享锁(IS)
SELECT ... LOCK IN SHARE MODE 语句会在查询的行上加上 共享锁(S),同时在表级别加上 意向共享锁(IS),表示这个事务打算对该表中的一些行加共享锁。意向锁表明了事务打算进行共享锁操作,而不直接锁定整个表。1
2
3
4
5-- 开始一个事务
START TRANSACTION;
-- 对表中的某行数据加共享锁,并在表上加意向共享锁(IS)
SELECT * FROM your_table WHERE id = 1 LOCK IN SHARE MODE;
行级锁:锁定特定的行,适用于高并发写入较多的场景,能提供更高的并发性能。
记录锁(Record Locks)
- 定义:记录锁是对索引记录加的锁。即使表没有定义索引,MySQL也会使用隐藏的主键索引来执行记录锁。
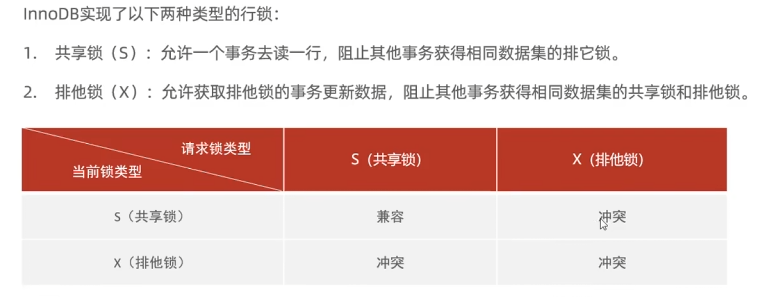
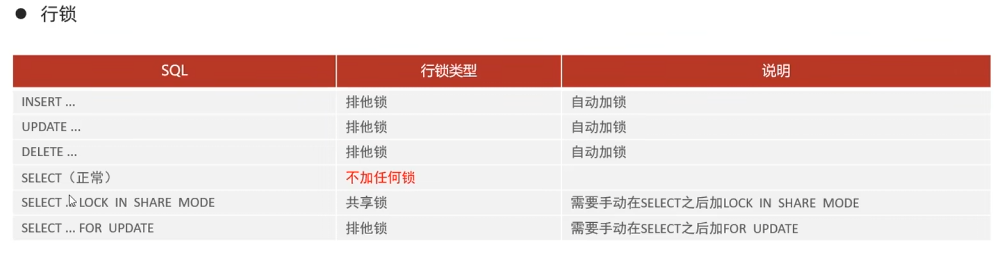

间隙锁(Gap Locks)
用于锁定索引记录之间的间隙,或者锁定第一个索引记录之前或最后一个索引记录之后的空间。间隙锁主要用于防止其他事务在这个间隙中插入新的记录,从而避免幻读问题(Phantom Reads)。它通常在可重复读(Repeatable Read)隔离级别下工作
- 定义:间隙锁锁定的是索引记录之间的间隙,或者锁定第一个索引记录之前或最后一个索引记录之后的空间。主要用于防止幻读现象。
- 适用范围:仅在可重复读(Repeatable Read)隔离级别下有效。
Next-Key Locks
- 定义:Next-Key Locks 是记录锁与间隙锁的组合,锁定的是索引记录本身以及它之前的间隙。这种锁机制有效地解决了幻读问题

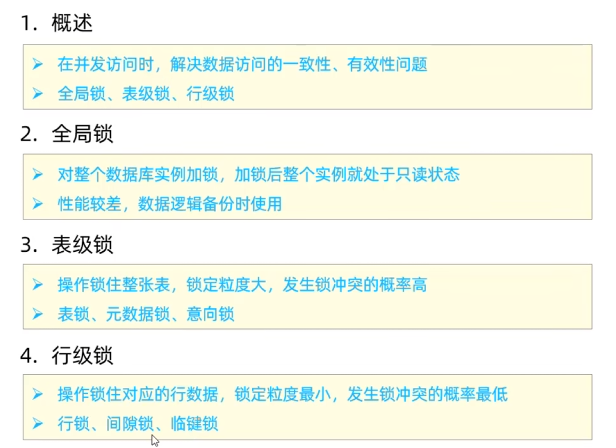
日志
错误日志
(1) 定义
- 错误日志记录了 MySQL 服务器启动、运行或停止过程中遇到的问题,包括启动失败、崩溃以及一些警告信息。
1 | show variable like '%log_error%' |
(2) 配置
默认情况下,错误日志通常位于数据目录下,文件名为
hostname.err(windows)。可以通过修改配置文件my.cnf或my.ini来指定错误日志的位置和是否启用:
1
2[mysqld]
log_error=/path/to/error.log
2. 二进制日志(Binary Log)
(1) 定义
- 二进制日志记录了所有更改数据库内容的事件(如
INSERT、UPDATE、DELETE等),主要用于数据恢复和主从复制。
(2) 配置
启用二进制日志:
1
2
3[mysqld]
server-id=1
log-bin=/path/to/bin-log可以设置过期时间自动清理旧的日志文件:
1
expire_logs_days=7
1
show variable like '%log_bin%'


查询日志(General Query Log)
(1) 定义
- 查询日志记录了所有客户端连接和执行的所有 SQL 语句,这对于调试和审计非常有用。
(2) 配置
可以通过以下方式启用查询日志:
1
SET GLOBAL general_log = 'ON';
或者在配置文件中设置:
1
2
3[mysqld]
general_log=1
general_log_file=/path/to/query.log
(3) 使用场景
- 调试:当需要了解应用程序如何与数据库交互时,查询日志是一个很好的工具。
- 性能分析:虽然查询日志对性能有一定影响,但它可以用来识别慢查询或频繁执行的查询。
3. 慢查询日志(Slow Query Log)
(1) 定义
- 慢查询日志记录了执行时间超过指定阈值的查询,有助于识别性能瓶颈。
(2) 配置
启用慢查询日志:
1
SET GLOBAL slow_query_log = 'ON';
设置慢查询的时间阈值(单位为秒):
1
SET GLOBAL long_query_time = 2; -- 记录执行时间超过2秒的查询
在配置文件中也可以进行相应的设置:
1
2
3
4[mysqld]
slow_query_log=1
slow_query_log_file=/path/to/slow-query.log
long_query_time=2
(3) 使用场景
- 性能优化:通过分析慢查询日志,可以找到执行效率低下的查询并进行优化。
- 监控:持续监控慢查询日志可以帮助及时发现性能问题。

Join连接
join连接两个表
- INNER JOIN:仅返回两个表中满足连接条件的记录。
- LEFT JOIN(或LEFT OUTER JOIN):返回左表中的所有记录,以及右表中满足连接条件的记录。若右表无匹配记录则填充NULL。
- RIGHT JOIN(或RIGHT OUTER JOIN):返回右表中的所有记录,以及左表中满足连接条件的记录。若左表无匹配记录则填充NULL。
- FULL JOIN(或FULL OUTER JOIN):返回两个表中的所有记录,任何表中无匹配记录的部分用NULL填充。(注意:MySQL不直接支持此语法)
- CROSS JOIN:产生两个表的笛卡尔积。
- SELF JOIN:一个表与自身的连接,适用于查询具有层次结构的数据。
% 可以匹配任意长度的字符串(包括空字符串),而 _ 总是代表一个单一字符.在SQL中,默认情况下并没有一个预设的转义字符用于 LIKE 查询中的通配符(如 % 和 _)转义。这意味着,如果你需要转义这些特殊字符,你必须明确指定一个转义字符,并通过 ESCAPE 关键字来定义它。
尽管没有默认的转义字符,但你可以选择一个不会出现在目标字符串中的字符作为转义字符。常用的转义字符包括反斜杠 \ 或者感叹号 ! 等。下面是如何使用 ESCAPE 来定义转义字符的例子:
如果想查找包含实际百分比符号 % 的记录,可以这样做:1
2
3SELECT column_name
FROM table_name
WHERE column_name LIKE '%\%%' ESCAPE '\';
在这个例子中:
\%表示实际的百分号字符%而不是通配符。ESCAPE '\'告诉数据库\是转义字符。
PostgresSQL
PostgreSQL: The world’s most advanced open source database
MongoDB
Start with Guides - Start with Guides
持久层框架
Mybatis✨
【尚硅谷】MyBatis零基础入门教程(细致全面,快速上手mybatis)_哔哩哔哩_bilibili
MyBatis视频零基础入门到进阶,MyBatis全套视频教程源码级深入详解_哔哩哔哩_bilibili
持久层框架,简化JDBC开发,负责数据库的读写.
JDBC问题:硬编码 操作繁琐
查询单表数据整体流程
- 创建表,插入数据
- 创建模块,导入maven
- 编写mybatis核心配置文件(替换连接信息,解决硬编码)
- 编写sql映射文件(统一管理sql语句)
- 编码: 定义POJO类 加载核心配置文件,获取sqlsessionfactory对象,执行sql语句
使用Mapper代理开发
创建mapper类,该类名称与命名空间相同,方法申明与mapper映射xml文件相同
既然有了 SqlSessionFactory,顾名思义,我们可以从中获得 SqlSession 的实例。SqlSession 提供了在数据库执行 SQL 命令所需的所有方法。你可以通过 SqlSession 实例来直接执行已映射的 SQL 语句。例如:1
2
3try (SqlSession session = sqlSessionFactory.openSession()) {
Blog blog = (Blog) session.selectOne("org.mybatis.example.BlogMapper.selectBlog", 101);
}
诚然,这种方式能够正常工作,对使用旧版本 MyBatis 的用户来说也比较熟悉。但现在有了一种更简洁的方式——使用和指定语句的参数和返回值相匹配的接口(比如 BlogMapper.class),现在你的代码不仅更清晰,更加类型安全,还不用担心可能出错的字符串字面值以及强制类型转换。
例如:1
2
3
4try (SqlSession session = sqlSessionFactory.openSession()) {
BlogMapper mapper = session.getMapper(BlogMapper.class);
Blog blog = mapper.selectBlog(101);
}

properties
这些属性可以在外部进行配置,并可以进行动态替换。你既可以在典型的 Java 属性文件中配置这些属性,也可以在 properties 元素的子元素中设置。例如:1
2
3
4<properties resource="org/mybatis/example/config.properties">
<property name="username" value="dev_user"/>
<property name="password" value="F2Fa3!33TYyg"/>
</properties>
settings
1 | <settings> |
TypeAliases
类型别名可为 Java 类型设置一个缩写名字。 它仅用于 XML 配置,意在降低冗余的全限定类名书写。例如:1
2
3
4
5
6
7
8<typeAliases>
<typeAlias alias="Author" type="domain.blog.Author"/>
<typeAlias alias="Blog" type="domain.blog.Blog"/>
<typeAlias alias="Comment" type="domain.blog.Comment"/>
<typeAlias alias="Post" type="domain.blog.Post"/>
<typeAlias alias="Section" type="domain.blog.Section"/>
<typeAlias alias="Tag" type="domain.blog.Tag"/>
</typeAliases>
当这样配置时,Blog 可以用在任何使用 domain.blog.Blog 的地方。
也可以指定一个包名,MyBatis 会在包名下面搜索需要的 Java Bean,比如:1
2
3<typeAliases>
<package name="domain.blog"/>
</typeAliases>
每一个在包 domain.blog 中的 Java Bean,在没有注解的情况下,会使用 Bean 的首字母小写的非限定类名来作为它的别名。 比如 domain.blog.Author 的别名为 author;若有注解,则别名为其注解值。见下面的例子:1
2
3
4
public class Author {
...
}
typehandlers
MyBatis 在设置预处理语句(PreparedStatement)中的参数或从结果集中取出一个值时, 都会用类型处理器将获取到的值以合适的方式转换成 Java 类型。
插件(plugins)
MyBatis 允许你在映射语句执行过程中的某一点进行拦截调用。默认情况下,MyBatis 允许使用插件来拦截的方法调用包括:
- Executor (update, query, flushStatements, commit, rollback, getTransaction, close, isClosed)
- ParameterHandler (getParameterObject, setParameters)
- ResultSetHandler (handleResultSets, handleOutputParameters)
- StatementHandler (prepare, parameterize, batch, update, query)
这些类中方法的细节可以通过查看每个方法的签名来发现,或者直接查看 MyBatis 发行包中的源代码。 如果你想做的不仅仅是监控方法的调用,那么你最好相当了解要重写的方法的行为。 因为在试图修改或重写已有方法的行为时,很可能会破坏 MyBatis 的核心模块。 这些都是更底层的类和方法,所以使用插件的时候要特别当心。
通过 MyBatis 提供的强大机制,使用插件是非常简单的,只需实现 Interceptor 接口,并指定想要拦截的方法签名即可。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23// ExamplePlugin.java
({(
type= Executor.class,
method = "update",
args = {MappedStatement.class,Object.class})})
public class ExamplePlugin implements Interceptor {
private Properties properties = new Properties();
public Object intercept(Invocation invocation) throws Throwable {
// implement pre processing if need
Object returnObject = invocation.proceed();
// implement post processing if need
return returnObject;
}
public void setProperties(Properties properties) {
this.properties = properties;
}
}
<!-- mybatis-config.xml -->
<plugins>
<plugin interceptor="org.mybatis.example.ExamplePlugin">
<property name="someProperty" value="100"/>
</plugin>
</plugins>
上面的插件将会拦截在 Executor 实例中所有的 “update” 方法调用, 这里的 Executor 是负责执行底层映射语句的内部对象。
xml映射器
MyBatis 的真正强大在于它的语句映射,这是它的魔力所在。由于它的异常强大,映射器的 XML 文件就显得相对简单。如果拿它跟具有相同功能的 JDBC 代码进行对比,你会立即发现省掉了将近 95% 的代码。MyBatis 致力于减少使用成本,让用户能更专注于 SQL 代码。
SQL 映射文件只有很少的几个顶级元素(按照应被定义的顺序列出):
cache– 该命名空间的缓存配置。cache-ref– 引用其它命名空间的缓存配置。resultMap– 描述如何从数据库结果集中加载对象,是最复杂也是最强大的元素。parameterMap– 老式风格的参数映射。此元素已被废弃,并可能在将来被移除!请使用行内参数映射。文档中不会介绍此元素。sql– 可被其它语句引用的可重用语句块。insert– 映射插入语句。update– 映射更新语句。delete– 映射删除语句。select– 映射查询语句。
常用属性
| 属性 | 描述 |
|---|---|
id | 在命名空间中唯一的标识符,可以被用来引用这条语句。 |
parameterType | 将会传入这条语句的参数的类全限定名或别名。这个属性是可选的,因为 MyBatis 可以根据语句中实际传入的参数计算出应该使用的类型处理器(TypeHandler),默认值为未设置(unset)。 |
resultType | 期望从这条语句中返回结果的类全限定名或别名。 注意,如果返回的是集合,那应该设置为集合包含的类型,而不是集合本身的类型。 resultType 和 resultMap 之间只能同时使用一个。 |
resultMap | 对外部 resultMap 的命名引用。结果映射是 MyBatis 最强大的特性,如果你对其理解透彻,许多复杂的映射问题都能迎刃而解。 resultType 和 resultMap 之间只能同时使用一个。 |
特殊字符处理,转义或CDATA区
参数占位符:#{} ${}
参数映射
鉴于参数类型(parameterType)会被自动设置为 int,这个参数可以随意命名。原始类型或简单数据类型(比如 Integer 和 String)因为没有其它属性,会用它们的值来作为参数。


不需要使用 @Param 的情况
单个参数:如果你的 Mapper 方法只接受一个参数,那么你不需要使用
@Param注解。MyBatis 会自动将这个参数映射到 SQL 语句中的占位符。1
List<User> selectUserByUserName(String username);
在对应的 XML 映射文件中可以直接引用该参数:
1
2
3<select id="selectUserByUserName" resultType="User">
SELECT * FROM users WHERE username = #{username}
</select>Java Bean 参数:如果你直接传递一个 Java Bean 对象作为参数,MyBatis 可以通过 OGNL 表达式访问 Bean 的属性,因此也不需要使用
@Param。1
List<User> selectUserByCondition(User user);
在 XML 文件中可以通过点符号访问属性:
1
2
3<select id="selectUserByCondition" resultType="User">
SELECT * FROM users WHERE username = #{username} AND age = #{age}
</select>
需要使用 @Param 的情况
多个简单类型参数:如果 Mapper 方法接受多个简单类型的参数(如
int,String等),你需要使用@Param来为每个参数指定一个名称,以便在 SQL 语句中引用它们。1
List<User> selectUsersByAgeAndUsername( int age, String username);
在 XML 文件中可以这样引用这些参数:
1
2
3<select id="selectUsersByAgeAndUsername" resultType="User">
SELECT * FROM users WHERE age = #{age} AND username = #{username}
</select>为了提高代码可读性:即使只有一个参数,有时候为了增加代码的可读性和明确性,也可以选择使用
@Param注解来命名参数。Map 类型参数:当使用 Map 传递参数时,通常也需要指定键名来访问值。在这种情况下,虽然不强制要求使用
@Param,但你可以通过 Map 的键来访问值。1
List<User> selectUsersByConditions(Map<String, Object> params);
1
2
3<select id="selectUsersByConditions" resultType="User">
SELECT * FROM users WHERE age = #{age} AND username = #{username}
</select>
总结
- 如果是单个参数或者传递的是 Java Bean,则通常不需要使用
@Param。 - 当方法有多个简单类型参数时,必须使用
@Param来为每个参数指定名称,以便在 SQL 语句中引用。 - 使用
@Param还有助于提高代码的可读性和维护性,尤其是在参数较多或逻辑较为复杂的情况下。
Java Bean 是一种符合特定规范的 Java 类,主要用于封装数据。它是 Java 中的一种标准,旨在使对象更容易被复用和管理,尤其是在可视化开发工具中。一个典型的 Java Bean 通常具有以下特征:
特征
- 私有属性:类中的成员变量应该是私有的(
private),这意味着它们不能直接从类外部访问。- 无参构造器:必须提供一个公共的无参构造函数(默认构造器),以便能够实例化对象而不需要传递任何参数。这是为了确保可以通过反射机制创建对象实例,比如在框架内部(如Spring, MyBatis)。
- getter 和 setter 方法:对于每个私有属性,应该提供公共的 getter(获取值)和 setter(设置值)方法。这允许外部代码安全地访问和修改这些属性的值。
- 可序列化(可选):如果需要在网络上传输对象或者保存到文件中,那么这个类应该实现
Serializable接口。

结果映射
返回结果如果包含多个值,可以使用map.
如果使用 JavaBean 或 POJO(Plain Old Java Objects,普通老式 Java 对象)作为领域模型。MyBatis 对两者都提供了支持。看看下面这个 JavaBean:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25package com.someapp.model;
public class User {
private int id;
private String username;
private String hashedPassword;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getHashedPassword() {
return hashedPassword;
}
public void setHashedPassword(String hashedPassword) {
this.hashedPassword = hashedPassword;
}
}
基于 JavaBean 的规范,上面这个类有 3 个属性:id,username 和 hashedPassword。这些属性会对应到 select 语句中的列名。
这样的一个 JavaBean 可以被映射到 ResultSet,就像映射到 HashMap 一样简单。1
2
3
4
5<select id="selectUsers" resultType="com.someapp.model.User">
select id, username, hashedPassword
from some_table
where id = #{id}
</select>
类型别名是你的好帮手。使用它们,你就可以不用输入类的全限定名了。比如:1
2
3
4
5
6
7
8
9<!-- mybatis-config.xml 中 -->
<typeAlias type="com.someapp.model.User" alias="User"/>
<!-- SQL 映射 XML 中 -->
<select id="selectUsers" resultType="User">
select id, username, hashedPassword
from some_table
where id = #{id}
</select>
在这些情况下,MyBatis 会在幕后自动创建一个 ResultMap,再根据属性名来映射列到 JavaBean 的属性上。如果列名和属性名不能匹配上,可以在 SELECT 语句中设置列别名(这是一个基本的 SQL 特性)来完成匹配。比如:1
2
3
4
5
6
7
8<select id="selectUsers" resultType="User">
select
user_id as "id",
user_name as "userName",
hashed_password as "hashedPassword"
from some_table
where id = #{id}
</select>
在学习了上面的知识后,你会发现上面的例子没有一个需要显式配置 ResultMap,这就是 ResultMap 的优秀之处——你完全可以不用显式地配置它们。 虽然上面的例子不用显式配置 ResultMap。 但为了讲解,我们来看看如果在刚刚的示例中,显式使用外部的 resultMap 会怎样,这也是解决列名不匹配的另外一种方式。1
2
3
4
5<resultMap id="userResultMap" type="User">
<id property="id" column="user_id" />
<result property="username" column="user_name"/>
<result property="password" column="hashed_password"/>
</resultMap>
然后在引用它的语句中设置 resultMap 属性就行了(注意我们去掉了 resultType 属性)。比如:1
2
3
4
5<select id="selectUsers" resultMap="userResultMap">
select user_id, user_name, hashed_password
from some_table
where id = #{id}
</select>
sql元素可以用来定义可重用的 SQL 代码片段,以便在其它语句中使用。 参数可以静态地(在加载的时候)确定下来,并且可以在不同的 include 元素中定义不同的参数值。比如:1
<sql id="userColumns"> ${alias}.id,${alias}.username,${alias}.password </sql>
这个 SQL 片段可以在其它语句中使用,例如:1
2
3
4
5
6
7<select id="selectUsers" resultType="map">
select
<include refid="userColumns"><property name="alias" value="t1"/></include>,
<include refid="userColumns"><property name="alias" value="t2"/></include>
from some_table t1
cross join some_table t2
</select>
也可以在 include 元素的 refid 属性或内部语句中使用属性值,例如:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17<sql id="sometable">
${prefix}Table
</sql>
<sql id="someinclude">
from
<include refid="${include_target}"/>
</sql>
<select id="select" resultType="map">
select
field1, field2, field3
<include refid="someinclude">
<property name="prefix" value="Some"/>
<property name="include_target" value="sometable"/>
</include>
</select>
在INSERT和UPDATE时,可以获取自增的字段值.设置useGeneratedKeys和keyProperty
| 属性 | 描述 |
|---|---|
useGeneratedKeys | (仅适用于 insert 和 update)这会令 MyBatis 使用 JDBC 的 getGeneratedKeys 方法来取出由数据库内部生成的主键(比如:像 MySQL 和 SQL Server 这样的关系型数据库管理系统的自动递增字段),默认值:false。 |
keyProperty | (仅适用于 insert 和 update)指定能够唯一识别对象的属性,MyBatis 会使用 getGeneratedKeys 的返回值或 insert 语句的 selectKey 子元素设置它的值,默认值:未设置(unset)。如果生成列不止一个,可以用逗号分隔多个属性名称。 |
<insert>:用于插入新记录,返回受影响的行数或通过配置获取自增主键。<update>:用于更新现有记录,返回受影响的行数。<delete>:用于删除记录,返回受影响的行数。
动态SQL
- if
- choose (when, otherwise)
- trim (where, set)
- foreach

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15<select id="findActiveBlogLike"
resultType="Blog">
SELECT * FROM BLOG
<where>
<if test="state != null">
state = #{state}
</if>
<if test="title != null">
AND title like #{title}
</if>
<if test="author != null and author.name != null">
AND author_name like #{author.name}
</if>
</where>
</select>
where 元素只会在子元素返回任何内容的情况下才插入 “WHERE” 子句。而且,若子句的开头为 “AND” 或 “OR”,where 元素也会将它们去除。
用于动态更新语句的类似解决方案叫做 set。set 元素可以用于动态包含需要更新的列,忽略其它不更新的列。比如:1
2
3
4
5
6
7
8
9
10<update id="updateAuthorIfNecessary">
update Author
<set>
<if test="username != null">username=#{username},</if>
<if test="password != null">password=#{password},</if>
<if test="email != null">email=#{email},</if>
<if test="bio != null">bio=#{bio}</if>
</set>
where id=#{id}
</update>
这个例子中,set 元素会动态地在行首插入 SET 关键字,并会删掉额外的逗号(这些逗号是在使用条件语句给列赋值时引入的)。
或者,你可以通过使用trim元素来达到同样的效果:1
2
3<trim prefix="SET" suffixOverrides=",">
...
</trim>
注意,我们覆盖了后缀值设置,并且自定义了前缀值
可以使用mybatisx插件提升开发效率
相关视频
Hibernate
Hibernate - Native SQL - GeeksforGeeks
Getting Started with Hibernate
maven依赖1
2
3
4
5<dependency>
<groupId>org.hibernate.orm</groupId>
<artifactId>hibernate-core</artifactId>
<version>6.6.10.Final</version>
</dependency>
配置
配置文件hibernate.properties1
2
3
4
5
6
7
8
9
10
11
12# Database connection settings
=jdbc:h2:mem:db1;DB_CLOSE_DELAY=-1
=sa
=
# Echo all executed SQL to console
=true
=true
=true
# Automatically export the schema
=create
创建注解实体类1
2
3
4
5
6
7
8
9
10
public class Event {
private Long id;
private LocalDateTime date;
//实体其他字段默认被认为是持久的。
}
使用sessionFactory1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27protected void setUp() {
// A SessionFactory is set up once for an application!
final StandardServiceRegistry registry =
new StandardServiceRegistryBuilder()
.build();
try {
sessionFactory =
new MetadataSources(registry)
.addAnnotatedClass(Event.class)
.buildMetadata()
.buildSessionFactory();
}
catch (Exception e) {
// The registry would be destroyed by the SessionFactory, but we
// had trouble building the SessionFactory so destroy it manually.
StandardServiceRegistryBuilder.destroy(registry);
}
sessionFactory.inTransaction(session -> {
session.persist(new Event("Our very first event!", now()));
session.persist(new Event("A follow up event", now()));
});
sessionFactory.inTransaction(session -> {
session.createSelectionQuery("from Event", Event.class)
.getResultList()
.forEach(event -> out.println("Event (" + event.getDate() + ") : " + event.getTitle()));
});
}
上面是native hibernate APIs
此外还可以使用JPA标准APIs
5.x版本的hibernate使用cfg和hbm提供映射,但新版本已经不用了.
>
JPA全称为Java Persistence API(Java持久层API),它是Sun公司在JavaEE 5中提出的Java持久化规范。它为Java开发人员提供了一种对象/关联映射工具,来管理Java应用中的关系数据,JPA吸取了目前Java持久化技术的优点,旨在规范、简化Java对象的持久化工作。很多ORM框架都是实现了JPA的规范,如:Hibernate、EclipseLink。
需要注意的是JPA统一了Java应用程序访问ORM框架的规范
JPA为我们提供了以下规范:
- ORM映射元数据:JPA支持XML和注解两种元数据的形式,元数据描述对象和表之间的映射关系,框架据此将实体对象持久化到数据库表中
- JPA 的API:用来操作实体对象,执行CRUD操作,框架在后台替我们完成所有的事情,开发人员不用再写SQL了
- JPQL查询语言:通过面向对象而非面向数据库的查询语言查询数据,避免程序的SQL语句紧密耦合。
Spring Data JPA
Spring Data是Spring 社区的一个子项目,主要用于简化数据(关系型&非关系型)访问,其主要目标是使得数据库的访问变得方便快捷。
Spring Data JPA是在实现了JPA规范的基础上封装的一套 JPA 应用框架,虽然ORM框架都实现了JPA规范,但是在不同的ORM框架之间切换仍然需要编写不同的代码,而使用Spring Data JPA能够方便大家在不同的ORM框架之间进行切换而不需要更改代码。
Core concepts :: Spring Data JPA
Spring Data JPA往往搭配Spring以及SpringBoot使用.
使用注解创建POJO类1
2
3
4
5
6
7
8
9
10
class Person {
private Long id;
private String name;
// getters and setters omitted for brevity
}
声明仓库接口1
2
3
4
5
6interface PersonRepository extends Repository<Person, Long> {
Person save(Person person);
Optional<Person> findById(long id);
}
使用仓库1
2
3
4
5
6
7
8
9
10
11
12
13
14import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
public class UserService {
private UserRepository userRepository;
public void addUser(String name) {
User user = new User();
user.setName(name);
userRepository.save(user);
}
}
增加自定义的CRUD方法1
2
3public interface UserRepository extends CrudRepository<User, Long> {
List<User> findByName(String name); // 根据名字查找用户
}
按照相关规范生成相应JPQL查询.
基本原则
- 实体属性作为基础:查询方法通常基于实体类中的属性名称构建。例如,如果你有一个
User实体,并且这个实体有一个name属性,你可以创建一个以findByName开头的方法来查找具有特定名称的所有用户。 - 关键词用于指定操作:在方法名中使用特定的关键字可以指定你想要执行的操作类型(如查找、计数等)以及查询条件(如等于、包含等)。
对于更复杂的查询需求,如果方法名约定不能满足要求,可以使用 @Query 注解直接定义JPQL或原生SQL查询。1
2
3
4public interface UserRepository extends JpaRepository<User, Long> {
User findByEmailAddress(String emailAddress);
}
或者使用原生SQL:1
2
User findByEmailAddress(String emailAddress);
消息组件
Redis✨
基本操作
Redis 的主要特性
- 高性能:所有数据都存储在内存中,读写速度非常快。
- 持久化:支持 RDB 和 AOF 两种方式将内存中的数据保存到硬盘上,以防止数据丢失。
- 复制功能:支持主从复制,可以提高系统的可用性和扩展性。
- 事务支持:通过 MULTI, EXEC, DISCARD 和 WATCH 等命令实现简单的事务管理。
- 发布订阅模式:支持 Pub/Sub 消息传递模式。
- Lua 脚本支持:允许用户执行自定义逻辑,保证原子性。
- 键过期时间:可以为每个键设置生存时间,过期后自动删除。
数据类型
Redis 主要支持以下几种数据类型:
- string(字符串): 基本的数据存储单元,可以存储字符串、整数或者浮点数。
- hash(哈希):一个键值对集合,可以存储多个字段。
- list(列表):一个简单的列表,可以存储一系列的字符串元素。
- set(集合):一个无序集合,可以存储不重复的字符串元素。
- zset(sorted set:有序集合): 类似于集合,但是每个元素都有一个分数(score)与之关联。
- 位图(Bitmaps):基于字符串类型,可以对每个位进行操作。
- 超日志(HyperLogLogs):用于基数统计,可以估算集合中的唯一元素数量。
- 地理空间(Geospatial):用于存储地理位置信息。
- 发布/订阅(Pub/Sub):一种消息通信模式,允许客户端订阅消息通道,并接收发布到该通道的消息。
- 流(Streams):用于消息队列和日志存储,支持消息的持久化和时间排序。
- 模块(Modules):Redis 支持动态加载模块,可以扩展 Redis 的功能。
String
基本编码方式是RAW,基于简单动态字符串实现. 存储上限512MB.
如果存储的SDS长度小于44字节,则会采用EMBSTR,此时object head与SDSS是连续空间.
如果是整数值,并且在LONG_MAX之内,采用INT编码.不需要SDS部分,ptr直接指向整数.
1
object encoding key # 查询编码方式
List
从首、尾操作元素的列表

Set
单列集合,不保证有序性,保证元素唯一,求交集、并集和差集.
set采用HT编码(Dict),key用来存储元素,value统一为null.
当存储的所有数据为整数,并且元素数量不超过set-max-intset-entries时,Set会采用IntSet编码,节省内存.
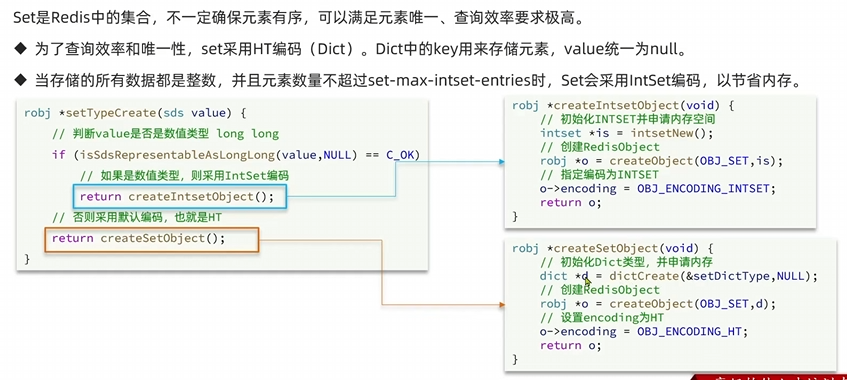
ZSet
每个元素指定一个score值
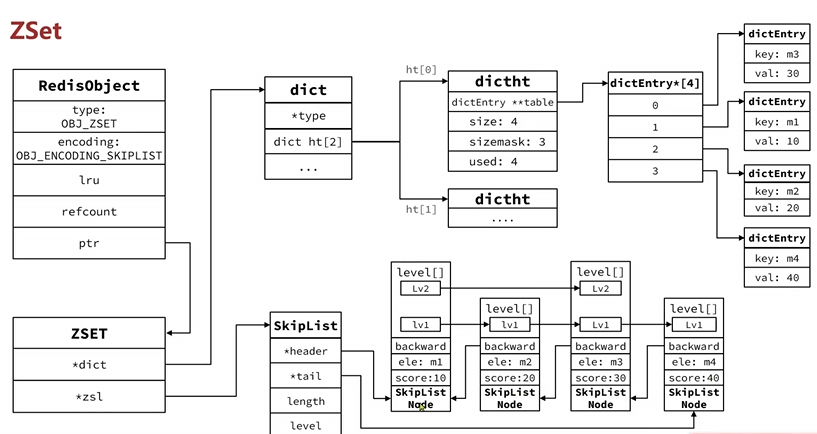


Hash
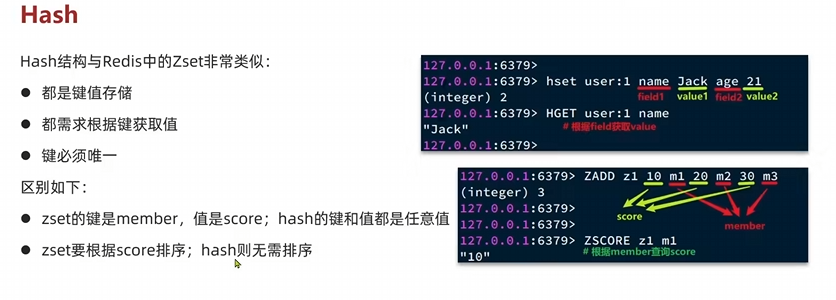
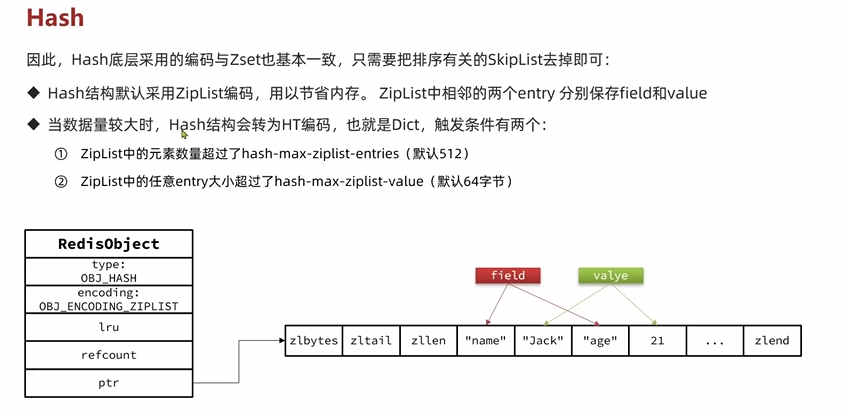
缓存穿透
缓存穿透是指客户端请求的数据在缓冲中和数据库中都不存在,这样缓存永远不会起作用,这些请求直接访问数据库.
缓存空对象
对于查询结果为空的数据,也可以将其缓存起来(通常设置较短的过期时间),这样当同样的请求再次到来时,可以直接从缓存中获取结果而不需要访问数据库。
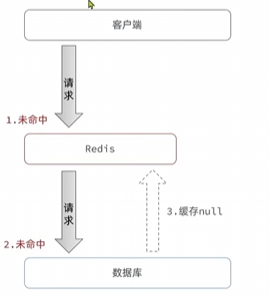
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18// 示例伪代码
public Object getData(String key) {
// 尝试从缓存获取数据
Object value = cache.get(key);
if (value != null) {
return value;
}
// 如果缓存未命中,则尝试从数据库获取
value = db.query(key);
if (value == null) {
// 对于不存在的数据也进行缓存,但设置较短的过期时间
cache.put(key, "NULL", SHORT_EXPIRE_TIME);
} else {
cache.put(key, value);
}
return value;
}
优点:实现简单,维护方便
缺点:额外的内存消耗,可能造成短期的不一致
布隆过滤
使用布隆过滤器可以在内存中高效地判断一个元素是否在一个集合中。它通过多个哈希函数将元素映射到位数组中的几个点,设置这些点为1。查询时,只要有一个对应的位不是1,就可以确定该元素不在集合中。1
2
3
4
5
6
7
8
9
10
11// 示例伪代码
BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(), expectedInsertions);
// 加载所有可能存在的key到布隆过滤器中
for (String key : allPossibleKeys) {
bloomFilter.put(key);
}
public boolean mightContain(String key) {
return bloomFilter.mightContain(key);
}
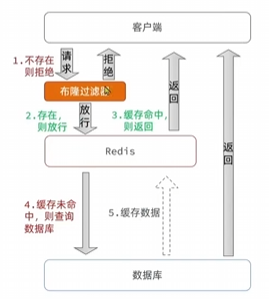
在实际应用中,你可以在查询之前先用布隆过滤器检查是否存在该键,只有当布隆过滤器认为该键可能存在时,才去数据库查询并更新缓存。
- 优点:节省空间且查询速度快。
- 缺点:有一定的误判率,即可能存在某些元素实际上不在集合中却被认为存在的假阳性情况,但对于缓存穿透问题来说,这通常是可接受的。
其他方法
接口限流与用户行为分析
合理的缓存策略设计

缓存雪崩
缓存雪崩是指在某个时间段内,大量的缓存数据同时过期失效,导致大量请求直接打到后端数据库或其他数据源上,造成服务器负载急剧增加,甚至可能导致系统崩溃的现象。这种情况通常发生在缓存层突然不可用或者缓存策略设计不合理时。
解决方案
- 设置不同的缓存过期时间
随机化过期时间,为避免大量缓存同时过期,可以在设定缓存的有效期时加入一定的随机性。例如,原本所有缓存的有效期都是1小时,现在可以设置成1小时±5分钟,这样可以分散缓存失效的时间点。
- 双缓存机制
实现两个级别的缓存,一级缓存用于快速响应请求,二级缓存则在一级缓存失效时提供支持。当一级缓存中的数据过期后,仍然可以从二级缓存中获取数据,从而减轻对数据库的压力。
其他
利用Redis集群提高服务可用性
给缓存业务添加降级限流策略
缓存击穿
缓存击穿是指一个非常热门的key,在缓存失效的瞬间,大量的请求同时访问这个key,由于此时缓存中没有该数据(已经过期或被删除),这些请求会直接打到数据库上,导致数据库压力骤增。这种情况类似于“击穿”了缓存层,直接冲击后端存储。
解决方案
1, 互斥锁
使用互斥锁可以在缓存失效时只允许一个线程去查询数据库并更新缓存,其他线程等待该线程完成后再从缓存中读取数据。这种方法能有效避免大量线程同时访问数据库。1
2
3
4
5
6
7
8
9
10
11
12
13
14public Object getData(String key) {
String lockKey = "lock:" + key;
Object value = cache.get(key);
if (value == null) { // 缓存未命中
synchronized(lockKey.intern()) { // 使用字符串内部池作为锁对象
value = cache.get(key); // 再次检查缓存,防止其他线程已经填充了缓存
if (value == null) {
value = db.query(key); // 查询数据库
cache.put(key, value); // 更新缓存
}
}
}
return value;
}
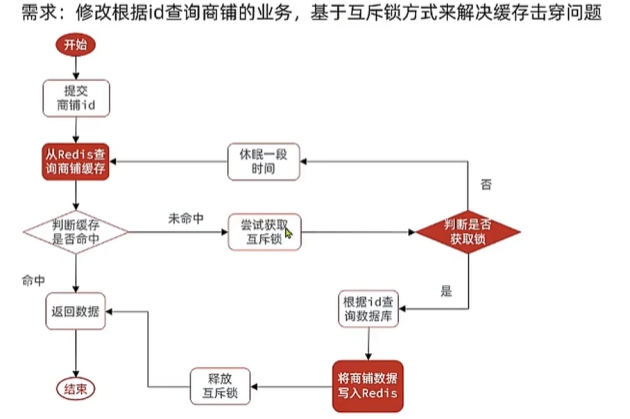
利用setnx实现互斥逻辑.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49String solvePassthrough(String key) {
// 1. 查询缓存是否存在
String s = redisTemplate.opsForValue().get(key);
if(s != null) {
//存在直接返回
return s ;
}else{
// 不存在 s==null,表示不存在
// 2. 缓存不存在,尝试拿锁
Boolean b = tryLock(key);
if(b) {
//3. 拿到锁,查询数据库
//"select * from table where key = " + key;
String result = "result";
if(result == null) {
// 数据库查询 没找到数据
// 设置空缓存对象 避免缓存穿透
redisTemplate.opsForValue().set(key, "", 10, TimeUnit.SECONDS);
unlock(key);
return null;
}
//4. 查询数据库后,将数据放入缓存
redisTemplate.opsForValue().set(key, result, 10, TimeUnit.SECONDS);
//5. 释放锁
unlock(key);
// 返回结果
return result;
}else{
//4. 没有拿到锁,等待重试
try {
Thread.sleep(1000);
return solvePassthrough(key);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}finally {
unlock(key);
}
}
}
}
Boolean tryLock(String key) {
Boolean b = redisTemplate.opsForValue().setIfAbsent(key, "1", 2, TimeUnit.SECONDS);
return b;
}
void unlock(String key) {
redisTemplate.delete(key);
}
2.逻辑过期
对于一些极其重要的热点数据,可以考虑将其缓存设置为永不过期。但是这种方式需要配合后台异步任务定期刷新缓存中的数据,以确保数据的时效性。

1
2
3
4
5
6
7
8
9
10
11// 假设我们有一个后台任务定期执行此方法
public void refreshHotData() {
String hotKey = "hot_data";
Object newValue = db.query(hotKey); // 从数据库获取最新数据
cache.put(hotKey, newValue); // 更新缓存
}
// 在业务逻辑中获取数据时,直接从缓存读取即可
public Object getHotData() {
return cache.get("hot_data");
}
可以增加过期时间,在业务层进行判断,如果实际已经过期(此时Redis中仍有数据,因为没有超过TTL). 则创建线程更新数据并写入缓存(加锁),原本线程返回过期数据.

内存持久化
RDB
Redis SAVE 命令用于创建当前数据库的备份
创建 redis 备份文件也可以使用命令 BGSAVE,该命令在后台执行。
basave会fork主进程得到子进程,子进程共享主进程的内存数据,完成fork后读取内存数据写入RDB文件.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24################################ SNAPSHOTTING
# Note: you can disable saving completely by commenting out all "save" lines.
#
# It is also possible to remove all the previously configured save
# points by adding a save directive with a single empty string argument
# like in the following example:
#
# save ""
save 900 1
save 300 10
save 60 10000
rdbcompression yes
# The filename where to dump the DB
dbfilename dump.rdb
# The working directory.
#
# The DB will be written inside this directory, with the filename specified
# above using the 'dbfilename' configuration directive.
#
# The Append Only File will also be created inside this directory.
#
# Note that you must specify a directory here, not a file name.
dir ./



AOF
APPEND ONLY MODE1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30############################## APPEND ONLY MODE ###############################
# still running correctly.
#
# AOF and RDB persistence can be enabled at the same time without problems.
# If the AOF is enabled on startup Redis will load the AOF, that is the file
# with the better durability guarantees.
#
# Please check http://redis.io/topics/persistence for more information.
appendonly no
# The name of the append only file (default: "appendonly.aof")
appendfilename "appendonly.aof"
# The default is "everysec", as that's usually the right compromise between
# speed and data safety. It's up to you to understand if you can relax this to
# "no" that will let the operating system flush the output buffer when
# it wants, for better performances (but if you can live with the idea of
# some data loss consider the default persistence mode that's snapshotting),
# or on the contrary, use "always" that's very slow but a bit safer than
# everysec.
#
# More details please check the following article:
# http://antirez.com/post/redis-persistence-demystified.html
#
# If unsure, use "everysec".
# appendfsync always
appendfsync everysec
# appendfsync no

使用bgrewriteaof节省AOF文件,因为记录的AOF命令可能多余(比如后面的更新了前面的值)

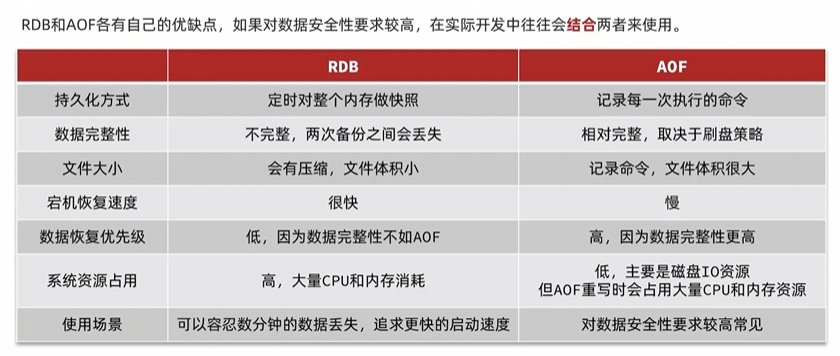
事务
Redis 提供了一种简单的事务机制,它允许用户将多个命令打包成一个事务进行执行。与传统数据库中的事务不同,Redis 的事务并不支持回滚(rollback)操作。
Redis 事务的关键命令
- MULTI:标记一个事务块的开始。一旦调用了
MULTI命令,客户端会进入事务模式,在这种模式下所有的后续命令都会被放入队列中等待执行,而不是立即执行。 - EXEC:执行所有在
MULTI和EXEC之间的命令。当调用EXEC时,Redis 会顺序地执行事务队列中的每个命令,并返回每个命令的结果。 - DISCARD:取消事务,放弃执行事务队列中的所有命令并退出事务模式。
WATCH:用于监控一个或多个键,如果这些键在事务执行之前被其他客户端修改了,则事务会被中断,
EXEC返回nil表示事务未成功执行。这为 Redis 提供了一种乐观锁机制。原子性:虽然 Redis 的事务保证了命令序列要么全部执行,要么一个都不执行,但是 Redis 并不支持回滚功能。这意味着如果有任何命令执行失败,其余命令仍将继续执行。
- 乐观锁:通过
WATCH命令实现的乐观锁机制可以在一定程度上解决并发修改的问题。例如,在对某个键进行修改前先WATCH它,然后执行一系列的操作,最后通过EXEC提交事务。如果在这期间有其他客户端修改了该键,则当前事务将被中断,EXEC将返回nil。
单个 Redis 命令的执行是原子性的,但 Redis 没有在事务上增加任何维持原子性的机制,所以 Redis 事务的执行并不是原子性的。
事务可以理解为一个打包的批量执行脚本,但批量指令并非原子化的操作,中间某条指令的失败不会导致前面已做指令的回滚,也不会造成后续的指令不做。
1 | WATCH mykey |
RabbitMQ✨
Kafka
RocketMQ
网络编程框架
Netty
Spring家族✨
Spring提供依赖注入(DI),控制反转(IOC),面向切面编程等,为Java开发提供便利.而SpringMVC提供了比纯Servlet更好的开发体验.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56package org.example.MyServlets;
/**
* @Author: proanimer
* @Description:
* @Date: Created in 2025/3/10
* @Modified By proanimer
*/
// Servlet实现web请求响应
import jakarta.servlet.ServletException;
import jakarta.servlet.annotation.WebServlet;
import jakarta.servlet.http.HttpServlet;
import jakarta.servlet.http.HttpServletRequest;
import jakarta.servlet.http.HttpServletResponse;
import java.io.IOException;
import java.io.PrintWriter;
/**
* @projectName: workspace
* @package: org.example.MyServlets
* @className: MyServlet
* @author: proanimer
* @description:
* @date: 2025/3/10 20:01
*/
public class MyServlet extends HttpServlet {
private static final long serialVersionUID = 1L;
public MyServlet() {
super();
}
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
resp.setContentType("text/html;charset=UTF-8");
try(PrintWriter out = resp.getWriter()) {
out.println("<html>");
out.println("<head>");
out.println("<title>MyServlet</title>");
out.println("</head>");
out.println("<body>");
out.println("<h1>MyServlet</h1>");
out.println("</body>");
out.println("</html>");
}
}
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
doGet(req,resp);
}
}
spring
IOC容器
依赖注入(DI)是 IoC 的一种特殊形式,其中对象仅通过构造函数参数、工厂方法参数或在对象实例构建或从工厂方法返回后设置的属性来定义其依赖(即它们与之一起工作的其他对象)。IoC 容器在创建 bean 时注入这些依赖。这个过程本质上是 bean 本身通过直接构建类或如Service Locator pattern等机制控制其依赖的实例化或位置的反向(因此得名,控制反转)。
Spring 框架支持多种配置方式,包括基于 XML 的配置、基于注解的配置以及基于 Java 配置类的配置。
spring6.x版本官方文档已经不再详细说xml配置,主流是java配置类.
- XML 配置:适用于传统的 Spring 应用程序,提供了对 Spring 容器的详细控制。
- 注解配置:减少了 XML 配置的需求,使得代码更加简洁,但可能不如 XML 配置那样直观地看到整个应用程序的结构。
- Java 配置类:提供了一种类型安全的方式来配置 Spring 应用程序,尤其适合新的项目或微服务架构。
org.springframework.beans 和 org.springframework.context 包是 Spring 框架 IoC 容器的基石。 BeanFactory 接口提供了一种高级配置机制,能够管理任何类型的对象。 ApplicationContext 是 BeanFactory 的子接口。
Spring容器就是
ApplicationContext,它是一个接口,有很多实现类,比如ClassPathXmlApplicationContext,表示它会自动从classpath中查找指定的XML配置文件。
BeanFactory 接口提供了一种高级配置机制,能够管理任何类型的对象,它是SpringIoC容器标准化超接口!
ApplicationContext 是 BeanFactory 的子接口。它扩展了以下功能:
- 更容易与 Spring 的 AOP 功能集成
- 消息资源处理(用于国际化)
- 特定于应用程序给予此接口实现,例如Web 应用程序的
WebApplicationContext
简而言之, BeanFactory 提供了配置框架和基本功能,而 ApplicationContext 添加了更多特定于企业的功能。 ApplicationContext 是 BeanFactory 的完整超集
ApplicationContext容器实现类:
| 类型名 | 简介 |
|---|---|
| ClassPathXmlApplicationContext | 通过读取类路径下的 XML 格式的配置文件创建 IOC 容器对象 |
| FileSystemXmlApplicationContext | 通过文件系统路径读取 XML 格式的配置文件创建 IOC 容器对象 |
| AnnotationConfigApplicationContext | 通过读取Java配置类创建 IOC 容器对象 |
| WebApplicationContext | 专门为 Web 应用准备,基于 Web 环境创建 IOC 容器对象,并将对象引入存入 ServletContext 域中。 |
IoC 容器的基本职责包括:
- 实例化 Bean。
- 设置 Bean 的属性值和生命周期回调。
- 管理 Bean 之间的依赖关系。
- 控制 Bean 的作用域(如 singleton, prototype 等)。
Spring 提供了两种类型的 IoC 容器:
- BeanFactory:提供了基础的功能来管理和操作 Bean,适合资源受限的环境。
- ApplicationContext:扩展了
BeanFactory,增加了事件发布、国际化支持、AOP 集成等功能,适用于大多数应用场合。
通常情况下,开发者更倾向于使用 ApplicationContext,因为它提供了更多的功能和便利性。
2. ApplicationContext 的实现类
Spring 提供了几种 ApplicationContext 的实现类,每种都有其特定的应用场景:
- ClassPathXmlApplicationContext:从类路径下的 XML 文件加载 Bean 定义。
- FileSystemXmlApplicationContext:从文件系统中指定位置的 XML 文件加载 Bean 定义。
- AnnotationConfigApplicationContext:用于基于 Java 注解的配置,不依赖于 XML 文件。
- WebApplicationContext:专为 Web 应用设计,支持 Servlet 上下文,并且可以方便地集成到 Web 应用程序中。
3. Bean 定义
在 Spring 中,Bean 定义是描述如何创建一个 Bean 的元数据。可以通过以下方式定义 Bean:
- XML 配置文件:传统方式,通过 XML 文件定义 Bean 及其依赖关系。
- 注解:例如
@Component,@Service,@Repository,@Controller等,配合@Autowired或构造函数注入。 - Java 配置类:使用
@Configuration和@Bean注解定义 Bean。
构造器注入
1 | <bean id="exampleBean" class="com.example.ExampleBean"> |
<constructor-arg> 标签用于在 XML 配置文件中定义构造函数注入所需的参数。通过该标签,你可以指定将哪些值或 Bean 注入到目标类的构造函数中。<constructor-arg> 支持多个属性来帮助精确地匹配和注入依赖,主要包括 name, value, index, 和 type 等属性。下面详细介绍这些属性的意义:
name
用途:指定构造函数参数的名字。
适用场景:当目标类的构造函数使用命名参数时,可以通过
name属性明确指定要注入哪个参数。不过需要注意的是,Spring 在早期版本中并不直接支持按名称注入构造参数,而是根据类型和顺序(索引)进行匹配。从 Spring 3.0 开始,如果使用 CGLIB 来增强字节码,则可以支持基于名称的构造函数注入。示例
1
2
3<bean id="exampleBean" class="com.example.ExampleClass">
<constructor-arg name="paramName" value="someValue"/>
</bean>
value
用途:直接为基本数据类型或 String 类型的构造函数参数提供值。
适用场景:适用于需要传递简单类型的值作为构造函数参数的情况。
示例:
1
2
3<bean id="exampleBean" class="com.example.ExampleClass">
<constructor-arg index="0" value="Hello, World!"/>
</bean>这里”Hello, World!”将被作为第一个参数传递给ExampleClass的构造函数。
index
用途:指定构造函数参数的位置索引,以确定向哪个参数注入值。
适用场景:当你有多个构造函数参数并且想要精确控制哪个参数接收哪个值时非常有用。
注意事项:索引是从 0 开始的。
示例:
1
2
3
4<bean id="exampleBean" class="com.example.ExampleClass">
<constructor-arg index="0" value="First Argument"/>
<constructor-arg index="1" ref="anotherBean"/>
</bean>
type
用途:指定构造函数参数的数据类型,帮助 Spring 容器更准确地选择合适的构造函数(特别是在存在重载构造函数的情况下)。
适用场景:当你有多个同名但不同类型的构造函数参数时,或者你需要确保特定类型的值被注入时使用。
示例:
1
2
3<bean id="exampleBean" class="com.example.ExampleClass">
<constructor-arg type="java.lang.String" value="String Argument"/>
<constructor-arg type="int" value="123"/>
Java配置类1
2
3
4
5
6
7
8
9
10
11
12
13
14
public class AppConfig {
public MyRepository myRepository() {
return new MyRepositoryImpl();
}
public MyService myService() {
// 使用构造函数注入
return new MyServiceImpl(myRepository());
}
}
静态工厂方法
1 | <bean id="clientService" class="com.example.ClientService" factory-method="createInstance"/> |
利用工厂类的静态方法
实例工厂方法
利用工厂的实例方法
首先定义工厂 Bean1
<bean id="serviceFactory" class="com.example.ServiceFactory"/>
然后,使用这个工厂 Bean 的方法来创建目标 Bean。1
<bean id="clientService" factory-bean="serviceFactory" factory-method="createClientServiceInstance"/>
这里假设 ServiceFactory 类中有一个名为 createClientServiceInstance 的方法,用于创建并返回一个新的 ClientService 实例。
注解方式创建工厂Bean
用工厂模式创建Bean需要实现FactoryBean接口。我们观察下面的代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
public class ZoneIdFactoryBean implements FactoryBean<ZoneId> {
String zone = "Z";
public ZoneId getObject() throws Exception {
return ZoneId.of(zone);
}
public Class<?> getObjectType() {
return ZoneId.class;
}
}
当一个Bean实现了FactoryBean接口后,Spring会先实例化这个工厂,然后调用getObject()创建真正的Bean。getObjectType()可以指定创建的Bean的类型,因为指定类型不一定与实际类型一致,可以是接口或抽象类。
因此,如果定义了一个FactoryBean,要注意Spring创建的Bean实际上是这个FactoryBean的getObject()方法返回的Bean。为了和普通Bean区分,我们通常都以XxxFactoryBean命名。
由于可以用@Bean方法创建第三方Bean,本质上@Bean方法就是工厂方法,所以,FactoryBean已经用得越来越少了。
实例化后设置属性
这是最常见的 Bean 实例化方式之一,在 Bean 被实例化之后,通过 setter 方法设置其属性。1
2
3
4
5
6<bean id="exampleBean" class="com.example.ExampleBean">
<property name="property1" value="value1"/>
<property name="property2" ref="anotherBean"/>
</bean>
<bean id="anotherBean" class="com.example.AnotherBean"/>
在这个例子中,ExampleBean 有两个属性 property1 和 property2,它们分别通过 set 方法被赋值
注解Annotation配置
使用XML配置的优点是所有的Bean都能一目了然地列出来,并通过配置注入能直观地看到每个Bean的依赖。它的缺点是写起来非常繁琐,每增加一个组件,就必须把新的Bean配置到XML中。
可以使用Annotation配置,可以完全不需要XML,让Spring自动扫描Bean并组装它们。
@Component注解就相当于定义了一个Bean,它有一个可选的名称,默认是mailService,即小写开头的类名。
使用Java配置类
Bean的声明周期管理
Bean 生命周期的基本流程
一个典型的 Spring Bean 生命周期包括以下几个步骤:
- 实例化:根据配置元数据(如 XML 配置、Java 注解或 Java 配置类),Spring 容器首先实例化 Bean。
- 设置属性值:将 Bean 实例化后,Spring 会为该 Bean 设置属性值和其他依赖注入。
- 初始化前:如果实现了
Aware系列接口(例如BeanNameAware,BeanFactoryAware,ApplicationContextAware),则调用这些接口的方法,让 Bean 能够感知其环境信息。 - BeanPostProcessor 前处理:如果存在实现了
BeanPostProcessor接口的 Bean,则调用其postProcessBeforeInitialization方法。这是对所有 Bean 都适用的一个扩展点。 - 初始化:
- 如果 Bean 实现了
InitializingBean接口,则调用afterPropertiesSet()方法。 - 如果指定了
<bean>元素的init-method属性或使用了@PostConstruct注解,则调用指定的初始化方法。
- 如果 Bean 实现了
- BeanPostProcessor 后处理:接着再次调用实现了
BeanPostProcessor接口的postProcessAfterInitialization方法。 - 使用阶段:此时 Bean 已经准备好并可以被应用程序使用了。
- 销毁阶段:
- 当容器关闭时,如果 Bean 实现了
DisposableBean接口,则调用destroy()方法。 - 如果指定了
<bean>元素的destroy-method属性或使用了@PreDestroy注解,则调用指定的销毁方法。
- 当容器关闭时,如果 Bean 实现了
2. 控制 Bean 生命周期的关键接口和注解
Aware系列接口:用于让 Bean 感知到容器的一些信息。BeanNameAware: 获取 Bean 的名称。BeanFactoryAware: 获取 BeanFactory。ApplicationContextAware: 获取 ApplicationContext。
BeanPostProcessor接口:提供两个方法用于前后处理 Bean 初始化逻辑。postProcessBeforeInitialization(Object bean, String beanName)在初始化之前调用。postProcessAfterInitialization(Object bean, String beanName)在初始化之后调用。
InitializingBean接口:提供afterPropertiesSet()方法,在所有属性设置完成后执行自定义初始化逻辑。DisposableBean掀口:提供destroy()方法,在容器关闭时执行清理工作。- 注解支持:
@PostConstruct:标注在方法上,表示这是一个初始化方法。@PreDestroy:标注在方法上,表示这是一个销毁方法。
在 Spring 框架中,Bean 的作用域(Scope)决定了 Bean 实例的作用范围和生命周期。Spring 提供了多种内置的作用域类型,每种类型适用于不同的场景。理解这些作用域可以帮助你更好地控制 Bean 的行为,确保它们在应用程序中的正确使用。
- 实例化(Instantiation):
- Spring容器根据Bean定义的信息创建Bean的实例。
- 属性赋值(Populate):
- Spring容器将配置文件中的属性值或者依赖注入到Bean实例中。这一步通常通过setter方法完成,也可以通过构造函数注入。
- 设置其他属性:
- 如果Bean实现了
BeanNameAware接口,Spring会调用setBeanName(String name)方法,传入Bean的名字。- 如果Bean实现了
BeanFactoryAware接口,Spring会调用setBeanFactory(BeanFactory beanFactory)方法,传入BeanFactory的实例。- 如果Bean实现了
ApplicationContextAware接口,Spring会调用setApplicationContext(ApplicationContext applicationContext)方法,传入ApplicationContext的实例。- 初始化前处理(Initialization Before Processing):
- 如果有实现
BeanPostProcessor接口的后处理器,它们的postProcessBeforeInitialization(Object bean, String beanName)方法会被调用。- 初始化(Initialization):
- 如果Bean实现了
InitializingBean接口,Spring会调用其afterPropertiesSet()方法。- 如果在XML配置中指定了
init-method属性,那么对应的自定义初始化方法也会被调用。- 也可以使用
@PostConstruct注解来指定初始化方法。- 初始化后处理(Initialization After Processing):
- 如果有实现
BeanPostProcessor接口的后处理器,它们的postProcessAfterInitialization(Object bean, String beanName)方法会被调用。- 使用Bean:
- 此时Bean已经完全初始化,可以正常使用了。
- 销毁前处理(Destruction Before Processing):
- 当容器关闭时,如果Bean实现了
DisposableBean接口,Spring会调用其destroy()方法。- 如果在XML配置中指定了
destroy-method属性,那么对应的自定义销毁方法也会被调用。- 同样可以使用
@PreDestroy注解来指定销毁方法。
1. 常见的 Bean 作用域
(1) Singleton(单例)
- 默认作用域:如果未指定作用域,默认为
singleton。 - 行为:Spring 容器在整个应用上下文中只会创建一个该类型的 Bean 实例,并且所有对该 Bean 的请求都会返回这个唯一的实例。
- 适用场景:大多数情况下,特别是对于无状态的服务类,如服务层、数据访问层等。
1 | <bean id="exampleBean" class="com.example.ExampleClass" scope="singleton"/> |
或通过注解:1
2
3
4
5
public class ExampleClass {
// ...
}
(2) Prototype(原型)
- 行为:每次对 Bean 的请求都会创建一个新的实例。
- 适用场景:当需要每次获取到的是一个新的对象实例时使用,例如命令对象、Web 控制器等。
1 | <bean id="exampleBean" class="com.example.ExampleClass" scope="prototype"/> |
或通过注解:1
2
3
4
5
public class ExampleClass {
// ...
}
此外还有Request,Session和Application等作用域.
选择性实例化Bean
选择性实例化 Bean 是指根据某些条件动态决定是否创建某个 Bean 实例。Spring 提供了多种机制来实现这种功能,例如使用注解、配置文件或编程方式
使用 @Conditional 注解
@Conditional 是 Spring 中的一个核心注解,用于根据特定条件决定是否加载某个 Bean。
(1) 工作原理
@Conditional接受一个实现了Condition接口的类作为参数。- 在运行时,Spring 会调用
Condition的matches()方法,如果返回true,则加载该 Bean;否则跳过。
(2) 示例代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27import org.springframework.context.annotation.Condition;
import org.springframework.context.annotation.ConditionContext;
import org.springframework.core.type.AnnotatedTypeMetadata;
// 自定义条件类
public class MyCondition implements Condition {
public boolean matches(ConditionContext context, AnnotatedTypeMetadata metadata) {
// 检查系统属性 "my.condition" 是否为 true
return Boolean.parseBoolean(System.getProperty("my.condition"));
}
}
// 配置类
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Conditional;
import org.springframework.context.annotation.Configuration;
public class AppConfig {
public MyBean myBean() {
return new MyBean();
}
}1
2
3
4
5# 不加载 MyBean
java -jar app.jar
# 加载 MyBean
java -Dmy.condition=true -jar app.jar
@Profile 是 Spring 中的一种更简单的条件加载机制,它根据当前激活的环境(profile)来决定是否加载某个 Bean。
(1) 工作原理
- 每个
@Profile注解可以指定一个或多个 profile 名称。 - 只有当这些 profile 被激活时,对应的 Bean 才会被加载。
(2) 示例代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Profile;
public class ProfileConfig {
public MyBean devBean() {
return new MyBean("Development Environment");
}
public MyBean prodBean() {
return new MyBean("Production Environment");
}
}
(3) 测试
启动程序时,可以通过指定激活的 profile 来加载不同的 Bean:1
2
3
4
5# 激活开发环境
java -Dspring.profiles.active=dev -jar app.jar
# 激活生产环境
java -Dspring.profiles.active=prod -jar app.jar
使用 FactoryBean 动态创建 Bean
FactoryBean 是 Spring 提供的一种接口,用于动态创建 Bean 实例。
(1) 工作原理
- 实现
FactoryBean接口,并重写getObject()方法。 - 在运行时,Spring 会调用
getObject()方法来获取实际的 Bean 实例。
(2) 示例代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28import org.springframework.beans.factory.FactoryBean;
public class MyBeanFactory implements FactoryBean<MyBean> {
private boolean enabled;
public MyBeanFactory(boolean enabled) {
this.enabled = enabled;
}
public MyBean getObject() throws Exception {
if (!enabled) {
throw new IllegalStateException("Bean creation is disabled!");
}
return new MyBean();
}
public Class<?> getObjectType() {
return MyBean.class;
}
public boolean isSingleton() {
return true;
}
}
(3) 配置1
2
3
4
5
6
7
8
9
10
11import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
public class FactoryBeanConfig {
public MyBeanFactory myBeanFactory() {
return new MyBeanFactory(Boolean.getBoolean("factory.bean.enabled"));
}
}
| 版本 | Bean 自动覆盖行为 |
|---|---|
| Spring Boot 2.0 | 允许用户定义相同类型的 Bean,Spring Boot 预置 Bean 被跳过。 |
| Spring Boot 2.1+ | Spring Boot 检测到多个相同类型 Bean 时,可能会有警告。 |
| Spring Boot 2.4+ | 默认不允许手动定义的 Bean 覆盖自动配置的 Bean(可通过 spring.main.allow-bean-definition-overriding=true 启用)。 |
| Spring Boot 3.0+ | 仍然默认不允许覆盖 Bean,除非手动启用 allow-bean-definition-overriding。 |
如何实现依赖注入
依赖注入是 IoC 的一种实现方式,允许对象定义其依赖关系而不必自行创建或查找依赖的对象。Spring 支持三种依赖注入类型:
- 构造器注入:通过构造函数参数注入依赖。
- Setter 方法注入:通过 setter 方法注入依赖。
- 字段注入:直接在字段上使用
@Autowired注解进行注入。
当 Spring 应用启动时,IoC 容器会根据 @Autowired 注解的信息去寻找相应的 Bean 并将其注入到目标对象中。以下是几种常见的注入方式:
- 构造函数注入
1 |
|
- 在这个例子中,Spring 将会查找类型为
MyService的 Bean,并将其注入到ServiceUser类的构造函数中。
- 字段注入
1 |
|
- 字段注入是最简单的形式,但它可能会导致难以进行单元测试,因为它绕过了类的构造函数。
- Setter 方法注入
1 |
|
- Setter 方法注入适合于那些可选依赖或希望在运行时更改依赖的情况
Bean 查找规则
Spring 容器按照以下顺序尝试解析依赖:
- 类型匹配:首先基于参数类型查找匹配的 Bean。
- 名称匹配:如果有多个相同类型的 Bean 存在,则根据参数名作为 Bean 名称进行匹配。
- 限定符(Qualifiers):当存在多个相同类型的 Bean 且名称也不足以区分时,可以使用
@Qualifier注解指定确切的 Bean 名称
如果你希望给 Bean 指定一个不同于方法名的名称,可以通过 @Bean 注解的 name 属性来实现或者 @Qualifier。例如:1
2
3
4
5
6
7
8
9
ZoneId createZoneOfZ() {
return ZoneId.of("Z");
}
ZoneId createZoneOfUTC8() {
return ZoneId.of("UTC+08:00");
}
@Autowired 标记的构造函数、字段或方法会被 Spring 容器扫描,并尝试找到匹配的 Bean 来注入。如果找到多个匹配的 Bean,则可能需要通过 @Qualifier 注解来指定具体的 Bean。
Spring 提供了多种注解用于实现依赖注入。以下是常用的注入注解及其用途:
1. 核心注入注解
(1) @Autowired
- 作用:自动注入依赖对象。
- 位置:
- 构造器
- 方法(如 setter 方法)
- 字段
- 参数
- 特点
- 默认按类型(byType)进行匹配。
- 如果有多个相同类型的 Bean,则会抛出异常,需要结合
@Qualifier使用。 注解用在构造器,setter,属性上和方法参数上
示例代码1
2
3
4
5
public class UserService {
private UserRepository userRepository; // 自动注入 UserRepository
}
(2) @Qualifier
- 作用:当存在多个相同类型的 Bean 时,指定要注入的具体 Bean。
- 配合:通常与
@Autowired配合使用。 - 特点:通过名称(byName)来限定注入的 Bean。
示例代码1
2
3
4
5
6
7
8
9
10
11
12
public class UserRepositoryV1 implements UserRepository { }
public class UserRepositoryV2 implements UserRepository { }
public class UserService {
private UserRepository userRepository; // 注入 UserRepositoryV1
}
(3) @Primary
- 作用:标记一个 Bean 为首选 Bean,当有多个相同类型的 Bean 时优先注入该 Bean。
- 特点:无需显式使用
@Qualifier,简化配置。
示例代码1
2
3
4
5
6
7
8
9
10
11
12
public class UserRepositoryV1 implements UserRepository { }
public class UserRepositoryV2 implements UserRepository { }
public class UserService {
private UserRepository userRepository; // 自动注入 UserRepositoryV1
}
(4) @Resource
- 作用:JSR-250 规范提供的注解,用于注入依赖。
- 特点
- 默认按名称(byName)进行匹配。
- 如果未找到匹配的名称,则按类型(byType)匹配。
- 区别:
@Resource是 Java 的标准注解,而@Autowired是 Spring 的注解。(推荐Resource而不是Autowired) 注解用在属性上和setter上.
示例代码1
2
3
4
5
6
7
8
public class UserRepository { }
public class UserService {
private UserRepository userRepository; // 按名称注入
}
(5) @Inject
- 作用:JSR-330 规范提供的注解,功能类似于
@Autowired。 - 特点:
- 默认按类型(byType)进行匹配。
- 需要引入
javax.inject包。
- 区别:
@Inject是 Java 的标准注解,而@Autowired是 Spring 的注解。
示例代码1
2
3
4
5
6
7
8
9
10import javax.inject.Inject;
public class UserRepository { }
public class UserService {
private UserRepository userRepository; // 自动注入
}
2. 高级注入注解
(6) @Value
- 作用:注入简单的值(如字符串、数字)、系统属性或配置文件中的值。
- 特点:支持占位符
${}和 SpEL 表达式#{}。
示例代码1
2
3
4
5
6
7
8
public class AppConfig {
private String appName; // 注入配置文件中的 app.name
private int sum; // 注入表达式的计算结果 (2 + 3 = 5)
}
(7) @ConfigurationProperties
- 作用:批量注入配置文件中的属性到一个 Java 对象中。
- 特点:适合处理复杂的配置结构。
示例代码1
2
3
4
5
6
7
8
9
10
11import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.stereotype.Component;
public class AppProperties {
private String name;
private int version;
// Getters and Setters
}
配置文件 (application.properties):1
2=MyApp
=1
(8) @Lookup
- 作用:用于方法注入,每次调用方法时都会返回一个新的 Bean 实例。
- 场景:适用于原型(Prototype)作用域的 Bean。
示例代码1
2
3
4
5
6
7
8
9
10
public class PrototypeBean { }
public abstract class SingletonBean {
public abstract PrototypeBean getPrototypeBean(); // 每次调用返回新的实例
}
3. 其他相关注解
(9) @Required
- 作用:标记某个 setter 方法必须注入值,否则抛出异常。
- 注意:从 Spring 5 开始已被废弃,推荐使用构造器注入或
@Autowired(required = true)。
示例代码1
2
3
4
5
6
7
8
9public class UserService {
private UserRepository userRepository;
public void setUserRepository(UserRepository userRepository) {
this.userRepository = userRepository;
}
}
(10) @Lazy
- 作用:延迟加载 Bean,只有在第一次使用时才会被创建。
- 特点:可以减少启动时间,适用于不常用的功能。
示例代码1
2
3
4
5
6
7
8
9
public class LazyBean { }
public class UserService {
private LazyBean lazyBean; // 延迟加载
}
4. 总结
| 注解 | 功能描述 | 特点 |
|---|---|---|
@Autowired | 自动注入依赖,按类型匹配 | 默认按类型,支持配合 @Qualifier 使用 |
@Qualifier | 指定要注入的 Bean 名称 | 按名称匹配 |
@Primary | 标记首选 Bean | 简化多 Bean 场景下的注入 |
@Resource | 按名称或类型注入 | JSR-250 标准注解 |
@Inject | 按类型注入 | JSR-330 标准注解 |
@Value | 注入简单值或配置文件中的值 | 支持占位符和 SpEL |
@ConfigurationProperties | 批量注入配置文件中的属性 | 适合复杂配置 |
@Lookup | 方法注入,每次返回新实例 | 适用于原型作用域 |
@Required | 强制要求注入 | 已废弃,推荐使用其他方式 |
@Lazy | 延迟加载 Bean | 减少启动时间 |
AOP的底层原理
如何把切面织入到核心逻辑中?这正是AOP需要解决的问题。换句话说,如果客户端获得了BookService的引用,当调用bookService.createBook()时,如何对调用方法进行拦截,并在拦截前后进行安全检查、日志、事务等处理,就相当于完成了所有业务功能。
在Java平台上,对于AOP的织入,有3种方式:
- 编译期:在编译时,由编译器把切面调用编译进字节码,这种方式需要定义新的关键字并扩展编译器,AspectJ就扩展了Java编译器,使用关键字aspect来实现织入;
- 类加载器:在目标类被装载到JVM时,通过一个特殊的类加载器,对目标类的字节码重新“增强”;
- 运行期:目标对象和切面都是普通Java类,通过JVM的动态代理功能或者第三方库实现运行期动态织入。
最简单的方式是第三种,Spring的AOP实现就是基于JVM的动态代理。由于JVM的动态代理要求必须实现接口,如果一个普通类没有业务接口,就需要通过CGLIB或者Javassist这些第三方库实现。
AOP 的几个核心概念:
AOP七大术语
- 切面(Aspect):一个模块化的关注点,例如日志记录、事务管理等。
- 连接点(Join Point):程序执行过程中的某个特定点,例如方法调用或异常抛出。
- 通知(Advice):在连接点执行的动作,分为前置通知、后置通知、环绕通知等。
- 切入点(Pointcut):定义哪些连接点会被通知。
- 目标对象(Target Object):被代理的对象。
- 代理对象(Proxy Object):由 AOP 框架创建的包装目标对象的对象。
- 织入(Weaving):织入是将切面与业务逻辑代码结合起来的过程。这个过程可以在编译时、类加载时或运行时完成
如果目标对象实现了接口,Spring 默认使用 JDK 动态代理。JDK 动态代理通过反射机制创建代理对象,并拦截方法调用。
如果目标对象没有实现接口,Spring 使用 CGLIB 动态代理。CGLIB 通过继承目标类并重写其方法来创建代理对象。
- CGLIB 是一个基于字节码生成的库,它通过 ASM 库操作字节码生成子类。
- 子类会覆盖父类的方法,并在方法调用前后插入自定义逻辑。
Spring AOP 封装了动态代理的细节,开发者只需关注切面和通知的定义。
(1) 定义切面和通知1
2
3
4
5
6
7
8
9
10
11
12
13import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.springframework.stereotype.Component;
public class LoggingAspect {
public void logBefore() {
System.out.println("Logging before method execution...");
}
}
(2) 配置 Spring AOP1
2
3
4
5
6
7
8
9import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.EnableAspectJAutoProxy;
// 启用 AOP 支持
public class AppConfig {
}
(3) 测试代码1
2
3
4
5
6
7
8
9
10
11import org.springframework.context.ApplicationContext;
import org.springframework.context.annotation.AnnotationConfigApplicationContext;
public class MainApp {
public static void main(String[] args) {
ApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
Service service = context.getBean(Service.class);
service.doSomething();
}
}
- Spring AOP 的底层依赖于动态代理技术。
- 如果目标对象实现了接口,则使用 JDK 动态代理。
- 如果目标对象未实现接口,则使用 CGLIB 动态代理。
面向切面编程(Aspect-Oriented Programming, AOP)是一种编程范式,它旨在通过将横切关注点从核心业务逻辑中分离出来,来提高代码的模块化程度。横切关注点指的是那些影响多个模块的功能,如日志记录、事务管理、安全性等。AOP的核心思想是将这些功能从业务逻辑中抽离出来,形成独立的模块——即所谓的“切面”.
代码复用性强
代码易维护
切点表达式
切点表达式(Pointcut Expression)是Spring AOP中用于指定哪些连接点应当被通知(Advice)所影响的关键部分。它通过特定的语法来描述匹配条件,从而选择程序执行流程中的某些点作为切点。
execution是最常用的切点指示器,用来匹配方法执行的连接点。
语法格式:
1
execution(modifiers-pattern? ret-type-pattern declaring-type-pattern? name-pattern(param-pattern) throws-pattern?)
示例:
execution(public * com.example.service.*.*(..)):匹配com.example.service包下所有公共方法的执行。execution(* com.example.service.UserServiceImpl.*(..)):匹配UserServiceImpl类中所有方法的执行。
访问控制权限符: 可选项,没写就是四个权限都包括.写public方法就表示只包括公开的方法.
返回值类型: 必填项 *表示返回值类型任意
全限定类名:可选项 两个点”..”代表当前包及子包下的所有类
省略时表示所有的类
方法名: 必填项 *表示所有方法
形式参数列表:必填项 ()表示没有参数的方法,(..)参数类型和个数随意的方法,(*)只有一个参数的方法
within用来限定匹配特定类型内的连接点。
语法格式:
1
within(type-pattern)
示例:
within(com.example.service.*):匹配com.example.service包内所有类的方法。within(com.example.service..*):匹配com.example.service包及其子包内所有类的方法。
1 |
|
通知类型
@Before - 前置通知,在目标方法执行之前执行。
1
2
3
4
public void beforeAdvice() {
// 在目标方法执行前执行的逻辑
}@After (或 @AfterReturning) - 后置通知,在目标方法成功执行之后执行(即使方法抛出异常,也会执行)。
- 如果你只关心方法正常返回的情况,可以使用
@AfterReturning,它可以访问到返回值。
1
2
3
4
public void afterReturningAdvice(Object result) {
// 在目标方法执行后执行的逻辑,并且可以访问返回值
}- 如果你只关心方法正常返回的情况,可以使用
@AfterThrowing - 异常通知,在目标方法抛出异常后执行。
1
2
3
4
public void afterThrowingAdvice(Exception error) {
// 在目标方法抛出异常后执行的逻辑,并且可以访问异常对象
}@Around - 环绕通知,可以在目标方法执行前后自定义行为,甚至控制是否执行目标方法。
1
2
3
4
5
6
7
public Object aroundAdvice(ProceedingJoinPoint joinPoint) throws Throwable {
// 在目标方法执行前的逻辑
Object proceed = joinPoint.proceed(); // 执行目标方法
// 在目标方法执行后的逻辑
return proceed;
}@After - 最终通知,在任何情况下(无论方法正常返回还是抛出异常)都会执行。
1
2
3
4
public void afterAdvice() {
// 无论目标方法正常返回还是抛出异常都会执行的逻辑
}
@Order 注解是 Spring 框架提供的一个用于定义组件加载顺序的注解。它可以在类、方法或接口上使用,主要用于控制 Bean 的加载顺序、切面的执行顺序以及组件的处理顺序
定义和作用
@Order 注解可以指定一个整数值作为参数,该值表示加载顺序,数值越小优先级越高。这意味着拥有较小 @Order 值的 Bean 将被优先加载
需要注意的是,这个注解并不影响 Bean 的实例化顺序,而是决定了 Bean 在集合中的排序或者是在自动装配时的顺序。
使用场景
多个拦截器的执行顺序
在 Spring MVC 中,如果有多个拦截器,可以使用@Order来确保它们按照特定顺序执行
切面的执行顺序
在 AOP 编程中,如果存在多个切面,可以通过@Order确定它们执行的顺序
事件监听器的执行顺序:当有多个事件监听器监听同一事件时,可以使用@Order来定义它们的执行顺序
定时任务的执行顺序:在 Spring 中,如果有多个定时任务,可以使用@Order来指定它们的执行顺序
通用切点
用切点指的是可以被多个通知(Advice)或者多个切面(Aspect)所共享的切点定义。通过将切点逻辑集中到一个地方来定义,可以在不同的通知或切面中复用这个切点表达式,从而减少重复代码并提高维护性。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
// 切面类
public class logDemo {
// 定义通用切点表达式
public void pointCut() {
}
// 交叉业务
public void log() {
System.out.println("log");
}
public void transaction() {
System.out.println("transaction");
}
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Pointcut;
public class CommonPointcuts {
/**
* 定义一个名为 allServiceMethods 的公共切点,
* 该切点匹配 com.example.service 包及其子包下所有服务类中的任意方法。
*/
public void allServiceMethods() {
// 空方法体,因为 Pointcut 注解已经定义了切点逻辑
}
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17import org.aspectj.lang.annotation.AfterReturning;
import org.aspectj.lang.annotation.Aspect;
import org.springframework.stereotype.Component;
public class LoggingAspect {
/**
* 假设我们已经有了上面定义的 CommonPointcuts 类
*/
public void logServiceAccess(Object result) {
System.out.println("完成了服务方法调用,结果是: " + result);
}
}
如何管理事务
事务是一组数据库操作的逻辑单元,这些操作要么全部成功执行(提交),要么全部不执行(回滚)。事务通常用于保证数据在并发访问或异常情况下的完整性和一致性。
事务的核心特性可以用 ACID 来概括:
- 原子性(Atomicity):事务中的所有操作要么全部完成,要么全部不完成,不允许部分执行。例如,转账操作中扣款和存款必须同时成功。
- 一致性(Consistency):事务执行前后,数据库必须从一个一致状态转换到另一个一致状态。例如,转账后账户余额总和不变。
- 隔离性(Isolation):多个事务并发执行时,一个事务的执行不应影响其他事务。通常通过隔离级别来控制。
- 持久性(Durability):一旦事务提交,其结果必须永久保存在数据库中,即使系统崩溃也能恢复。
开始事务(Begin Transaction):标记事务的起点。
提交(Commit):确认所有操作成功,将结果持久化。
回滚(Rollback):如果发生错误或异常,撤销所有操作,恢复到事务开始前的状态。
Spring事务
编程式
声明式
- 基于注解
- 基于xml
Spring声明式事务管理是通过面向切面编程(AOP)机制实现的。当Spring容器启动时,如果发现有@EnableTransactionManagement注解存在,那么会拦截所有Bean的创建过程,扫描是否有@Transactional注解的存在。如果有,Spring会通过AOP的方式给Bean生成代理对象,代理对象中会增加一个拦截器,该拦截器会在方法执行之前启动事务,在方法执行完毕之后提交或回滚事务
事务属性
(1)传播行为(Propagation)
propagation 属性决定当前事务方法执行时,是否新建事务或加入已有事务。
| 传播行为 | 说明 |
|---|---|
REQUIRED(默认) | 如果有事务,则加入;否则创建新事务。 |
REQUIRES_NEW | 无论是否已有事务,都创建新事务,暂停旧事务。 |
SUPPORTS | 如果有事务,则加入;如果没有,则以非事务方式运行。 |
NOT_SUPPORTED | 始终以非事务方式运行,若有事务则挂起。 |
MANDATORY | 必须在已有事务中运行,否则抛异常。 |
NEVER | 不能在事务中运行,否则抛异常。 |
NESTED | 在当前事务中嵌套一个子事务,子事务可以单独回滚。 |
🔹 示例:1
2
3
4
public void saveData() {
// 该方法无论是否存在事务,都会新建一个事务
}
(2)隔离级别(Isolation)
isolation 属性决定多个事务并发时,数据的可见性。通常数据库提供以下隔离级别:
| 隔离级别 | 说明 | 可能问题 |
|---|---|---|
DEFAULT | 使用数据库默认隔离级别 | - |
READ_UNCOMMITTED | 允许读取未提交数据 | 脏读、不可重复读、幻读 |
READ_COMMITTED | 只能读取已提交数据 | 可能出现不可重复读、幻读 |
REPEATABLE_READ | 事务内多次查询,结果一致 | 可能出现幻读 |
SERIALIZABLE | 串行化访问数据,最高隔离级别 | 性能开销大 |
🔹 示例:1
2
3
4
public void processTransaction() {
// 事务中多次查询结果保持一致
}
只读事务(Read-Only)
readOnly = true 表示事务仅用于查询,不允许数据修改,数据库可能进行优化。适用于 SELECT 语句,提高性能。
🔹 示例:1
2
3
4javaCopyEdit
public List<User> findAllUsers() {
return userRepository.findAll();
}
注意:某些数据库(如 MySQL)会对 readOnly=true 进行优化,但仍需手动确保没有写操作。
回滚规则(Rollback Rules)
rollbackFor 和 noRollbackFor 控制事务回滚条件:
rollbackFor = Exception.class:遇到指定异常回滚(默认只回滚RuntimeException)。noRollbackFor = CustomException.class:遇到指定异常不回滚。
🔹 示例:1
2
3
4
5
6
7
8javaCopyEdit
public void processTransaction() throws Exception {
// 遇到任何 Exception(包括 Checked Exception)都会回滚
}
javaCopyEdit
public void processWithoutRollback() {
// 遇到 IllegalArgumentException 不回滚
}
超时(Timeout)
timeout 指定事务的最大执行时间(秒),超时后事务会回滚。默认值 -1(无限制)。
🔹 示例:1
2
3
4javaCopyEdit // 事务最多执行 5 秒,否则回滚
public void slowTransaction() {
// 事务执行超过 5 秒,会自动回滚
}
超时时间记录的是直到最后一条DML语句执行完成的时间.
如何处理循环依赖
在 Spring 中,循环依赖是指两个或多个 Bean 在初始化过程中相互依赖。例如:
- Bean A 依赖于 Bean B;
- Bean B 又依赖于 Bean A。
Spring 容器通过一些机制来处理循环依赖问题,但并不是所有类型的循环依赖都能被解决
循环依赖可以分为以下几种情况:
(1) 构造函数注入的循环依赖
当两个 Bean 使用构造函数注入时,如果它们之间存在循环依赖,则 Spring 无法解决这种循环依赖,会抛出 BeanCurrentlyInCreationException 异常。
示例代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public class BeanA {
private final BeanB beanB;
public BeanA(BeanB beanB) {
this.beanB = beanB;
}
}
public class BeanB {
private final BeanA beanA;
public BeanB(BeanA beanA) {
this.beanA = beanA;
}
}
在这种情况下,Spring 无法创建任何一个 Bean,因为它们互相依赖且都需要完全初始化后才能使用
(2) Setter 方法或字段注入的循环依赖
当两个 Bean 使用 setter 方法或字段注入时,Spring 可以解决这种循环依赖。
示例代码:1
2
3
4
5
6
7
8
9
10
11
public class BeanA {
private BeanB beanB;
}
public class BeanB {
private BeanA beanA;
}
Spring 能够通过提前暴露未完全初始化的 Bean 来解决这种循环依赖。
Spring 处理循环依赖的机制
Spring 容器通过三级缓存(singleton caches)和提前暴露未完全初始化的 Bean 来解决循环依赖问题。
(1) 单例 Bean 的三级缓存
Spring 容器维护了三个缓存来管理单例 Bean 的生命周期:
- 一级缓存(singletonObjects)
- 存储已经完全初始化完成的 Bean。
- 当 Bean 完全初始化后,会从二级缓存移动到一级缓存。
- 二级缓存(earlySingletonObjects)
- 存储未完全初始化但已经被提前暴露的 Bean。
- 当一个 Bean 正在初始化但还未完成时,Spring 会将其放入二级缓存中,以便其他 Bean 可以引用它。
- 三级缓存(singletonFactories)
- 存储 Bean 的工厂对象(ObjectFactory),用于动态生成未完全初始化的 Bean。
- 当需要提前暴露一个 Bean 时,Spring 会先将其工厂对象放入三级缓存。
(2) 提前暴露未完全初始化的 Bean
当 Spring 发现一个 Bean 正在初始化且有其他 Bean 需要引用它时,Spring 会提前暴露该 Bean 的实例(即使它还未完全初始化)。这通过以下步骤实现:
- 创建 Bean 实例(调用构造函数)。
- 将 Bean 实例的工厂对象放入三级缓存。
- 如果需要提前暴露,将工厂对象生成的 Bean 放入二级缓存。
- 其他 Bean 可以从二级缓存中获取该未完全初始化的 Bean。
- 当 Bean 完全初始化后,将其移入一级缓存。
这种方式适用于基于 setter 方法或字段注入的循环依赖。
3. 为什么构造函数注入的循环依赖无法解决?
构造函数注入要求 Bean 必须在完全初始化后才能被使用。因此,当两个 Bean 通过构造函数相互依赖时,Spring 无法满足它们的初始化顺序要求。以下是具体原因:
- Bean A 需要 Bean B 的完全初始化实例。
- Bean B 需要 Bean A 的完全初始化实例。
- 由于两者都处于“正在初始化”状态,Spring 无法完成任意一方的初始化。
一个 Bean 被认为是完全初始化的,当它已经通过了所有的初始化步骤,并且可以安全地用于应用程序中。这些步骤通常包括:
- 实例化:创建 Bean 的实例。
- 属性填充:为 Bean 的属性设置值或注入依赖(通过构造函数、setter 方法或字段注入)。
- Aware 接口回调:如果 Bean 实现了特定的
Aware接口(如BeanNameAware,BeanFactoryAware,ApplicationContextAware等),Spring 会调用相应的方法,让 Bean 能够访问到容器的相关信息。 - 初始化方法调用:如果有定义初始化方法(通过
@PostConstruct注解或<bean>元素中的init-method属性),Spring 会在该阶段调用这些方法。
一旦所有这些步骤都完成了,这个 Bean 就被认为是完全初始化的,并被放入 Spring 容器的一级缓存(singletonObjects)中,供其他组件使用。
一个 Bean 被认为是未完全初始化的,是指它正处于初始化过程中的某个中间状态。例如,在某些情况下,Bean 已经被实例化并注入了一些依赖,但尚未完成所有的初始化步骤(比如还没有调用初始化方法)。这种状态下,Bean 还不能完全满足其契约要求,因此可能不适合直接使用。
在处理循环依赖时,Spring 使用一种称为“提前暴露”的机制来解决 Setter 或字段注入引起的循环依赖问题。具体来说,当 Spring 正在初始化一个 Bean A 时,如果发现另一个 Bean B 需要引用 Bean A,而此时 Bean A 尚未完全初始化,Spring 会将 Bean A 提前暴露出来,尽管它还未经过全部的初始化步骤。这种提前暴露的 Bean 只完成了实例化和部分依赖注入,但尚未执行 Aware 接口回调、初始化方法等后续步骤。
代理模式
静态代理
对于安全检查、日志、事务等代码,它们会重复出现在每个业务方法中。使用OOP,我们很难将这些四处分散的代码模块化1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27public class SecurityCheckBookService implements BookService {
private final BookService target;
public SecurityCheckBookService(BookService target) {
this.target = target;
}
public void createBook(Book book) {
securityCheck();
target.createBook(book);
}
public void updateBook(Book book) {
securityCheck();
target.updateBook(book);
}
public void deleteBook(Book book) {
securityCheck();
target.deleteBook(book);
}
private void securityCheck() {
...
}
}
动态代理
在内存中动态生成字节码代理类
JDK动态代理技术:只能代理接口.这是Java标准库提供的一种代理方式,要求被代理的目标对象必须实现了接口。Spring会在目标对象实现了接口时默认使用这种代理方式。JDK动态代理主要通过java.lang.reflect.Proxy类来创建代理对象,并通过InvocationHandler接口来处理代理对象的方法调用。
CGLIB:当目标对象没有实现任何接口时,Spring会使用CGLIB(Code Generation Library)来为该类创建子类,并覆盖其方法以实现代理。CGLIB通过继承的方式进行代理,因此不能对final类或final方法进行代理。与JDK动态代理相比,CGLIB代理不需要目标对象实现接口,但是性能上可能会稍逊一筹。
从Spring 4.0开始,默认情况下即使目标对象实现了多个接口,Spring也会尝试使用CGLIB代理,除非特别配置了只使用JDK动态代理
JDK动态代理1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.lang.reflect.Proxy;
// 定义接口
interface UserService {
void addUser(String name);
}
// 实现类
class UserServiceImpl implements UserService {
public void addUser(String name) {
System.out.println("Adding user: " + name);
}
}
// 动态代理处理器
class MyInvocationHandler implements InvocationHandler {
private Object target; // 被代理的目标对象
public MyInvocationHandler(Object target) {
this.target = target;
}
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
// 在方法调用前执行逻辑
System.out.println("Before method: " + method.getName());
// 调用目标对象的方法
Object result = method.invoke(target, args);
// 在方法调用后执行逻辑
System.out.println("After method: " + method.getName());
return result;
}
}
// 测试类
public class JdkDynamicProxyExample {
public static void main(String[] args) {
// 创建目标对象
UserService userService = new UserServiceImpl();
// 创建代理对象
UserService proxyInstance = (UserService) Proxy.newProxyInstance(
userService.getClass().getClassLoader(),
userService.getClass().getInterfaces(),
new MyInvocationHandler(userService)
);
// 调用代理对象的方法
proxyInstance.addUser("Alice");
}
}
CGLIB动态代理
CGLIB(Code Generation Library)是一个强大的、高性能的代码生成库,它允许在运行时扩展Java类和实现接口。CGLIB动态代理主要通过继承的方式来实现代理对象,而不是像JDK动态代理那样基于接口。以下是关于CGLIB动态代理的关键点:
工作原理
- CGLIB通过字节码技术为代理对象创建一个子类,并在子类中重写父类中的非final方法。
- 在调用这些重写的方法时,会先经过用户自定义的拦截器(
MethodInterceptor),然后可以选择性地调用父类的方法。
使用场景
- 当目标对象没有实现任何接口时,可以使用CGLIB来创建代理对象。
- 对于那些需要对现有类进行功能增强,而不想修改原始类的情况下,CGLIB也是一个不错的选择。
与JDK动态代理的区别
- 依赖:JDK动态代理要求被代理类必须实现至少一个接口;CGLIB则不需要,它可以代理普通的类。
- 性能:CGLIB代理的执行速度通常比JDK动态代理快,因为它直接生成了目标类的子类,而JDK动态代理是基于反射机制的。
- 限制:CGLIB不能代理final类或final方法,因为子类无法覆盖它们
springmvc
拦截器
过滤器
Spring 框架中处理模型(Model)- 视图(View)- 控制器(Controller)或 MVC 模式的一个模块。它结合了 MVC 模式的所有优点和 Spring 的便利性。
Spring 使用其 DispatcherServlet 前控制器模式实现 MVC。
简而言之,DispatcherServlet 是将请求路由到预定目的地的主要控制器。Model 只是应用的数据,而视图则由各种模板引擎来表示。
包含spring的依赖同时使用servlet等实现MVC架构的Web开发.
servlet如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18import java.io.IOException;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
public class HelloServlet extends HttpServlet {
private static final long serialVersionUID = 1L;
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
response.setContentType("text/html");
response.getWriter().println("<h1>Hello, World!</h1>");
}
}
springmvc的示例代码如下.
要通过 Java 配置类启用 Spring MVC 支持,只需添加 @EnableWebMvc1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
public class WebConfig implements WebMvcConfigurer {
public void addViewControllers(ViewControllerRegistry registry) {
registry.addViewController("/").setViewName("index");
}
public ViewResolver viewResolver() {
InternalResourceViewResolver bean = new InternalResourceViewResolver();
//bean.setViewClass(JstlView.class); in older version
bean.setPrefix("/WEB-INF/view/");
bean.setSuffix(".jsp");
return bean;
}
}
这将设置 MVC 项目所需的基本支持,如注册处理器、映射器、类型转换器、验证支持、消息转换器和异常处理。本例中注册了一个 ViewResolver Bean,它从 /WEB-INF/view 目录返回 .jsp 视图。可以注册视图控制器(ViewController),使用 ViewControllerRegistry 在 URL 和视图名称之间创建直接映射。这样,两者之间就不需要任何 Controller 了。
如果想自定义扫描 Controller 类,可以使用 @ComponentScan 注解,并指定包含 Controller 的包。1
2
3
4
5
6
public class WebConfig implements WebMvcConfigurer {
// ...
}
为了引导应用加载该配置,还需要一个 Initializer 类:
在Servlet3.0环境中,容器会在类路径中查找实现javax.servlet.ServletContainerInitializer接口的类,如果找到的话就用它来配置Servlet容器。 Spring提供了这个接口的实现,名为SpringServletContainerInitializer,这个类反过来又会查找实现WebApplicationInitializer的类并将配置的任务交给它们来完成。Spring3.2引入了一个便利的WebApplicationInitializer基础实现,名为AbstractAnnotationConfigDispatcherServletInitializer,当我们的类扩展了AbstractAnnotationConfigDispatcherServletInitializer并将其部署到Servlet3.0容器的时候,容器会自动发现它,并用它来配置Servlet上下文。
1 | public class MainWebAppInitializer implements WebApplicationInitializer { |
1 | public class MyWebAppInitializer extends AbstractAnnotationConfigDispatcherServletInitializer { |
一个基本的 Controller 示例:1
2
3
4
5
6
7
8
public class SampleController {
public String showForm() {
return "sample";
}
}
相应的 JSP 资源是 sample.jsp:1
2
3
4
5
6
7<html>
<head></head>
<body>
<h1>This is the body of the sample view</h1>
</body>
</html>
基于 JSP 的视图文件位于项目的 /WEB-INF 文件夹下,因此只有 Spring 才能访问它们,而不能直接通过 URL 访问。
也可以使用纯 XML 配置来代替上述 Java 配置:1
2
3
4
5
6
7
8
9
10
11
12<context:component-scan base-package="com.baeldung.web.controller" />
<mvc:annotation-driven />
<bean id="viewResolver"
class="org.springframework.web.servlet.view.InternalResourceViewResolver">
<property name="prefix" value="/WEB-INF/view/" />
<property name="suffix" value=".jsp" />
</bean>
<mvc:view-controller path="/" view-name="index" />
</beans>
如果想使用纯 XML 配置,还需要添加一个 web.xml 文件来引导应用。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16<servlet>
<servlet-name>dispatcher</servlet-name>
<servlet-class>
org.springframework.web.servlet.DispatcherServlet
</servlet-class>
<init-param>
<param-name>contextConfigLocation</param-name>
<param-value>/WEB-INF/spring/dispatcher-config.xml</param-value>
</init-param>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>dispatcher</servlet-name>
<url-pattern>/</url-pattern>
</servlet-mapping>
springboot
Spring Boot 是对 Spring 平台的补充,它能让你轻松上手并创建独立的生产级应用。Spring Boot 的目的不是取代 Spring,而是让使用 Spring 变得更快、更简单。
pring Boot Starter
Spring Boot 提供了便捷的 Starter 依赖,这是一种依赖描述符,可以为特定功能引入所有必要的技术。
这样做的好处是,不再需要为每个依赖项指定版本,而是让 Starter 管理依赖。
最快捷的入门方法是在 pom.xml 中添加 spring-boot-starter-parent:1
2
3
4<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
</parent>
这样就能解决依赖管理问题。
Spring Boot 入口点
使用 Spring Boot 构建的每个应用都需定义 main 入口点。
这通常是一个 Java 类,带有 main 方法,并用 @SpringBootApplication 进行注解:1
2
3
4
5
6
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
该注解添加了以下其他注解:
@Configuration将类标记为 bean 定义的来源。@EnableAutoConfiguration会告诉框架根据 classpath 上的依赖自动添加 Bean。@ComponentScan会扫描与 Application 类相同包或其子包中的其他配置和 Bean。
有了 Spring Boot,就可以使用 Thymeleaf 或 JSP 设置前端,而无需使用定义的 ViewResolver。在 pom.xml 中添加 spring-boot-starter-thymeleaf 依赖后,Thymeleaf 就会启用,无需额外配置。
application.yml
这是Spring Boot默认的配置文件,它采用YAML格式而不是.properties格式,文件名必须是application.yml而不是其他名称。
YAML格式比key=value格式的.properties文件更易读。比较一下两者的写法:
使用.properties格式:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15# application.properties
=${APP_NAME:unnamed}
=jdbc:hsqldb:file:testdb
=sa
=
=org.hsqldb.jdbc.JDBCDriver
=false
=3000
=3000
=60000
=20
=1
使用YAML格式:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17# application.yml
spring:
application:
name: ${APP_NAME:unnamed}
datasource:
url: jdbc:hsqldb:file:testdb
username: sa
password:
driver-class-name: org.hsqldb.jdbc.JDBCDriver
hikari:
auto-commit: false
connection-timeout: 3000
validation-timeout: 3000
max-lifetime: 60000
maximum-pool-size: 20
minimum-idle: 1
可见,YAML是一种层级格式,它和.properties很容易互相转换,它的优点是去掉了大量重复的前缀,并且更加易读。
使用环境变量
在配置文件中,我们经常使用如下的格式对某个key进行配置:1
2
3
4
5app:
db:
host: ${DB_HOST:localhost}
user: ${DB_USER:root}
password: ${DB_PASSWORD:password}
这种${DB_HOST:localhost}意思是,首先从环境变量查找DB_HOST,如果环境变量定义了,那么使用环境变量的值,否则,使用默认值localhost。
这使得我们在开发和部署时更加方便,因为开发时无需设定任何环境变量,直接使用默认值即本地数据库,而实际线上运行的时候,只需要传入环境变量即可
ogback-spring.xml
这是Spring Boot的logback配置文件名称(也可以使用logback.xml),一个标准的写法如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
<configuration>
<include resource="org/springframework/boot/logging/logback/defaults.xml" />
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
<charset>utf8</charset>
</encoder>
</appender>
<appender name="APP_LOG" class="ch.qos.logback.core.rolling.RollingFileAppender">
<encoder>
<pattern>${FILE_LOG_PATTERN}</pattern>
<charset>utf8</charset>
</encoder>
<file>app.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.FixedWindowRollingPolicy">
<maxIndex>1</maxIndex>
<fileNamePattern>app.log.%i</fileNamePattern>
</rollingPolicy>
<triggeringPolicy class="ch.qos.logback.core.rolling.SizeBasedTriggeringPolicy">
<MaxFileSize>1MB</MaxFileSize>
</triggeringPolicy>
</appender>
<root level="INFO">
<appender-ref ref="CONSOLE" />
<appender-ref ref="APP_LOG" />
</root>
</configuration>
它主要通过<include resource="..." />引入了Spring Boot的一个缺省配置,这样我们就可以引用类似${CONSOLE_LOG_PATTERN}这样的变量。上述配置定义了一个控制台输出和文件输出,可根据需要修改。
static是静态文件目录,templates是模板文件目录,注意它们不再存放在src/main/webapp下,而是直接放到src/main/resources这个classpath目录,因为在Spring Boot中已经不需要专门的webapp目录了。
springcloud
日志库
slf4j✨
Overview (Logback-Parent 1.5.15 API)
SLF4J为各种日志框架(例如 java.util.logging、logback、log4j)提供了一个简单的门面或抽象,允许用户在部署时插入所需的日志框架。
logback
Logback 旨在作为流行的 log4j 项目的继任者,从 log4j 1.x 停止的地方继续发展。
Logback 的架构相当通用,以便在不同情况下应用。目前,logback 分为三个模块,分别是 logback-core、logback-classic 和 logback-access。
logback -core模块为其他两个模块奠定了基础。logback-classic模块可以看作是 log4j 1.x 的改进版本。此外,logback-classic模块原生实现了 SLF4J API,因此您可以轻松地在logaback和其他日志框架(如 log4j 1.x 或 java.util.logging(JUL))之间切换。
log4j
Log4j – Apache Log4j 2 - Apache Log4j 2
Apache Log4j 2 是 Log4j 的升级版本,在性能上对前一代 Log4j 1.x 进行了显著提升,并提供了许多 Logback 中的改进,同时修复了 Logback 架构中的一些固有缺陷。1
2
3
4
5
6
7
8
9
10
11
12
13<!-- https://mvnrepository.com/artifact/ch.qos.logback/logback-classic -->
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.5.18</version>
<scope>compile</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.slf4j/slf4j-api -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>2.0.17</version>
</dependency>
一般可以使用slf4j-api接口加上logback-classic(或者slf4j-simple)实现.
常用术语
- 类(Class)命名
- 规则:使用大写驼峰式(UpperCamelCase),首字母大写,每个单词首字母大写。
- 特点:通常是名词或名词短语,表示一个实体或概念。
- 示例
- User
- OrderService
- HttpRequestHandler
- 注意
- 接口命名与类类似,但通常反映其功能或角色,例如 Runnable、Serializable。
- 抽象类可以以 Abstract 开头,例如 AbstractFactory。
- 接口(Interface)命名
- 规则:同样使用大写驼峰式,通常是形容词或表示能力的名词。
- 特点:突出功能或契约。
- 示例
- Comparable
- Iterable
- UserService
- 注意:避免使用 I 前缀(如 IUserService),这是 C# 的习惯,Java 中不推荐。
- 方法(Method)命名
- 规则:使用小写驼峰式(lowerCamelCase),首字母小写,后续单词首字母大写。
- 特点:通常是动词或动词短语,表示行为或操作。
- 示例
- getName
- calculateTotalPrice
- isValid
- 约定
- Getter 方法以 get 开头(返回布尔值时用 is),例如 getAge、isActive。
- Setter 方法以 set 开头,例如 setName。
- 操作方法通常以动词开头,例如 saveUser、deleteRecord。
- 变量(Variable)命名
- 规则:使用小写驼峰式。
- 特点:简洁、有意义,反映变量的作用。
- 示例
- userName
- orderList
- totalAmount
- 约定
- 局部变量:短而明确,例如 i(循环计数器)、temp。
- 成员变量(字段):避免无意义的缩写,例如 firstName 而不是 fName。
- 布尔变量:通常以 is、has 等开头,例如 isFinished、hasPermission。
- 常量(Constant)命名
- 规则:全部大写,单词间用下划线 _ 分隔。
- 特点:用于 static final 修饰的常量。
- 示例
- MAX_VALUE
- DEFAULT_TIMEOUT
- PI
- 注意:通常定义在类或接口中,表示不可变的值。
- 包(Package)命名
- 规则:全部小写,使用点号 . 分隔,通常基于域名倒写。
- 特点:层次清晰,避免关键字。
- 示例
- com.example.util
- org.springframework.context
- 约定
- 避免使用连字符或下划线。
- 通常以公司或组织域名开头,避免命名冲突。
- 枚举(Enum)命名
规则:类名使用大写驼峰式,枚举值使用全大写(类似常量)。
示例
1
2public enum Status {
ACTIVE, INACTIVE, PENDING }
- 异常(Exception)命名
- 规则:使用大写驼峰式,以 Exception 或 Error 结尾。
- 示例
- FileNotFoundException
- NullPointerException
- CustomValidationError
- 注解(Annotation)命名
- 规则:使用大写驼峰式,通常反映用途。
- 示例
- @Autowired
- @RestController
- @MyCustomAnnotation
- 测试类和方法命名
规则
- 测试类以 Test 结尾,命名反映被测试的类,例如 UserServiceTest。
- 测试方法以 test 开头,描述测试行为,使用小写驼峰式。
示例
1
2
3
4
5public class UserServiceTest {
public void testSaveUser() {
// 测试代码 }
}
- 其他约定
避免缩写:除非是广为人知的缩写(如 URL、HTTP),否则使用完整单词,例如 userIdentifier 而不是 userId。
语义清晰:命名应反映用途,避免过于泛泛的名称,如 data、process。
单复数
:
- 集合使用复数,例如 users、orderList。
- 单个对象使用单数,例如 user、order。
- Spring 中的特殊命名
- Bean 名称
- 默认是类名首字母小写,例如 UserServiceImpl 的 Bean 名是 userServiceImpl。
- 可通过注解指定,例如 @Service(“customName”)。
- 接口与实现类
- 接口:UserService。
- 实现类:UserServiceImpl(以 Impl 结尾是常见约定)。
- POJO (Plain Old Java Object)
- 含义:普通的 Java 对象,指不依赖特定框架、不继承特定类或实现特定接口的简单 Java 类。
- 特点
- 只包含属性(字段)、getter/setter 方法,可能有简单的业务逻辑。
- 不受外部框架约束,例如不继承 Servlet 或实现 Serializable(除非业务需要)。
- 用途:作为基础数据载体,广泛用于各种场景
- VO (Value Object)
- 含义:值对象,通常用于表示不可变的数据结构,强调值的语义。
- 特点
- 通常是不可变的(Immutable),创建后属性不可修改。
- 常用于传递数据,关注数据的完整性和一致性。
- 在某些场景下,也被用作视图对象(View Object),表示展示层的数据。
- 用途:在业务逻辑中传递数据,或在前端展示时封装数据。
- PO (Persistent Object)
- 含义:持久化对象,表示与数据库表直接映射的对象,通常用于 ORM(对象关系映射)框架(如 Hibernate、MyBatis)。
- 特点
- 属性与数据库表的字段一一对应。
- 通常包含主键(如 id)和其他表字段。
- 可能有注解(如 @Entity、@Table)来映射数据库。
- 用途:用于数据持久化层,与数据库交互
- DAO (Data Access Object)
含义:数据访问对象,负责封装数据库操作的逻辑。
特点
:
- 提供 CRUD(增删改查)方法,与数据库交互。
- 屏蔽底层数据访问细节(如 JDBC、ORM 的具体实现)。
- 通常与 PO 配合使用。
用途:隔离业务逻辑与数据访问逻辑。
- DTO (Data Transfer Object)
含义:数据传输对象,用于在不同层(如服务层与表现层)或系统之间传递数据。
特点
:
- 不直接映射数据库表,属性根据传输需求设计。
- 通常是简单的数据容器,不含复杂业务逻辑。
- 常用于减少网络传输中的数据冗余或适配前端需求。
用途:跨层或跨系统的数据交换。
- BO (Business Object)
- 含义:业务对象,封装业务逻辑或表示业务实体的对象。
- 特点
- 包含业务数据和相关操作方法。
- 通常聚合多个 PO 或 DTO,表示更高层次的业务概念。
- 用途:在业务逻辑层处理复杂的业务规则。
对比总结
| 术语 | 全称 | 主要用途 | 与数据库关系 | 是否含业务逻辑 |
|---|---|---|---|---|
| POJO | Plain Old Java Object | 通用简单对象 | 无特定关系 | 可能有简单逻辑 |
| VO | Value Object | 数据传递或视图展示 | 无直接关系 | 通常无 |
| PO | Persistent Object | 数据库表映射 | 直接映射 | 通常无 |
| DAO | Data Access Object | 数据访问逻辑 | 与数据库交互 | 数据操作逻辑 |
| DTO | Data Transfer Object | 层间或系统间数据传输 | 无直接关系 | 通常无 |
| BO | Business Object | 业务逻辑处理 | 间接(聚合 PO/DTO) | 包含业务逻辑 |
典型使用场景
在一个 Spring 项目中,这些对象可能这样协作:
- PO:UserPO 用于与数据库表 users 映射,由 ORM(如 JPA)管理。
- DAO:UserDAO 提供对 UserPO 的增删改查操作。
- DTO:UserDTO 从 UserPO 转换而来,传递给服务层或前端。
- BO:OrderBO 聚合多个 UserDTO 和订单信息,执行业务计算。
- VO:UserVO 用于返回给前端的不可变视图数据。
- POJO:任何简单的 Java 类都可以是 POJO,可能用作上述某种对象的基类。
数据库连接池
| 特性 | DriverManagerDataSource | HikariCP |
|---|---|---|
| 连接池支持 | 无,每次创建新连接 | 有,高效连接池管理 |
| 性能 | 低,适合低并发 | 高,优化了并发和资源复用 |
| 使用场景 | 开发、测试、小型应用 | 生产环境、高并发应用 |
| 配置复杂度 | 简单,仅基本连接信息 | 支持丰富配置(如池大小、超时等) |
| 依赖 | Spring 自带,无需额外库 | 需引入 HikariCP 依赖 |
| Spring Boot 默认 | 否 | 是(2.x 和 3.x 默认使用) |
| 连接管理 | 每次获取连接都新建,关闭即销毁 | 池化管理,连接复用 |
HikariCP 是 Spring Boot 默认连接池,性能极高,但无内置监控。
Druid 提供强大监控功能(如 SQL 执行时间、连接状态),适合需要实时分析连接池状态的场景。
